
基于信号改进深度学习网络的京津冀城市群二氧化氮浓度预测
2021-03-16 03:51宫同伟刘炳春
中国环境监测 2021年1期
宫同伟,张 洋,刘炳春
1.天津城建大学建筑学院,天津 300384
2.天津理工大学管理学院,天津 300384
随着中国经济的快速发展,各种大气污染物的排放量不断增多,造成经济发展与环境保护的矛盾加剧,生态环境持续遭受破坏[1]。 京津冀城市群是该类矛盾表现最突出的区域之一,尤其是工业排放和机动车尾气排放带来的大量氮氧化物(NOx)、二氧化硫(SO2)和烟尘,导致区域性雾霾频发,空气污染严重[2-3]。 二氧化氮(NO2)在常温状态下呈现为具有刺激性气味的有毒气体。 除了雷电与土壤排放等自然来源之外,空气中大量的NO2主要由化石燃料的使用、汽车尾气排放等人为活动产生[4]。 NO2通过呼吸进入人体,会严重影响人体健康,在腐蚀呼吸道的同时,可能引发迟发性肺水肿等疾病[5]。 因此,对京津冀地区NO2日均浓度进行精准预测,探究其时空分布变化,对于NO2污染的预警与防治尤为重要。 通过模型预测揭示京津冀城市群NO2时空变化特点,探究其发展变化的趋势和原因,可为京津冀城市群NO2污染防治工作提供科学参考。
当前,大气污染物浓度预测研究主要集中在数值模式预测和统计模式预测两方面。 数值模式需基于大气污染物观测实况、污染源排放情况和气象资料,利用初始值和边界值,通过模拟大气运动状态实现预测[6];传统统计模型往往需要大量空气污染物历史观测数据,利用回归分析等拟合方法建立污染物历史数据与被预测变量之间的关系[7]。 李华娇等[8]开展了利用基于动态模糊综合评价的混合模型,在我国建立空气质量预测预警系统的研究与应用[8]。 WANG 等[9]结合模糊时间序列预测技术和数据后处理方法,对主要大气污染物进行了预测。 机器学习和传统回归模型逐渐无法满足大数据预测所需的数据承载能力,神经网络算法成为预测领域的热点方法[10]。WANG 等[11]结合全年污染来源的排放模式,从日常可用气象参数中提取关键信息,建立了基于物理的人工神经网络(ANN)空气污染物预测工具,可以充分捕捉特定场景下空气污染物浓度的时间变化。 然而在污染物浓度非常高的情况下,对PM2.5和PM10等颗粒物浓度的预测能力还存在不足[12]。 刘炳春等[13]采用IG-LASSO 组合预测方法对我国城市空气质量指数进行了预测,证明通过输入变量优化的组合模型的预测精度更高。NIU 等[14]设计了一种新的基于模糊聚类算法的模糊时间序列模型,该模型对异常值和噪声数据点具有鲁棒性。 然而,单一化的神经网络模型已逐渐不能满足政府和企业高精度的预测需求,于是研究人员不断尝试通过改进输入变量结构来提高模型预测性能[15]。 LI 等[16]构建了基于数据预处理和分析的混合EMMD-GRNN 模型,提高了输入变量的数据维度,实现了快速并准确预测未来一天的PM2.5浓度。 输入变量选择方面,朱素玲等[17]设计了一个非负性且高效的化学解决方案,修改了嵌套空气质量预测系统的后序,仅考虑6项大气常规污染物之间的影响关系进行数值预测。 以上研究为大气污染控制提供了重要的技术支持,促进了空气质量预测方法的发展。 目前,对污染物浓度的预测研究大多使用日均浓度数据进行试验[18],因此,本文选择京津冀城市群6 项大气常规污染物日均浓度数据,组成NO2浓度预测数据库进行预测。
相对于空气质量指数的动态变化,长短期记忆(LSTM)神经网络可以有效解决空气质量指数时空变化带来的不利影响。 LSTM 是一种通过学习长跨度时间序列来解析数据特性的深度学习方法,可以自动确定最优时间滞后,以实现精准预测[19]。 小波分解(WD)能够有效、准确地表达空气污染物的浓度信号信息,从而提高深度学习模型对试验数据的学习能力。 因此,本文使用通过WD 得到的其他5 项大气常规污染物(不包含NO2)日均浓度时序数据,作为训练模型的输入指标,继而基于LSTM 构建预测模型,对京津冀城市群NO2浓度进行预测。 本文主要完成以下研究内容:①通过使用WD 对数据进行升维处理,优化输入变量,提升LSTM 模型的预测精度;②开发针对京津冀城市群NO2日均浓度的WD 和LSTM 组合神经网络预测模型(W-LSTM);③将传统神经网络预测模型与W-LSTM 预测模型进行性能比对,验证组合预测模型的预测精度和稳定性;④基于W-LSTM 的2019—2020 年京津冀城市群NO2浓度预测与时空变化分析。
1 研究方法
1.1 LSTM 网络
空气污染物浓度预测不仅需要当日数据,还需要历史数据用来进行经验学习。 由于神经网络模型的隐藏层存在自反馈机制,因此,其在处理长期依赖问题方面具有优势。 LSTM 作为当前流行的递归神经网络算法,促进了时间序列长期趋势特征和短期动态特征的学习能力[20]。 不同于传统的循环神经网络模型,LSTM 拥有独特的“记忆单元”,通过该结构构建的LSTM 网络的隐藏层能够存储任意时间长度的信息,获得更为精确的时间序列模型。 LSTM 网络的记忆单元结构如图1所示。 该模块的主体由输入门、遗忘门和输出门,以及1 个循环单元构成。 LSTM 通过非线性函数实现对各“门”的开关控制,用以控制和保护记忆单元状态,最终控制通过神经单元的信息量的增减。

