
基于区块链的村镇污水处理监测系统设计
2021-03-11 03:35张云天
电子技术与软件工程 2021年21期
张云天
(青岛理工大学信息与控制工程学院 山东省青岛市 266525)
1 概述
村镇污水处理监测系统与技术行业关联密切,长期以来,云计算、大数据等创新技术为其带来了更高的可用性与实时性。传统系统[1-2]利用物联网(IoT)[3]技术采集设备监测数据上传存储至中心服务器,基于应用程序实现可视化监测。如张效苇[4]等设计的村镇污水处理远程采集与监测系统;Rezwan Sifat[5]等搭建的IoT 传输污水处理站数据极简模型。然而传统系统依赖中心数据库,面临数据篡改风险,这对需要在多种参与者之间共享IoT 数据的村镇污水处理监测场景危害极大。
在村镇污水处理监测场景中,数据共享主要涉及三方,污水处理站管理人员、监管机构以及公众。通过系统,污水处理站管理人员实时了解站点运行情况,监管机构履行政务监管,公众进行第三方监督。恶意的村镇污水处理监测数据篡改可能会造成经济损失、环境污染、监管失职等不利后果,甚至危害到人身健康。如美国弗林特市水污染事件[6]中水质数据被恶意篡改造成的市民饮用污染水中毒事件。
区块链技术[7]的出现,为保护村镇污水处理监测系统数据安全带来新思路,区块链是一种分布式的存储方案,具有安全不可变的数据存储模型,可以使数据具有不可篡改性从而保护数据安全,因此区块链与村镇污水处理监测系统的结合具有重要的现实意义。
事实上,区块链技术与IoT 监测场景的结合已经被研究[8-10]。如曾隽芳[11]等针对能耗监测中数据安全问题,构建的基于区块链能耗监测平台;胡忠启[12]等针对大坝监控数据存在的安全性与可靠性隐患问题,提出的基于区块链的大坝监控系统架构。但村镇污水处理监测场景客观存在着高并发的监测数据存储和监测数据查询,区块链的存储效率和查询效率都较低,直接应用会出现存储受限、高查询时延的问题。
近年来,国家政策的鼓励,促使村镇污水处理站数量大幅增长,如张效苇等监测的村镇具有高达760 个污水处理站点。这使村镇污水处理监测系统面临着巨大的并发存储压力。根据广东省某县现场调研结果,目前常规村镇污水处理场景每秒钟需存储约160 条监测数据。目前区块链体系中存储效率处于前列的,基于Raft 共识的fabric,经测试每秒可存储约100 条监测数据,存储效率无法支撑实际应用需求,应用时易出现监测数据存储受限。
针对此问题,本文引入了可实现高吞吐的哈希图[13](Hashgraph)高效异步共识,在使用fabric 架构的基础上,使用Hashgraph 取代fabric 原生的Raft 共识。Hashgraph 是由Hedera 公司首席技术官Leemon 设计提出的高速异步共识算法,它基于gossip 与虚拟投票完成排序共识过程,相对于Raft 共识, Hashgraph 强调最终一致性而非强一致性,大量减少了节点一致性通信和投票签名的消耗,以大幅提高存储效率,可以有效解决村镇污水处理监测场景下应用区块链出现的存储受限问题。
