
一种矩阵和排序索引关联规则数据挖掘算法
2021-03-08 01:06:12刘彦戎
计算机技术与发展 2021年2期
刘彦戎,杨 云
(1.陕西国际商贸学院 信息工程学院,陕西 西安 712000;2.陕西科技大学 电子信息与人工智能学院,陕西 西安 710021)
0 引 言
在互联网产业急速发展的情况下,信息技术和信息经济也发展迅速,由此在各行各业中数据挖掘技术的应用越来越广泛。数据挖掘技术从现有的未知数据中可以发现大量具有潜在价值的信息或模式,当这个理论提出时,立刻引起了科学界的广泛关注。在数据挖掘领域中最重要的研究方向是关联规则挖掘,关联规则技术的实现是以数据之间的联系为基础来实现其可信度的支持。该算法最初是被P.-G. Cheng[1]作为市场购物篮分析理论提出的,在此过程中通过研究顾客购买行为建立关联知识,来指导商业贸易中交易事项的数据集合[2]。由于数据具有多样性的特点,从海量数据中通过有效探索和筛选可得到有效数据,从而可以为智能人机交互提供技术支持。在数据挖掘过程中,关联规则技术得到了长足发展,已在银行风险预警、金融证券分析和移动通信方面深入应用,并显示出较好的应用前景和巨大的发展潜力。
许多学者在数据挖掘方面做了大量的研究,为其发展做出了贡献。传统关联规则数据挖掘的改进大多是基于Apriori[3-5]算法,Apriori算法最大的缺陷是需要对数据库进行多次扫描[6]才能得到频繁项目集,这就严重影响了数据挖掘的运行效率。魏玲等人提出了NFUP算法[7],该算法基于强大项目集的概念,将强大项目集加入到候选项目集的小数量中,并采用早期裁剪策略来减少扫描数据库的次数。Dean. J等人[8]提出一种改进的基于客户关系管理系统的数据挖掘关联规则Apriori算法,该算法删除了大量无效事务,随着事务的减少,数据库的规模也随之变小,减少了后续扫描的记录,提高了数据挖掘的处理效率[9-10]。Rakesh等人[11]针对候选项集数量多、扫描数据库耗时长等问题,提出了一种有效的挖掘候选项集的算法,该算法克服了数据库扫描时间长的缺陷,减少了候选项集的数量,提高了执行效率。Linden G等人[12]提出了一种基于模糊技术的数据类型统一识别方法,该技术可以使所有不同的数据类型都能以统一的方式进行处理。Borthakur D[13]针对Apriori算法中对数据库进行多次扫描并生成大量候选项集的性能瓶颈,提出了一种新的算法,该算法通过一个预先设定的过滤器过滤掉与挖掘目标无关的事务,这种方法大大提高了算法的整体性能。