图1 LSTM 神经网络示意图Fig.1 Schematic diagram of the interior of LSTM
假设在t 时刻,某记忆单元模块的输入为xt,输出为ht,单元状态为ct,那么该记忆单元模块的“门结构”可以表示为
输入门:
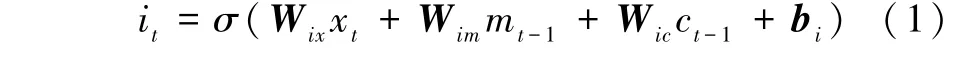
遗忘门:

输出门:

各计算模块表示为
输入转换:

单元状态更新:

隐藏层输出:

式中:σ 为Sigmoid 函数;tan h 为双曲正切函数;it、 ft、ot、c_int分别为输入门、遗忘门、输出门、输入转换对单元的输入;Wix、Wfx、Wox、Wcx和Wim、Wfm、Wom、Wcm分别为xt和ht-1对应的输入门、遗忘门、输出门、输入转换的权重矩阵; bi、bf、bo、bc分别为输入门、遗忘门、输出门、输入转换的偏移向量。
1.2 WD 变换
WD 变换通过窗口调整使数据信号经伸缩平移后更便于局部化分析,变换后的信号包含反映变化趋势的低频信号和随机波动的高频信号。NO2浓度时序数据{y1,y2,…,yn} 的特点是非线性非平稳,经过WD 变换能够提取NO2浓度时序数据在不同时频上的信息特征。 通过WD 变换将污染物浓度数据分解为由不同维度数据信号构成的序列组。 与原始数据相比,这些序列组具有更稳定的方差和较少的奇异值点,在模型中可以更有效、准确地表达原信号信息。 若WD 变换的尺度函数为φ(t),母小波函数为ψ(t), 则

式中:j 为尺度参数,k 为平移参数。
由此可得
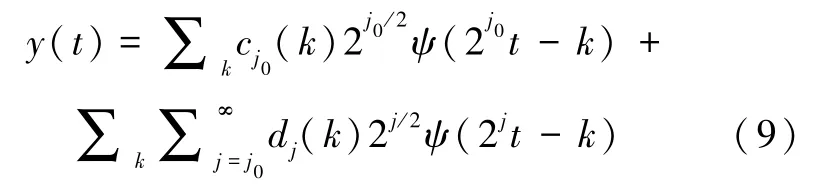
式中: cj0(k) 为近似系数,dj(k) 为细节系数。
NO2浓度数据经m 步变换得到

