
卷积神经网络SIP微系统实现
2021-03-09 16:41:36张盛兵景德胜
计算机工程与应用 2021年5期
吕 浩,张盛兵,王 佳,刘 硕,景德胜
1.西北工业大学 计算机学院,西安710072
2.中国航空工业集团公司 西安航空计算技术研究所,西安710065
近年来,随着深度学习(Deep Learning)技术的发展,卷积神经网络(Convolutional Neural Network,CNN)在目标检测、人脸识别等机器视觉领域广泛应用。由于CNN的算法复杂度对运行平台的计算要求较高,目前通常采用的是GPU(Graphics Processing Unit)来实现。深度学习一般分为两个阶段:训练和推断,学习阶段可以采用GPU或CPU来实现,但在推断阶段较多为嵌入式使用场景,对系统往往有体积、功耗、实时和性能等多目标约束,FPGA(Field Programmable Gate Array)的实现方式更具有优势[1]。FPGA低功耗、低延时和可重构,适合CNN的并行加速。目前已有一些基于FPGA的神经网络研究,例如CNN的FPGA数字识别仿真结果可达到95.4%的识别率[2]等。
在嵌入式电子系统的微型化方面,微系统技术得到了越来越多的重视,而SIP和SOC是微系统实现的两种重要技术途径。伴随着微组装技术的发展,SIP和SOC相比,可以将不同类型的器件和电路芯片叠在一起,构建成更为复杂的、完整的系统,其集成方式更灵活,在研发周期、成本方面具有优势,弥补了SOC的不足。SIP与SOC的结合是未来微型化的趋势。
目标识别与分类微系统技术在军民用领域都有着广泛的应用需求。民用和军用小型无人机目标识别系统迫切需要微型化,美国在其航空设备上也已经大量使用SIP芯片技术。研制基于CNN的SIP微系统,实现CNN的轻量化,以手写数字识别作为测试,一方面满足了金融等领域自动化识别手写数字的迫切需求,另一方面为进一步研究目标识别与分类微系统技术奠定基础。Xilinx公司的Zynq-7000 SOC芯片适合于构建该SIP最小系统,Zynq SOC组合了一个双核ARM Cortex-A9处理器和一个FPGA逻辑部件。
本文将SIP微系统集成封装技术与卷积神经网络相结合,构建深度学习CNN微系统。将XC7Z010芯片和DDR3、Flash存储器等集成封装,减小了体积和功耗,并改善了信号完整性[3]。基于VGG神经网络模型,在SIP芯片的FPGA资源中使用HLS来设计实现CNN的卷积层、池化层IP,在ARM处理器端采用时分复用的方式进行分层调用。最后使用MNIST手写数字数据集来验证。
1 SIP微系统设计与实现
1.1 SIP技术
SIP芯片的封装制造主要包括裸芯片的备货、基板的制造和裸芯片封装。基板一般采用BT树脂覆铜刚性基板。SIP的封装工艺主要包括FC(Flip Chip)和WB(Wire Bonding)等。FC是将IC倒置在基板凸点上,与芯片相应焊接区域对准,可以使空间充分利用,立体堆叠,但对基板的平整度工艺要求较高。如果FC工艺无法保证基板平整度,就会造成芯片可靠性的降低,导致脱焊故障或者良品率的降低。WB是传统比较成熟的引线键合工艺方式,工艺制造难度相对低一些,成品的可靠性更高。
在硬件原理设计完毕后,采用工具(例如Cadence)进行SIP芯片的布局和布线,以及各项仿真工作,包括热仿真、结构强度仿真、信号完整性仿真和电源完整性仿真等。
1.2 SIP微系统芯片设计实现
本次采用SIP技术来实现CNN微系统的硬件芯片平台。该款航空电子SIP微系统芯片以Zynq SOC(XC7Z010)为核心,其中包含有Processing System(PS)和Programmable Logic(PL)两部分,PS端为Dual-core ARM®Cortex™-A9,Maximum Frequency为667 MHz,PL端包含Artix™-7 FPGA,有28 000 Logic Cells、17 600 LUTs,可以在PL中通过可编程逻辑构建接口或者CNN逻辑IP核,PS端和PL端通过工业标准的AXI总线互联通信[4]。
以Zynq SOC为核心,外周配置有128 MB的DDR3 Memory和128 Mbit的SPI_FLASH,以及接口驱动器,所有这些和相应配置的电阻、电容等器件封装成为该SIP芯片,构成最小计算系统。芯片塑封BGA480封装形式,芯片尺寸为30 mm×30 mm,芯片厚度1.2 mm。图1是SIP芯片的系统结构示意图,图2是裸芯布局图。

