
融合时间上下文的改进协同过滤图书推荐模型
2021-03-15 05:25王子岚
科技风 2021年3期
关键词:协同过滤

摘 要:针对传统的协同过滤推荐算法在高校图书推荐场景中存在缺乏显性评分、推荐精度低等问题,提出一种融合时间上下文的改进协同过滤图书推荐模型。基于图书历史借阅记录,首先构建基于借阅时长的读者—图书偏好度模型,将读者历史借阅记录中隐含的借阅偏好信息转换成显性的读者—图书评分;然后考虑读者借阅偏好随时间动态变化因素,引入时间衰减因子对读者—图书评分模型进行修正,最后应用隐语义模型进行个性化图书推荐。
关键词:时间上下文;协同过滤;图书推荐
随着高校图书馆藏图书资源的日益增长,面对海量馆藏图书,读者常常陷入图书信息过载难题[1]。现有的高校图书借阅系统中仅提供基于信息检索的服务,缺乏个性化图书推荐模块,但同时系统中累积的大量借阅记录隐含着读者的借阅偏好,具备了个性化图书推荐的数据基础。因此,如何利用好这些借阅记录,挖掘读者借阅偏好并进行个性化图书推荐,是当下图书推荐亟待解决的问题。高校图书馆中图书数量远大于读者数量,基于图书内容的推荐算法不适用[2]。在高校图书推荐场景中,现有的研究主要是在用户协同过滤推荐算法[3]上加以改进,该类算法仅基于目标读者的近邻相似读者进行推荐,且在读者借阅记录稀疏的情况下推荐精度较低。同时该方法默认读者偏好不会随时间推移而变化,而实际上读者在不同时间段的借阅偏好是动态变化的。基于以上分析,本研究从以读者历史借阅记录出发,选择在Netflix Prize大赛中脱颖而出的隐语义模型(latent factor model,LFM)[4]作为基本算法,考虑读者借阅偏好动态因素,融入时间上下文以提高推荐精度。
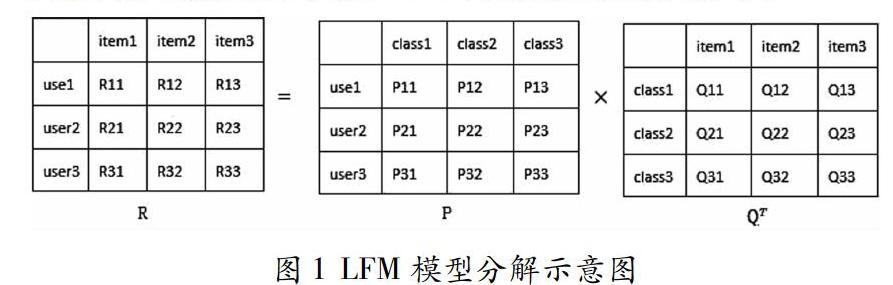
1 LFM模型
LFM模型是时下最主流的协同过滤推荐算法,是一种基于模型的协同过滤算法。其主要原理是找到用户和项目之间的关联,并基于此构建用户兴趣偏好进行推荐。如公式所示:
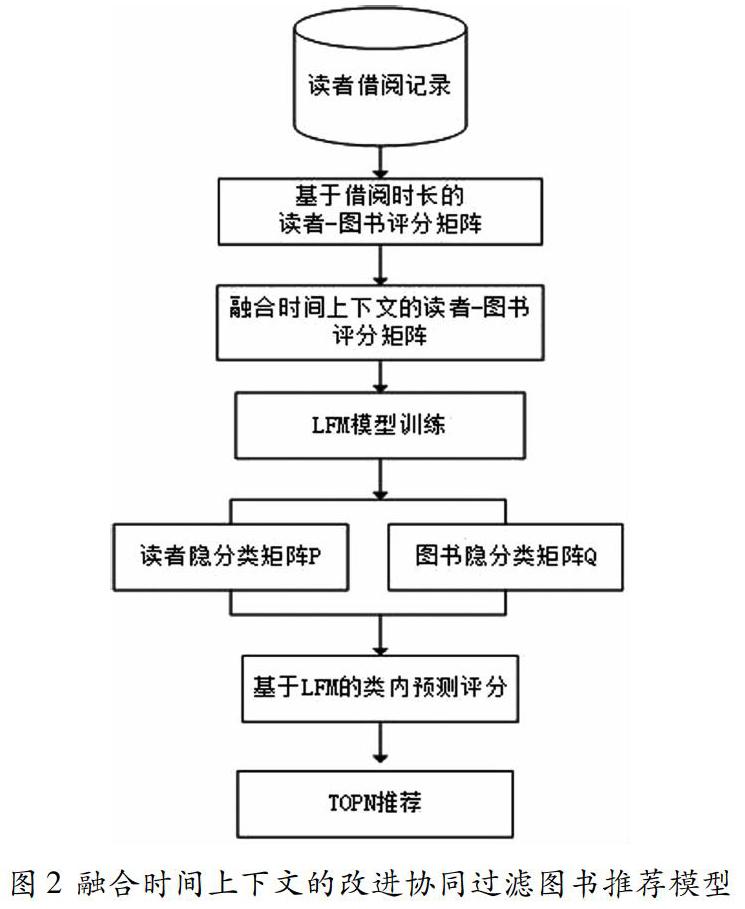
2 融合时间上下文的改进协同过滤图书推荐模型
2.1 基于借阅时长的读者—图书评分模型
协同过滤算法严重依赖评分矩阵,但现有的高校图书管理系统中缺乏评分模块,因此首先需要构建读者—图书评分矩阵。一般来说,读者借阅图书的时间越长,表示其对该图书的偏好度越高[6]。因此本文基于读者借阅记录,首先进行数据预处理,将借阅时间超期记录等数据作为噪声删除,得到读者—借阅图书的时长矩阵,同时考虑读者阅读习惯和图书借阅情况两个维度构建基于借阅时长的读者—图书评分模型,并加权得到基于借阅时长的读者—图书评分模型。
(1)考虑读者阅读习惯,构建读者—图书借阅时长的评分模型如下:
2.2 融合时间上下文的读者—图书评分模型
传统的协同过滤方法假定读者偏好是静态不变的,但实际上读者对借阅图书的偏好是会随时间变化的[7]。例如受学科及教学进度影响,学生在大一时会更偏好借阅基础课程的书籍,而大四的时候会更偏好借阅考研或就业类书籍。以读者编号为21800300125的读者为例,由于准备计算机二级考试,他在2018年10月10日至2018年12月17日借阅了图书《C语言程序设计》,借阅时长累计77天,按照公式(9)可得likeui1=0.9245,同时根据公式(10)可得likeui2=0.8946,加权可得likeui=0.9095,可见该读者对此图书的评分很高。但随着时间的推移,读者学习进度的推进,直接以该评分为该读者做当下这个时间的图书推荐显然并不恰当。因此,本文融合时间上下文,在原评分基础上引入时间衰减因子,对上一节中提出的基于借阅时长的读者—图书评分模型加以修正,進而得到融入时间上下文的读者—图书评分模型。
