
熵率超像素分割一致性检验视差细化算法
2021-03-09 16:41:34张忠民刘金鑫席志红
计算机工程与应用 2021年5期
张忠民,刘金鑫,席志红
哈尔滨工程大学 信息与通信工程学院,哈尔滨150001
近年来,随着计算机视觉与机器视觉领域的迅速发展,立体匹配算法作为其重要组成部分也在被众多学者不断优化更新。立体匹配算法的目的是寻找同一场景下两幅或者多幅图片中的对应点,从而进行深度信息估计,此算法广泛应用于三维重建、目标跟踪以及VR等领域。2002年,Scharstein和Szeliski[1]提出了一种适用于立体视觉领域的分类方法,将立体匹配过程总结为以下四个步骤:(1)匹配代价计算;(2)代价聚合;(3)视差计算;(4)视差精化。全局立体匹配算法需要进行(1)、(3)、(4)三个步骤,跳过了代价聚合阶段,通过最小化能量函数来选择最佳视差值,这种方法常常可以得到局部精确的视差图,但是计算的复杂度也更高,消耗时间更长。常见的全局立体匹配算法有图割法(GC)[2]、置信传播(BP)[3]、最小生成树法(MST)[4]、分割树法(ST)[5]。局部立体匹配算法需要进行全部四个步骤,结构简单,但结果准确率较低。局部立体匹配算法是现如今学者们的研究热点与重点。
现如今,很多学者通过优化匹配代价来提高视差精度,包括灰度差绝对值和(SAD)与灰度差平方和(SSD)[6],这两种方法对光照与噪声比较敏感,以及基于梯度的度量(GBM)[7],鲁棒性较高的是Census变换[8]匹配算法。周旺尉等[9]在传统Census变换匹配算法的基础上引入了自适应权重,此算法有效改善了匹配效果但实时性不尽如人意。王云峰等[10]提出了一种自适应权重AD-Census算法,此算法虽准确率较高,但运行时间过长,在实际应用中受到一定限制。郭鑫等[11]提出了将传统的Census变换、互信息、梯度信息这三种测度融合作为匹配代价,有效地提高了视差精度。在聚合窗口的选择方面同样涌现了大批算法,Yoon等[12]提出了自适应权重的立体匹配算法,根据邻域像素和中心像素的颜色和几何相似性调整权重。2013年,Hosni等[13]将引导滤波应用在窗口聚合上,引导滤波算法[14]能够提高物体边缘特征的匹配准确率。张华等[15]提出跨尺度变窗口代价聚合匹配方法,采取互尺度正则化方法跨尺度聚合匹配代价。同样的,也有学者在视差精化方面做文章,传统的视差精化方法有左右一致性检测(LRC)、中值滤波等等。Vieira等[16]提出了一种分割一致性检验的视差精化算法,将图像分割成块,采用统计分析方式选取每个分割块中可信值与不可信值,然后进行视差填充,该方法可以有效地细化视差,提高精度。
本文基于文献[16]中提出的分割一致性检验算法,提出了基于熵率超像素分割的分割一致性检验算法。本文算法将传统分割一致性检验算法中的均值漂移分割算法改进为熵率超像素分割算法,熵率超像素分割算法可以将图片分割成紧凑,具有区域一致性的区域,可以有效降低分割错误率及提高分割后区域整体性进而提高后续匹配精度。本文算法在保持原算法在复杂纹理区域细化精度的基础上,优化了其在低纹理区域的细化精度。
1 算法描述
本文算法基于传统分割一致性检验方法进行有效改进。首先利用基于熵率的超像素分割算法将参考图像进行分割,然后将分割块按统计分析阈值分成可信值与不可信值,保留可信值剔除不可信值,最后通过颜色与空间的约束信息进行视差填充,最终获得精确的视差图,具体算法流程图如图1所示。
1.1 熵率超像素分割算法
Liu等[17]经过对超像素分割问题的研究,提出了基于熵率的超像素分割算法(Entropy Rate Super-pixel Segmentation Algorithm)。此算法采用一个带权的无向图代替源图像,将源图像中每个像素当作无向图的一个结点,利用两个结点的相似性作为结点之间的权重,采用了一种图上随机游走的熵率和平衡项相结合的目标函数,通过迭代最大化该目标函数获得分割结果。通过熵率分割可以获得更均匀紧凑的区域,使得分割后的区域符合人眼感知,且分割后得到的各个区域具有较高的相似度。
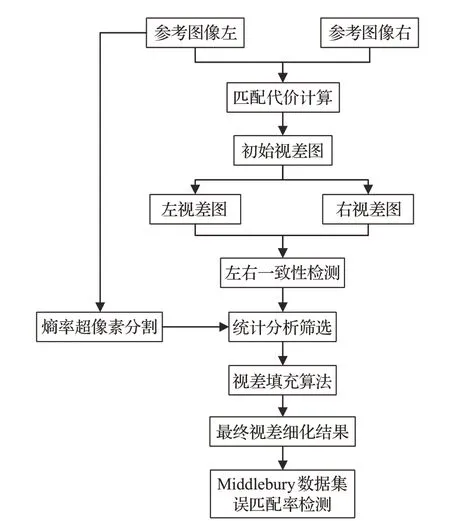
图1 算法流程图
无向图G=(V,E),其中V代表图的顶点集,E代表边集,这样就把图像的分割问题转化为图的划分问题。即将V划分为一系列不相交的集合,其中任意两个子集的交集为空集,所有子集的并集为V。选取E的子集A,得到无向图G′=(V,A)。故学者们提出了一种新型聚类目标函数,公式如下:

其中,H′(A)为图上随机游动的熵率,B(A)表示平衡项,A为边集,λ为平衡系数,此平衡系数为非负值。
1.1.1 熵率

其中,A为边集,i和j表示图的顶点,ei,j表示连接顶点的边。所以,图G′=(V,A)上随机游动的熵率可以用如下公式表示:
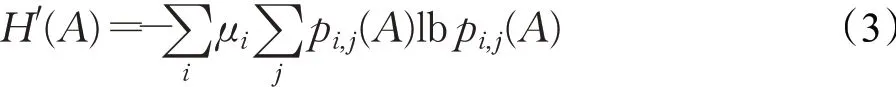
其中,μ为随机过程的平稳分布|V|表示图的顶点个数。
1.1.2 平衡函数
平衡函数即平衡项为一个判决准则,若边集A的分割结果为集群成员的分布可用如下公式表示:

其中,NA表示划分后的子集个数,ZA表示集群成员的分布,pZA(i)为第i个子集顶点数所占比例,i=1,2,…,NA,||Si表示第i个子集的顶点个数。
平衡函数定义由如下公式表示:
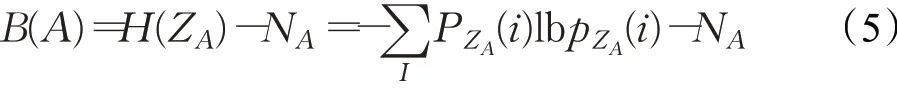
熵H(ZA)使得生产的集群具有相似的大小,NA使得聚类的数目尽可能少。对于给定的聚类数目,倾向于使平衡函数尽可能大的划分方法,图2可以解释上述描述。
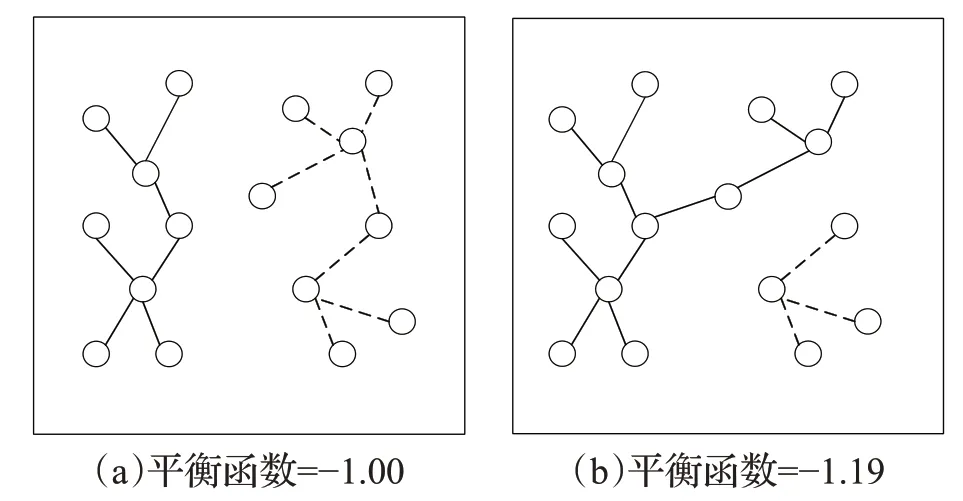
图2 熵率对集群相似性作用描述
接着,学者使用算法分割图像。学者们首先将图G=(V,E)中每个顶点当成单独集群,将不同的标志赋予每个集群,初始化A=∅。使用前文已经定义的目标函数来计算E中各条边的函数值,从这些函数值中选出最大值的边加入A中,A中增加一条边,E中就减少一条边,同时进行合并集群的操作。不断重复此操作直到E为空。迭代完成后,可以得到K个集群,每个集群就是一个超像素。基于熵率的超像素分割方法中,熵率有利于形成结构均匀、紧凑的集群,促进获得的超像素仅覆盖图像中的单一目标对象,使得图像分割为符合人眼感知的区域。平衡项促使各集群具有相似的尺寸,降低不平衡超像素个数。
1.2 统计分析算法
经过第一步骤得到了参考图像的分割图,将参考图像分割成了若干分割块。接着,此方法通过统计分析为每一个分割块计算出一个统计值,将此统计值作为集中趋势值,公式如下:

根据计算出的集中趋势值,将每一个分割块中的每个视差点进行求值,筛选可信值与不可信值,若求得的值在此范围内,则赋值为m并保留,反之若不在此范围内,则赋值为0,将其当作未知视差点处理。公式如下:
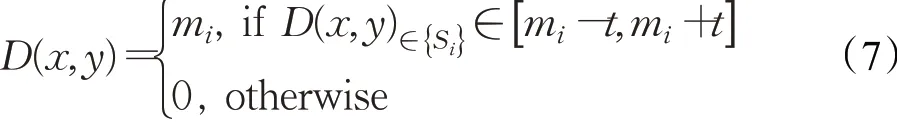
对于视差图D中分割块表示为Si(Si∈D)。计算全部n个分割块的集中趋势值并表示为m。阈值t的值可以自定,设置此阈值的目的是接近分割块中的集中趋势值,并且每一个视差值D(x,y)都应该在Si中。
1.3 自适应加权窗口视差填充算法
由于上一步骤中存在被赋值为0当作未知视差值的点,所以需要填充这些点来保证视差图的完整精确性。Yoon和Kweon[18]提出了一种支持加权窗口算法来进行立体匹配,他们的方法考虑了点与点之间的颜色相似性和点与点之间的空间距离关系。作者在论文中定义了一个窗口,并且定义窗口的中心点为主点。计算每个邻近点与主点的颜色差异与空间几何关系可以作为约束条件来进行视差填充。主点p与邻近点n的颜色邻近约束公式如下:

其中,Δcpn表示图像I中主点p与邻近点n的颜色间的欧式距离。Δcpn可以由如下公式表示:
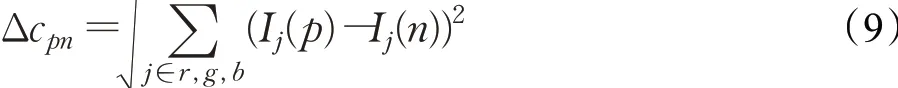
同样的,空间邻近约束公式为:

其中,Δspn表示图像I主点p与邻近点n的坐标(x,y)间的欧式距离。Δspn可以由如下公式表示:
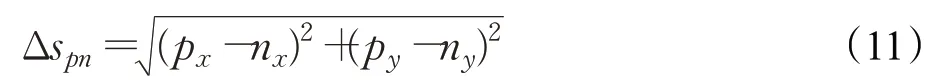
其中,γc与γs分别表示颜色相似性常数及用于调整空间距离项的常数。
将颜色与空间两种约束相结合,就可以得到支持加权窗口的公式:

本文使用自适应支持加权窗口算法处理未知视差,窗口内的主点就是想要的视差点。权值是根据上述颜色相似度与几何距离来调整的,即像素颜色越相近,所分配到的权值越大;像素几何距离越近,所分配到的权值也就越大。通过此方法得到的权值是具有准确性的。在相同视差点处的每个像素的权值都会累加。将窗口内的每个点的权值设为w。如下公式表示了权值累加的过程:其中,dmin与dmax表示最小与最大的视差值,Ω表示累加值。

因此,如下公式可以代表视差优化的过程,以此来求出最佳视差:

其中,(x,y)为视差图D中各个位置视差处的坐标,将计算出的最佳视差值Ω赋值给D,即可达到有效填充视差的作用。
2 实验结果与分析
本实验在Matlab R2016b平台完成。为验证算法有效性,采用立体匹配领域公认的Middlebury[1]数据集进行实验,其中包括Tsukuba、Venus、Teddy和Cones等15组标准测试图。按照Middlebury统一评价标准,设置误差参数阈值为1。实验中部分参数设置与文献[16]中相同,15组立体图像对的视差搜索范围参数与缩放倍数参数如表1所示。

表1 视察搜索范围与缩放倍数参数
2.1 算法综合性能测试结果
2.1.1 统计分析方法适配性实验
本文使用众数(Mode)作为集中趋势值的求取方法。为验证本文统计分析方法的适配性,本文对比了另外两种集中趋势值的测量方法:均值法(Mean)、中值法(Median)。针对Tsukuba、Venus、Teddy和Cones四组标准测试图分别用三种集中趋势值测量方法得到最终的视差图误匹配率。对比数据如表2所示。
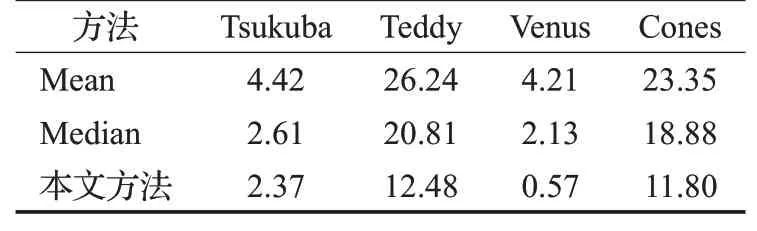
表2 统计分析方法适配性对比%
可以看出,本文使用的统计分析方法最终得到四组测试图的视差图误匹配率均低于均值与中值两种算法。实验结果表明,本文所使用的统计分析方法与分割块较传统均值中值两种方法具有更好的适配性。
2.1.2 算法综合性能对比实验
