
HDFS管理节点自保护优化
2021-03-11 03:34王宝
电子技术与软件工程 2021年21期
王宝
(中国电信股份有限公司 上海企业信息化运营中心 上海市 201315)
1 前言
中国电信分布式小文件系统组件,包含了HDFS(Hadoop Distributed File System)的组件。在运维的生产系统中,存在多个节点使用HDFS 提供的分布式存储能力。物联网大数据平台存储的数据最终都落地在HDFS 集群DataNode 上存储,而HDP2.5(Hortonworks Data Platform)版本HDFS 集群只有一个主管理节点,元数据量伴随着海量数据增长存储不断增大,最终会引起管理节点NameNode 性能减低,运行不稳定进程宕机重启,上层承载的MR2和Hbase 等应用服务能力降级,进而影响这个集群的稳定性和可用性,降低集群整体服务水平和客户感知。
现有集团其中一个物联网计费大数据平台管理的业务数据1.8PB、元数据量峰值近1 亿,此时HDFS 的管理节点NameNode频繁出现宕机已经有4 次。为应对这种情况,需要对HDFS 集群的NameNode 节点进行特殊保护,采取配置参数优化、算法调整和性能调优等一系列措施,实现NameNode 的高可用性和强伸缩性,为大数据平台提供高效稳定的分布式HDFS 存储能力。
2 HDFSNameNode功能和HA with QJM的主要原理
2.1 HDFSNameNode功能介绍
在Hadoop 大数据应用平台架构中,HDFS 作为底层的存储能力提供者,支撑着Hbase、mapreduce 等组件的正常运行。NameNode 节点会维护存储节点的状态,定时心跳检测DataNode的存活情况,同时接收DataNode 的块数据信息上报,更新本地的元数据管理信息。
HDFS 集群主要由管理文件系统元数据的NameNode 功能单元和存储实际数据的DataNode 功能节点组成。
在图1架构中,描述了NameNode、DataNode 和客户机之间的基本交互流程。客户机联系NameNode 以获取文件元数据或文件修改,并直接使用DataNodes 执行实际的文件读写操作。
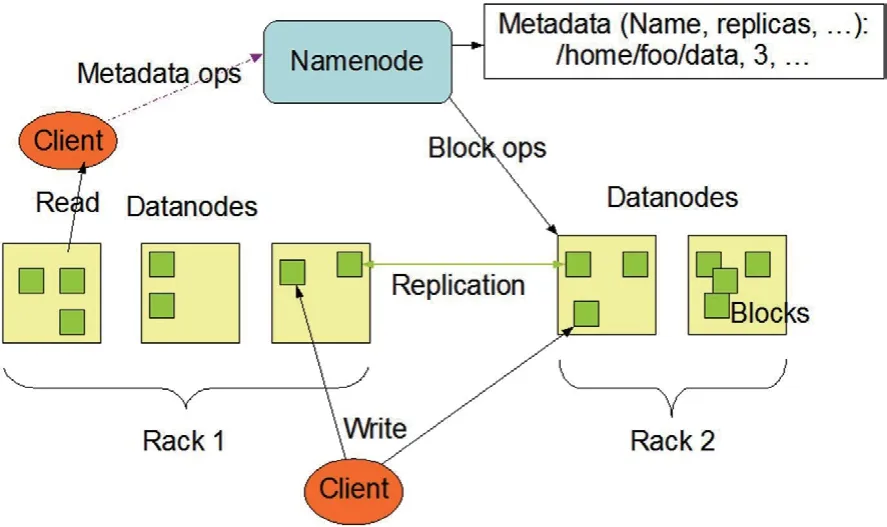
图1:HDFS 架构
2.2 HDFSHA with QJM功能介绍
采用仲裁日志管理QJM 机制的HDFS 高可用性能力,通过两个NameNode 节点同时存在,具备热备用节点和仲裁的策略机制,保障了服务器或进程服务故障的情况下,具备了能够快速切换转移到新的NameNode 节点的高可用能力,也提供了计划内HDFS 集群维护优雅的进行主备切换,同时集群服务不降级的能力。
在图2架构中,集群只有一个NameNode 处于活动状态,另一个处于备用状态。活动NameNode 负责集群中的所有客户机操作,而备用节点只是充当从节点,维护足够的状态,以便在必要时提供快速故障转移。

