
基于社交媒体大数据的大学生情感分析研究*
2021-03-12 05:25黄静玉李彤彤李坦郭栩宁葛慧欣
中国教育信息化·高教职教 2021年2期
黄静玉 李彤彤 李坦 郭栩宁 葛慧欣
摘 要:对大学生特定时间的社交媒体评论文本进行情感倾向分析,不仅可以帮助教师更好地了解该群体的情感特点,还可以为有关部门针对该群体的决策提供科学参考。文章采用SVM、KNN、DT和NB四种机器学习算法分别构建情感分类模型,同时采用查准率P、召回率R和F值作为评估指标对情感分类模型进行对比,最终选择SVM模型对157名大学生2019年1月至2020年2月期间的13048条微博文本数据进行了情感分析。研究结果表明,负向情感出现的时间段集中在2019年11月和2020年1至2月。在这两个时间段内,研究群体更关注“军训”“期末”“疫情”等事件,由此,学校管理者可针对这些话题或事件进行有针对性的干预,从而在一定程度上缓解学生的负向情绪,保障大学生的心理健康。
关键词:大学生;情感分析;社交媒体;大数据
中图分类号:G434 文献标志码:A 文章编号:1673-8454(2021)03-0052-05
一、引言
随着互联网的普及,微博、朋友圈、知乎等社交媒体平台为广大网民获取信息、发表观点提供了新的途径。人们会对事件、人物、产品等相关内容发表带有个人情感倾向与情感色彩的文本评论信息,这些主观性的文本信息往往蕴含着巨大的价值。企业通过挖掘并分析购物网站上商品客户评论中蕴含的情感倾向和态度,不断调整和改善自己的销售策略以优化消费者的购物体验,从而提升企业实力。通过对此类文本信息进行情感倾向分析,可以及时获取公众对特定事件的价值观点与情感倾向,帮助有关部门准确把握舆论发展趋势并辅助其进行决策分析,从而更有效地干预和引导舆论方向。
2019年发布的《第44次中国互联网络发展状况统计报告》显示,受过大学专科、大学本科及以上教育的网民群体占比分别为10.5%、9.7%。大学生是网民群体的重要组成部分,并且大学生们热衷于在社交媒体平台发布自己的意见、看法[1]。通过对特定时间大学生的社交媒体评论文本进行情感分析,不仅可以帮助我们更好地了解该群体的情感特点,情感分析结果也可以为有关部门针对该群体的决策提供参考。
本研究基于SVM、KNN、DT和NB四种算法,分别构建情感分类模型。采用查准率、召回率和F值作为评估指标对情感分类模型进行评估,发现基于SVM算法的情感分类模型表现优于其他三种算法模型。本研究采用SVM算法构建的情感分类模型,对天津某大学学生2019年1月至2020年2月发布的微博文本进行情感分析,关注不同时间段、不同事件背景下用户的情绪反映,以期为相关高校管理部门提供及时有效的反馈。
二、研究设计
1.概念界定
(1)社交媒体
社交媒体,也被称为社会媒体,是能够支持人们写作、分享、评论、讨论和交流的网站和技术[2]。社交媒体是建立在互联网技术,特别Web2.0技术基础之上的互动社区。社交媒体赋予每个人创造并传播内容的能力,是用来进行社会互动的媒体,是一种通过无处不在的交流工具进行社会交往的方式。它能够给予用户极大的参与空间,不仅能够满足网民个人基础资料存放的需求,更重要的是能够满足用户“被人发现”和“受到崇拜”的心理感受需求,以及用户“关系建立”和“发挥影响”的需求[3]。大学生热衷于在社交媒体平台发布自己的意见、看法[1],社交媒体上的文本数据一定程度上能够真实地反映大学生的情感状态。社交媒体种类繁多,本研究以社交媒体中的主流媒體“微博”为例展开研究。