图1 SIP芯片结构示意图

图2 SIP芯片内部裸芯布局图
SIP芯片设计过程中必须经过必要的仿真[5]。例如为了使芯片适应不同应用环境要求,必须进行强度仿真。在管脚施加约束,模拟芯片受到200g的加速度,对强度进行仿真。通过仿真,整体结构在200g加速度下最大应力为16.7 MPa,发生在上盖板处,应力远远小于其屈服极限(136 MPa)。图3显示了以200g的加速度在芯片各个部分上的压力分布。

图3 芯片整体200g加速度下应力分布图
最终实现的SIP芯片照片如图4所示,该微系统芯片使最小计算系统体积进一步减小,功耗降低,信号完整性也得以改善[6],为CNN微系统的实现提供了可靠的硬件平台。

图4 SIP芯片照片
2 CNN微系统设计
2.1 CNN模型
自2012年Krizhevsky等人提出的深度卷积神经网络AlexNet在ImageNet大规模视觉识别挑战赛中夺冠以来,开始了深度学习技术在图像领域的研究热潮。很多目标检测算法被研究者所提出,如LeNet、VGG、SDD和YOLO等深度学习算法[7]。相比较而言VGGNet算法由AlexNet演化而来,更适合小规模可编程逻辑器件使用开发。标准的CNN包含卷积层、池化层和全连接层。
VGGNet由牛津大学计算机视觉组和谷歌旗下DeepMind团队的研究员共同研究提出,获得2014年ImageNet图像分类竞赛第二名。VGGNet是加深版的AlexNet。VGGNet的特点包括:结构简洁,激活函数使用ReLU;使用3×3小卷积核和多卷积子层;使用2×2的池化层过滤器;通道较多;将全连接层转换为卷积层。图5是典型VGG16的结构图[8]。

图5 典型VGG16的网络结构图
本次设计使用了基于VGGNet优化的小型神经网络,该网络结构非常简洁,全网络使用了3×3卷积核和2×2最大池化尺寸。通过不断加深网络结构和分时复用来提升性能。每一层卷积或全连接层后面都使用易于在硬件上实现的Relu激活函数。图6是设计所使用的自定义Micro_VGGNet网络模型图。

图6 使用的Micro_VGGNet网络模型图
Relu激活函数[9]如下:

该模型结构有8层,第一层为输入层,为手写数字图像数据的输入,采用MNIST数据集,最后一层为输出层,输出结果为10种,使用Softmax函数,实现10个分类。为了降低过拟合,在输出层的前一层还加入了Dropout层。
Softmax函数公式如下[10]:

第2、4层为卷积层,采用3×3的卷积核,步长为1,扩充值为1,采用same卷积;第3、5层为池化层,步长为2,采用最大池化;第6、7层为全连接层,同样使用卷积运算,卷积核7×7,步长为1,扩充值为0,采用valid卷积。

可用采用FLOPS(FLOating-Point operationS,浮点运算次数)衡量模型的时间复杂度公式[11]如下:其中,M是卷积核输出特征图的尺寸,K是卷积核的尺寸,C_in是卷积核的输入通道数,C_out是卷积层具有的输出通道数,从而可以看出90%以上的运算集中在卷积层。
综上该Micro_VGGNet网络架构的特点是:
(1)结构简洁,只有8层,利于FPGA实现;
(2)使用小的卷积核和小的池化滤波器;
(3)将全连接层转换为卷积层,方便实现和复用。
2.2 Zynq系统设计
系统基于XC7Z010,在PL端的FPGA内实现两个IP核:Con_IP、Pool_IP。
Con_IP负责卷积与Relu;
Pool_IP负责池化。
采用Vivado HLS工具的HLS方式[12]实现,由C语言代码转换为HDL语言IP核。卷积、池化、全连接、softmax(其实就是全连接运算),所以只需要做三个通用加速电路,循环迭代使用这三个电路就可以实现功能。各做一个通用卷积、池化、全连接。而全连接是一种特殊的卷积运算,故可以卷积代替全连接。图7是HLS高层次综合的流程图。
各部分通过AXI总线连接[13],axi_slave接口用于配置电路连接,axi_master用于主动取数据及数据结果写回,不用cpu干预。使用vivido工具完成的系统硬件图如图8所示。