本实验分别使用立体匹配效果较好的文献[13]算法及立体匹配效果较差的SAD算法[19]进行1、2、3步,第4步视差精化则分别运用传统分割一致性检验算法与本文算法,然后将四组误匹配率结果进行比较,最终得到量化对比结果。算法综合性能测试结果如表3所示。
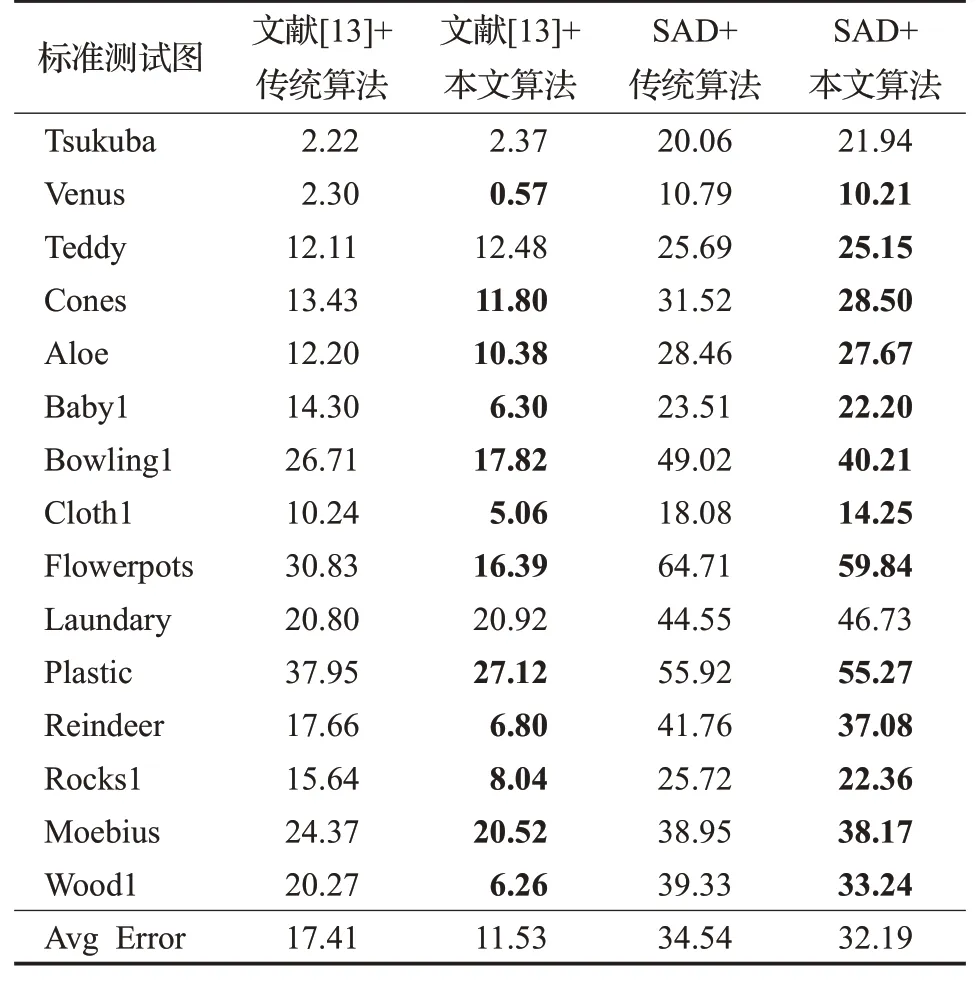
表3 算法量化对比结果 %
从表3可以看出,文献[13]由于立体匹配效果较好,所以总体误匹配率较低,SAD立体匹配算法匹配误差较大导致总体误匹配率较高。但是总体来说在经过两种视差细化方式后,误匹配率均呈现明显下降趋势。对比上述数据,平均误差匹配率最多提高了5.88个百分点。表3可以看出,在综合性能上,本文算法要优于传统算法。其原因在于熵率超像素分割算法可以将参考图像分割成紧凑的,具有区域一致性的若干区域,因此可以有效避免图像中的信息缺失情况,这样在细化后可以保持物体的形状基本不变。在对这些区域进行筛选时首先遍历每个区域进行视差求取,并与集中趋势值进行比较筛选。这样可以保证每个区域信息的均匀性,进而保持均匀区域视差的规律性,这样进行有效视差填充后视差细化效果会优于传统算法。
2.2 低纹理图片算法对比结果
选取文献[13]中的立体匹配算法分别进行两种视差细化算法,然后分别对于初始视差图及两种视差细化后得到的视差图进行误匹配率检测,图片选择Venus、Baby1、Rock1、Wood1四组低纹理图片,测试结果如表4所示。
表4 可以看出传统算法与改进算法在低纹理图片中的细化精度对比。例如,Venus图中纹理信息较少,使用传统算法得到的细化精度为2.30%,但是本文改进算法得到的细化精度为0.57%,较传统算法精度提升了
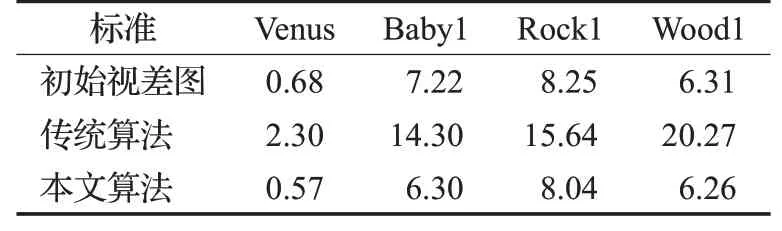
表4 低纹理图片测试结果对比 %
1.73个百分点,其余三张低纹理图片细化精度均有不同程度提高,最多提升14.01个百分点。图3为算法对比图。