(2)文本情感分析
文本情感分析,又被称为观点识别、意见挖掘等,是指对文本中的观点、情感极性、主客观性进行识别、提取、分类、归纳及推理的分析过程[4]。其中,情感分类应用最为普遍,其主要任务是对主观性文本进行情感分类[5]。
国内外对于情感的划分较为普遍的观点有以下几种:有些研究将情感分为积极情感、消极情感两类;有些研究将情感划分为积极、消极和中立三个类别[6];有些研究为了表达情感的强度将情感分为五级,0为最大消极情感,4为最大积极情感[7];也有研究根据人们的情绪表达将情感划分为“快乐、悲哀、褒扬、贬斥、信心和意外”等类型[8]。本研究采用了二维分类:正向情感与负向情感。正向情感指代积极情感,负向情感指代消极情感。
情感分析最常用的方法是机器学习方法和情感词典法。相较于情感词典法,机器学习方法不需要过多人工干预和成本投入,偏差更小[9],并且在更新速度上占据一定优势[10]。本研究采取机器学习的有监督算法构建情感分类模型,对微博文本进行情感倾向分析。
2.研究思路
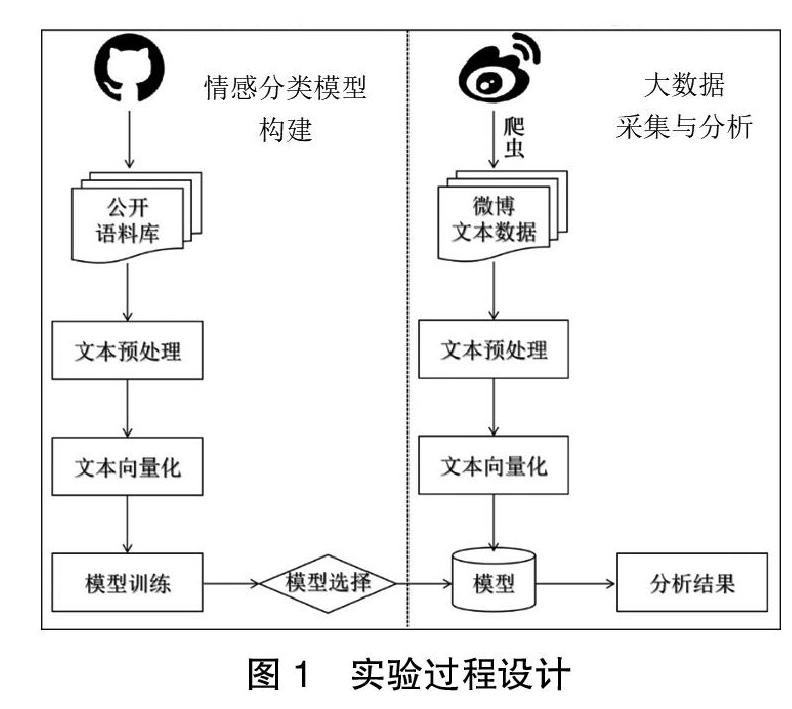
本研究实验思路如图1所示,主要分为两个部分。第一部分是情感分类模型的构建,是将公开语料库划分为训练集与测试集,对测试集部分进行文本预处理、文本向量化,然后调用算法函数训练情感分类模型。通过对当前机器学习的主流算法进行模型查准率、召回率和F值比较,选取分类效果最佳的模型。第二部分是大数据的采集与分析,通过爬虫技术爬取微博中相关用户的信息数据并依次进行文本预处理和文本向量化,然后运用情感分类模型对信息数据进行分析。
三、情感分类模型构建
1.实验数据集
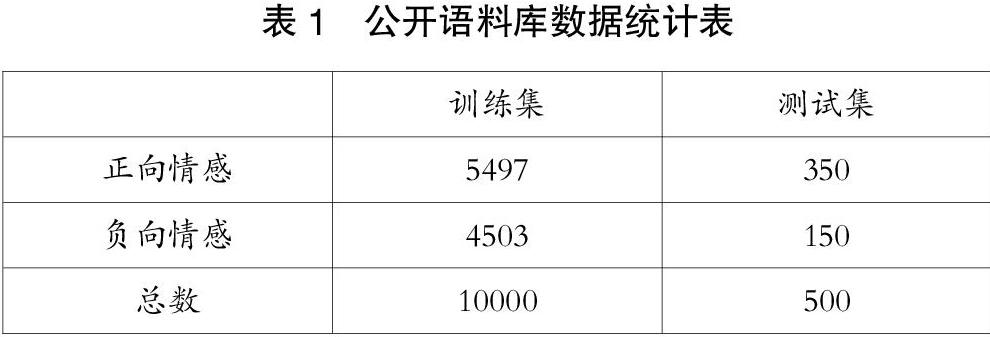
本实验采用代码托管平台“github”上的公开语料库进行模型训练。该语料库是对一些评论进行正负情感标注的数据集合,其建设时间较新,在数据标注期间采取多人核验保证数据质量。将该语料库划分为训练集和测试集两个部分。训练集用于对情感分类模型的训练评估;测试集用于检验构建的模型能否准确得出正确分类标签。公开语料库的具体情况如表1所示。
2.预处理
对文本数据进行预处理,使计算机识别自然语言形式的语料[11]。常见的预处理包括以下内容:①信息抽取,去除文本含有的“噪声”。②将提取出来的有用数据借助已有的分词工具进行中文分词。③借助已有的停用词词典,过滤掉文本中的停用词,降低停用词对分析结果的影响[12]。本研究主要使用预处理技术的分词处理与去停用词处理。使用北京理工大学研发的分词工具“NLPIR”对采集到的微博文本数据进行分词处理;使用哈尔滨工业大学停用词词库去除干扰实验的停用词。
3.文本向量化
文本向量化即通过算法模型将文本转化为一系列能够表示文本的语义向量,研究中通常是以词为基本单位进行文本向量化。数据容量的大小能够直接影响算法模型的准确性、计算效率、计算时间等多个方面性能。文本向量化不仅在提高模型效率、减少计算时间、减少空间维度发挥着重要作用,同时也是提高算法性能至关重要的一环。