图2:基于QJM 的高可用架构
3 问题和背景
在实际的运维场景中,大数据平台为计费系统提供各类话单文件的存储能力和计算能力。由于业务数据本身的原生特性,用户话单和上网的详单文件都是小文件,具备文件数量大和单个文件极小的特点。随着业务发展,存储的数据量在三副本的情况下近2PB,而NameNode 节点管理的元数据block 数量也接近1 亿,此时NameNode 节点出现运行不稳定的情况,元数据管理压力大,频繁出现NameNode 节点进程异常终止,主备切换后再次服务终止的情况,导致整个集群故障,严重影响了集群各类能力的服务提供。
面对采用QJM(Quorum Journal Manager)机制的HDFS 高可用架构,两个节点频繁出现问题的情况,高可用的能力也受到了严重的挑战,通过对HDFS 的运行日志进行分析,主要发现了以下几个问题:
(1)NameNode 节点的进程服务多次异常退出由于GC(Garbage Collection )问题,fullGC 导致程序异常
(2)NameNode 节点多次进行主备切换,由于ZKFC 检测失败判定正常节点异常
(3)NameNode 节点写入fsimage 文件失败,切换期间存在脑裂现象
(4)NameNode 的RPC(Remote Procedure Call)通信拥塞,频繁判定DataNode 节点处于stale 状态
4 验证实施方案
4.1 总体实施策略
面对存在的问题,主要的问题解决思路和策略就是处理GC 时间长和RPC 通信链路拥塞两种情况下,ZKFC 健康监测进程误判。
主要思路一,调整优化Java 的GC 算法。针对HDFS 的Java进程,JVM 管理存在问题,在进行GC 的操作时,进行fullGC 的时候会出现时间过长,导致ZKFC 进程检测超时,判定进程异常停止active 节点,发生主备切换后依然还会有gc 问题。HDFS2.7.1.2默认采用的是CMS 算法,修改为G1 算法,并针对G1 的多个参数进行测试验证和优化调整,解决JavaGC 时间过长的问题。
主要思路二,调整优化NameNode 的配置参数,管控分离。HDFSNameNode 通过默认RPC 端口8202,处理来自多个数据节点的增量块报告和heatbeat 健康监测,处理客户端的请求,处理ZKFC 的健康监测,在大规模生产集群中,同一个RPC 端口会遇到争用的情况。鉴于此,通过将客户端访问端口,数据通信端口,健康监测端口分开的机制,可以有效的避免拥塞情况发生影响健康检测失败,而ZKFC 程序误判发生主备切换。
4.2 验证环境介绍
本次HDFSNameNode 扩缩性能调优方案,实施软硬件生产环境为华为R5885 服务器+Centos7.2+HDP2.5.3。
具体的软硬件环境如表1所示。

表1
4.3 生产环境实施方案
保护并优化HDFS 集群的管理节点NameNode,提升高可用能力。
4.3.1 配置独立的健康检查lifeline RPC port,与现有客户端RPC 端口分开,保障健康和存活检查
目的:该更改主要是为了避免ZKFC 进程通过默认知名RPC端口8020 检查NameNode 健康和存活状态时时,由于集群压力过大8020 端口出现RPC 拥塞响应超时,ZKFC 会进而判断节点运行异常而强制NameNode 节点程序自动退出,该问题在生产环境已经出现过多次,导致管理节点NN 单节点运行。采用轻量级的RPC消息既可以用于存储节点DN 报告健康状态给管理节点NN,又可以解决集群中管理节点NN 繁忙处理心跳问题,会把把存储DN 标记为死亡stale 的情况。
实施步骤:
(1)将NameNode 的健康检查和存活检查端口从现有的默认ROC 端口8020 分开,使用8050 端口。如图3所示。