式中: Amt为近似信息集合, 表示原始数据的信息特征; D1t,…,Dmt为高频信息集合, 表示细微信号波动,即原信息的噪声部分。
1.3 组合预测模型
使用WD 变换和LSTM 网络搭建京津冀NO2浓度组合预测模型,预测试验分为两个部分,如图2 所示。 第一部分将京津冀地区13 个城市的6 项大气常规污染物日均浓度原始数据通过WD变换获得重组试验数据集合,截取80%的原始数据(2014 年1 月—2018 年5 月)作为训练数据集合,另外20%(2018 年6 月—2019 年6 月)作为测试数据集合。 本阶段获得两组输入集合,即NO2日均浓度数据通过WD 变换得到的低频信息集合{a3},以及其他5 项大气常规污染物数据通过WD 变换得到的多维信息集合{a3,d1,d2,d3}。
第二部分使用LSTM 网络搭建多层次深度预测模型,学习和记忆训练数据的数据特征及潜在指标之间的关联关系,继而使用测试数据集对模型进行预测性能测试,通过不断调整参数获得最优预测模型。 具体试验过程如下:
第一步,由京津冀城市群6 项大气常规污染物日均浓度数据形成时序数据集{AP1,AP2,…,APn},通过WD 变换将{AP1,AP2,…,APn}经m 层分解可得到高维输入信息集{X′1,X′2,…,X′t}。
其中,X′i= (Ami-1,Dli-1,…,Dmi-1),i= 1,2,…,t。同理可得到t+1 时刻的分解结果,即:X′t+1=(Amt,D1t,…,Dmt)。

第四步,使用以上训练得到的预测模型及第一步得到的t + 1 期输入向量X′t+1, 可测得t + 1期NO2浓度的预测值f(X′t+1)。
通过重复步骤一至步骤四,得到预测值
f(X′1),…,f(X′t+1)。
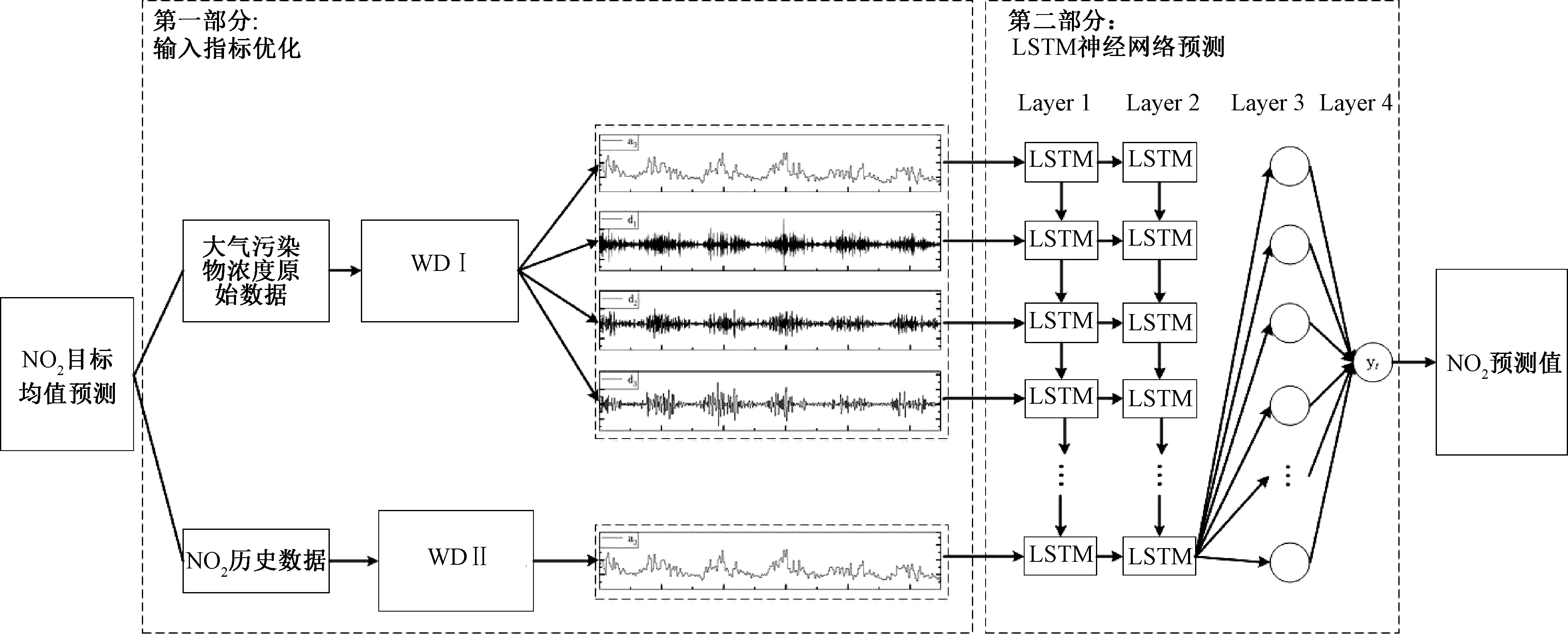
图2 W-LSTM 模型预测过程示意图Fig.2 Frame of the W-LSTM forecasting model
1.4 模型预测性能评价指标
为评价模型的预测性能,选取平均绝对误差(MAE)、均方根误差(RMSE)、平均绝对百分误差(MAPE)作为模型误差评价指标[21],计算公式如公式(11)至公式(13)所示:

式中:n 为试验样本数量,yi为实际观测值,为预测值。
2 实证结果
2.1 研究区域及数据
以京津冀城市群为研究对象,使用京津冀13个城市大气污染物日均浓度历史数据进行预测试验。 为方便检验预测模型的预测效果,选取13 个城市在2014 年1 月—2019 年6 月的主要大气污染物(PM10、PM2.5、SO2、NO2、O3、CO)浓度日均值数据(共计26 091 组),作为本次试验的原始数据,对模型预测结果进行回算验证,其中PM10、PM2.5、SO2、CO 和O3作为模型的输入变量。
2.2 京津冀城市群NO2 浓度预测结果评价
本研究构建的W-LSTM 组合模型实质上是运用WD 变换对原始数据进行维度拓展,其预测性能与LSTM 模型的比较如表1 所示。 从整体性能来看,W-LSTM 模型对京津冀城市群13 个城市NO2浓度的预测结果更佳,平均MAPE 约为9%,说明W-LSTM 模型对京津冀城市群的整体预测结果更加接近真实值。 从各城市的预测结果来看,LSTM 模型的MAPE 均在10%左右,除天津和石家庄以外,该模型的预测稳定性较强。 WLSTM 模型对单一城市预测评价指标的MAPE 最优低至5.34%,但同时也存在张家口、承德MAPE 较高的情况,尤其是承德的MAPE 高达14. 47%。 出现该现象的原因是京津冀城市群整体呈狭长分布,南北各地区污染物浓度水平及分布规律存在明显差别。 由于模型对学习训练数据特征的敏感度较低,在充分学习唐山这一类较高污染水平城市的数据特征之后,再使用承德和张家口等较低污染水平城市的数据进行学习,会使预测性能下降。 可以认为,W-LSTM模型对不同地区污染数据的泛化能力比LSTM模型弱。 然而,W-LSTM 模型对京津冀城市群13 个城市NO2日均浓度预测结果的MAE 明显优于LSTM 模型,平均MAE 为2. 645 8,且各地之间的偏差较小。 模型性能的另一评价指标RMSE 在两个预测模型中的表现均较为良好,W-LSTM 模型以0. 462 1 的差值优于LSTM 模型,说明基于LSTM 搭建的W-LSTM 组合模型适用于京津冀城市群NO2浓度的预测。

表1 LSTM 模型与W-LSTM 模型NO2 浓度预测性能比较Table 1 Comparison of NO2 concentration prediction performance between LSTM model and W-LSTM model
LSTM 模型在预测石家庄市NO2日均浓度时表现较为优秀,MAPE 为5.61%,而W-LSTM 模型在预测唐山市NO2日均浓度时表现最为优秀,MAPE 为5.34%。 与LSTM 模型相比,W-LSTM模型提高了部分城市的NO2日均浓度预测精度,最为明显的是在唐山市,其MAPE 由10.88%下降为5.34%。 另外,在预测北京、廊坊、衡水、秦皇岛NO2日均浓度时,W-LSTM 也有更好的表现,其MAPE 分别下降了4.00%、1.62%、2.61%、3.03%。 两种模型同时存在最优预测状态,而W-LSTM 模型在平均预测性能方面表现更加卓越。 W-LSTM 模型预测结果与真实观测结果的对比如图3 所示。 通过将表1 中不同模型的MAE进行对比可知,加入WD 变换的组合预测模型可以有效降低MAE,部分城市的RMSE 也有非常明显的降低。 也就是说,W-LSTM 模型能更加有效地预测NO2浓度的变化趋势,对于空气污染物控制工作具有更为有效的指导作用。
图4 为W-LSTM 模型NO2浓度预测结果。输入变量通过WD 变换转而生成高维输入变量,能够有效增加数据表示的信息量,预测结果符合预测目标历史数值变化规律,对提高预测模型的预测精度和稳健性贡献较大。 京津冀地区西部环山、东部沿海,气象条件在不同城市有一定的差别,并且气象因素对于污染物累积和扩散的影响比较明显。 在京津冀城市群整体气象数据可获取的情况下,若在组合预测模型输入数据中补充气象信息,可以更加准确地对环境状态进行表达,有助于在很大程度上提高模型的泛化能力。
2.3 京津冀城市群NO2 污染趋势分析
为更清晰地展现京津冀地区各地级市NO2污染指数的空间分布状态,在绘制不同年际的京津冀城市群NO2污染综合指数地图时,使用统一的图例可有效对比NO2污染指数的时空变化,同时也能够避免极端值对等级划分造成过大影响。鉴于此,以每10%分位点为划分界限,对平均NO2污染指数进行等级划分,研究通过统一划分标准下的各地区不同时间、跨度较大的污染指数进行预测结果表达,最终得到便于对比分析的动态演变图[22]。 NO2污染指数诠释内容见表2。
通过迭代预测获得2019 年7 月—2020 年12月共计18 个月的NO2日均浓度数据,绘制年平均NO2污染指数地图,同时加入2018 年和2019年整年数据用来对比观测,探究京津冀城市群NO2污染的时空演变规律,结果如图5 所示。 从整体趋势来看,京津冀城市群NO2污染水平从2018 年开始逐年明显降低,仅唐山市的污染治理效果不明显。