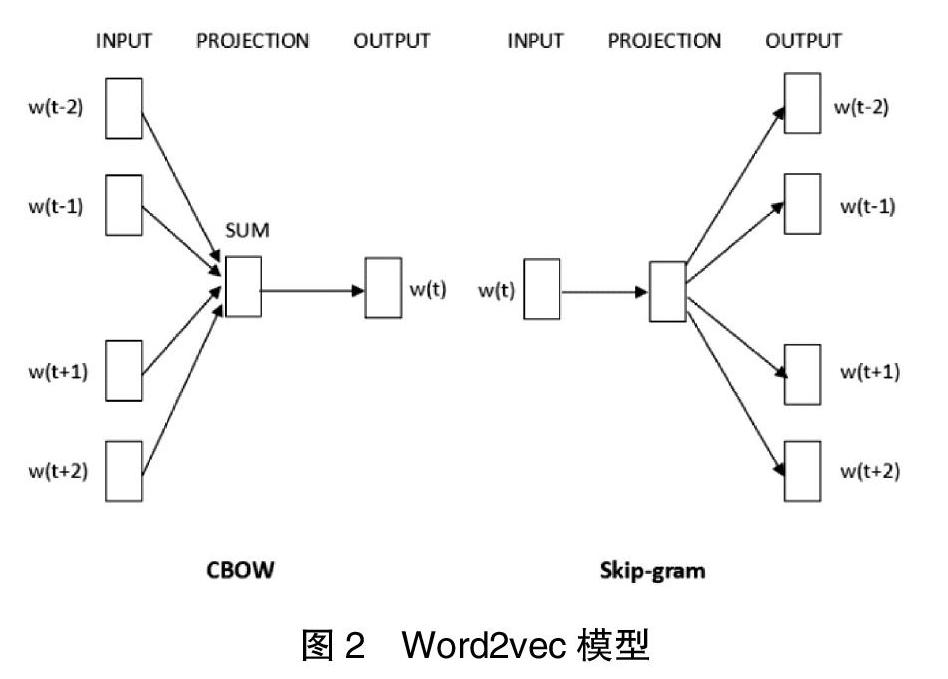
本研究使用了Google公司2013年提出的生成词向量的神经网络算法“Word2vec”[13]。该算法通过给定对语料库的学习,可以生成维度不同的词向量空间。该算法是基于上下文对词语进行分析处理,因而能够达到本文需要达到的情感倾向性分类目的。这些词向量可被放置于各类 NLP的计算任务中[14]。“Word2vec”采用的模型有CBOW和Skip-gram两种,如图2所示。两者的组成部分均有输入层、投影层和输出层。CBOW模型的原理是根据位于当前词前后的词语来预测出当前词语,而Skip-gram模型是以词向量空间中的当前词语来预测位于其前后的词语。
在此基础上,采用“Word2vec”中的Skip-gram方法对训练集中的文本数据进行词语向量化,使得每个词都有特定的数值来代表其特征,构建了特征空间。Skip-gram方法主要是以词向量空间中的当前词语来预测位于其前后的词语,为模型训练打下基础。
4.模型构建
当前机器学习的主流算法有支持向量机算法(SVM)、K临近算法(KNN)、决策树算法(DT)、朴素贝叶斯法(NB)等。
SVM算法一般来说可用于线性分类与非线性分类,其最重要的任务是选择最优的决策边界,能够实现得到的两类数据点之间距离最大化分割的直线。在二维空间中,决策边界就是一条直线,将特征空间划分正类与负类。但现实中很多数据分布是非线性的,可以借助核函数将二维数据空间向高维转化,从而可以找到一个决策平面将不同类别的数据点距离最大化分割[15]。SVM最大的优势是能够在计算机性能欠缺、样本数不高的情况下取得不错的结果。
KNN算法是经典的文本分类算法,其基本过程是将训练样本映射成空间中的点,再计算相似度,按照计算结果进行排序,找出训练集D中与待分类文本x相似度最高或距离最近的k个文本。根据找出的k个文本的分类结果来对待分类文本x进行判定[16]。在樣本数据集大或训练样本分布不均匀的情况下,分类的准确度会受到影响[17]。
DT算法所用的DP矩阵可以基于抽象层次的结果及统计意义的度量层次结果来建立。但是当面临样本类别较多或训练样本数量较少的情况时,通常很难做出准确的估计。
NB算法由概率论中的贝叶斯公式得来,具有实现简单、计算高效等优势。贝叶斯算法本身具有增量学习的特性,可有效降低学习算法的复杂性。但数据增长的爆炸式趋势限制了该算法的可扩展性和泛化性[18]。
将经过预处理及文本向量化的训练集数据,分别使用前文介绍的SVM、KNN、DT、NB算法调用已有库函数编写相应的算法程序,逐条读取训练集中的数据,对数据及其蕴含的情感倾向进行学习,分别构建了四种算法所对应的情感分类模型。
5.模型选择
本研究采用的模型需要通用评估标准评价和衡量其效率。目前通用的文本分类评估标准有查准率、召回率(也叫查全率)和F值等。
(1)查准率P
准确分类的测试组与该类数据总和之比的百分化,具体计算方法如公式1。
p=■公式1
其中,x代表某类一个测试组分类正确的样本个数;C代表某类数据总和;P代表查准率 Precision。
