
机器学习在网络管理系统中动态资源分配的应用研究
2021-03-08 10:14林逍
科学与财富 2021年4期
关键词:机器学习
林逍
摘 要:通信网络的发展将网络的维护和操作变得复杂化,在网络管理中减少人工操作有利于提高效率,规避错误。随着人工智能技术的发展和网络设备的智能化,网络管理的智能化将逐渐成为可能。
本文首先提出网络管理系统智能化需求点:动态资源分配。要实现的是对信道资源的合理分配,以降低全网小站申请、占用资源的平均时间。
本文对动态资源分配问题的模型进行抽象,据此仿真搭建了神经网络,并以强化学习算法进行训练,与传统的先到先分配、短任务优先分配、小任务优先分配、随机分配等算法共同进行测试,对所产生的结果进行对比分析。
关键词:网络管理系统,机器学习,动态资源分配
1 需求分析
对于网络管理系统,智能化就是指那些具有能动地满足网络管理员的各种需求的属性。
为保证通信系统长期可靠地服务,极为关键的一点功能需求有:对信道资源进行高效地分配管理。针对功能需求,本文希望网管能够能在其中能动地实现一些智能化。
资源分配的本质是资源的有限性,目标是使得整体价值最大。资源的目标有时候是互斥的,比如一项决定对A目标实现是有利的,而对B目标达成是有害的,所以需要对互斥的目标设定权重,从而决定是否要采取这项决定。
目前在网络管理系统中,可能存在约上千个终端小站,当有需要时,这些小站将通过返向链路传输文件,这就需要向中心站申请信道资源。而中心站所能分配的信道资源是有限的,这就不可避免地会存在传送任务需要排队的问题。
为了使得在最短时间内,完成所有终端小站的文件传输任务,分配算法的选择至关重要。目前常见的资源分配算法有先到先分配算法(First Come First Served,FCFS)、最短任务优先分配算法(Shortest Job First,SJF)、最小任务优先分配算法(Minimum Job First,MJF)及随机分配算法(Random)。
显然,在何时给哪个任务分配资源,这是一个非常典型的智能决策问题,非常适合采用强化学习方法进行。
2 模型设计
在本实验中,本文将动态资源分配问题抽象为以下模型:
已知网络管理系统中的各个终端小站,在有需求会向中心站申请资源传送文件,中心站所能分配的信道资源是有限的。将小站的文件传送申请称作一个任务,将中心站可分配的信道资源称为资源池。当任务申请到达中心站时,若资源池已满,则任务进入等待池。设定任务在每一个离散的时间步长t到达。智能体将在每一个时间步长选择一个或多个等待的任务进行分配。
假设每个任务的信道资源需求在它到达时是已知的,更具体地,对每个任务j,其所需要的资源是rj,它的任务持续时间,也就是所需要占用信道的时间是Tj。模型所分配的各个任务是同一优先级的,换句话说,同一优先级的任务将进入同一等待池。以任务平均完成时间的最小化作为网络训练的目标。
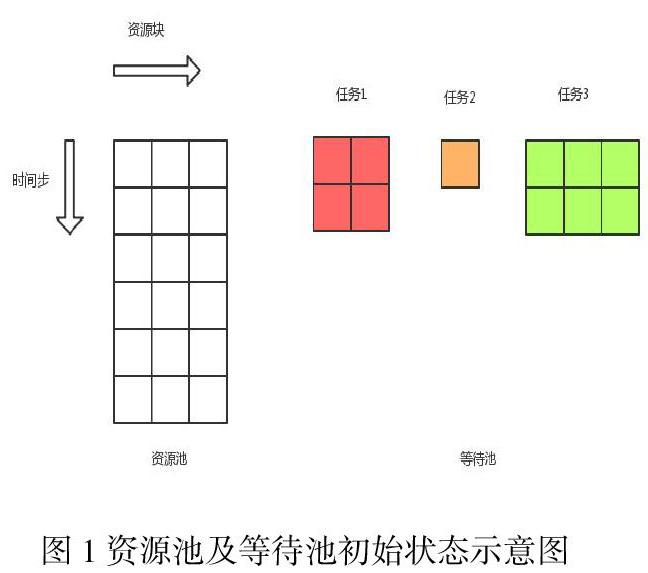
用当前资源池中的实时占用情况、等待资源分配的申请队列及后台日志来描述系统状态。如图1是资源池的初始状态及等待池中任务的示意图。不同颜色代表不同的任务。任务块横向格数代表资源需求,纵向格数代表时间需求。
行动空间用A = { ,1,...,M}表示,其中a = i表示“对等待池第i个任务分配资源”; a = 表示资源池已满,即不可再分配任务。在每一个时间步,时间被冻结,直到智能体做完这些选择。一旦智能体选择了行动a = ,则行动结束,进入下一个时间步,资源池图像上的任务下移一步,任何新到达的工作都会显现出来。