钱光超等人[14]提出了一种新的基于布尔矩阵的Apriori算法,该算法通过关联图和矩阵裁剪的方法减少了候选项集的数量,实验结果表明,该算法使用一次就降低了系统数据采集的性能。S. Anekritmongkol等人[15]提出了一种新的基于布尔模型的关联规则数据挖掘压缩算法,主要思想就是通过压缩数据可以大大减少扫描数据库的次数。J.Pavon等人[16]提出了一种结合两者最佳特征算法的矩阵算法,该种组合算法利用矩阵和向量等简单结构来生成频繁模式,同时对候选集的数量进行了最小化处理,从而实现比Apriori算法和FP-growth[17]算法更高效的计算。
基于相似度的Apriori算法是Li X等人[18]所提出的,他们把余弦相似度的阈值作为Apriori算法的改进策略。研究调查发现Apriori算法主要存在的问题就是在结束扫描库之后生成过多的候选项目集,所以改进关联规则的主要方式就是缩短扫描时间,提高扫描效率。采用矩阵算法对数据库进行扫描,将项目集改变为布尔值可以提高效率,但是无法删减重复的事务和项目集,还会导致计算量的增加,所以该文提出了新型的矩阵和排序索引关联规则数据挖掘算法,这种方法可以在一次扫描过程当中提高算法的执行效率,而且删除不需要的项目集。
1 一种矩阵和排序索引关联规则数据挖掘算法
该文在深入探讨了传统关联规则之后,提出一种改进的矩阵和排序索引关联规则数据挖掘算法,该算法简称为IMSIA。算法的基本思想是:结合矩阵算法k-频繁项集生成中的高效率和排序索引的高搜索速度的优点,将交易数据库转换为交易矩阵,然后不再扫描和使用交易数据库,直接扫描交易矩阵,删除之前的初始矩阵,在删除矩阵之前,将矩阵按标记序列放置随后搜索表,删除后更新两个标记序列。将删除的矩阵与其通过新矩阵获得的转置矩阵相乘,在矩阵的上三角中分析其数据并搜索序列,从而得出两个准确的频繁项集。利用所计算出来的频繁项集,建立排序索引矩阵,矩阵和频繁项集之间可以使用向下的方式进行连接。
1.1 Apriori关联规则挖掘算法
在关联规则算法当中,I表示项目,D表示事务数据库,T表示数据库当中的一组项目。且元素T⊂I,TID表示任何一个事务的标识符。当满足A∩B=∅、A⊂I、B⊂I条件时,A⟹B的形式称为关联规则。A⟹B的关联规则是在存在支持度的事务数据库中D建立的,其中p指概率,s指事务数据库中所占的百分比。关联规则在交易数据库中存在置信度c,如式(1)和式(2):
sup(A⟹B)=P(A∪B)
(1)
confidence(A⟹B)=P(B|A)
(2)
