
基于随机森林的深圳二手房价格预测与分析
2021-03-13 14:38:43李函谕魏嘉银卢友军
现代信息科技 2021年15期
李函谕 魏嘉银 卢友军







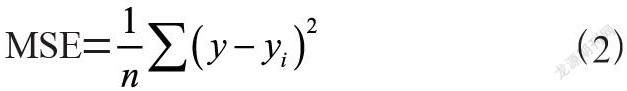


摘 要:针对深圳市二手房市场房价预测问题,结合相关的八个特征变量,利用随机森林模型训练房价预测模型。在研究过程中为使得模型准确率与泛化能力更高,使用交叉验证与网格搜索法,绘制学习曲线寻找最优参数,最后完成二手房价格预测模型的构建,预测精度达82.22%。结合相关政策,得出近年来深圳市二手房地产均价虽仍会上涨但总体较为稳定、且涨幅较小,以及近十年小户型的房源增量减少的主要结论。
关键词:网络爬虫;随机森林;深圳二手房价;网格搜索
中图分类号:TP311 文献标识码:A文章编号:2096-4706(2021)15-0100-05
Abstract: Aiming at the problem of house price prediction in Shenzhen second-hand house market, combined with eight relevant characteristic variables, the house price prediction model is trained by using random forest model. During the course of research, to improve the accuracy and generalization ability of the model, the cross validation and grid search method are used to draw the learning curve and find the optimal parameters, the construction of the second-hand house price prediction model is completed finally, and the prediction accuracy reaches 82.22%. Combined with relevant policies, it is concluded that although the average price of second-hand real estate in Shenzhen will still rise in recent years, it is generally relatively stable with a small increase, and the increase of house supply of small houses has decreased in recent ten years.
Keywords: web crawler; random forest; Shenzhen second-hand house price; grid search
0 引 言
房产作为如今经济社会的主要经济支柱,不管是用于刚需居住还是用于理财投资,对于国人的影响意义深远,对购房者而言,房价是影响购房者决策的重要因素[1]。从不同角度对房价变化趋势的探索一直都是人们关注的热点问题。针对房价预测问题,高玉明、张仁津[2]等人通过遗传算法对BP神经网络进行改进,在贵阳市的房价预测中获得较高预测精度,但并未结合当地政策对房价进行定性分析;董倩、李伟[3]等人基于网络搜索房产交易信息,对16个城市建立了各自适应的房产指数预测模型,使得房产价格模型的时效性得到一定解决,但对于影响模型的最佳参数探究欠缺。本文从购房者角度出发,获取2020年深圳市3月与7月在售房产网站的不同维度二手房产数据,通过交叉验证下随机森林算法训练房产价格预测模型,再结合网格搜索找到使得模型泛化能力最佳的参数,通过均方误差(MSE)与拟合优度(R2)对模型进行评估,同时结合相关政策与一定统计分析,辅助购房者综合各方面的因素进行科学决策。
1 数据准备
1.1 数据获取方式
房源数据的来源可以通过走访相关政府住建单位或通过中介等实地考察当地二手商品房的在售情况获取,但是用这种方式获取数据存在时间成本高、花费精力大、数据量少、效率低等缺点。随着信息技术的发展,人们越来越多地通过网络来获取相关的信息,在买卖二手房时也主要是通过网络来发布和获取数据。因此,在明确模型构建所需的特征后,对于房源数据的获取,本文通过网络爬虫技术来进行高效的自动化数据抓取。