图7 高层次综合流程图
设计将运算量巨大的CNN放在FPGA端,充分发挥FPGA并行运算能力。整个硬件架构由PS端ARM处理器、时钟复位模块、总线互联模块和CNN_IP模块四部分组成。ARM处理器通过SD卡存储器将手写数字图像导入DDR3存储器,CNN_IP自行从DDR3中获取图像数据。前期的数据获取和预处理工作由ARM端的主控程序来完成,由SDK工具开发实现。
2.3 CNN IP核设计
模型中卷积层和池化层均采用HLS来实现,采用C语言来编写代码,使用Vivado HLS工具来生成IP核。两个函数IP,一个负责卷积与Relu,一个负责池化。由处理器ARM来分时调用不同的函数IP[14],其工作流图如图9所示。
卷积函数的定义代码如图10所示,其中,Chin是输入路数;Hin是输入特征高;Win是输入特征宽;卷积核KxKy;步幅SxSy;卷积模式mode;relu使能relu_en;运算规模大小feature_in[]、feature_out[]、W[]、bias[]。

图8 系统硬件结构图
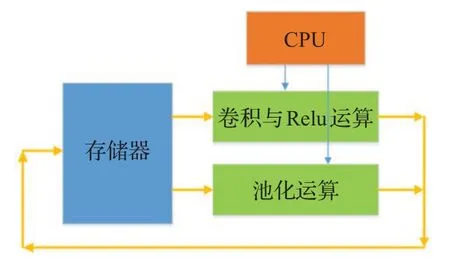
图9 CNN IP核工作流图
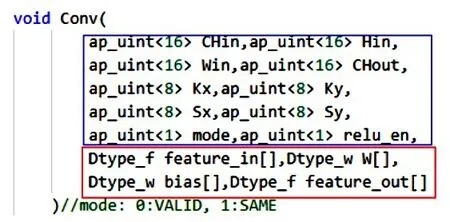
图10 卷积函数代码定义图
池化函数的定义代码如图11所示,其中,CHin是输入路数;Hin是输入特征高;Win是输入特征宽;卷积核KxKy;池化模式mode;运算规模大小feature_in[]、feature_out[]。

图11 池化函数代码定义图
3 测试与分析
3.1 测试环境
采用本次设计的SIP微系统芯片搭建测试平台,测试平台和PC机之间通过RS232口进行通信,PC机端使用Visual Studio 2012 OpenCV2.4.9搭建上位机环境,通过RS232串口给平台发送手绘图板工具绘制的手写数字图像(.bmp图片),由测试平台进行识别后将结果通过RS232回传至PC机显示。
前期训练将Minist数据集存放到SD卡中去(读入DDR),该数据集一共有6 000张训练图片和1 000张测试图片,大小为28×28×1。
图12 为测试环境与结果PC机界面显示图,正在测试手写数字5,并由SIP微系统平台正确识别:“receive data success 5”。

图12 测试结果显示界面
3.2 不同平台间对比分析
在PC机端进行了手写数字的软件算法实现,并进行了测试,PC机采用CPU型号为Core i7-8700k处理器。将SIP微系统和PC机进行了手写数字识别正确率和用时的比较,从表1中可以看出SIP微系统的识别正确率基本与PC机持平,且其一次迭代用时仅为PC机的1/3。

表1 SIP微系统平台和CPU平台结果对比
使用vavido分析工具对SIP微系统(XC7Z010)的资源利用情况和功耗情况进行分析统计,如表2和图13所示,CNN微系统做占用逻辑资源并不多,功耗很低,动态功耗占住,静态功耗仅为0.114 W。