一个项目集即是包含一组项目的集合,包含k个项目的集合称为k-项集。在一个项目集中若是存在频繁项集,则必定具有最小支持度min_sup,关联规则中若是存在强关联规则,该规则中的隐含条件一定是包含最小支持度阈值和最小置信度阈值。
Apriori算法的思想是先搜索而后逐层迭代搜索项集的过程,在搜索的过程中首先扫描事务数据库,并计算每个数据项的支持度,生成候选项集C1,利用支持阈值生成频繁为1-项集L1。Apriori算法的思想是先搜索而后逐层迭代搜索项集的过程,在搜索的过程中首先扫描事务数据库,并计算每个数据项的支持度,生成候选项集C1,利用支持阈值生成频繁为1-项集L1。将生成的L1项集与L1项集自身进行与运算得到候选项集C2,完成事务数据库的再次搜索并将计算得出的候选项集C2的支持度与最小支持度min_sup相比,取其最小者为2-项集L2,以此类推,若事务数据库中找不到频繁项集,则算法结束。
1.2 矩阵关联规则挖掘算法
要实现矩阵关联算法的规则,首先将事务数据库集合D转变为布尔矩阵[19],然后对其中所包含的n个事物和m个项目进行排序,用项目矩阵表示的整个数据库如下所示:
其中,Aij∈I(0≤i≤m,0≤j≤m),元素{Aij}在矩阵Amn中的定义方程为:
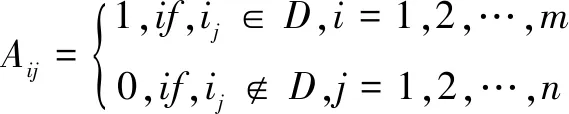
(3)
在矩阵Amn中包含了表示每一事务的行m和表示每一项的列n。在定义方程中若任意一个事务数据库Di存在项目i的第j项,则{Aij}的值为1,若不存在项目i的第j项,则{Aij}的值为0,当矩阵A是一个事务向量时,也可表示为a1,a2,…,am(具有m行向量的矩阵)。
矩阵关联规则具有属性1:不包含任何频繁出现的项目集中,一定也不包含(k-1)频繁项目集;属性2:任何非频繁项集的子集也是非频繁项集。
1.3 改进的事务矩阵和标记序列扫描
Apriori算法在求解的过程中首先需要求出候选项集Ck,然后对频繁项集Lk执行批处理操作,生成频繁项集的候选集数量较大,同时所有频繁项集要对数据库进行扫描,该操作占用系统内存空间较大和CPU处理时间较长,因此很难适应海量数据挖掘。矩阵关联规则挖掘算法虽然不删除非频繁项和事务,但还需要搜索数据以找到频繁项集,从而增加了计算量。尽管这些算法已经能够减少候选集的数量或通过修剪策略来提高挖掘效率,但仍不能完全解决候选集产生的问题。
索引最关键的特征是可以让检索信息速度更快,利用索引号可以完成向搜索项目集跳转,假如该行不满足下行连接条件,则不需要增加扫描量,从而提高了项目集挖掘的速度。在生成2-频繁项集的算法过程中有计算量大的缺点,由此导致算法的效率低下,矩阵算法在得到频繁项集前先将事务数据库转换为事务矩阵,然后通过分析得到上三角矩阵,这个过程中省略了向下连接和修剪的步骤,这样就大大减少了计算步骤,提高了项集的生成效率。该文在分析实验结果的基础上,提出结合改进的关联规则数据挖掘方法和索引优点的IMSIA算法,此算法较好地解决了多个数据库连接过程中产生大量候选集的问题。
