
三维输入卷积神经网络脑电信号情感识别
2021-03-09 16:41:24蔡冬丽钟清华朱永升廖金湘韩劢之
计算机工程与应用 2021年5期
蔡冬丽,钟清华,朱永升,廖金湘,韩劢之
华南师范大学 物理与电信工程学院,广州510006
情感在人们的日常生活中起着至关重要的作用。目前,情感识别的研究对象有文本、语音、脑电以及其他的生理信号等。情感识别已经成为人工智能、计算机科学和医疗健康等领域的研究重点。早期的情感识别主要是基于面部表情或者语音来进行识别,后来有基于心率、肌电、呼吸等外围生理信号进行情感识别。与上述的方式相比,脑电(Electroencephalogram,EEG)信号作为中枢神经生理信号,其不会因为人们的主观因素而受到影响,更能够客观真实地反映人们当前的情感状态。因此,近年来脑电信号被广泛应用于情感识别研究领域[1]。
由于在大数据集上,使用深度学习通常比使用机器学习所取得的效果更优,其已成功应用在计算机视觉、语音识别、自然语言处理等各个领域,因此受到了各个领域的广泛关注。Li等人[2]从不同的EEG通道中提取功率谱密度(PSD)并将其映射到二维平面,构建了EEG多维特征图像(EEG MFI),并结合CNN和LSTM进行脑电情感识别。Tripathi等人[3]使用CNN在开源DEAP数据集[4]效价以及唤醒度上进行情感识别,平均准确率分别为81.406%和73.36%。Chen等人[5]利用经验模态分解(EMD)和近似熵进行脑电特征提取,使用DBN和SVM的集成进行情感分类。Salama等人[6]从多通道EEG信号中提取3D数据并作为3D-CNN模型的数据输入,在DEAP数据集效价和唤醒度两个维度上准确率分别是87.44%和88.49%。Song等人[7]提出了一种基于新型动态图卷积神经网络(DGCNN)的多通道脑电信号情感识别方法,平均准确率达到90.4%。Yang等人[8]在不同频段上提取微分熵,使用三维输入的卷积神经网络对DEAP数据集在效价和唤醒度上进行情感分类,平均准确率分别达到了89.45%和90.24%。陈景霞等人[9]提取了脑电信号的时域、频域以及其组合特征,采用卷积神经网络对DEAP数据集在效价和唤醒度上进行情感分类。目前,只存在较少的文献是采用组合特征作为分类器的输入数据进行情感识别,另外这些文献很少在采用组合特征的同时考虑电极之间的空间信息。
本文使用DEAP数据集,将单熵(近似熵、排列熵和奇异值分解熵)以及不同组合熵作为特征输入到三维输入的卷积神经网络进行情感识别。三维输入既可以保留电极之间的空间信息,同时又可以整合脑电提取的多种特征值。实验结果表明,与单熵作为特征相比,组合熵特征可以有效提高情感识别准确率。同时,利用EEG电极分布的空间信息比未利用空间信息时所取得的分类准确率有显著提高。
1 方法
1.1 近似熵