此外村镇污水处理监测场景还存在着高并发的监测数据查询。经估算单用户请求单站点监测数据时,平均每秒约产生20 次以上的监测数据查询。查询效率同样位于前列的fabric 在常规配置下每秒仅可完成约10 次,应用时易产生较高的查询时延。
针对此问题,本文基于余涛[14]等面向交易系统的高效链下查询方案,改进提出了一种面向IoT 监测的监测数据链下查询方案,可以有效降低监测数据查询时延。本文提出的监测数据链下查询方案对比余涛等人的方案,主要贡献如下:
(1)针对监测数据的数据结构特征,链下数据库改用OpenTSDB 时序数据库,OpenTSDB 时序数据库是一种主要用于处理带时间标签的数据的非关系型数据库,相对于原方案使用的关系型数据库它的存储空间减半,具有优越的时间序列函数,查询效率具有明显优势,因为OpenTSDB 时序数据库仅能存储double 类型数据而不能存储字符串,所以本文方案设计了全新的加密算法。
(2)针对监测数据具有低关联性,方案摒弃了原方案使用的中心链下数据库,同步策略改用边缘存储,使每一个污水处理站节点拥有独立的链下数据库,仅存储本站的监测数据。
(3)针对IoT 监测系统实时性要求,提供了原方案未提供的链下数据篡改应对机制,通过将链下数据库区块化,使监测数据篡改后可以得到修复,并确保查询服务的持续。
2 监测数据存取方案
图1为本文设计系统的监测数据存取方案模型,图中左上为通过网络连接的部署于各污水处理站的服务器组成的集群,服务器负责本站监测数据的处理和响应本站监测数据查询。右上为任意物理位置的浏览器,负责为用户提供可视化查询入口。图1示例了虚线框所示的某个污水处理站的服务器对该站监测数据的处理过程。图中连线序号标识了步骤顺序。

图1:监测数据存取方案模型
步骤(1):监测数据采集器将监测数据上传至服务器。监测数据是一个结构体,主要包含时间戳、监测项、监测数值三类信息,例如{ 1612109100,一号机器电压,5},表示2021年02月01日00 时05 分,一号机器电压为5V。
步骤(2):服务器将监测数据存储到本站fabric 账本中。
步骤(3):fabric 账本进行存储时,会基于Hashgraph 共识机制将存储内容广播至其他站点的fabric 账本中,使所有站点完成相同的存储。Hashgraph 共识过程如图2所示。
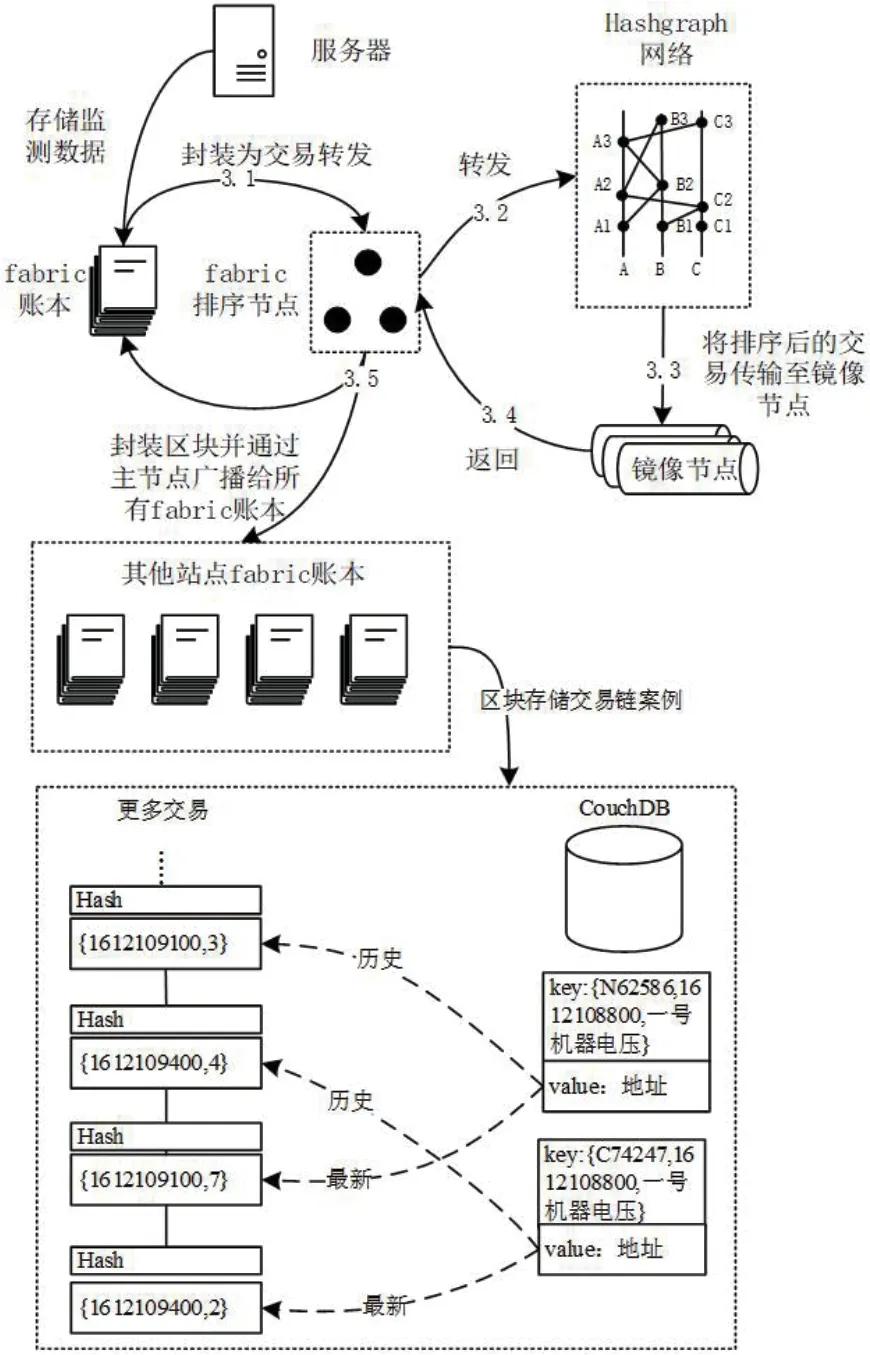
图2:Hashgraph 共识过程