步骤如下:将事务数据库转换为布尔数据库事务矩阵D,并将标记序列事务对应的矩阵保存到表中相应的项目中,建立一个事务数据库,该事务数据库包含m×n个项目、对应的标记序列为Lr={1,2,…,m}和Lc={1,2,…,n}。在删除矩阵的属性时,必须为删除的相应项目序列进行标记。删除矩阵后,可以通过相乘获得S=A×AT。
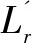
1.4 改进的自适应排序索引矩阵
由于验证算法需要搜索数据库并生成候选项,因此会占用大量内存并增加I/O成本。索引可以提高检索信息的速度,但是内存编号中保存排列索引所占内存较少,并能通过索引号来跳转搜索序列,如果该行不满足向下连接的条件,则无需进行扫描,在此基础上减少了搜索时间、搜索数量、内存占用搜索项集量和I/O开销。该文在改进矩阵算法的基础上,结合改进的自适应排序索引矩阵,仅扫描数据库一次,无需生成候选集,并根据选择排序规则进行排序,提高了计算效率和算法的执行效率。具体实现步骤如下:
(1)当频繁项集满足k>2时,使用改进的自适应排序索引方法以搜索第k个项集(k≥3)。
(2)使用降序排列的1个项目集L作为矩阵的列,在建立排序索引的过程中,按照降序(k-1)项进行设置。例如:行项目集I2对应于值1,I4对应的值为1,则该行表示2个项目集I2I4。其中,每个项目集的每行(k-1)项目也与安排的编号递减顺序保持一致。
(3)由于排序规则对排序结果的影响较大,通常是按照自行确定规则的方法,无法选择最优排序规则,因此提出了置信度和支持度之间的自适应最优选择规则。通过计算每个项目集的支持度和置信度,比较min_sup和min_conf的值,如果匹配的项目集数量较少,则选择相应的min_sup或min_conf(如果数据库仅给出一个参数)作为给定参数默认的排序规则。
(4)依据每一列当中非零元素的行号顺序,将其保存到数组当中,如果最小支持度的阈值大于项目数,可以将其所对应的频繁项目集删除,对于每一列,使用V(i+j)项集的行号值来替换第j个项集的非零元素,用下一个位置号作为搜索来替换原始列值1,分配最后一个非零元素为当前列的值。对频繁k-项集Lk(k≥3),在进行数据挖掘时采用的是向下连接排序索引矩阵的方式实现的。