Pincus[10]将近似熵定义为相似向量从m维增加到m+1维时保持其相似性的条件概率。近似熵是一种非线性动力学参数,用于量化时间序列波动的规律性和不可预测性,表示时间序列的复杂性。因此,可以使用近似熵算法进行脑电信号特征提取,通过近似熵来反映脑电信号的复杂程度。在本文实验中,使用脑电信号求近似熵的算法步骤如下所示:
(1)设信号长度为N的一维脑电时间序列{u(i),i=1,2,…,N},按照以下式子:
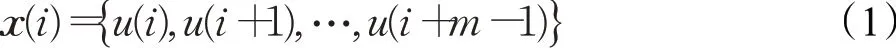
重新构造m维向量x(i)。其中参数m为比较窗口长度。
(2)依照下列给出公式,计算向量x(i)与向量x(j)之间的距离为:
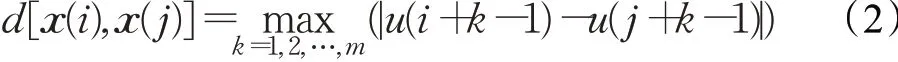
(3)给定域值r,统计d[x(i),x(j)]≤r的数目,并求出该数目与距离总数(N-m+1)的比值,记作Cm i(r):


(5)参数m加1,重复(1)至(4)的步骤,可以求出
(6)再根据Φm(r)和Φm+1(r)可求得近似熵为:
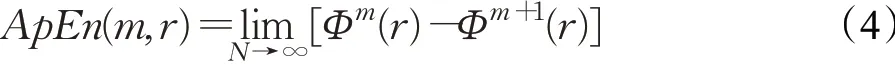
(7)对于脑电信号,ApEn(m,r,N)可通过统计值估计得到:
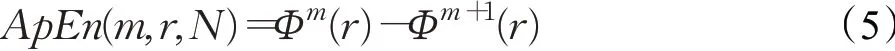
本文实验将脑电信号平均分割为1 s的长度,其中信号的频率为128 Hz,即时间序列长度N为128。相似容限边界r设置为0.2,比较窗口长度m为2。经过上述步骤计算,可以得到长度为1 s的脑电信号对应的近似熵。该数值可以反映时间序列中新信息发生的可能性,越复杂的脑电信号对应的近似熵越大。
1.2 排列熵
Bandt等人[11]提出了一种衡量一维时间序列复杂度的平均熵参数,称为排列熵,它和近似熵、样本熵[12]以及模糊熵[13]一样,都可以表示时间序列的复杂性。排列熵有计算简单以及较强的抗噪能力等优点。因此,同样可以通过排列熵来反映脑电信号的复杂程度。使用排列熵算法进行脑电信号特征提取的步骤如下:
(1)取给定长度为N的一维脑电时间序列u(1),u(2),…,u(N)。
(2)将原序列进行重构,用X(i)表示每个子序列,其中X(i)=u(i),u(i+L),…,u(i+(m-1)L),m表示嵌入维数,L表示延迟时间。
(3)接着对每个X(i)内部进行递增排序,即u[i+(j1-1)L]≤u[i+(j2-1)L]≤…≤u[i+(jm-1)L],如果两个值相等,就按照ji的下标i进行排序。因此,X(i)被映射到(j1,j2,…,jm),这是m!个排列中的一种,并且每个m维的子序列都被映射到m!种排列中的其中之一。
(4)经过上述步骤,将m维相空间映射到不同的符号序列(j1,j2,…,jm),总共有m!。
(5)计算每一种符号序列出现的概率分别为P1,P2,…,Pk,其中K≤m!,按照Shannon熵的形式,时间序列X(i)的k种不同符号序列的排列熵根据下式计算可得:

本文实验中,m的值设置为3,L为1,N为128。Hp值的大小表示时间序列X(i)的随机程度。排列熵越小,说明脑电信号越规则;越复杂的脑电信号,它对应的排列熵越大。排列熵的变化反映并放大了脑电信号的微小细节变化。
1.3 奇异值分解熵
奇异值分解(SVD)已广泛用于许多领域,例如降噪[14]和信号检测[15]等。在本文实验中,使用奇异值分解熵算法进行脑电信号特征提取。对于脑电时间序列x1,x2,…,xN,n维相空间可以通过窗口长度为m的滑动窗口均值进行重构。相关步骤如下所示:
(1)从x1,x2,…,xN中提取x1,x2,…,xn并将其作为n维相空间的向量1。接着从x1,x2,…,xN中提取x2,x3,…,xn+1并将其作为向量2。因此,可以获得一组行向量,利用这些向量,构造出一个m×n矩阵:
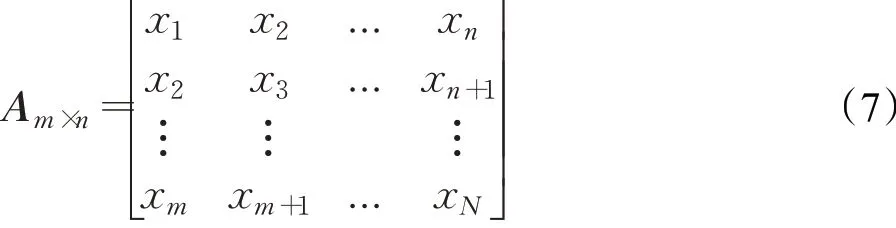
(2)根据SVD定理,将矩阵A分解为:
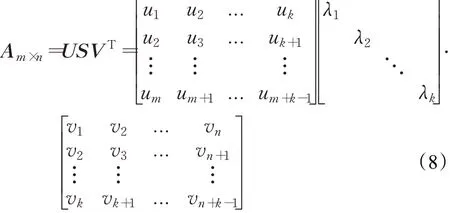
其中,U是一个m×k的矩阵,V是一个n×k的矩阵,并且满足UTU=I,VTV=I。定义对角矩阵S=diag(λ1,λ2,…,λk),其中k=min(m,n)。
矩阵S的对角元素λ1,λ2,…,λk被称为矩阵A的奇异值。这些奇异值是非负值并按照降序排列:λ1≥λ2≥…≥λk≥0。矩阵U包含了A的左奇异向量,矩阵V包含了右奇异向量。λ1与信号能量成正比,信号能量越高,奇异值λ1越大。
(3)将奇异值进行归一化:

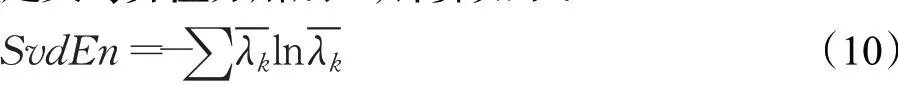
SvdEn表示奇异值偏离均匀分布的情况。在本文实验中,N为128,m的值设置为3,L为1。
2 实验步骤及结果分析
2.1 实验设计
2.1.1 实验环境
本文实验使用的硬件设备是Intel®Core™i7-8750H CPU以及NVIDIA GeForce GTX 1060 GPU。实验软件采用的是Python 3.6,同时使用了Google开源深度学习系统TensorFlow搭建神经网络。
2.1.2 实验数据
本文实验使用的数据是由伦敦玛丽皇后大学的研究团队开发的开源数据集DEAP。数据采集实验中,记录每个被试者在观看40个带有不同情感倾向的音乐视频时的脑电及其他生理信号。被试者观看1 min的音乐视频后,根据自我测评量表从愉悦度、唤醒度、控制度、喜欢程度以及熟悉度五个方面进行评价。实验记录的63 s的脑电信号是样本数据,被试者对上述五个评价维度的打分为样本数据对应的标签。数据集包含32通道的脑电信号和8通道的其他生理信号。
在数据预处理中,数据下采样至128 Hz并去除了眼电伪迹,同时应用了4.0~45.0 Hz的带通频率滤波器进行滤波。实验记录的EEG信号时长为63 s,其中前面3 s是基线数据。在本文实验中,只采用了经过预处理的32通道的脑电信号作为样本数据,并只取该数据集中的两个维度:效价(valence)和唤醒度(arousal),分别在这两个维度标签上进行二分类。以5作为阈值将效价和唤醒度上的评价值划分为两类,其中大于5的标记为1,小于或等于5的标记为0。
