
食品科学大数据与人工智能技术
2021-03-06 07:35崔晓晖顾诚淳
中国食品学报 2021年2期
崔晓晖,李 伟,顾诚淳
(1 武汉大学国家网络安全学院 武汉430072 2 江南大学人工智能与计算机学院 江苏省媒体设计与软件技术重点实验室 未来食品科学中心 江苏无锡214122)
1 人工智能与大数据简介
1.1 人工智能
自1956年达特茅斯会议,以麦卡赛、明斯基、罗切斯特和申农等为首的一批有远见卓识的年轻科学家在一起聚会,首次提出“人工智能”(AI)这一术语,它标志着“人工智能”这门新兴学科的正式诞生。进入20世纪70年代,许多国家都开展了人工智能的研究,涌现了大量的研究成果。然而,和其它新兴学科的发展一样,人工智能的发展道路也不是平坦的。1973年,美国和英国都停止了对没有明确目标的人工智能研究项目的投资,尽管后来美国又在AI 行业投资了数十亿研究经费,这些投资者还是在上世纪80年代末撤回了投资。在研究领域,如神经网络、机器学习等方面,也都遇到困难,使人工智能的研究一时陷入困境。AI领域研究的高潮和低潮不断交替出现,如今依然有人对AI 的前景保持相当乐观的态度[1]。2006年,深度学习的出现,计算机计算能力的增强与数据采集能力的增强突破了人工智能的瓶颈[2],使得人工智能这门学科能够处理困难且更切合实际的应用问题。
早在2001年,就有学者提倡将人工智能运用于食品领域[3]。目前人工智能的技术越来越成熟,将这技术运用在食品领域,突破了一个又一个难题,打破了一个又一个局限。
1.2 大数据
大数据(Big data)是一个抽象的概念,是对当前,无论是企业还是政府、高校等单位面临的数据无法存储、无法计算的状态的形容词,单从字面上看,大数据这一概念很难和之前“海量数据”(Massive data)的概念有所区别[4]。针对这个概念,目前有很多理解和定义。
Kusnetzky[5]和Vance[6]认为的大数据,又称巨量数据,是指传统数据处理应用软件不足以处理的大或复杂的数据集的术语。麦肯锡在其报告《大数据:创新,竞争和生产力的下一个前沿》中给出大数据的定义[7]:大数据是大小超出常规的数据库工具获取、存储、管理和分析能力的数据集。其同时强调,并不是说一定要超过特定TB 值的数据集才能算是大数据。
根据美国国家标准与技术研究院(National Institute of Standards and Technology,NIST)发布的研究中的定义,大数据是用来描述在数字网络世界中数据泛滥现象的常用词语。大量数据资源为解决以前不可能解决的问题带来了可能性。
Mayer-Schönberger 等[8]在他的著作《大数据时代》中提出大数据的4V 特性:规模性(Volume)、高速性(Velocity)、多样性(Variety)、价值性(Value)。规模性是大数据中的数据量爆炸性地增长。高速性是大数据相对传统数据挖掘,对于处理数据的响应速度有更严格的要求。多样性是数据来源、数据类型的多样。价值型是大数据背后隐藏着巨大的潜在价值。
大数据的核心作用是数据价值化,简单地说,大数据让数据产生各种“价值”,这个数据价值化的过程就是大数据要做的主要事情。大数据做的是:记录一切、描述一切、预测一切。
由于近期技术的进步,发布新数据的便捷性和全球大多数政府对数据高透明性的要求,海量数据分析在现代研究中越来越突出[9]。大数据主要应用在给人类提供辅助服务,以及为智能体提供决策服务。通俗地说“大数据就像互联网+,可以应用在各行各业”,如在食品行业中,利用大数据技术帮助地方餐厅作出调整决策,发现食品中隐藏的规律等等案例已十分多见。
1.3 人工智能与大数据的关系
随着时代更迭和计算机科学的进步,数据的采集变得前所未有的便利,由此推动了人工智能技术和大数据技术的进步。这些新兴的智能技术影响着现实生活中的各个方面,人们可以深刻感受到人工智能、大数据带来的便利,尤其是在食品行业,人工智能与大数据技术在食品安全、食品口味、食品搭配等方面的效果卓有成效。