相对来说,读者最近借阅的图书更能代表其当前时间的借阅偏好,这与人们的遗忘规律是相类似的。很多研究者通过各种函数拟合了艾宾浩斯遗忘曲线,本文选用了最常用的牛顿冷却公式[8],得到时间衰减因子:
2.3 模型实现流程
基于以上研究,提出了一种融合时间上下文的改进协同过滤图书推荐模型,首先基于借阅时长构建读者图书偏好度模型,将读者历史借阅记录转换成读者—图书显性评分矩阵;然后考虑读者偏好度随时间的动态变化,融入读者还书行为的时间上下文,应用时间衰减因子作为权重对读者图书评分进行修正,得到修正的读者—图书评分矩阵;最后应用LFM模型对目标读者进行图书TOPN推荐。
步骤1:根据读者—图书借阅记录数据集,利用公式(11),将借阅记录中的读者隐含偏好信息转换成基于借阅时长的读者—图书评分矩阵;
步骤2:利用公式(13),融入时间衰减因子,将读者—图书评分矩阵转换为融合时间上下文的读者—图书评分矩阵;
步骤3:随机初始化得到读者隐分类矩阵P、图书隐分类矩阵Q;
步骤4:采用SGD进行LFM模型训练,得到的P、Q矩阵,进而得到读者u对图书i的基于LFM的预测评分;
步骤5:根据读者u的预测评分输出其TOPN本未借图书列表进行推荐。
3 小结
提出了一种融合时间上下文的改进协同过滤图书推荐模型。该模型的创新之处在于从读者和图书两个维度构建了基于借阅时长的读者—图书评分模型,并考虑读者借阅图书偏好度的动态变化,融合时间上下文进行修正,最后应用推荐精度高的LFM模型进行图书推荐。
参考文献:
[1]李薛剑,刘梦雅,海健强,吴雪扬,余雪莉.基于时间效应与隐语义模型的高校图书馆的个性化推荐研究[J].计算机应用与软件,2018,35(05):130-134+189.
[2]翁小兰,王志坚.协同过滤推荐算法研究进展[J].计算机工程与应用,2018,54(01):25-31.
[3]Hill W,Stead L,Rosentein M,et al.Recommending and evaluating choices in a virtual community of use[C].Priceedings of CHI95.
[4]王升升,赵海燕,陈庆奎,曹健.个性化推荐中的隐语义模型[J].小型微型计算机系统,2016,37(5):881-889.
[5]汪宝彬,戴济能.随机梯度下降法的收敛速度(英文)[J].数学杂志,2012,32(1):74-78.
[6]魏港明,刘真,李林峰,张猛.加入用户对项目属性偏好的奇异值分解推荐算法[J].西安交通大学学报,2018,52(05):101-107.
[7]梁思怡,彭星亮,秦斌,林伟明,胡振宁.时间上下文优化的协同过滤图书推荐[J/OL].图书馆论坛,1-11[2020-12-23].
[8]孙克雷,沈华理.基于用户多种关联信息和项目聚类的推荐算法[J].安徽理工大学学报(自然科学版),2018,38(05):57-64.
基金项目:2019年度安徽高校科学研究一般项目(项目编号:KJ2019H05);黄山职业技术学院2019年校级质量工程项目(项目编号:2019jxtd01)
作者简介:王子岚(1984— ),女,安徽黄山人,讲师,研究方向:计算机应用技术。
猜你喜欢
软件导刊(2016年12期)2017-01-21
软件(2016年4期)2017-01-20
计算机时代(2016年12期)2017-01-14
中国新通信(2016年22期)2017-01-13
软件导刊(2016年11期)2016-12-22
现代情报(2016年11期)2016-12-21
电脑知识与技术(2016年27期)2016-12-15
电脑知识与技术(2016年26期)2016-11-24
商(2016年29期)2016-10-29
电脑知识与技术(2016年20期)2016-08-19