服务器向fabric 账本发起监测数据存储后,会被封装为一条交易转发往fabric 排序节点,由fabric 排序节点转发至Hashgraph 网络进行排序共识,被Hashgraph 排好顺序的交易由镜像节点收集并返回给fabric 排序节点,fabric 排序节点将一段时间内的有序交易封装为区块后,通过主节点将区块广播给所有站点的fabric 账本。
采用共识机制后,任意站点的fabric 账本都存储了完整的、全部站点的监测数据。图2最下方的虚线框示例了账本区块内的交易链片段,其中CouchDB 为fabric 内置的用于的索引键值对数据库,存储键key 由站点唯一序列号、小时时间戳、监测项组成,示例的两个key 含义为N62586 号和C74247 号处理站在2021年02月02日00 时至01 时对一号机器电压的监测数值。存储值value 指向若干交易,指向方式有历史与最新两种,示例的第一条交易为第一个key 的历史交易,其内容由时间戳和监测数值组成,含义为2021年02月02日00 时05 分的监测数值为3。若站点每5min 上传一次监测数据,则一个value 至多指向11 条历史交易,1 条最新交易。fabric 账本中每一条交易都包含根据自身生成的Hash,以此有效察觉fabric 账本中数据篡改,并以其他站点fabric 账本作为数据源得到修复,确保数据的安全。
步骤(4):服务器将监测数据存储入fabric 账本后,将监测数据同步存储至链下OpenTSDB 时序数据库中。因为链下OpenTSDB时序数据库中数据并不安全,所以存储时仿照fabric 账本,对链下OpenTSDB 时序数据库进行区块化加密存储。由于OpenTSDB 规定了行键必须由小时时间戳、监测项、标签值组成,规定了列族必须由1 至3600 共3600 个数字构成,代表小时内3600 秒且仅允许存储double 数值,因此方案设计将两行记录视为一个逻辑区块,把两行记录中相同列族的两个值视为一条逻辑交易。区块化加密存储过程如图3所示:
(1)将图3所示监测数据结构体解析,获取其中的监测数值8。

图3:OpenTSDB 区块化加密存储
(2)根据监测数据结构体的时间戳和监测项寻找目标行列位置进行存储,图3中监测数据结构体时间戳为1612109100,因此存储行键的小时时间戳应为1612108800,存储列族应为300,存储行键的监测项为一号机器电压,方案规定监测数值存储标签值为tagkey=1。
(3)根据监测数据结构体生成一个加密数值5,生成加密数值伪代码如图4所示。

图4:生成加密数值伪代码
(4)重复(2)过程但存储标签值选择为tagkey=2。
对生成加密数值伪代码解释如下:
(1)中 pre_encryptValue 为加密数值目标存储行列的上一个非空列族值;如图3中标识的上一条加密数值4,此处假设了存储频率为5min 一次,因此列族300 的上一个非空列族为列族1。
(2)判断是否找不到这样一个列族值,即目标存储行列会成为该行记录中的第一个非空列族值,则令pre_encryptValue 为startEncrypt,startEncrypt 是一个固定数值。
(3)将value 与pre_encryptValue 两个double 数值转化为8位byte 数组。对两个转化后的8 位byte 数组进行异或操作后,可得到一个新的8 位byte 数组,并再次转化为一个double 类型数据midEncryptValue。
(4)使用加盐MD5 将midEncryptValue 加密为32 位字符串并拆解为32 位byte 数组midEncryptBytes,其中key 是加密秘钥,salt 为加密盐。
(5)将midEncryptBytes 分割为四个8 位byte 数组并由第一个8 位byte 数组逐一对其他三个8 位byte 数组进行异或操作获得一个新的8 位byte 数组encryptBytes。
(6)将encryptBytes 转化为一个double 数字作为输出的加密数值encryptValue,即图3中的加密数值5。
在生成加密数值的过程中,引用了目标存储行的上一条加密数值,因此该行记录形成一条短链,若视该行记录中每一个列族值为一个交易头,则可视存储对应监测数值的一行记录中每一个列族值为一个交易体,交易头与交易体所在的两行记录的行键仅tagkey 不同。因此图3中圆圈所示的两个列族值可视为一条逻辑交易,图3中虚线框所示两行记录可以视为一个逻辑区块。
至此区块化加密存储过程完毕,不同于fabric 账本,链下OpenTSDB 时序数据库不会广播存储内容至其他站点,因此仅存储本站监测数据,这符合边缘存储策略。由于高增量的数据将显著降低列数据库的条件查询效率,方案令链下OpenTSDB 时序数据库的数据增量与站点数量无关,从而使查询性能稳定。
步骤(5):进入数据查询阶段,当用户需要监测站点时,可通过浏览器向服务器发起请求。请求主要包含时间戳、监测项两类信息,例如{ 1612108800,二号机器水位},即请求本站2021年02月01日00 时00 分的二号机器水位的监测数值,根据边缘存储策略,当用户请求其他站点数据时,请求将被发送至其他站点服务器,形成负载均衡。
步骤(6):服务器接到浏览器请求后,向链下OpenTSDB 时序数据库查询符合请求的监测数值和加密数值,并生成加密数值进行校验。若输入请求的监测项、请求的时间戳、查询获得的监测数值,输出查询获得的加密数值,则通过校验,判断被请求监测数值及其相关数值(对应加密数值、上一条加密数值)未被篡改,这是因为对被请求监测数值及其相关数值的篡改一定会使校验结果有误。当校验未通过时,判断被请求监测数值及其相关数值被篡改,启动篡改应对机制,模型如图5所示。
