
基于SPSS的高校学生一卡通数据实证分析
2021-03-11 14:08:22郑海鹏
黑河学院学报 2021年1期
郑海鹏
(淮南联合大学 信息工程学院,安徽 淮南 232001)
高校一卡通系统中存储了海量的学生行为数据,这些数据整体上是杂乱无章的,无法真实有效地映射学生的实际行为特征。如能充分发掘这些数据背后的真正价值和意义,将会给高校的学生管理工作提供巨大的帮助。
目前,已有许多高校科研团队对高校一卡通数据展开了相关研究工作。张四海等[1]对南开大学师生食堂的消费数据进行了深入分析,给出了师生的就餐规律曲线,用于优化食堂的膳食资源配置。邢窈窈等[2]对学生校园卡刷卡行为进行分析,利用逐步回归法得出学生成绩排名的回归模型,提出提高学生成绩的实际举措;王祎珺等[3]对校园一卡通的图书馆学生学习行为进行详细分析,有效地获取了学生的学习行为现状。本文使用SPSS软件中的K-Means算法对学生用餐数据进行聚类,对聚类后的不同群体做其他行为分析。
1 淮南联合大学一卡通系统简介
淮南联合大学一卡通系统于2009年正式开通。在图书馆、学校食堂、超市、洗浴中心、校园门禁等场所中均已投放使用,系统集成度高,完美地融合了信息通信技术[4],实现了身份认证、数据共享、金融消费等多种功能[5]。给全校学生每天的生活提供了极为便捷的服务,加速了数字化、信息化管理的进程,切实提高了学校的科学管理水平,一卡通系统已成为学校不可或缺的核心业务系统[6]。
2 一卡通数据采集、预处理及建模
高校一卡通数据涵盖了学生在校内食堂、超市、洗浴消费场所及图书馆读书、借阅等相关记录,为便于对学生用餐行为数据进行聚类分析,需要对采集到的原始数据进行预处理,去除冗余及属性值无效或缺失的相关记录。
2.1 数据采集及导入
本文原始数据由淮南联合大学一卡通系统管理中心提供,所采集数据的真实及可靠性均能得到有效保证。(注:有极少量的学生学习成绩相关数据来自于学校的学工系统)将采集到的一卡通数据文件ecexpressquery.DMP导入到Oracle数据库中,具体操作如下:
(1)使用cmd命令打开命令提示符,输入sqlplus system/1211@orcl as sysdba;
命令,以管理员身份登录oracle数据库。
(2)创建表空间并指定其存储容量
创建一个表空间用于存放将要导入的ecexpressquery.DMP文件,输入命令:
create tablespace ecexpress datafile 'C:app Administratororadataorclecexpress.dbf' size 2048M;
(3)创建用户并指定默认表空间
创建一个用户用于管理将要导入的一卡通ecexpressquery.DMP文件,输入命令:
create user zhenghaipeng identified by 1211 default tablespace ecexpress;
(4)给创建的用户授权
输入命令: grant connect,resource,dba to zhenghaipeng; 授权zhenghaipenghp用户拥有连接、资源管理及管理员权限。
(5)将一卡通原始数据文件导入到Oracle数据库中
使用命令:imp zhenghaipeng/1211@orcl file= E:一卡通数据ecexpressquery.DMP full=y;
将ecexpressquery.DMP文件导入到Oracle数据库。
2.2 数据预处理
对导入的一卡通数据进行预处理,提取学生用户有效数据特征。是对学生用户数据进行聚类分析的必要前提。处理好这一环节至关重要,对后续研究的开展具有决定性作用,因此,需要慎重处理这一环节。