人工智能是计算机科学的一个分支,它是研究、开发用于模拟、延伸和扩展人的智能的方法、技术和手段。人工智能技术企图了解智能的实质,并产生一种新的能以人类智能相似方式作出反应的机器,其研究领域包括机器人、语言识别、图像识别、专家系统等。
大数据是人工智能的基础,大数据本身的概念不仅指海量的数据和资料,也包括数据里蕴含的价值。人们使用大数据技术获得和存储大规模、多样性的数据,并对获取的数据进行分析,发现数据中规律,然后作出科学的决策。
大数据和人工智能关注点不同,然而二者关系密切,相辅相成、互助发展。大数据是人工发展的基石、动力。只有通过海量的多样性好、价值高的数据(包括文本、视频、图片等),人工智能才能学习到更多的信息,从而更好地模拟人的思维,扩展人的智能。换句话说,人工智能是大数据应用的体现,是大数据的应用场景[10]。
2 人工智能与大数据在食品领域上的应用
随着时代的进步和经济的发展,我国对于食物的要求已经从“吃饱”转型成“吃得好和吃得健康”。现今人们更加关注食品风味和食品营养,传统的食品科学技术逐渐不能满足这些需求。而新兴的人工智能与大数据分析技术给食品领域带来了全新的科学分析方式。例如,Kazama 等[11]利用大数据来构成一个能转换国家、地区风味的神经网络,让人们更方便地品尝到异域风味的料理;为了让大家更关注自己餐盘里食物的营养,Kalra 等[12]构建了一个基于大数据的营养评估系统,通过食谱分析,计算食物的营养。
食品安全是人对食物的基本要求,是人们正常生活的基本保证。食品安全追溯系统是确保食品安全,为食品供应链组件创造收益的关键,传统的追溯系统通过射频识别(RFID)技术追溯货物的来源,该方法高昂的成本一直制约着RFID 的的普及和应用[13]。目前出现了功能更强大的新型智能追溯系统[14],通过利用先进的互联网和大数据技术,以二维码为载体,作为每件货物的“身份证”,实现了一物一码,并在北京、天津、河北等地区进行了检测试验。除此之外,Whitehouse 等[15]使用人工智能技术(监控摄像头)对厨房操作进行监控,提高了食品的安全性,让坐在餐桌上的客人更加安心。
不仅从食物的角度,人工智能和大数据技术也能建议食客选择优质餐厅和帮助餐馆的管理者作出最优秀、最合理的决策。Zuheros 等[16]提出一种基于人工智能情感分析的决策模型,对Tripadvisor 中的餐馆点评进行分析和评估,从而给用户推荐餐厅。Delanoy 等[17]认为通过大数据分析可以帮助管理者作出合理的业务决策,运用在饮食行业中,利用庞大的数据集和精湛的分析技术,分析用户的需求变化,从而作出最合理的决策。
综上所述,这些技术不仅能提升食品的安全性,提供多样的口味,给出更营养的食物搭配,还能帮助管理者决策,使得食品科学更好地为人类服务。
2.1 大数据在食品风味上的应用
2.1.1 基于大数据驱动的风味网络构建 过去十几年中,已有一些厨师和食品科学家注意到一个规律:相比不含共享风味化合物的食物搭配,共享风味化合物的搭配更受人们的欢迎。例如,外国流行把蓝纹奶酪和巧克力搭配起来,这两种食材共享风味化合物高达73 种。为了证实以上的规律,Ahn 等[18-19]对此进行了相关研究,构建了包含381种食材和1 021 种风味化合物的风味网络。网络中每个节点代表一种食材,节点与节点之间的连线粗细代表这两个节点所代表的食材之间共享风味化合物的数量大小。
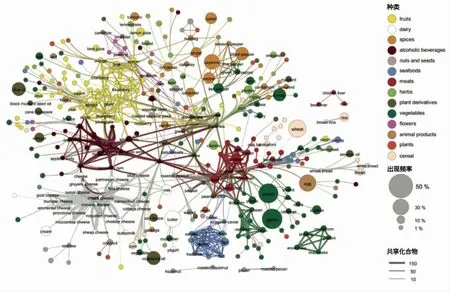
图1 风味网络示意图[18]Fig.1 The backbone of the flavor network[18]
由于Ahn 等[18-19]的风味网络仅用作试验和观察,因此他们的网络仅采用相对少量的数据形成了可视化网络。同时为了避免对世界美食给出西方化的解释,他们的食谱取自北美、西欧、南欧、拉丁美洲和东亚。