表2 SIP微系统硬件资源消耗(XC7Z010)

图13 XC7Z010功耗分配图
最后,将同样的模型算法代码在SIP微系统的ARM端(PS)用纯软件的方法实现[15],并再次进行比较分析。将PC机平台、纯ARM平台和SIP系统平台进行综合测试对比,情况如表3所示。SIP微系统在性能、功耗和体积等方面具有综合优势。SIP微系统的性能功耗比是纯ARM平台的76倍,是PC机平台的146倍。SIP微系统的图像处理速度是纯ARM的115倍,是PC机平台的5倍。在电路板所占面积方面,SIP微系统仅约为PC机CPU平台同样资源所占面积的1/3。
3.3 与LeNet-5模型对比
LeNet-5模型是卷积神经网络中的一个经典模型,在手写数字识别领域具有重要意义。在相同的SIP微系统平台下,对Micro_VGGNet和LeNet-5模型的测试结果进行对比。
LeNet-5模型共有8层,包括输入层、C1卷积层、S2池化层、C3卷积层、S4池化层、C5卷积层、F6全连接层和输出层。模型中的输入参数大小32×32,测试时需要将MNIST图像28×28的进行填充,使维度变为32×32。其具体结构如图14所示。

表3 不同平台测试对比表
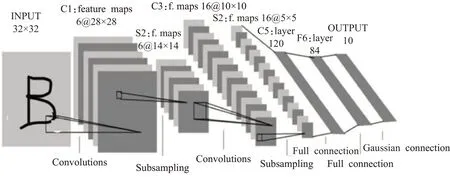
图14 LeNet-5网络模型图
LeNet-5卷积层采用的是5×5大小的卷积核,且卷积核每次滑动一个像素,下采样层将卷积层28×28或10×10的特征图谱以2×2为位单位的下采样(池化)得到14×14或5×5的图。最后全连接层将所有的节点连接起来传给输出层。输出层共有10个节点,分别代表数字0到9。除了最后一层,每一层的结果都会通过sigmoid非线性激活函数。同样采用时分复用FPGA IP核的方法进行实现,在SIP微系统平台中测试其资源消耗如表4所示。

表4 SIP微系统硬件资源消耗(LeNet-5模型)
LeNet-5相对于Micro_VGGNet来说,使用的卷积核更大,计算复杂度更高,激活函数sigmoid也比ReLU运算复杂度高得多,这就导致其在训练时收敛得更慢,需要更多的训练样本[16]。在用同样图8的架构进行逻辑测试时,表4和表2比较,整体逻辑资源使用相当,部分资源占用率更高。
在同样的SIP微系统平台666 MHz+100 MHz的条件下测试,LeNet-5模型结果如表5所示,两种模型的性能接近,但LeNet-5模型的识别正确率和识别速度都不及Micro_VGGNet。

表5 SIP微系统LeNet-5模型测试结果
4 结束语
CNN深度学习技术和SIP微系统技术都已取得了深入发展,将两者相结合设计和实现了基于SIP的CNN微系统,构建了适用于嵌入式应用加速的Micro_VGG模型,实现了CNN的轻量化,并结合Minist数据集进行了测试。通过不同平台间的对比,可以发现该CNN微系统在性能、功耗和体积等方面具有综合优势;通过和LeNet-5模型对比,发现Micro_VGG模型的优势。本设计符合嵌入式应用微型化的需求,同时为目标识别与检测SIP微系统的进一步研究积累了技术基础,提供了参考。
猜你喜欢
无线电工程(2024年8期)2024-09-16 00:00:00
学苑创造·A版(2024年5期)2024-06-10 21:55:57
科学技术与工程(2023年3期)2023-03-15 10:34:12
软件导刊(2022年3期)2022-03-25 04:45:04
故事作文·低年级(2021年12期)2021-12-21 23:04:39
作文成功之路·小学版(2020年7期)2020-08-24 08:19:18
计算机技术与发展(2019年1期)2019-01-21 00:56:38
电子制作(2018年18期)2018-11-14 01:48:08
电脑与电信(2018年12期)2018-03-23 02:37:40
制造技术与机床(2017年9期)2017-11-27 02:13:55