图3 W-LSTM 模型NO2 浓度预测偏差观测图Fig.3 Deviation observation diagram of NO2 concentration prediction in W-LSTM
通过整理京津冀城市群2015 年以来有关空气污染的部分治理举措可知,2018—2019 年年均NO2污染综合指数下降明显,可能是我国在空气污染预警、监管和减排等多方面控制力度不断加强的结果。 北京市和河北省产业结构转变速度相对较缓慢,而天津市第二产业比重降幅较大,在一定程度上造成了进行京津冀城市群NO2浓度预测分析与比对时,天津市NO2污染指数显著降低的情况。 近年来,唐山不断承接北京和天津等地的传统工业企业外溢,导致唐山市NO2污染指数常年居于显著水平,因此,建议将唐山作为开展京津冀城市群北部地区空气污染治理的重点城市。

图4 W-LSTM 模型NO2 浓度预测结果Fig.4 Results of NO2 concentration prediction in W-LSTM

表2 NO2 污染指数诠释Table 2 Interpretation of nitrogen dioxide pollution index

图5 京津冀城市群NO2 预测趋势Fig.5 Trend of NO2 prediction results in Beijing-Tianjin-Hebei urban agglomeration
综上所述,使用W-LSTM 模型得到的2019 年7 月—2020 年12 月京津冀城市群NO2浓度预测结果,基本符合当下京津冀城市群的NO2污染分布趋势。 京津冀城市群NO2污染高值区的分布较为集中,以唐山、天津、石家庄、保定和邢台为主的工业集中城市仍是该地区未来开展NO2污染治理的重点区域,应进一步加强区域协作与属地管理,确保区域环境空气质量得到切实改善。
3 结论
1)利用LSTM 网络构建的W-LSTM 预测模型对长期跟踪时序数据具备良好的预测性能,基本可以掌握NO2浓度数据的周期性变化规律,对于特殊时间节点的把控也有突出表现,例如季节更替、政策实施等。
2)NO2浓度时序数据通过WD 变换后,在一定程度上加深了对数据规律的解释程度,WLSTM 组合模型的预测平均MAPE 明显降低,说明增加输入数据维度有助于提升LSTM 模型的预测精度。
3)由NO2空间分布特征分析结果可知,其分布特征差异较大,北部地区明显低于南部地区,从北部草原到南部沿海呈现出明显的增高趋势,并且较高浓度水平的NO2污染分布区域较为集中,主要以保定、石家庄、邢台一带为中心。
4)本文提出的结合WD 和LSTM 网络搭建的组合预测模型,对京津冀城市群整体NO2浓度的预测效果良好,平均MAPE 可达到9.21%,并且基于其他5 项大气污染物数据的预测结果基本符合京津冀地区NO2分布规律,说明该模型可在NO2污染防治工作中发挥一定作用。
猜你喜欢
今日农业(2021年11期)2021-11-27
环境科学研究(2021年6期)2021-06-23
环境科学研究(2021年4期)2021-04-25
少儿科学周刊·儿童版(2021年23期)2021-03-24
领导决策信息(2018年7期)2018-05-22
建筑科技(2018年1期)2018-02-16
领导决策信息(2017年10期)2017-05-17
区域经济评论(2015年4期)2015-12-21
中国卫生(2015年10期)2015-11-10
中国卫生(2014年12期)2014-11-12