网络构成的结果表明:北美食谱配方中,两种食材共有的风味化合物越多,它们一起出现在食谱中的可能性就越大,而与之相反的是在东亚食谱中,两种食材共享化合物越多,一起使用的可能性就越小,这就是 “食物配对”(Food-pairing)原则。尽管不可能用科学的角度来全面解释烹饪艺术,至少还可以了解,对于东亚人来说,更倾向于共享化合物较少的食物搭配,并由此来考虑食材搭配。
风味网络是大数据的产物,通过建立两种材料之间的联系,依据联系的强、弱,可以判断这几种材料是否适合出现在某个地区的菜谱中,为人们选择菜谱搭配提供更加智能和科学的思考方式。
2.1.2 基于风味网络的地区食物搭配模式 风味网络的发现给食品科学家带来了全新的分析方式,他们从这个微观的角度来观察各地区食物之间的联系。
印度学者Jain 等[20]根据风味网络调查了印度的食物配对情况,他们发现印度各地区的美食都遵循负面的食物搭配模式,即在印度美食中遵循风味共享程度越高,在烹饪中它们共同出现的频率就越小。
Ozturk 等[21]为了在马尔马拉地区创造新型菜谱,基于风味化合物网络的分析方法,根据食物材料的常见化合物数量来评估菜谱的成分,结果发现8 种常见的化合物,它们包含了相似的风味和香气,表明风味配对理论可用于该地方的新配方,在他们的设计试验中,20 名成员中的80%表示非常喜欢新的配方。尽管最后的结果是乐观的,然而,Ozturk 等[21]在大米、牛奶、干豆和无花果中发现的8 种常见化合物可能难以具有代表性,应采用更多的统计数据来说明。
2.1.3 大数据驱动的新风味食品开发 自风味网络被提出后,食品科学领域的研究人员开始重视风味化合物的数据,由此诞生了FlavorDB。FlavorDB 是一种资源数据库,广泛覆盖25 595 种风味化合物,在数据库中列出的分子中,这些天然成分被进一步分为34 类,并映射到527 种不同的天然来源。这些风味化合物数据库的建立弥补了之前风味网络数据不完整的缺陷,使得风味网络的数据分析更加科学、精准,避免了一些因数据缺失而导致的不全面的结论,方便了后续数据驱动的新风味食品开发。
2019年,香料公司McCormick 公布,他们将利用IBM 的人工智能技术,结合自身的专业知识来开发全新的调味产品[23]。在风味化学的世界,香料和味道都是一门科学。世界上存在着大量可用的风味组合,而新风味配方的开发需要耗费大量的时间与资金。McCormick 公司大量的风味数据和IBM 的AI 算法结合,只要花费少量的时间就能预测配方的替代品,配料的正确比例,甚至人们会对味道做出哪些反应。
3 人工智能在社会饮食上的应用
3.1 基于语义分析技术的社会饮食分析
随着移动设备的普及,各种各样的社交媒体应声而起,例如Twitter、Facebook、微信朋友圈、微博等。人们分享生活方式和生活细节的方式越来越方便和快捷。更多的人愿意在网上分享美食和心得,成千上万的人都乐此不疲,这些分享在网络上的数据有文字、图片,甚至是视频,有学者收集这些数据并利用人工智能语义分析技术来进行解读。语义分析技术不仅能够分析语言,也包含能够将图片和视频转换成文字描述后解读的技术[24]。有了这些技术,就能够判断用户对特定食物的喜好程度,利用关键字的矢量空间模型方法构建用户饮食偏好模型,在此基础上进行分析,能够得到该用户的口味偏好并能为用户推荐菜品和餐馆信息等[25-26]。
Jalal 等[27]抓取肯尼亚居民在社交媒体Instagram 上发布的图片,通过分类器KenyanFC 区分食物图像和非食物图像,提出一种关键字抓取技术获取图像的类别,接着将这些数据作为模型Kenyan-FTR 的训练集进行深度神经网络的训练。这个模型可以识别13 种肯尼亚的流行食物,在Instagram 图像上的准确率高达81%。后续直接使用Kenyan-FTR 读取Instagram 上的食物图像,统计结果表明,蛋糕和烤肉是2019年3月在肯尼亚最受欢迎的食物。然而,消融研究表明,13 种食物中的3 种仅通过图像进行分类非常困难,例如土豆泥这种不具有固定形状的食物,食物的形状只取决于它的制作者,因此还需通过添加辅助的文字信息进行语义分析,提取关键字,以提升正确率。