(1)使用Oracle数据库应用程序开发工具SQL Developer创建一个新的连接,连接名设置为“一卡通数据预处理”,使用用户zhenghaipeng、密码:1211进行连接登录,查看每个表的表结构及表中的记录,发现其中TTNSMFLWING表为所有一卡通用户的消费流水数据,共5 130 879条记录,如图1所示。
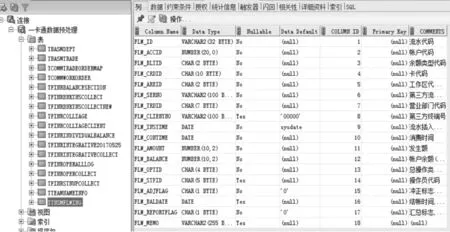
图1 一卡通消费流水数据表
(2)数据清洗。消费流水数据表中包含了学校行政管理人员、专任教师及学生等一卡通用户的相关数据。选取用户卡号在2000043243—2000046280之间的用户数据(这些卡号为2018级在校学生的校园一卡通卡号),创建Student_water数据表,获取2018级在校学生在2018—2019学年度的全年消费流水记录,表记录数由原来的513万条数据缩减至170万条,保留accid、amount、instime、trdid四个有效字段分别代表:用户卡号、用户单笔消费金额、用户刷卡消费的日期和具体时间、用户消费终端pose机id,其中pose机id表示对应的刷卡场所。
(3)数据分类。依据Student_water表中trdid字段对学生数据进行分类,打开TBASMIRADE表,查看trd_id字段,找出代表食堂、超市、洗浴、图书馆等场所的trd_id的相关字段值,分别创建食堂消费、超市消费、洗浴消费、图书馆阅读等数据表,存储学生相关数据记录。用以区分学生刷卡记录的不同场所。由于学生食堂消费表Canteen_water中包含了学生的三餐记录,需要进一步细化,将学生的就餐时间分为6:00—8:30、11:00—13:30、17:00—19:30等三个时段。用于区分学生早餐、午餐、晚餐消费记录。最终生成了Breakfast_water、Lunch_water、Dinner_water、supermarket_water、Wash_water、Library_water六个数据表。
(4)数据整合。上述操作完成后,需要对Breakfast_water等六个表的数据进行整合,比如:同一天学生早餐食堂刷卡记录可能有多次,但统计时只算一次早餐用餐行为。需要创建新表将Breakfast_water数据表中的卡号和日期相同的多条记录合并为一条记录,在合并的过程中需要将amount字段值(刷卡金额)进行累加,用于统计学生每次早餐消费总金额。在创建Breakfast_amount表后,所有学生的每日早餐用餐总金额已经确定,根据Breakfast_amount表中相同的accid字段值(学生卡号)出现的次数,来统计每位学生年度的早餐次数及年度早餐总额。经过一系列的数据整合后生成了Breakfast_times_amount、Lunch_times_amount、Dinner_times_amount、Supermarket_times_amount、Wash_times_amount 、Library_times六个数据表。对整合后的六个表进行合并操作(Breakfast_times_amount与Lunch_times_amount两表合并过程实例如式1所示,然后再依次合并其他表,在此不再累述)。
create table b_l_times_amount as select Breakfast_times_amount.⋆,
Lunch_times_amount.Lunch_times, Lunch_times_amount.Lunch_amount