1.2 主题数据确定
由于人们在购买二手房时,主要关注房源的小区、户型、面积、装修、朝向、建房年代、辖区、总价这八个基本属性,而这些属性也正是现在的二手房交易网站均有提供的信息,于是本文将其作为主要的数据爬取目标。本文从某房产网站上爬取三月份与七月份总共2 940个样本数据用于模型的训练与预测,部分数据如表1所示。
2 数据预处理
为了对2020年深圳市二手房产特征进行分析,并建立房价预测模型,对于原始数据的预处理工作会直接影响模型结果的好壞,所以需要对数据进行预处理以提高数据质量[4],主要工作包括去重、空值处理、去冗余数据平滑噪声数据等。本文运用Python的数据分析工具Pandas和科学计算库Numpy对已爬取的数据进行预处理工作,主要完成了对爬取后的样本数据进行去重、缺失值填补、字符串的剪切、房屋建房年份离散化以及对类别特征进行独热编码工作等,此时数据清洗工作基本完成。
3 深圳市二手房价预测回归模型
准备好数据之后,接下来尝试运用随机森林回归模型来建立二手房价的预测模型,以期能够辅助购房者做出更有科学依据的购房决策。
3.1 随机森林
随机森林(random forest, RF)是一种具有代表性的集成算法,它以多棵相互独立的决策树作为基评估器,通过集成各个决策树的建模评估结果,运用平均或多数表决原则,可随机地生成几百个至几千个分类树,然后选择重复程度最高的树作為最终结果,同时该算法对多元共线以及数据离群值并不敏感,适用于房产价格这种波动较大的数据[5-6]。
3.2 房价预测模型及评估
scikit-learn(简称sklearn)是基于Python的机器学习模块,提供了常用的分类、回归、降维和聚类等机器学习算法实现,可以直接运用于模型训练。本文运用sklearn来进行模型的训练和评估。
3.2.1 模型训练
对于本文的研究,数据源为已经处理好的数据,被解释对象即预测特征为房屋总价(total_price)。在建模的过程中,首先调用sklearn模块中的RandomForestRegressor函数对数据在默认参数下进行10次交叉验证的模型训练,其次调用cross_val_score函数以计算模型的拟合优度与均方误差,最后将建立的模型与支持向量机(support vector machine, SVM)模型进行对比以验证所建立模型的有效性。随机森林模型构建的关键代码如下:
rfc=RandomForestRegressor( random_state=90)
R2=cross_val_score(rfc,X,y,cv=10,scoring=’r2’).mean()
MSE=cross_val_score(rfc,X,y,cv=10,scoring=’neg_mean_squared_error’).mean()
3.2.2 模型评价指标
对于回归模型而言,cross_val_score结果可输出为模型预测的拟合优度(R2)与均方误差(MSE)以作为模型准确率与稳定性的评估,两个评估指标意义如下:
拟合优度(或决定系数)可以解释回归模型在多大程度上解释了被解释特征的变化,或者说回归模型对观测值的拟合程度如何,可以作为模型预测的准确性评价指标来评估回归模型的准确性。拟合优度(R2)的定义为:
均方误差(MSE)是指被预测值与样本真实值之差平方的期望值。MSE是衡量平均误差的一种较为方便的方法,MSE可以评价数据的变化程度,MSE值越小,说明预测模型的稳定性也越好。均方误差(MSE)的定义为:
3.2.3 模型评估结果
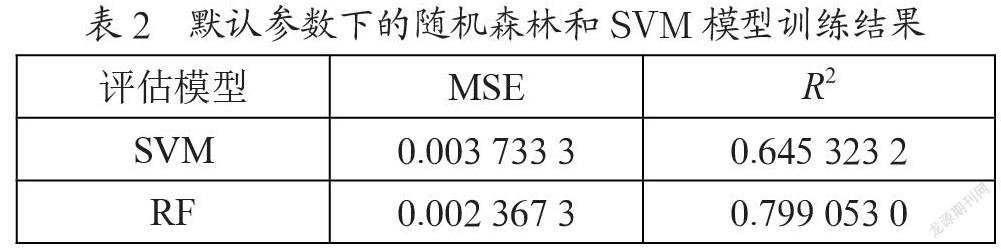
对于默认参数下的随机森林和SVM模型,其训练结果如表2所示。
从结果来看,随机森林决定系数接近0.8,说明了10次交叉验证下随机森林建立的房价预测模型模型能在80%的程度解释了二手房价的变化程度,相比SVM准确率更好;均方误差也表明该模型的稳定性较好,可见基于随机森林构建的房价预测模型更适用于预测深圳市二手房价格。为了避免模型在训练集上陷入过拟合或欠拟合的情况,需要进一步对模型的泛化能力进行评估与调整。
3.3 通过网格搜索模型最优参数
3.3.1 泛化误差与参数调整思路