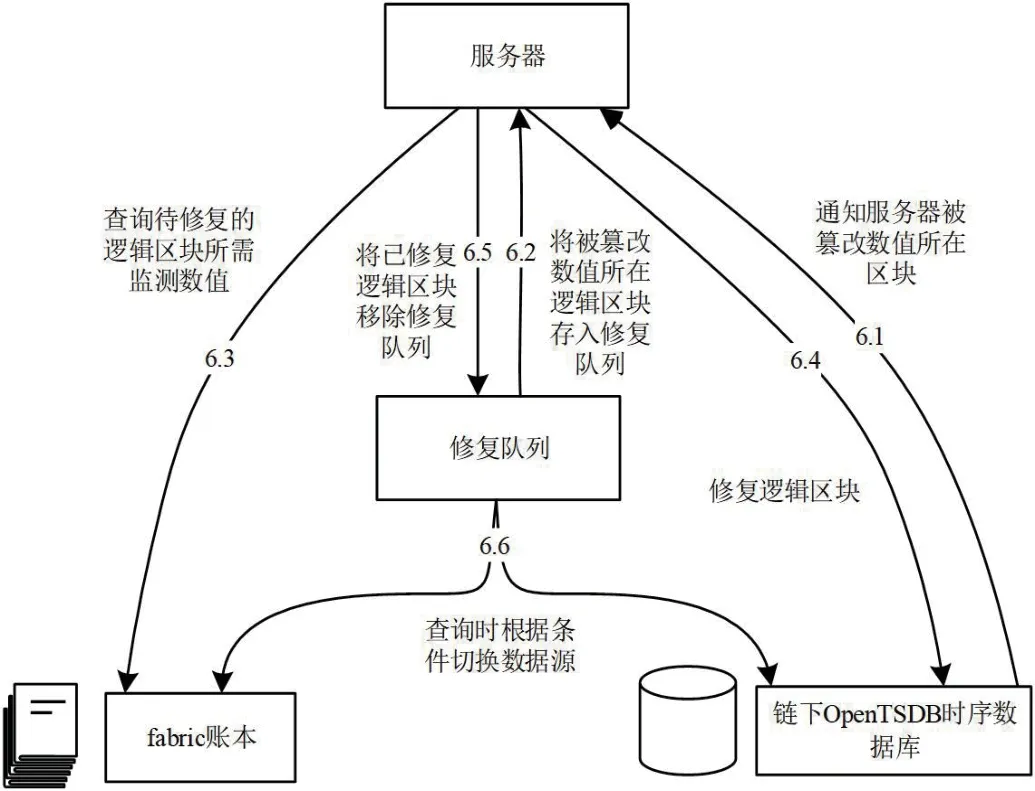
图5:篡改应对机制模型
首先链下OpenTSDB 时序数据库会立刻通知服务器被篡改监测数值所在逻辑区块,不单独修复被篡改的监测数值及其相关数值是因为逻辑区块内交易头是迭代生成的,必须对整个逻辑区块进行修复。服务器得到通知后会将逻辑区块以队列元素形式存储入修复队列中,队列元素应由小时时间戳、监测项组成,例如{1612285200,三号机器电流},可唯一指定链下OpenTSDB 时序数据库中的两行记录形成的逻辑区块。接下来服务器会向fabric 账本查询待修复的逻辑区块所需监测数值,并重新生成两行记录,覆盖至链下OpenTSDB 时序数据库完成逻辑区块的修复。修复完成后,服务器将已修复逻辑区块移除修复队列。图5中最后的步骤(6.6)并非最后执行,而是与步骤(6.1)异步执行。由于IoT 监测场景的特殊性,不允许数据查询服务因等待修复而停止,因此需要进行数据源的切换:数据篡改被发现的当次查询会返回fabric 账本的监测数值查询结果,且当用户再次通过浏览器向服务器查询监测数值时,会首先判断待查询监测数值所在逻辑区块是否存在于修复队列中,若不存在,则向链下OpenTSDB 时序数据库查询,否则向fabric 账本查询。完整的监测数值查询伪代码如图6所示。

图6:监测数值查询伪代码
对监测数值查询伪代码解释如下:(1)判断待查询监测数值是否存在于修复队列repairQueue 中,若存在则执行(2),从本站fabric 账本中获取待查询监测数值并定义为结果aimValue。其中serial 指污水处理站的唯一序列号;若不存则执行(3)、(4)、(5),从本站链下OpenTSDB 时序数据库获取待查询监测数值value 与对应加密数值encryptValue,生成加密数值进行校验。若通过校验则执行(6),定义value 为结果aimValue;若未通过则执行(7),将待查询监测数值所在逻辑区块添加至修复队列,执行(8)从fabric 账本中获取待查询监测数值定义为结果aimValue。与此同时启动异步修复线程,线程内容包括(9)至(12),(9)到(11)完成逻辑区块的修复。(12)完成将已修复的逻辑区块从修复队列移除。
步骤(7):服务器返回给浏览器可视化结果,完成整个数据存取流程。
3 系统架构
系统架构如图7所示,由用户层、节点层、应用层、合约/接口层、数据层、数据来源层组成。

图7:系统架构图