from Breakfast_times_amount full join Lunch_times_amount on Breakfast_times_amount.accid=Lunch_times_amount.accid;(式1)
最终将Breakfast_times_amount等六个表合并生成了Student数据表,包含了每位学生年度的早餐次数、早餐消费总额、午餐次数、午餐消费总额、晚餐次数、晚餐消费总额、超市次数、超市消费总额、洗浴次数、洗浴消费总额、图书馆阅读次数共十一个字段。祛除student表中字段值缺失值及无效记录,得到了2 259条有效记录,即采集2 259名2018级学生的相关数据作为研究对象,并从学校学工系统中采集了上述2 259名学生2018—2019学年度期末考试成绩数据信息,依据学生的成绩排名,利用公式:学生成绩排名/班级总人数,得到学生成绩在班级的所处位置,(如该班级30人,学生成绩排名第5,则该学生成绩排名占比为16.66%,将成绩的占比划分为:前20%、21%—40%、41%—70%、71%—100%计做:1、2、3、4等四个等级,其中等级为1代表成绩优秀),最后依据student表中的trdid对应成绩占比表中的trdid字段将成绩占比表中的等级字段并入student表中,student表的相关信息,如图2所示。
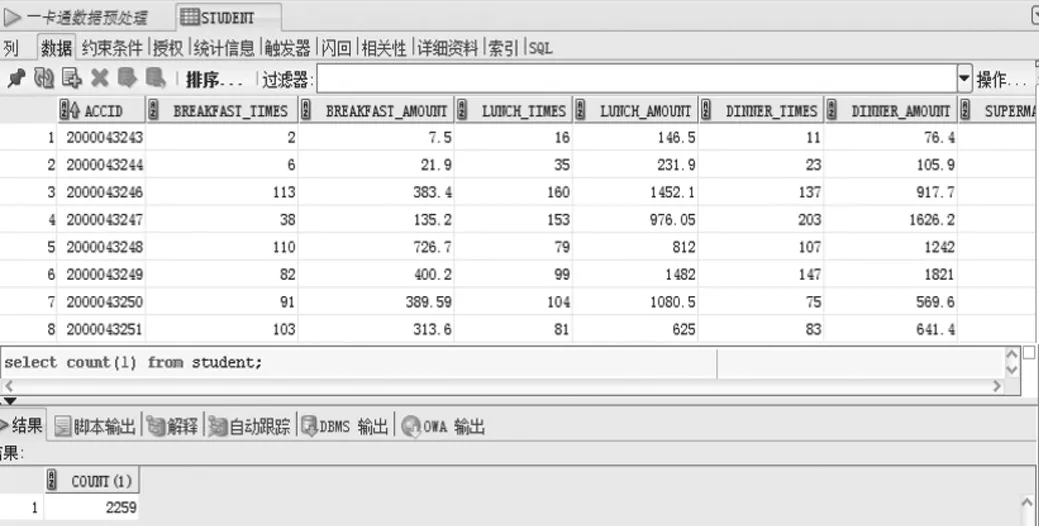
图2 student数据表记录截图及记录总数
2.3 数据建模
为便于数据处理,将Student表从Oracle数据库中导出,转换为同名的excel文件。将之存放到数据仓库中,对数据仓库中的数据集进行建模,采用SPSS软件中的K-Means算法进行聚类。并对聚类结果加以详细分析。整体过程如图3所示。
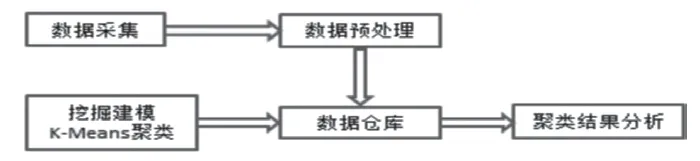
图3 数据建模
3 数据分析
3.1 学生一卡通数据整体情况
3.1.1 学生各项消费数据占比
依据2018级所有学生年度用餐的总额、超市消费总额、洗浴消费总额、各项消费占比,如图4所示,从中发现学生的消费总额的80%左右用于三餐消费、超市消费和洗浴消费较为接近,两项消费占比约20%。
3.1.2 学生每日用餐高峰期情况
统计学生每日三餐不同时段刷卡频次(采样:2018年5月4日至2018年6月3日时段的学生用餐信息),将每日三餐用餐时间以半小时为准划分为15个时段,分别用B1-B5、L1-L5、D1-D5表示早餐、午餐、晚餐各自的五个时段。获取学生用餐规律曲线。从图5中发现学生在工作日期间早餐、午餐、晚餐的用餐高峰期分别为:7:00—7:30、11:30—12:00、17:30—18:00,其主要由学校日常教学作息时间所致。学生一二节课上课时间为8:00,中午11:40放学、每天晚7点学生需要按照学校规定到固定教室上晚自习。故在工作日期间学生三餐的用餐高峰期的三个时段分布较为合理;节假日期间三餐用餐高峰期分别为:7:30—8:00、11:30—12:00、18:30—19:00,主要原因归结为:周末学生早晨有充分休息的意愿,且周末没有晚自习、故节假日早、晚餐用餐高峰期滞后一个时段。相同时段工作日与节假日平均刷卡频次相差不大,主要因为学校新校区所在位置相对比较偏僻,周围餐馆离学校距离较食堂偏远,故节假日学生也大部分选择在食堂就餐。学生可以依据自己的作息时间合理地避开用餐高峰期。

图 4 学生各项消费数据占比
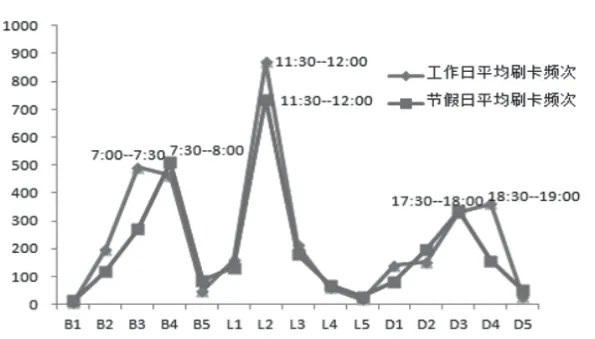
图 5 三餐不同时段刷卡频次
3.2 学生一卡通数据K-means聚类分析