(2)召回率R
从被分类领域中,召回目标类别的比例,具体计算方法如公式2。
R=■公式2
其中,m代表标签“1”数据的总数;x代表分类器预测标签为“1”的正确样本个数;R代表查全率 Recall。
(3)F值
P和R指标有时候会出现互相制约的情况。P值和R值不可能同时正增长,这样就需要综合考虑它们。最常见的方法就是F-Measure(又称为F-Score,简称F值)。F值综合反映整体的指标,由上面得到的 P 与 R 进行加权调和,具体计算方法如公式3。
F1=■公式3
在具体评估过程中,查准率与召回率有一定的制约关系。查准率、召回率和F值的值越高,模型越有效。
本研究构建的四种模型分别对经过文本预处理及文本向量化的测试集进行情感倾向判定,即正向情感标记为“1”,负向情感标记为“-1”。使用程序分别统计分类器将输入文本正确地分类到某个类别的个数、错误地分类到某个类别的个数、错误地排除在某个类别之外的个数、正确地排除在某个类别之外的个数。采用查准率、召回率和F值等评估标准对构建的情感分类模型进行评估,结果如表2所示。可以发现,SVM、KNN、DT、NB等四种算法构建的分类模型分析效率相对较高,其中SVM算法的P、R、F三个标准的值均为最高。因此,本研究最终选择SVM算法构建的情感分类模型进行情感倾向分析。
四、基于微博文本大数据的情感分析
1.数据采集
本研究追踪了半年内曾定位在天津师范大学的账户204个,并人工筛选获取157名学生的ID。使用“github”上公开的新浪微博爬虫程序,通过不断更新config.json中的学生ID列表,再利用Spyder执行weiboSpider.py程序来爬取已知微博ID学生2019年1月1日至2020年2月29日的微博文本。
本次爬取微博数据取得了较好的结果。共计爬取157名学生的13048条数据,分别存放在157个CSV文件中。其格式如表3所示,主要由微博ID、正文、发布时间、位置、点赞数等组成。文本及发布时间作为本文主要的实验数据。
2. 数据分析
本研究对2019年1月至2020年2月期间157名学生的13048条文本数据进行分词、去停用词等文本预处理及文本向量化,选择基于SVM算法的情感分类模型对其情感极性进行了分类。本研究使用SVM算法构建的情感分类模型对实验数据集进行情感倾向判定。输出判定结果为“-1”的文本,即负向情感文本;输出判定结果为“1”的文本,即正向情感文本。统计结果如下。
(1)正负向情感文本数量统计
首先,本研究对正负情感的文本以月份为单位进行了数量统计,结果如表4所示。可见,每个月份正向文本的数量均明显多于负向文本,表明该校学生在微博社交媒体平台上发布的文本在情感倾向上相对偏正向。
(2)负向情感文本比例分布情况
其次,本研究对每个月份负向情感所占比例进行了分析,结果如图3所示。可以发现,2019年1月的群体负向情感比重最小,2019年9月的群体负向情感比重最大。
(3)负向情感文本时间序列分布情况
再次,本研究对负向情感文本的时间序列分布情况进行了分析,以时间为横轴,负向情感文本数目为纵轴,绘制出负向情感文本数量时间序列分布图,如图4所示。2019年9月至2020年2月时间段的负向情感文本数量相对于2019年1至8月时间段更高,尤其是在2019年9月及2020年1至2月负向情感文本数目急剧增长。因此,本研究推测研究群体的负向情感与相应时间段发生的社会事件存在某些关联。