其中用户层为系统的使用人群,节点层为各污水处理站服务器集群;应用层为服务器的Web 服务和数据处理服务部署的应用;合约/接口层为服务器的fabric-sdk 服务部署的合约和OpenTSDBsdk 服务部署的合约与接口;数据层为系统数据的存储工具;数据来源层为数据的具体来源。
4 系统协作
系统协作如图8所示,过程共10 步:
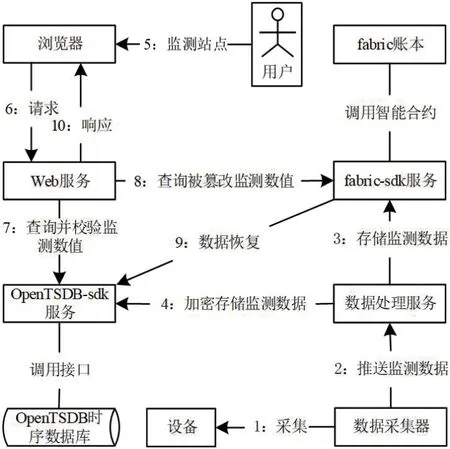
图8:系统协作图
(1)数据采集器采集设备监测数据。
(2)数据采集器推送监测数据到数据处理服务中。
(3)数据处理服务通过新增链上监测数据应用,调用fabricsdk 服务的监测数据增改合约,完成链上存储监测数据。
(4)数据处理服务通过新增链下监测数据应用,调用OpenTSDB-sdk 服务的监测数值增改接口、加密数值增改接口,完成链下加密存储监测数据。
(5)用户通过浏览器请求监测某站点。
(6)浏览器向指定站点Web 服务发起请求。
(7)Web 服务通过查询链下监测数据应用,调用OpenTSDB数据库服务的监测数据查询接口、加密数值查询接口获得并校验监测数值。
(8)若未通过校验,Web 服务调用fabric-sdk 服务的监测数据查询合约获得监测数值。
(9)Web 服务通过修复链下监测数据应用,调用fabric-sdk 服务的监测数据查询合约和OpenTSDB 时序数据库的监测数值增改合约、加密数值增改合约, 完成数据修复。
(10)Web 服务响应浏览器。
5 性能实验
为验证系统性能符合村镇污水处理监测场景需求,进行仿真环境实验,实验方案如下:部署四台服务器,服务器硬件参数如表1所示。

表1:服务器硬件参数
在四台服务器上均部署fabric 节点,每一个节点形成一个联盟,背书策略为每一个联盟至少有一个节点参与,共识配置为Hashgraph,目前Hashgraph 网络仅可通过公网由Hedera 公司提供,分付费版和免费版,本文选择的是免费版,此外在每台服务器部署链下OpenTSDB 时序数据库。部署测试应用后,模拟持续一天存储100 个污水处理站点的8 种监测数据,存储频率至5s 一次,使实际每秒监测数据存储量达到160。
图9为测试应用截图,左上所示为全部站点均处于在线状态,证明在该监测数据并发量下,方案使用的基于Hashgraph 共识的fabric 集群可以稳定的完成监测数据的存储。中央弹窗所示即为一个被观察的站点,展示了其模拟存入的8 种监测数据,测试应用对受观察站点的监测数据的实时查询正常。实验证明,本文设计系统可以良好的完成村镇污水处理监测场景的存储与查询需求。

图9:测试应用截图