当k=3时,以R1为目标开始扫描,此时完成以索引号为目标的最后一列扫描,之后通过索引号的导引完成Rx的扫描,将扫描得到的结果与对应的R1和Rx相连得到3-项集。得到的项目集再与具有最小支持数的项目集连接,对项集进行扫描按照行排列的方式,直到所有的频繁项集都处于连接转态,此时得到新的项集。最后根据关联规则数据挖掘的属性确定是否继续进行扫描生成4-项集。当k=3时,按以下步骤生成频率k-项目集:
①利用向下连接的方法扫描以建立好的排序索引矩阵,如果在扫描的行中不存在“1”,但是具有与k-2相同的索引号时,则直接按照对应的索引号进行跳转,跳转到的行与(k-1)Ry连接形成k-项目集。如果没有在扫描数据库的过程当中找到继续连续的条件,则可以跳过该行继续进行下一行扫描过程。
②使用较小的两个(k-1)-项目集支持数作为连接的k-项目集的支持数。
③按行方式,直到扫描最后一行,将所有的频繁(k-1)-项目集连接,得到所有的频繁k-项目集。然后根据关联规则属性确定是否继续生成频繁(k+1)-项目集。
2 实验结果
2.1 举例分析
假如存在事务数据库,设最低支持度为20%,事务数目为10,如表1所示。
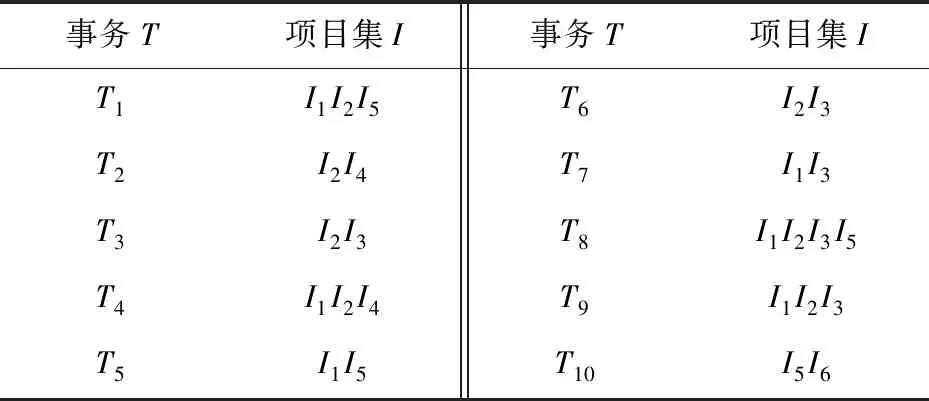
表1 事务数据库D
根据上述数据库,可以得到矩阵A:

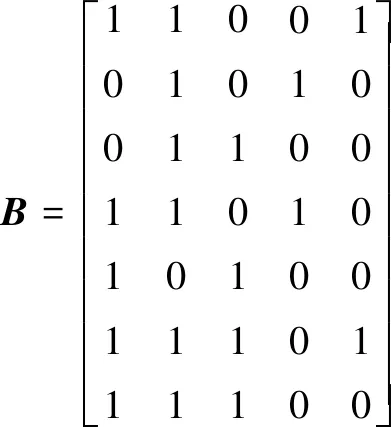

根据编号对形成的6个频繁2-项集进行排序,在项目I4对应的列中只存在一个“1”,由此形成的I2I4项目集与其他2个项目集无法进行连接,故删除事务数据库中与I4对应的列和行,生成结果如表2所示。

表2 排序索引矩阵
如表2所示,a,b,c,d和e分别表示序号,即在表中5个序号表示的行号只具有索引的作用。首先,用I2I1扫描第1行,将I1的搜索列删除,以索引号c跳到第三行,即I1I3的行,将第1行和第3行连接起来,获得频繁3-项集I2I1I5。I2I1I3的支持度为4,I2I1和I5I1的支持度分别为4和2,因此I2I1I5的支持度为2。继续扫描第2行和第3行,直到最后一行,Apriori算法在此步骤中形成候选3个项集,并且有6个,故该方法不利于算法效率的提高。频繁3-项集L3是{I2I1I3(4),I2I1I5(2)}通过使用排序索引关联矩阵得到的,在生成L3后,对其中的两个项集再次建立排序索引,用索引号a和b进行向下连接,在此连接过程中不满足产生4-频繁项集的条件,至此算法运行结束,如表3所示。
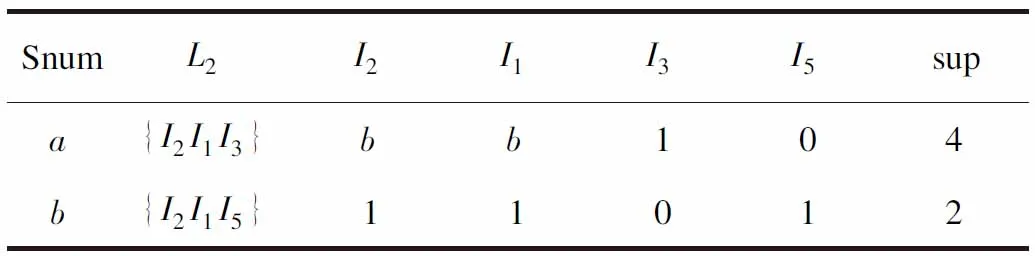
表3 L3排序索引矩阵