2.1.3 实验预处理
在本次实验中,为了增加实验的样本数,对实验数据进行分割,把63 s的脑电信号平分为63段1 s的信号。在本文中,选用了近似熵、排列熵以及奇异值分解熵分别对脑电信号进行特征提取。首先,计算前3 s的脑电信号特征平均值。然后计算后60 s脑电信号每秒的信号特征值,接着用后60 s脑电信号特征值分别减去前3 s的脑电信号特征平均值,最后得到减去基线信号后的一维特征向量ν32。
DEAP数据集获取脑电信号的电极分布是按照标准的国际10-20系统。图1左边是国际10-20系统的平面图,这里使用紫色来标记在DEAP数据集中使用了的电极。从左边的EEG电极图中,可以看到每个电极都邻近多个电极,这些电极在大脑的特定区域记录EEG信号。为了保留多个相邻通道之间的空间信息,根据电极分布图将一维特征向量以图1所示的方式构造二维特征矩阵(h×w)。其中,矩阵的h和w分别是电极在垂直方向和水平方向上的最大数。对于DEAP数据集,h和w的值都为9。此外,DEAP数据集中未使用的通道用零填充。

图1 构造二维矩阵
在本文实验中,每一段EEG信号分别提取了三种不同的脑电信号特征值,按照图1所示的方法将得到的一维向量转化为二维矩阵,得到三个二维矩阵。接着将这三个二维矩阵叠加为一个三维的矩阵,作为CNN的输入。具体转化过程如图2所示。
2.1.4 卷积神经网络
卷积神经网络是一种深度前馈神经网络,其已广泛应用于图像识别等各个领域。CNN具有较好容错性、自学习能力强等优点,同时具有自动提取特征、权值共享等优势。目前卷积神经网络模型参数设置只能通过人工多次实验选择确定,定义参数的搜索空间为:卷积层数为2~5个,卷积层特征图个数为16~512个,全连接层数为1~2个。通过多次实验,最终构建的卷积神经网络模型确定为由四个卷积层、一个全连接层以及一个softmax层构成。其中,CNN网络的输入是由三个不同特征提取方法分别得到的二维特征矩阵构成的三维特征矩阵。池化层的主要功能是降低数据维数,但其代价是损失一些信息。由于本文网络输入的数据量不大,为了尽量保留有用的信息,在本文的CNN网络中没有加入池化层。具体的CNN网络模型结构如图3所示。其中,第一个卷积层有32个特征图,后面的卷积层特征图是前面卷积层的两倍,分别为64、128和256。卷积核大小为4×4,步长为1。在卷积运算后,加入SELU激活函数,使模型具有非线性特征变换能力。接着连接一个全连接层,将256个9×9特征图映射到特征向量f∈R1024。网络最后是一个softmax分类器,输出情感识别的预测值。本文使用截断正态分布函数来初始化权重,并使用Adam优化器来最小化交叉熵损失函数。初始学习率设置为0.000 1。采用Dropout以50%的概率输出避免过拟合。此外,使用了L2正则化以避免过拟合并提高泛化能力,正则化项的权重设置为0.5。