为验证本文使用的Hashgraph 共识在吞吐量上的优越性,进行实验对比fabric 的原生Raft 共识和本文使用的Hashgraph 的污水处理监测数据吞吐量。实验配置块内最大交易数为100,使用Caliper工具发起总共10000 条污水处理监测数据,截取两种共识在实验条件下的连续10 次稳定出块,给定编号1-10,获取出块时间、块内交易数,并计算其吞吐量(TPS),实验结果如图10 所示。

图10:监测数据吞吐量对比
如图10 所示,Hashgraph 具有更高的吞吐量,峰值可达550TPS,平均达到350 TPS 以上;而Raft 峰值可达200 TPS,平均达到130 TPS 以上,平均提高1.6 倍。实验结果证明,本文采用的Hashgraph 具有更高的监测数据吞吐量,更适合村镇污水处理监测场景。
为验证本文设计系统对查询时延的降低,使用控制台在监测数据总存入量的多阶段分别进行单条监测数值查询测试,为体现本文方案查询时延降低的有效性,进行对比试验,分别模拟链上查询、FabricSQL 查询、本文方案查询,对以上三种查询方案的查询时延进行对比,结果如图11 所示,实验数据显示,链上查询具有最高时延,FabricSQL 次之,本文方案具有最低查询时延。因此本文方案的查询效率具有明显优势,且随着监测数据总存入量的增加,查询效率优势不断增加。
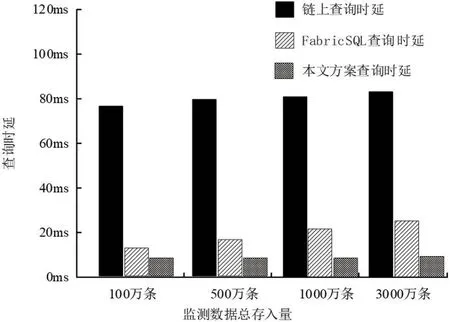
图11:三种方案查询时延对比
在实际村镇污水处理监测生产环境中,监测数据存入总量远大于实验环境,FabricSQL 的查询时延将随监测数据存入总量的增加而明显提高,将不再符合场景需求。在村镇污水处理站数量爆发式增长的今后,本文设计系统将更具现实意义与实用价值。
6 结束语
本文针对传统村镇污水处理监测系统存在的数据安全性低的问题,引入了区块链技术。同时针对区块链存储与查询性能较低,不满足村镇污水处理监测场景客观存在的高并发数据存储与数据查询带来的性能需求的问题,引入了Hashgraph 共识,设计了基于时序数据库的链下查询方案。实验证明,本文设计系统有效解决了上述问题,具有重要的现实意义。接下来将进一步研究监测数据流向与监测数据分析流程相关问题,期待有进一步的突破。
猜你喜欢
今日农业(2020年22期)2020-12-14
电子制作(2019年14期)2019-08-20
铁道通信信号(2019年11期)2019-05-21
国际呼吸杂志(2019年1期)2019-01-28
今日农业(2019年14期)2019-01-04
中国自行车(2017年1期)2017-04-16
故事会(2016年21期)2016-11-10
学习月刊(2015年10期)2015-07-09
振动工程学报(2015年1期)2015-03-01
全球定位系统(2015年4期)2015-02-28