通过对这些在社交媒体上实时更新的数据进行分析,能够掌握某个地区的人们在某个时间段的社会饮食习惯和偏好,从而帮助餐厅或企业采取相应的营销策略。
3.2 疫情背景下基于社交网络的社会饮食监测
目前COVID19 病毒,即新型冠状肺炎病毒席卷全球,对人们的生活方式、心理健康和饮食习惯造成重大影响。针对这样的情况,意大利的学者对意大利的患者进行了在线调查[28],数据分析总共包括602 名患者,很大比例的人经历了情绪低落、焦虑感和失眠,而且几乎有一半的受访者因其饮食习惯而感到焦虑,更倾向于增加食物的摄入量和选择令人舒适的食物。由于这项调查的数据来自抽样调查,仅选择602 患者,因此对该较小的群体的分析很难获得具有代表性的结果。截至2021年1月2日,全球确诊患有新型冠状病毒的人数已高达2 300 万人,面对庞大的患病人群,逐个统计分析的成本昂贵且不切实际,且国与国之间的疫情合作难以统一。
鉴于这种情况,通过人工智能技术分析患者社交网络的动态,不仅成本相对较低,而且受众较广,获得的数据还具有一定的实时性。目前Eftimov 等[29]使用AI 技术对隔离后的食物消费模式进行分析,他们收集了最大的美食社交网络——AllRecipes(https://www.allrecipes.com/)上发布的两套食谱:一套是隔离开始之前发布的配方的集合,另一套是隔离之后发布的。这些食谱来自不同地区和饮食习惯。为了分析配方,他们采用一个名为DietHub[30]的方法,通过这个方法,只需将配方制备的文字描述作为输入,就可以输出一系列主要成分的列表,接着,把这些主要成分通过在Hansard 语料库[16]中的分层语义标签自动注释。通过这些方法Eftimov 等[29]观察了COVID-19 对食物消费方式的影响并进行食品语义标签相对频率的统计分析,以此观察人们在疫情隔离期间一餐的健康程度是否存在问题,并打算以此研究结构构建有针对性的通用配方推荐系统。
4 人工智能在未来食品上的应用
4.1 未来食品
回顾之前的食品发展[31],1886年,约翰·彭伯顿医生把碳酸水加苏打水搅在一块,制成一款黑色糖浆,该饮料即可口可乐。1928年之前,没有人尝过泡泡糖是什么滋味。而跳跳糖的诞生让人们知道,糖不仅可以吃,也可以很有趣。1934年Tom Carvel 的冰激凌车爆胎,不得不将融化的冰激凌出售给路人,两天内就出售了所有的冰激凌,这给他带来开发软冰激凌配方的灵感——软而非硬的冰冻甜点。1990年,红牛公司展示的一种口味独特的药用风味,自此成为能量饮料的代言词。
可口可乐、泡泡糖、跳跳糖等食品对于各自年代的人来说就是未来食品,具有不同于当时的口味和人们从未见过的新奇。冰激凌满足了人们对于新口感冰冻甜点的需求,红牛则满足了人们对于好喝的保健饮料的需求。
人们很难给出未来食品的精确定义,不过可以确定的是人们吃的食物一直在发展,新的口味一直在创造,崭新的未来食品一直在遵循以人为本的原则发展着,满足着人们日益发展的需求。
4.2 基于个人遗传因子的未来饮食推荐系统
2015年,来自以色列的Zeevi 等[32]在几天内追踪了800 人的血液中的血糖水平,令人惊讶的是,人们对于相同食物的生物化学反应差异大不相同。有些人吃了含糖冰激凌后血糖升高,而另一些人仅随着淀粉的摄入而升高,这一观点和传统观念不符。人体对于养分的特殊处理似乎取决于基因,目前已有科学家做了针对个人DNA 提供饮食建议的研究[33],这项研究已投入实际生活中,如一些公司提供所谓的“营养遗传服务”,通过测试用户的遗传信息提供适合用户的饮食建议。