频繁1-项集L1、频繁2-项集L2、频繁3-项集L3、频繁4-项集L4的取值分别为{I2(7),I1(6),I3(6),I4(2),I5(2)}、{I2I3(4),I2I1(4),I1I3(4),I2I5(2),I2I4(2),I1I5(2)}、{I2I1I3(4),I2I1I5(2)}及空,因此频繁3-项集L3为最大。
2.2 实验结果和数据库分析
依据算法的时间复杂度可以发现,IMSIA算法和Apriori算法在对数据库进行扫描时的时间复杂度分别是Q(m)和Q(n×m),对比后发现,IMSIA算法扫描数据库的时间较短。在实验中,利用随机函数Random()生成所需数据集,当每次输入项目集|I|和事务|T|时,数据库当中的随机函数会生成数据集。在数据集的生成过程中不存在外界干扰因素,可以充分反映所提出算法的高效性能。
为了进一步深入了解改进算法的优势,对矩阵算法、Apriori算法和IMSIA算法的内存使用情况和算法运行时间进行比较。实验环境采用Java语言下的Eclipse环境搭建,操作系统用Windows 7,硬件使用Pentium(R)双核2.8 GHz/5.0 GB。
分析不同算法在最小支持度和相同数据集下的运行时间,IMSIA在k=2时的运行时间为生成矩阵乘以矩阵。当k≥3时,改进后的IMSIA算法所使用的运行时间是矩阵当中搜索项目集和将项目进行排序时间的总和。计算Apriori算法总运行时间时,需要生成候选项目集时间、扫描数据库时间和修剪项目集时间相加得出。图1对比了多种支持度运行时间,分析该图可得,处于同一个数据集(|T|=1 000,|I|=30)下,改进后的IMSIA算法和每种支持度下的运行时间均小于Apriori算法和矩阵算法。这表明在计算频繁2-项集之前先删除了无用的项目和事务,减少不必要的计算量,提高了计算效率,因此改进算法在计算时间上具有较好的优越性。在支持度不同的情况之下,对比三种算法所使用的计算时间,可以发现IMSIA算法效率较高,消耗时间较短,因此优势更为明显。
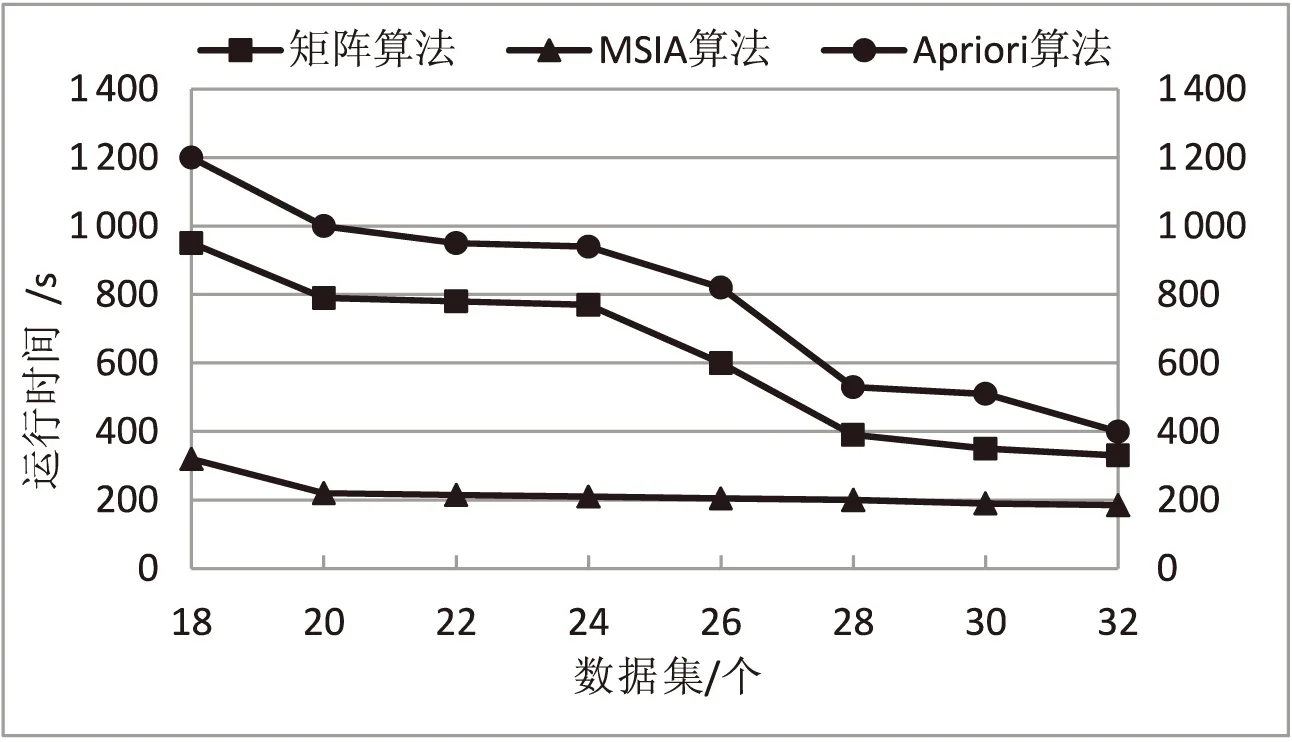
图1 不同算法的运行时间支持度
在数据集不同、支持度相同的前提下对比运行时间,结果如图2所示。7个随机生成的长度不同的数据集为:D1(|T|=100,|I|=15),D2(|T|=300,|I|=30),D3(|T|=500,|I|=40),D4(|T|=1 000,|I|=50),D5(|T|=1 500,|I|=60),D6(|T|=5 000,|I|=80)和D7(|T|=10 000,|I|=120),将min_sup计数设置为28。当设置参数不同时,矩阵算法的运行时间小于Apriori算法、大于IMSIA算法,由此可以得出,改进算法具有更好的执行效率,此外,当数据集的数量成线性增长时,所提出的IMSIA算法更能体现其高效率和可扩展的性能。