对能够降低所有任务平均完成时间的行动给予正的奖赏,反之给予负的惩罚。在每一个时间步设置奖励为-J,在这里J是当前系统中的任务数量总和,包括资源池、等待队列及后台日志中的所有任务。
3.仿真训练
将智能体的策略表示为一个神经网络,它的输入是环境当前状态空间构成的矩阵,输出是可能采取行动的概率分布。训练过程中,在每一个episode中,都有固定数量的任务到达,根据策略进行安排。当所有作业均执行完毕后,episode终止。本实验设置了多组不同的任务到达序列,每组称为一个任务序列。
在每次训练迭代中,模拟每个任务序列在每个episode里使用当前策略的可能操作,并使用結果数据来改善分配之后所有任务序列的策略。记录每个episode的每个时间步长的所有环境状态、行动及奖励信息,并使用这些值计算在每个episode每个时间步t的累计奖励vt。然后使用强化学习算法里的梯度下降策略来训练神经网络。
4.测试结果
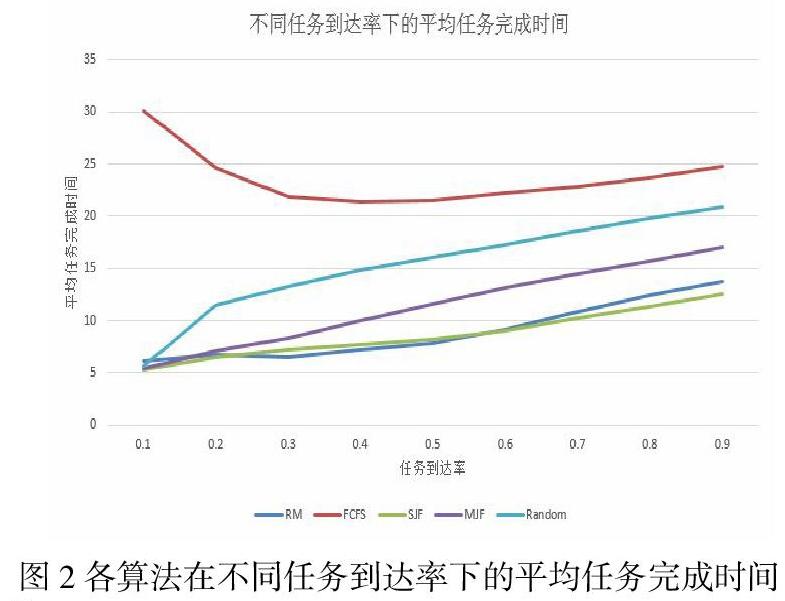
当等待池中的最大任务数量M取5时,整个实验过程,用各个算法进行分配,所有的任务平均完成时间与任务到达率关系如图:
5.结论
以缩短全部任务平均完成时间为目标,本文所测试的几种不同的分配算法中,先到先分配(FCFS)算法表现最差,平均任务完成时间最长;次差为随机分配(Random)算法;当任务负载率较低时,强化学习所训练的RM算法、短任务优先算法(SJF)及小任务优先算法(MJF)的表现几乎没有区别;当任务负载率较高时,MJF算法的表现显著不如RM算法及SJF算法,此时RM算法优于SJF。而当任务负载率进一步提高之后,RM算法与SJF算法的表现趋于一致。
故而,本文所用的强化学习算法,在动态资源分配问题中,对于降低任务平均完成时间有着较好的表现,证明了强化学习算法的有效性。而强化学习算法在本实验中的表现,完全可以迁移到网络管理系统中的信道资源分配。
参考文献:
[1] 闻新,周露,王丹力,熊晓英等 MATLAB神经网络应用设计.北京科学出版社,2001.5.
[2] 张文鸽,吴泽宁,途洪波神经网络的改进及应用河南科学Vol.21,No2,2003.
[3] 戚涌,李千目,刘凤玉基于BP神经网络的网络智能诊断系统.微电子学与计算机,2004,21(10):10-13,18.
[4] 焦李成,神经网络计算[M].西安:西安电子科技大学出版社,1993.9.
[5]陈桦,程云艳.BP神经网络算法的改进及在Matlab中的实现.陕西科技大学学报.Vol.22,No.2,2004.4.
猜你喜欢
电子技术与软件工程(2016年22期)2016-12-26
时代金融(2016年27期)2016-11-25
科教导刊(2016年26期)2016-11-15
活力(2016年8期)2016-11-12
电脑知识与技术(2016年20期)2016-08-19
电脑知识与技术(2016年12期)2016-06-14
科教导刊·电子版(2016年10期)2016-06-02
科教导刊·电子版(2016年10期)2016-06-02
电脑知识与技术(2016年3期)2016-04-07
物联网技术(2015年9期)2015-09-22