3.2.1 利用Python程序实现手肘法,确定K-Means聚类中心最优个数K值
(1)手肘法原理:随着聚类中心个数K值的增加,聚类划分会更加详细,每个聚类中心的聚合程度会逐步提高,那么误差平方和SSE则会逐渐减小。当K小于实际聚类个数时,随着K值的增大会大幅度加快聚类中心的聚合程度,加速误差平方和SSE的下降幅度,一旦K达到实际聚类数时,再次增加K所得到的聚合程度回报会急剧变小,SSE的下降趋势骤减,继而趋于平缓,即SSE和K的关系呈手肘状,手肘位置的K值为最佳。
(2)手肘法Python语言实现:(SSE和K的关系如图6所示:即K=4为最佳)
import pandas as pd
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
Student_data = pd.read_excel(r'E:学生一卡通数据student.xlsx') # 读入数据
SSE = [] # 存放每次结果的误差平方和
for K in range(1,8): # K值取值范围为1-8
estimator = KMeans(n_clusters=k) # 构造聚类器
estimator.fit(Student_data [['早餐次数','午餐次数', '晚餐次数']])
SSE.append(estimator.inertia_)
X = range(1,8)
plt.xlabel('K') # X轴坐标为:K值
plt.ylabel('SSE') # Y轴坐标为:SSE
plt.plot(X,SSE,'o-')
plt.show() # 数据可视化,显示K与SSE的关系图
3.2.2 K-Means聚类分析
打开SPSS17软件,导入student.xlsx文件,点击菜单“分析”-->“分类”--> “K-均值聚类(k)”,弹出“K均值聚类分析”对话框,将学生的早餐次数、午餐次数、晚餐次数三个选项导入到“变量”一栏中,在聚类数(U)的文本框内输入数值4,迭代次数设置为100,对数据进行聚类分析,最终经过聚类获取了4类学生个体的案例数,选择对聚类贡献最大的两个变量早餐次数和午餐次数做散点图,如图7:Y轴代表早餐,X轴代表午餐(数据经Z-Score 标准化处理)。通过散点图可以发现聚类效果较好,表明了本研究的有效性。

图6 K与SSE关系图
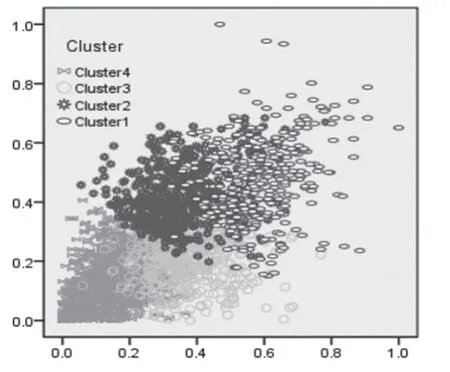
图7 散点图
3.2.3 学生群体行为分析
依据上述聚类结果,统计各类学生群体的相关指标的总和、均值,做图比较各类学生群体的各种行为规律和差异。
(1)学生群体不同场所消费占比,如图8所示。
第一、第二、第三类学生群体的三餐消费分别占总体消费的87%、80%、82%,其余消费占13%、20%、18%。说明这三类学生食堂就餐相对较为规律,第四类学生群体超市消费占比46%比三餐消费占44%还要多,说明此类群体用餐习惯不规律,推测用餐习惯偏向于外卖。对比图10和图6发现:图6中整体学生用餐消费占比81%,和前三类群体就餐占比的87%、80%、82%差距甚微,而第四类群体用餐占比仅占46%,间接说明第四类群体的案例数相对较少,并没有在较大程度上影响学生整体的用餐占比。四类学生群体的洗浴占比仅第二类超过了10%,说明个人卫生消费在整个群体的消费中不是主要支出。
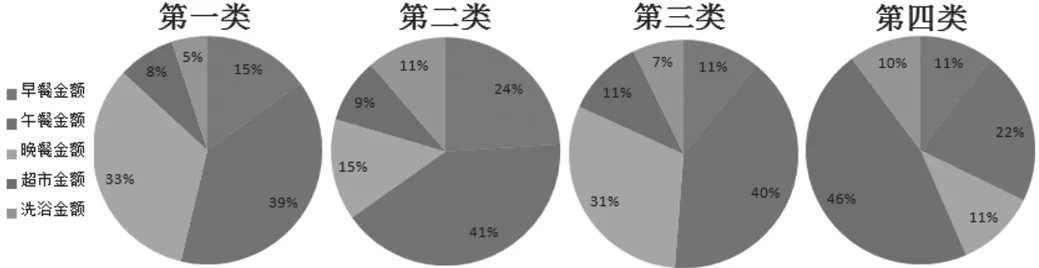
图8 各类学生群体不同场所消费占比
(2)学生群体用餐行为分析,如图9(下页)所示