泛化误差是指模型对未知数据的预测值的误差,其反映了模型的泛化能力。不管模型欠拟合或过拟合,泛化误差都会变大,当模型的泛化误差最小时,模型的复杂度最佳。随机森林属于树模型,树的深度越深,越易陷入过拟合从而使得模型复杂度增加。因此对模型参数的调整思路为使模型的泛化误差减小的同时使其复杂度接近最佳的模型复杂度。
3.3.2 网格搜索随机森林最佳模型参数
在构建随机森林模型时,对模型泛化能力有敏感影响的参数主要有评估器数量(n_estimators)、最大深度(max_depth)、叶节点最小样本(min_samples_leaf)数以及最大特征(max_features),其影响如表3所示。
参数对模型的影响趋势可以通过绘制学习曲线及其走势来判断,以评估器数量为例,通过设定1到200个评估器,绘制每次增加10个评估器的学习曲线,可以找到学习曲线中模型评分(R2)最高的大致范围,再继续缩小范围,即可找到最佳的评估器数量,对其余三个超参数也采用相同的方式,最终参数的学习曲线如图1所示。
根据学习曲线,对于最大深度max_depth,随着深度增加,模型的可解释率增加后趋于稳定,对准确率影响不大,但模型的泛化误差变大;对于最小叶子节点数min_samples_leaf,增加每个叶子节点的数量也会使得模型的可解释率降低,所以对以上两个参数,将其设置为默认值即可。对其余两个参数可观察曲线找到准确率的最高值,最终对各个超参数进行调整后模型的准确率可达82.22%,相比寻优前提升了2%,此时模型接近最佳复杂度,泛化能力最好,最优参数如表4所示。
4 模型解释与特征定性分析
对普通读者而言,由数据分析构建得到的模型是难以理解的,为增加可解释性,可以通过绘制相应的可视化图形,以使读者能直观地理解模型本身的含义。
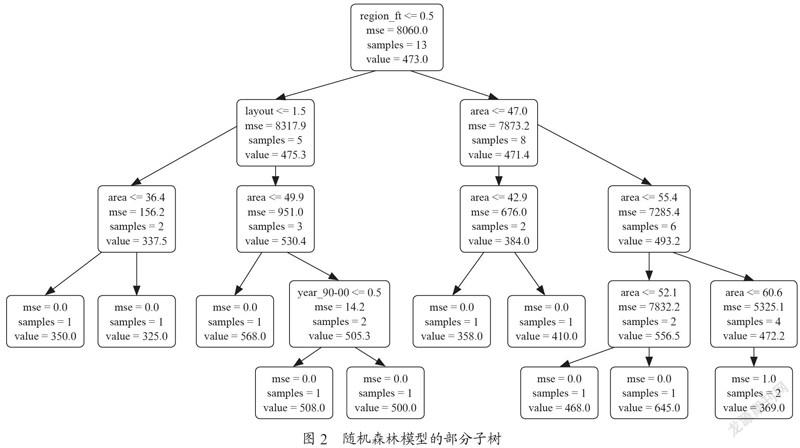
本文根据前述构建的随机森林模型通过Graphivz软件来绘制相应的可视化树图,由于随机森林模型的分支很多不便于解释,此处只选取其中一颗子树的部分分枝来阐述,如图2所示。由图2知,该决策树分支以福田区作为主要分裂条件来对该节点包含的13个样本进行分裂,根据面积、户型等不同的决策条件最终对每个子节点进行了预测。
为进一步观察各特征对于购房决策影响的重要程度,可以绘制相应的柱形图,如图3所示,从图中可知对模型影响最大的特征为房屋面积(area),影响程度达0.6。
为验证模型的拟合效果,可以通过绘制模型的预测值-真实值散点图,如图4所示,图中的点线为预测值与真实值相等的理想预测直线,由图可见散点靠拢理想效果直线,表明预测效果比较理想。
对于不同辖区房价的分布情况,可以绘制相应的均价箱线图以清楚地展示各辖区房源价格的总體分布,如图5所示。对于各年代房源的分布情况可以绘制小提琴图直观地呈现不同年代房源的存量与总价分布情况,如图6所示。
根据图5可知,深圳市二手房龙岗区[7]的房价最低,但是在售房源最多,投资属性强,适合做理财投资,而随着经济下行的压力越大,交易量必定会受影响。南山区均价最高,主要因为南山区科技企业多,常住人口高,地段好,所以对房源的需求量大,而豪宅税的调整[8-9]会促使更多人参与买房,所以至少2020年深圳市二手房房价还会上涨。随着新型冠状病毒疫情的蔓延与控制,使得人们的居住愿望变强[10],所以房价仍在上涨,但是7月的调控新政策减小了房价上涨的势头,严格控制了涨幅,使得房价回归在稳定的趋势。
根据图6可知,深圳市房地产2010—2020年的二手房源量较少,在售二手房源的修建年份主要集中在2000—2010年,房龄较大,近10年的新房量少是导致如今二手房增量少的主要原因。
根据以上结果,可以对二手房价格有一个基础的认知,然后再结合深圳购房政策变化、税收等因素,便能从不同角度观察和发现深圳市二手房特点[11-12]。
5 结 论
在本文的研究中,首先对深圳二手房产数据进行爬取,利用Python各功能模块对原始数据进行预处理,运用随机森林算法建立房价预测模型并寻找最佳模型超参数,获得显著的精度,与SVM模型的对比结果表明,本文的预测模型在准确率与稳定性方面都更好;然后,对模型进行了可视化解释并结合当时的实际政策对二手房特征进行定性分析;最后实现了房价预测模型稳定性与泛化能力的有效结合,为有购房需求的人提供了相应的决策依据。
参考文献:
[1] 张智鹏,郑大庆.影响区域房价的客观因素挖掘分析 [J].计算机应用与软件,2019,36(11):32-38+85.