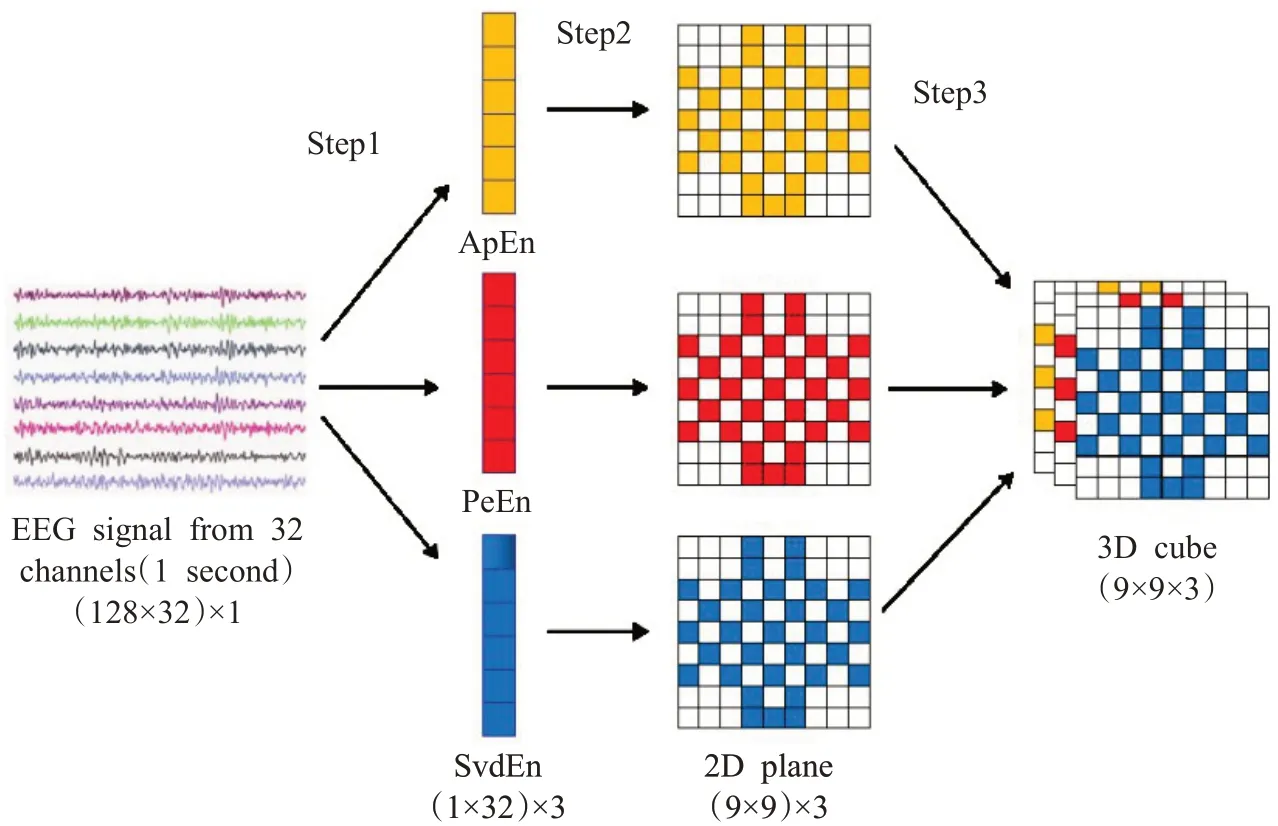
图2 脑电信号特征提取和转化过程

图3 CNN网络模型结构
2.2 实验
本文实验使用的实验数据是DEAP数据集中32个被试40次实验所采集的脑电信号以及对应的标签。在实验预处理时以1 s的时间间隔将每次实验的脑电信号分为了63段,其中前面3 s的是基线信号,再根据上述的方式进行特征提取。本文实验在划分数据集之前先对被试的所有样本数据进行随机打乱操作。对每个被试的数据进行10重交叉验证,并计算平均值作为被试的最终结果。本文实验的输入特征共有7种,包括单熵特征和组合熵特征,分别为ApEn、PeEn、SvdEn、Multiplefeatures1(ApEn和PeEn组合)、Multiple-features2(ApEn和SvdEn组合)、Multiple-features3(PeEn和SvdEn组合)、Multiple-features4(ApEn、PeEn和SvdEn组合)。其中,经多次的对比实验分析,熵组合的排列顺序对识别准确率影响不大。参照上文实验预处理的方式步骤构造三维特征矩阵,其中ApEn、PeEn和SvdEn为9×9×1的特征矩阵,Multiple-features1、Multiple-features2以及Multiple-features3为9×9×2的特征矩阵,Multiplefeatures4是9×9×3的特征矩阵。将以上7种特征矩阵分别输入图3所示的卷积神经网络中进行实验,即在每个维度上共进行7组实验。此外,本文还根据常规的熵组合方式进行了对比实验。该实验在构造输入特征时并没有考虑EEG电极空间信息,即输入特征没有根据EEG电极分布图将一维特征向量转化为二维特征矩阵。将7种无空间信息的特征分别输入到与图3相同网络结构的一维卷积神经网络进行实验,实验设置与本文提出的神经网络设置相应一致。
2.2.1 不同特征提取方法的结果对比
为了验证单熵特征、组合熵特征以及空间信息对情绪识别的影响,本文实验分别对包含了空间信息和未包含空间信息的单熵特征以及不同组合熵特征在效价和唤醒度上进行实验。结果分别显示在图4和图5中。其中,图中的蓝色柱状图表示没有利用空间信息的一维卷积神经网络的实验结果,红色柱状图表示本文提出的神经网络的实验结果。
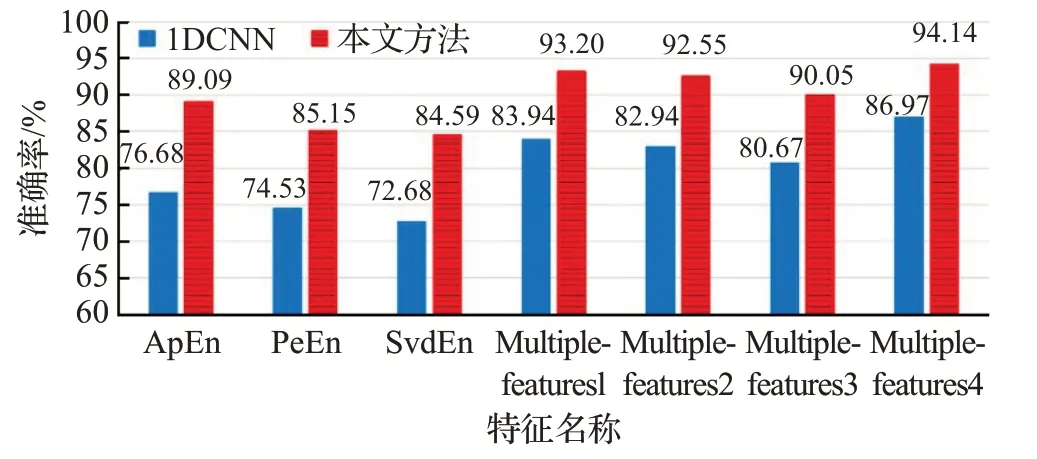
图4 效价维度上不同特征的情感识别平均准确率
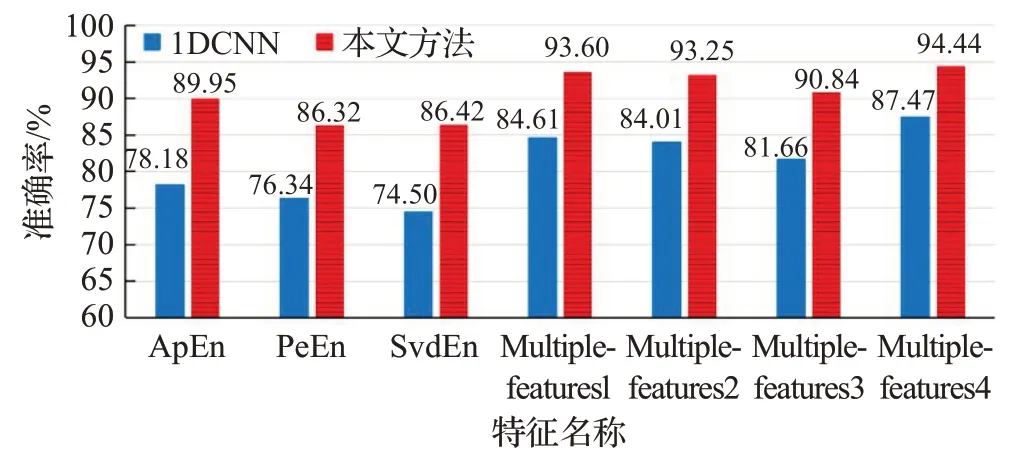
图5 唤醒度维度上不同特征的情感识别平均准确率