图3 算法对比图
在分别对初始视差图使用传统算法与本文算法进行视差精化后。首先求出初始视差图的误匹配率及其误匹配标记图,然后分别求出通过两种精化算法后的误匹配率及误匹配标记图。对比图3中各组图片,可以得到以下结论:(1)对比图3(d)与(f)两组图片,可以看出对于低纹理图片传统算法会出现负优化的情况。这说明传统算法对低纹理图片的精化处理是存在局限性的。(2)对比图3(b)、(e)、(g)三组视差图中的Baby1图,从图中红圈部分可以看出传统算法视差图中视差信息存在缺失的情况。(3)对比图3(f)与(h)两组误匹配标记图,红色误匹配部分本文算法明显少于传统算法;对比Venus图中蓝圈部分可以看出在纹理信息较少的位置,本文算法优化效果优于传统算法。针对以上三点结论,结合本文算法与传统算法的机制,可以看出:(1)传统算法运用的均值漂移分割方法虽然可以有效保持视差图边缘特征,但是由于窗口选择及迭代过程造成了信息的缺失。然而,熵率超像素分割算法则会将图像均匀分割,可以有效避免这一情况。(2)图像纹理信息越少,传统算法的局限性就越明显,相反本文算法得到的分割块与后续统计分析方法的适配性更高,在低纹理区域更容易发挥算法精度优势,同样在复杂纹理区域也不输于传统算法。对比图3(g)本文算法求得的最终视差图的效果,可以看出在边缘处还存在散点较多的现象,由于熵率超像素分割算法会将参考图像分割成若干块,相邻边缘信息部分很可能存在于不同块中,一旦有些边缘信息被置零处理,就会出现边缘信息散点情况。因此导致匹配效果不是很好,可见本文算法在边缘处的鲁棒性还有待提高。未来可以深入研究的方法可能有以下三种:(1)首先将初始视差图进行边缘检测,将边缘信息单独提取出来进行细化处理,然后将这些边缘信息加入到细化后的视差图中,这样可以避免信息缺失。(2)同样先进行边缘检测,细化处理时将边缘信息阈值提高,分割时尽量保留边缘信息,避免散点及误分割情况出现。(3)未来可以研究对边缘特征收敛性更高同时兼顾其他特征信息的分割方法。
3 结束语
本文提出了一种改进熵率超像素分割的分割一致性检验算法,使用基于熵率的超像素分割算法将参考图像分割,然后按照统计分析的方法计算出集中趋势值以区分保留值与剔除值,最后进行视差填充,得到优化后的视差图。通过对15组立体图像对进行误匹配率测试,验证本文算法的有效性及优越性。本文算法改进了传统分割一致性检验算法在处理低纹理图片时可能出现的负优化问题,并进一步优化了视差精化步骤的视差图效果,但最终得到的视差图仍然在边缘处存在鲁棒性不高的问题。究其原因主要在于超像素分割算法的局限性。未来可以将效果更好的分割算法应用到分割一致性检验算法中,在后续研究中可以针对此问题进行深入研究。
猜你喜欢
小型微型计算机系统(2022年1期)2022-01-21 02:55:06
劳动保护(2018年5期)2018-06-05 02:12:06
天津大学学报(自然科学与工程技术版)(2018年6期)2018-05-30 00:57:46
华人时刊(2018年23期)2018-03-21 06:26:16
测绘科学与工程(2017年3期)2017-08-16 02:46:00
中华建设(2017年3期)2017-06-08 05:49:29
测绘科学与工程(2017年1期)2017-05-04 03:40:46
现代计算机(2016年3期)2016-09-23 05:52:13
浙江大学学报(工学版)(2016年11期)2016-06-05 09:21:03
西部广播电视(2015年5期)2016-01-16 03:45:06