(4)负向文本内容分析
本研究按照时间段对负向文本内容进行了分析与讨论。在2019年9月期间,负向情感和正向情感文本内容中,“军训”出现的频率都比较高,推测研究群体在这个时间段对“军训”的关注度较高。2019年11月,负向情感文本内容中,“课业”“考研”“学生会”三个话题出现的频率较高,说明这三个话题可能与研究群体在这一阶段的负向情绪有关联。相比之下,“课业”“考研”“学生会”在同一时间段正向文本中出现的频率较低。由此推测,在这个时间段内,“课业”“考研”“学生会”对于研究群体的负向情感有直接影响。2020年初的负向文本内容中,“期末”“疫情”这两个话题出现的频率较高,话题与学生负向情绪出现的时间段基本吻合,推测研究群体在这个时间段的负向情绪与“期末”及“疫情”事件有一定程度的关联。
研究群体在社交媒体上表现出的情感倾向整体偏于正向,而负向情感倾向所占比例较小。负向情感比较集中的时间段主要有两个,即2019年9月与2020年初(1月和2月)。在这两个时间段中,学生比较关心的事件分别是“军训”“期末”“疫情”。其中“疫情”为突发事件,而“军训”“期末”是该群体比较普遍的话题。这表明该群体除日常生活以外,也会关注社会事件。
五、结语
本研究构建了基于SVM算法的情感分类模型。利用该模型对采集到的文本数据进行情感分类,得出负向情感出现比较集中的时间段及期间发生的相关事件。针对产生负向情感的话题,学校相关管理部门可以针对性地采取一些措施来缓解学生的负向情绪。例如:一方面,针对该群体的军训和期末考试等日常生活,可以适度组织心理培训,培养学生应对大学生活的积极心态;组织关于专业学习的讲座,增强该群体的学习兴趣和专业信心;开展具有积极意义的团日活动,帮助该群体树立理想信念;积极开展体育锻炼活动,帮助学生增强体魄等。另一方面,面对类似“疫情”等突发社会事件,有关管理部门应该高度关注学生群体的心理状况,积极开展心理健康教育培训,提升学生心理抗压能力;针对突发事件,加大相应的防控知识普及力度。
参考文献:
[1]刘世权.中华优秀传统文化在高校中的传播路径研究——基于社交媒体大数据视角[J].重庆科技学院学(社会科学版),2018(6):104-106.
[2]孟恒玥,闫水华,尹永奎.移动互联网社交媒体使用行为对大学生社会化行为的影响及策略研究[J].中国市场,2020(11):190-191.
[3]曹博林.社交媒体:概念、发展历程、特征与未来——兼谈当下对社交媒体认识的模糊之处[J].湖南广播电视大学学报,2011(3):65-69.
[4]杨鑫,杨云帆,焦维等.基于领域词典的民宿评论情感分析[J].科学技术与工程,2020,20(7):2794-2800.
[5]杨立公,朱俭,汤世平.文本情感分析综述[J].计算机应用,2013,33(6):1574-1607.