因为个体的差异性,所以生产个性化的饮食可能是未来食品发展的趋势。正如Zeevi 等[32]所提到的,基于基因的饮食推荐因可能涉及个人隐私以及耗费大量的资源而在现阶段难以普及化,展望未来进一步发展的技术,有望能够解决这一系列难题。
5 人工智能和大数据的局限性
使用人工智能和大数据技术可以帮助人们解决很多食品领域的实际问题,然而,这些方技术目前处在不断上升的阶段,还存在局限性,比如人工智能在深度学习方面尽管证明很有效,但是尚无完整的理论体系能够解析其原理。目前人工智能的等级仅在较弱的水平上,不能真正学会推理和解决问题。
为了拟合个人的需求,不得不获取一些个人的信息。以上述按照个人的DNA 来推荐饮食建议的方法,这个想法着实新颖且可行,然而,遗传信息是每个人不分国界的身份证,包含大量的信息,如果这些信息泄露则可能导致一系列不必要的伦理问题发生。
再说起大数据的发展前提是要有大量的数据源头,即使对于IT 行业而言数据化程度较高,仍然缺少资源共享和信息交换机制,且网络上某些公开的数据缺乏真实性和完整性。难以辨识真假的数据使得研究结果可能产生偏差,特别是与人类健康和正常生活息息相关的食物方面的研究更不能出现问题。
区块链技术是解决大数据带来的挑战的可行方案[34],它被认为是一种革命性的解决方案,可以解决诸如身份、数据所有权等现代技术问题。通俗地讲,区块链就像是一个公共账本,一种集体来维护更新的网上数据库。“区块链+大数据”是未来解决数据拥有者间数据共享的问题的可行方案,是促进食品行业人工智能化的强大推力。目前区块链技术处于新兴阶段,仍有待技术的进一步成熟。
6 总结与展望
随着社会的快速发展,食品行业累积了大量来源广泛,增长速度快,价值密度低而应用价值高的数据。如何使用大数据与人工智能技术挖掘食品数据更多潜在的应用价值,从而促进食品行业的可持续发展,成为食品领域重点研究的问题。本文主要介绍了食品领域大数据与人工智能技术在不同国家、地区的发展现状、技术优、缺点,阐述不同食品子领域如何利用大数据与人工智能技术的优势而创新发展。例如:食品感官是食品领域的关注点之一。如何使创新的食材,如人造肉、人造蛋以及个性化食品等更加符合人们的口感并愉悦身心,物联网、区块链、大数据以及人工智能是解决这个问题的重要途径。可通过生物穿戴传感器的方法实时采集个体数据,并上传到云链上。通过大数据技术将收集到的数据进行融合,统一格式。利用人工智能自然语言处理技术、图片处理技术等分析处理后的数据,使得训练的模型能够感知人们利用自然语言描述的“美味”,或者看到图片而联想到的“美味”。最后,利用人工智能的推荐技术为个人定制独特口味,使得推荐的食物最拟合当前用户身体的需求。
又如:食药同源也是当下关注的焦点。其原因:一是我国人民的需求已从“吃的好”逐渐转向于“吃的健康”;二是我国人民需要自己的膳食结构,而非西方生搬硬套的膳食结构。基于我国传统饮食文化的食药同源理论,不少植物既是食材又是药材。利用大数据与人工智能技术创新食药同源网络,开发新的满足不同人群口味的药膳谱,是未来食品科学发展的一个重要方向。通过大数据技术分析不同食材的各种化学成分,依据这些成分组建食药同源网络。利用人工智能的个性化推荐技术,生成深度网络模型等,不断创新药膳谱,使其不仅能够满足人的营养需求之欲,也能预防并干预一些慢性疾病。
猜你喜欢
新世纪智能(高一语文)(2020年10期)2021-01-04
新世纪智能(高一语文)(2020年10期)2020-12-31
少儿美术(快乐历史地理)(2020年7期)2020-11-26
家庭影院技术(2019年1期)2019-01-21
商界(2019年12期)2019-01-03
IT经理世界(2018年20期)2018-10-24
小康(2017年16期)2017-06-07
南风窗(2016年19期)2016-09-21
爆笑show(2016年2期)2016-04-11
少儿科学周刊·儿童版(2015年6期)2015-11-24