从图4和图5中可以看到,三种单熵特征进行比较,使用近似熵作为特征比排列熵和奇异值分解熵分类准确率更高。近似熵在一维卷积神经网络上效价和唤醒度的平均准确率分别为76.68%和78.18%,近似熵在本文提出的网络上效价和唤醒度的平均准确率分别为89.09%和89.95%。全部特征进行比较,组合熵特征比单熵特征分类准确率都有所提高。其中使用Multiplefeatures4作为输入特征时平均准确率最高,在一维卷积神经网络上效价和唤醒度的平均准确率分别为86.97%和87.47%,比单熵的最高平均准确率分别提高10.29个百分点和9.29个百分点。在本文提出的网络上效价和唤醒度的平均准确率分别为94.14%和94.44%,比单熵的最高平均准确率分别提高5.05个百分点和4.49个百分点。实验结果表明,使用组合熵作为特征输入时能显著提高情感识别准确率。此外,对利用了空间信息的实验结果与没有利用空间信息的同一类型熵特征实验结果进行比较,在效价和唤醒度两个维度上,利用了空间信息的所有熵特征都比没有利用空间信息的熵特征作为输入时取得的情感分类准确率高。其中使用Multiplefeatures4作为输入特征时,在效价和唤醒度两个维度上的分类准确率分别提高了7.17个百分点和6.97个百分点。在实验结果表明,利用EEG电极分布的空间信息能有效提高情感识别准确率。
为了进一步分析本文提出的神经网络的实验结果,图6、图7分别显示了在效价和唤醒度维度上32个被试在不同特征上的情感识别准确率。从图中可以看到,使用单熵作为输入特征时,情感识别准确率在不同被试上的差异较大,总体的准确率也相对较低。而使用Multiplefeatures4作为输入特征时,情感识别准确率在不同被试上的差异较小,准确率基本维持在94%左右。单个被试在效价和唤醒度两个维度上的最高分类准确率分别为98.17%和98.52%。与使用单熵作为输入特征进行比较,使用组合熵特征Multiple-features4作为输入特征时,除了被试11在唤醒度维度上的分类准确率略有下降外,其他被试在两个维度上的分类准确率都有所提高。被试11在唤醒度维度上出现分类准确率下降的原因是由于采用ApEn作为输入时已达到很高的分类准确率,所以采用组合熵时会比较难提升分类准确率而维持差不多的分类准确率,另外由于实验每次的训练和测试数据是随机选取的,实验结果会在一定的范围内波动,所以会存在分类准确率略有下降的可能。实验结果表明,在提取脑电特征时,不同熵进行组合可以相互补充,有效提高情感识别准确率。
2.2.2 相关方法的结果对比
本文还将实验结果与其他方法所得的实验结果进行比较。Samarth等人使用深度神经网络和卷积神经网络分别对EEG信号进行情感分类。Yin等人[17]提出了一种基于多融合层的堆叠式自动编码器集成分类器识别情绪状态。Elham等人使用三维卷积神经网络针对多通道脑电图数据进行情绪识别。Yang等人在不同频段上提取微分熵,使用三维输入的卷积神经网络进行情感分类。分类准确率如表1所示,本文所提出的使用三种熵组合特征作为输入的卷积神经网络在效价和唤醒度两个维度上的平均准确率都超过了这四种方法。