第一类学生群体。早餐、午餐、晚餐次数均为最多,均高于其他三类群体。说明第一类学生群体用餐习惯较好,拥有良好的生活作息时间,早晨不懒床,能够按时吃三餐,自控力极强。
第二类学生群体。晚餐次数较第一类学生群体差距巨大,主要原因在于学校下午放学时间在4点15左右,到7点上晚自习之间时间比较充沛,此类学生可以自主安排晚餐,而早餐、午餐次数与第一类相比差距不太大,表明这类学生群体有一定的自我约束能力,能够在大部分时间克制自己的惰性,维持较好的生活习性,有一定的自控力。
第三类学生群体。午餐、晚餐次数较前两类有一定差距,不是特别大,而早餐次数较前两类差距较大,说明该群体不喜欢早起吃早饭,有懒床的可能性。即使晚餐时间宽裕也选择在食堂就餐。因此,推测此类学生群体自控力较差、惰性较大,生活习惯需要进一步改善(第三类群体和第二类群体虽有两餐相对而言较为正常,但一定要区分其产生的本质原因,差异对待)。
第四类学生群体。三餐次数与前三类学生群体相比,差距一目了然,几乎很少或不去食堂吃饭,推测此类学生群体用餐倾向于外卖,自身的生活处于游离状态,与现实的校园生活相违背,生活轨迹已然发生了弯曲,此类学生群体自控力极差,生活萎靡、惰性十足。
(3)学生群体其他行为分析,如图10所示
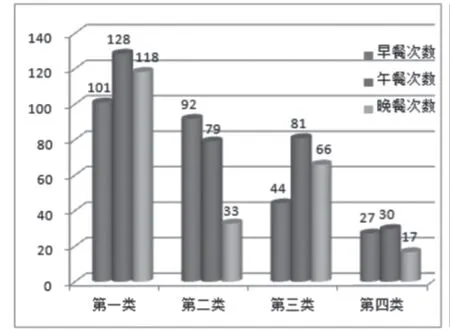
图9 用餐行为次数统计
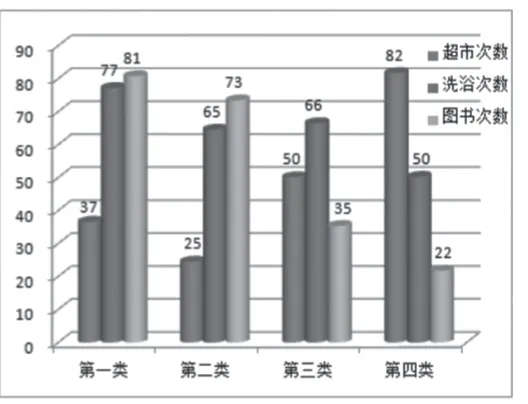
图10 其他行为次数统计
第一类学生群体。洗浴、图书馆次数相比其他三类群体均为最多,说明此类群体爱学习并注重个人卫生,超市次数相对较少,说明生活较节俭。
第二类学生群体。超市次数最少,说明比较节俭,洗浴、图书管次数与第一类相比差距不太,说明比较爱学习和注意个人卫生。表明了该类学生与第一类学生有许多相似之处,有成为第一类群体的潜力。
第三类学生群体。洗浴次数较前两类群差距不大,说明个人卫生情况较好,超市次数稍多,但超市消费占比并不大、图书馆次数较少,整体情况表明该类学生较为懒散、不太爱学习,与前两类学生群体有本质上的差异。
第四类学生群体。洗澡次数与前三类无大的差异,个人卫生较好;超市次数明显高于其他三类学生群体,成了此类学生的主要消费场所,图书馆次数最少,几乎不去或很少去图书馆看书。说明此类学生厌倦或讨厌学习。
(4)学生用餐行为与其他行为关联性分析
依据四类学生群体学习成绩等级为优秀的人次,统计每类群体的优秀率,研究表明:第一、二、三、四类学生群体的优秀率为分别为78.17%、54.52%、26.89%及5.73%。验证了学生用餐行为与学习行为之间存在明显的关联性。良好的用餐行为从侧面反映了学生自身良好的自律性,这种自律可以延伸扩展到学生的其他行为中,因此,拥有良好用餐行为的学生学习优秀率也非常高;四类学生群体个人卫生习惯均较好,说明用餐行为与个人卫生习性不具有关联性。
猜你喜欢
品牌研究(2022年8期)2022-03-23 06:49:36
品牌研究(2022年1期)2022-03-18 02:01:16
党员生活(2020年2期)2020-04-17 09:56:30
铁道通信信号(2018年10期)2018-12-06 09:34:56
小太阳画报(2018年4期)2018-05-14 17:19:27
创新作文(小学版)(2017年22期)2017-04-04 02:17:18
电子制作(2016年19期)2016-08-24 07:49:44
中学生数理化·高一版(2016年2期)2016-05-30 10:48:04
新高考·高一物理(2015年5期)2015-08-18 18:52:01
中国石油企业(2014年4期)2014-11-30 06:13:06