[6]Li S T, Tsai F C. A Fuzzy Conceptualization Model for Text Mining with Application in Opinion Polarity Classification[J].Knowledge-Based Systems,2013(39):23-33.
[7]Socher R, Perelygin A, Wu J Y, et al. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank[C].Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing,2013:1631-1642.
[8]杨小平,张中夏,王良等.基于Word2Vec的情感词典自动构建与优化[J].计算机科学,2017,44(1):42-47.
[9]V. Ha-Thu, J. Renders. Large-scale hierarchical text classification without labeled data[C].Proceedings of the fourth ACM international conference on Web search and data mining. ACM, New York, USA,2011:685-694.
[10]A. Kennedy, D. Inkpen. Sentiment classification of movie reviews using contextual valence shifters[J].Computational intelligence,2006,22(2):110-125.
[11]沈芬.基于SVM的電商评论文本情感倾向性分析[D].秦皇岛:燕山大学,2019.
[12]刘家锋,赵巍,朱海龙.模式识别[M].哈尔滨:哈尔滨工业大学出版社,2014:51-55.
[13]Mikolov T,Chen K, Corrado G,et al. Efficient estimation of word representations in vector space[J].Computer Science,2013(1):47-61.
[14]Zhang D,Xu H,Su Z,et al.Chinese comments sentiment classification based on word2vec and SVMperf[J].Expert Systems with Applications,2015,42(4):1857-1863.
[15]李苍柏,肖克炎,李楠等.支持向量机、随机森林和人工神经网络机器学习算法在地球化学异常信息提取中的对比研究[J].地球学报,2020(2):309-319.
[16]刘述昌,张忠林.基于中心向量的多级分类KNN算法研究[J].计算机工程与科学,2017,39(9):1758-1764.
[17]王志华,刘绍廷,罗齐.基于改进K-modes聚类的KNN分类算法[J].计算机工程与设计,2019,40(8):2228-2234.
[18]韩素青,成慧雯,王宝丽.三支决策朴素贝叶斯增量学习算法研究[J].计算机工程与应用,2020(3):15-16.
(编辑:王晓明)