图3:通过UI 前台配置存活检测端口
(2)重启管理节点NN 和ZKFC 服务,使配置结果生效
4.3.2 配置单独的service RPC 端口与存储节点进行RPC 通信和数据上报,与客户端默认RPC 端口8020 分开
目的:该服务RPC 端口允许DN 由此上报数据块状态和心跳检测,也可以用于ZKFC 周期健康性监测,该端口不会被客户端请求调用,客户端依旧请求知名端口8020,降低了客户端请求和DN节点之间的RPC 队列拥塞情况.
(1)在ambari 前台,custom HDFS-site 配置文件增加;
dfs.namenode.serviceRPC-address.wbtest.nn1=yfhdp1.wb.com:8060
dfs.namenode.serviceRPC-address.wbtest.nn2=yfhdp2.wb.com:8060
(2)由于集群启用了kerberos 认证,所以需要在后台两个节点分别增加kerberos 认证的文件HDFS_jaas.conf;
A、首先查询nn 节点的principals 情况,确认是否配置票据信息
B、其次按照方案增加如下的配置,集群启用kerberos,分别给两个节点创建新的HDFS_jass.conf 文件,并各自复制到/etc/hadooop/conf/HDFS_jaas.conf
非交互式生成并写入文件
echo 'Client { com.sun.security.auth.module.Krb5LoginModule required useKeyTab=true storeKey=true useTicketCache=false keyTab="/etc/security/keytabs/nn.service.keytab" principal="nn/yfhdp1.wb.com@IOT.COM";};' >/etc/hadoop/conf/HDFS_jaas.conf
C、在后台/etc/hadoop/conf/hadoop-env.sh 文件中增加如下配置,两个节点分别增加
echo 'export HADOOP_NAMENODE_OPTS="-Dzookeeper.sasl.client=true -Dzookeeper.sasl.client.username=zookeeper -DJava.security.auth.login.config=/etc/hadoop/conf/HDFS_jaas.conf-Dzookeeper.sasl.clientconfig=Client ${HADOOP_NAMENODE_OPTS}"'>>/etc/hadoop/conf/hadoop-env.sh
(3)重启备用管理节点,之后进行主从切换,在重启新的备用节点;
(4)重启所有的DN 节点,轮询每次2 台,间隔30 分钟;
(5)在ambari ui 前台停止ZKFC 的两个进程;
(6)两台NN 节点主机上分别执行HDFSZKFC -formatZK;
(7)在ambari UI 上启动ZKFC,建议在主节点上启动,再启动standby 节点。
4.3.3 配置管理节点NameNode 句柄数和service 句柄数
为了提高服务能力,分别增加NameNode 的服务线程队列数目以及数据节点心跳检测的服务线程数,可以允许更多的客户端和数据节点连接。
按照算法服务线程数根据集群节点数X 确定,推荐值NameNode 的服务线程数=20*log2X,而数据节点心跳检测的服务线程数建议不超过NameNode 线程数50%,例如有128 个节点,log2128=7,所以集群设置的参数如下:
dfs.namenode.handler.count=140
dfs.namenode.service.handler.count=70
注:根据实际HDFS 的客户端请求数目调整线程句柄数,避免RPC 等待时间过长,如图4所示。

图4:通过UI 前台配置服务句柄数
4.3.4 配置管理节点的RPC 客户端端口拥塞控制RPC Congestion Control
在ambariUI 前台增加,修改custom HDFS-site 配置文件,新增加如下配置后并分别重启主备NameNode 节点。如图5所示。

图5:通过UI 前台配置进程调用拥塞控制
4.3.5 配置RPC 公平队列 RPC FairCallQueue
配置该参数之前确保service RPC 端口已经配置生效。
在ambariUI 前台增加,修改对应的custom HDFS-site,增加如图6所示的参数并重启主备NameNode 节点服务进程。

图6:通过UI 前台配置进程调用公平队列
4.3.6 配置管理节点访问时间,避免因频繁访问而去强制写数据影响性能
设置dfs.namenode.accesstime.precision 参数数值,可以控制NameNode 更新每个文件上次访问时间的频率。它以毫秒为单位指定。如果该值太低,则NameNode 将被迫写入一个编辑日志事务来更新每个读取请求的文件的最后访问时间,其性能将受到影响,为了避免将读操作变成了写操作,建议将其数值设置为零,以便关闭上次访问时间更新。将以下内容添加到HDFS-site.xml 文件中,如图7所示。