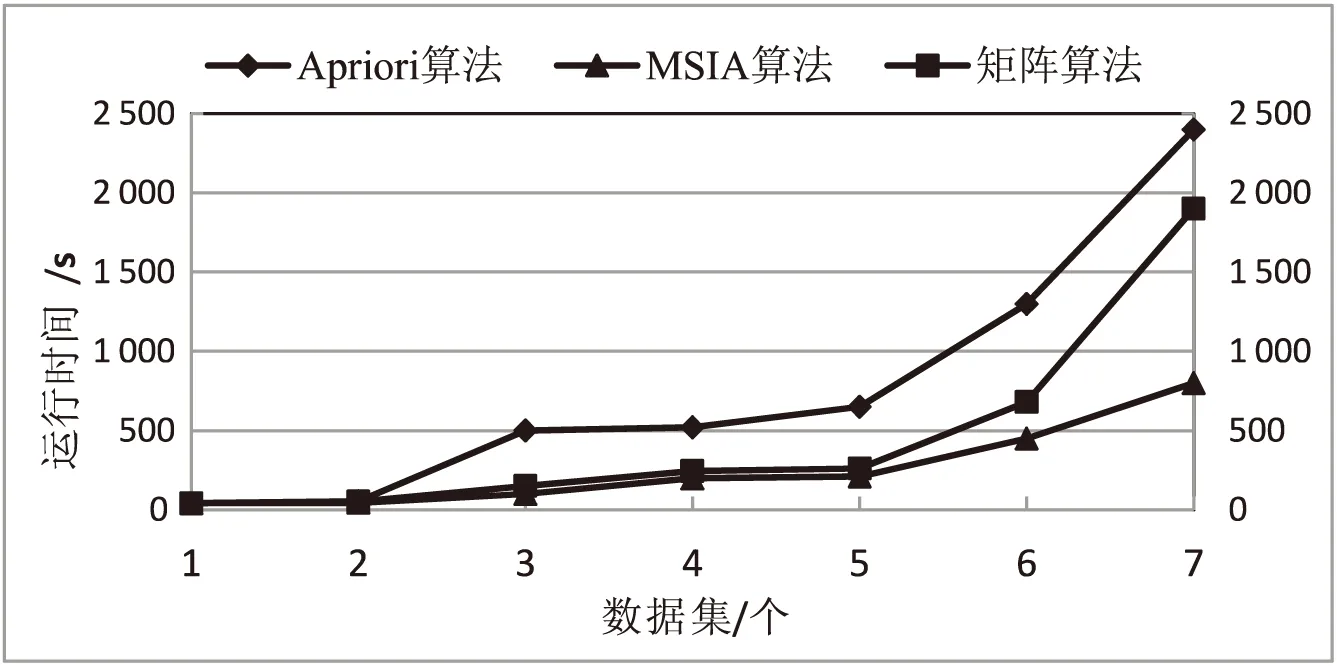
图2 不同数据集下不同算法的运行时间比较
考虑到算法成本,提出的IMSIA算法只扫描数据库一次,并将索引和排序放入缓存中,降低了I/O操作的成本。在相同数据集(|T|=1 000,|I|=30)的情况下设置min_sup=28,通过对比表4中的内存使用数据,发现Apriori算法内存使用量占15.38%;矩阵算法的内存使用量占12.56%;改进的IMSIA算法内存使用量占8.31%。通过对比矩阵关联规则算法与Apriori算法的使用率,前者低于后者2.82%,三种算法中内存使用率最低的为IMSIA算法,通过对比内存使用率提高了7.05%,进一步验证了该算法效率高,内存使用率低,I/O成本低。
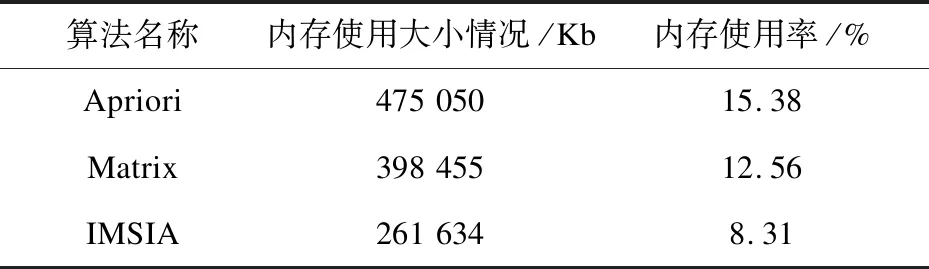
表4 不同算法的内存使用情况比较
3 结束语
提出了一种IMSIA关联规则数据挖掘算法,该算法首先通过扫描数据库建立事务标记序列和事务矩阵,而后对矩阵中的无用事务集进行删除操作,并对标记序列进行从新标记,最后将删除的矩阵与其转置矩阵相乘,得到频繁2-项集,再结合排序索引,得出其余的频繁k-项集。该算法在运行过程中只对数据库进行了一次扫描,且不生成候选项集,从而大大减少了内存的使用率并降低了I/O成本,而且还支持数据挖掘的实时更新,提高了数据挖掘效率。
猜你喜欢
作文大王·低年级(2022年12期)2022-12-23 02:16:15
中国交通信息化(2022年10期)2022-11-17 08:19:42
中学生数理化·七年级数学人教版(2022年11期)2022-02-14 07:14:12
河南水利年鉴(2020年0期)2020-06-09 05:43:44
科普童话·学霸日记(2020年1期)2020-05-08 16:45:11
小天使·一年级语数英综合(2019年2期)2019-01-10 11:57:30
儿童绘本(2018年5期)2018-04-12 16:45:32
卷宗(2014年5期)2014-07-15 07:47:08
计算机工程(2014年6期)2014-02-28 01:26:12
长春大学学报(2013年8期)2013-06-21 09:04:04