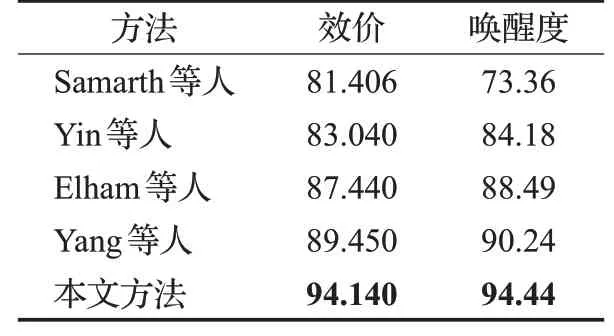
表1 与其他方法对比结果%

图6 效价维度上32个被试在不同特征上的情感识别准确率
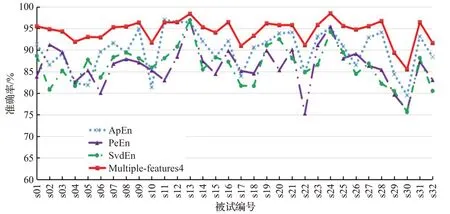
图7 唤醒度维度上32个被试在不同特征上的情感识别准确率
3 结束语
本文使用DEAP数据集中32个脑电通道信号进行实验,首先将每次实验的63 s脑电信号以1 s长度进行分割,分别计算出每秒的熵值。其中前3 s的脑电信号为基准信号,基准信号的熵值取这3 s熵值的平均值。接着用后60 s脑电信号的熵值减去基准信号熵值得到除去基准信号后的一维特征向量ν32。按照图1所示的方法将一维向量转化为二维矩阵。在本文实验中,对近似熵、排列熵和奇异值分解熵进行实验分析,即每一段EEG信号分别提取了三种不同的脑电信号特征值,得到三个二维矩阵。将这三个二维矩阵以及其不同的组合作为特征分别输入到卷积神经网络进行效价和唤醒度两个维度上的情感识别。
实验结果表明,与单熵特征相比,组合熵特征能有效提高分类准确率。此外,利用EEG电极分布的空间信息也能有效提高情感识别准确率。使用三维输入的卷积神经网络结合组合熵特征能保留电极之间的空间信息,同时可以充分提取脑电信号特征。与其他相关方法相比,该方法在效价和唤醒度两个维度上分类准确率显著提高,其平均分类准确率分别为94.14%和94.44%。
在脑电信号的研究中,通常把信号分为Delta、Theta、Alpha、Beta、Gamma五个频段再进行特征值计算。而在本文中,直接在整个频域上计算特征值。在今后的研究中将考虑分频段提取特征,并对脑电信号提取时序特征、频域特征、统计学特征等不同类型的特征及其组合进行进一步研究。另外,本实验只使用了数据集中的脑电信号,没有利用其他的生理信号,如何充分利用其他生理信号结合脑电信号来提高情感分类准确率也将是未来的研究工作之一。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31 08:57:52
心理学探新(2022年1期)2022-06-07 09:16:02
成都信息工程大学学报(2021年4期)2021-11-22 07:44:40
科技传播(2019年24期)2019-06-15 09:29:28
猪业科学(2018年5期)2018-07-17 05:55:18
北京航空航天大学学报(2017年9期)2017-12-18 07:12:22
地理空间信息(2017年2期)2017-03-06 08:35:12
中国当代医药(2015年8期)2015-03-01 02:01:55
中成药(2014年9期)2014-02-28 22:28:58
汽车电器(2014年8期)2014-02-28 12:14:29