图7:通过UI 前台配置管理节点访问时间
dfs.namenode.accesstime.precision=0
4.3.7 优化NN 的garbage collection 算法
NameNode 使用CMS 算法,其性能在FullGC 情况经常存在问题导致进程终止,通过替换G1(Garbage-First)算法,经10 余次优化G1 的参数,期间针对G1 重点解决newGC 未设置最大值限制导致时间恶化的问题,还有mixGC 在20 次之后时间过长导致ZKFC在此检测失败进程停止的情况,最终多次验证得出最优方案,NN节点已经无GC 问题稳定运行1年多,充分保障了HDFS 稳定运行无故障。而采用了G1 算法后,newGC 的实践缩短了20 倍,性能得到极大提升
本次调整的内容和主要参数说明:
(1)-XX:G1MixedGCLiveThresholdPercent=70
默认75,降低活跃度的比例,降低需要加入回收候选集的区块占用比例,减少需要回收的region,被大量占用的区块回收时间会很长。
(2)-XX:G1HeapWastePercent=25
默认值是10,提高不收集的堆比例,尽可能多回收,允许更多的浪费,超过才启动回收周期。
(3)-XX:G1MixedGCCountTarget=32
默认值是8,提高一个回收周期的mixGC 数量,尽可能回收资源。
(4)-XX:G1HeapRegionSize=32M
默认值是0,提高到32M,降低region 数目。
(5)-XX:G1RSetUpdatingPauseTimePercent=5
默认是10,降低update RS 的停顿百分比,执行更多的并发update 操
(6)-XX:-ReduceInitialCardMarks
默认是true,设置为false,避免在GC 之前有应用程序批量操作申请而导致GC 的update 动作停止
(7)-XX:G1RSetRegionEntries=2048
默认是0,增大该值,降低region 粗化的密集度,分散数据,提高scan 效率
(8)-XX:MaxGCPauseMillis=50
默认值是200 毫秒,最长暂停时间设置目标值,调整为50ms。
(9)-XX:InitiatingHeapOccupancyPercent=75
触发标记周期的Java 堆占用率阈值。默认占用率是整个Java堆的 45%,调整为75%,尽可能避免GC 操作
(10)-XX:ParallelGCThreads=32
并行工作的线程数。建议设置为逻辑处理器数的 5/8 左右,根据服务器配置调整为32,提高并行度,缩短整体GC 时间
(11)-XX:G1NewSizePercent=3
设置年轻代大小最小值的堆百分比。默认值是Java 堆的5%,由于新生代可以动态调整,所以初始值可以设置小一点,调整为3%。
(12)-XX:G1MaxNewSizePercent=8
设置要用作年轻代大小最大值的堆大小百分比,默认值是Java堆的 60%,根据不同应用的特点,经过验证新生代最大值在6G 内存时,可以保障newGC 时间在50ms 以内,在80G 的heapsize,设置新生代最大堆内存比例为8%,如图8所示。
5 方案实施结果分析
该HDFS 管理节点自保护方案具有在线调优业务无感知、JVM运行稳定性高、平台和应用访问分离的特点,在运维使用过程中主要情况如下:
5.1 集群运行的问题得到根本性解决
集群未再出现存储节点DataNode 变成stale 状态故障,未再出现HDFS 管理节点故障情况。
5.2 业务应用访问和平台通信隔离
实现了应用客户端访问HDFS 集群和HDFS 内部通信隔离,保障了客户感知。
5.3 HDFS的管理节点进程通信能力提升
实现了NameNode 的RPC 拥塞控制算法和公平队列配置,提升了RPC 处理能力
5.4 管理节点的JVM稳定性提高
实现了默认CMS 算法变更,替换为G1 算法,并调优了G1 的10 余个参数调优,保障HDFS 再也没有出现过GC 引起的宕机情况。
5.5 在线调整业务无感知优势
所有参数调整、配置优化、服务变更均可在线完成,不影响业务。
6 结论与展望
6.1 结论
该方案是在大数据平台HDFS 运维过程中发现问题、解决问题和性能优化的最佳实践,其G1 的性能调优更是经过数十次测试生产验证最终得出最佳的算法参数,是结合日常平台运维实践和hadoop 框架工具技术学习基础之上总结出来的宝贵经验,是大数据工具调优技术的一种具体实现方式,从HDFS 的NameNode 调优最为切入点,以最高效的方式保障了大数据平台的稳定性和可用性。
目前在3 个以上生产集群使用,取得了良好的效果,scaling 后未在发生过GC 问题、检测失败宕机和RPC 失败等情况,持续稳定运行。
其创新性和先进程度主要体现在:
(1)高内聚低耦合,客户服务进程独立端口运行,保障业务请求正常和提升客户感知
(2)业务通信和平台通信分而治之,采用独立的NN 检测端口以及DN 的数据上报端口
(3)启用拥塞控制算法和公平队列,避免RPC 拥塞引起业务客户端访问失败的情况
(4)深度分析GC日志调优GC 算法:通过监控、分析GC日志,调优了NameNode 的GC 算法,得到了一套最优的G1 调优参数,杜绝了NameNode 的JVM 运行异常。
6.2 展望
该调优方案,最终在大数据平台运维中落地生根,其平台与业务通信隔离能力,RPC 拥塞控制能力,JVM 的GC 稳定运行能力,在线调整业务无感知优势,充分验证了该HDFS 管理节点自保护方案的可行性和技术有效性,既提高了大数据平台管理的效率和稳定运行能力,又提高了组件的排障和性能优化能力,具有极高的推广度和普适度。
调优方案具有平台系统无改造,配置在线调优业务无感知,提升了大数据平台HDFS 运行效能,极大的提高了组件运维效率和技术能力,其成果主要体现在:
(1)符合企业云改数转战略要求,保障了大数据平台Hadoop运维工作高效开展;
(2)符合运维能力提升的要求,调优大数据平台的HDFS 存储核心NameNode 节点性能,提高了维护质量和维护效率;
(3)实现了生产环境hadoop 平台的组件运行稳定性能力提升,提高了业务连续性、稳定性和业务系统客户的满意度,提升客户感知能力。
猜你喜欢
中国外汇(2019年20期)2019-11-25
传媒评论(2018年4期)2018-06-27
传媒评论(2018年4期)2018-06-27
电子测试(2018年10期)2018-06-26
网络安全和信息化(2017年6期)2017-11-23
电脑迷(2015年6期)2015-05-30
电子设计工程(2015年12期)2015-02-27
民主与科学(2014年3期)2014-02-28
教育与职业(2014年7期)2014-01-21
计算机与网络(2013年1期)2013-06-05