[2] 高玉明,张仁津.基于遗传算法和BP神经网络的房价预测分析 [J].计算机工程,2014,40(4):187-191.
[3] 董倩,孙娜娜,李伟.基于网络搜索数据的房地产价格预测 [J].统计研究,2014,31(10):81-88.
[4] 刘馨,张卫军,石泉,等.基于数据挖掘与清洗的高炉操作参数优化 [J].东北大学学报(自然科学版),2020,41(8):1153-1160.
[5] ANTIPOV E A,POVSKAYA E B. Mass appraisal of residential apartments:An application of Random forest for valuation and a CART-based approach for model diagnostics [J].Expert Systems with Applications,2012,39(2):1772-1778.
[6] 顾桐,许国良,李万林,等.基于集成LightGBM和贝叶斯优化策略的房价智能评估模型 [J].计算机应用,2020,40(9):2762-2767.
[7] 百度百科.深圳市行政区划 [EB/OL].[2021-04-23].https://baike.baidu.com/item/%E6%B7%B1%E5%9C%B3%E5%B8%82%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92/18655114?fr=aladdin.
[8] 深圳市规划和国土资源委员会.深圳市安居型商品房定价实施细则 [EB/OL].(2017-12-17).http://www.sz.gov.cn/slhwz/zcfg/content/post_9177804.html.
[9] 深圳市司法局.深圳市房地产市场监管办法(修订征求意见稿) [EB/OL].(2020-10-22).http://sf.sz.gov.cn/hdjlpt/yjzj/answer/7097#feedback.
[10] 陈兴蜀,常天祐,王海舟,等.基于微博数据的“新冠肺炎疫情”舆情演化时空分析 [J].四川大学学报(自然科学版),2020,57(2):409-416.
[11] 张望舒,马立平.城市二手房价格评估方法研究——基于Lasso-GM-RF组合模型对北京市二手房价格的分析 [J].价格理论与实践,2020(9):172-175+180.
[12] CHEN L J,YAO X J,LIU Y L,et al. Measuring Impacts of Urban Environmental Elements on Housing Prices Based on Multisource Data-A Case Study of Shanghai,China [J/OL].ISPRS International Journal of Geo-Information,2020,9(106):1-23.
作者简介:李函谕(1996-),男,苗族,贵州贵阳人,硕士研究生在读,研究方向:统计建模与分析、大数据处理与分析;魏嘉银(1986-),男,汉族,福建三明人,副教授,硕导,博士,研究方向:算法设计与分析、大数据处理与分析;卢友军(1985-),男,汉族,贵州遵义人,硕导,博士,研究方向:复杂网络。
3169500338292
猜你喜欢
安徽农学通报(2017年1期)2017-02-15 17:49:06
软件(2016年7期)2017-02-07 15:54:01
南水北调与水利科技(2016年6期)2017-01-06 13:43:27
中国新通信(2016年21期)2017-01-06 13:36:11
电脑知识与技术(2016年23期)2016-11-02 23:25:12
电脑知识与技术(2016年20期)2016-08-19 19:30:39
电脑知识与技术(2016年17期)2016-07-23 19:00:29
中国市场(2016年23期)2016-07-05 04:35:08
电脑知识与技术(2016年7期)2016-05-19 14:02:36
现代电子技术(2015年15期)2015-08-14 21:28:48
