
恐龙相关数据库的发展现状与数据驱动下的研究实例剖析
2021-03-05 06:07梁晴晴邢立达
高校地质学报 2021年1期
梁晴晴,邢立达
中国地质大学(北京)地球科学与资源学院,北京 100083
1 引言
随着科技的发展与进步,地球科学与大数据、大平台的关系越来越密切,这不仅涉及科学研究范式变革,更对全球相关的经济与产业变革产生了深远影响,“深时数字地球”(Deep-time Digital Earth,DDE)大科学计划应运而生(Jackson,2008;孙枢和王成善,2009;Gantz and Reinsel,2012)。DDE是国际地质科学联合会(IUGS)批准的第一个国际大科学计划,由中国科学家发起并主导,旨在建立地球大数据关联集点,促进全球地学知识共享,打造出一个专业服务于地球科学的“地学谷歌”(Normile,2019),构建全球最大的地学基础数据库群。恐龙作为中生代占主导地位的陆生脊椎动物,是深时地球生命演化史的重要组成部分(Currie and Kevin,1997;Fisher et al.,2000;Benton,2004)。在恐龙形态特征、生活习性以及生态环境,特别是其长达1.6亿年的生命历史、地理演化规律等方面,前人已经积累了海量的历史数据(Butler and Barrett,2008;Csiki et al.,2010;Langer et al.,2010;Xu et al.,2014)。如何更好地挖掘、分类、储存和使用上述的恐龙学数据,恢复恐龙生命演化进程,细化中生代1.6亿年的陆地生命系统发育树(Ezcurra,2010;Nesbitt et al.,2010),已经成为恐龙学当今的研究热点。
恐龙学研究始于19世纪40年代的英国(Owen,1842),之后的百余年里,其研究的重点主要为新标本的报道(Holmes,1996),以及恐龙的科学分类系统与分类标准的建立(Seeley,1887;Russell,1995;Benton,2004)。其 中,在20世纪晚期,恐龙学开始迈入一个新的阶段,各国学者开始尝试解决关于恐龙起源、演化与古地理分布等方面的问题(如Bakker,1972;Russell,1993)。进入21世纪后,古生物学家们开始尝试使用计算机批量处理恐龙学数据(如Fisher et al.,2000),借助高分辨率CT扫描仪对化石进行无损扫描,从而获得其内部结构与海量化石CT数据(如Rayfield et al.,2001)。近二十年,恐龙学的数据量出现了爆发式的增长,且数据类型也不断多样化。为了更好地使用这些数据,全球陆续出现了一些恐龙学、古生物学及相关数据库。这些数据库的涵盖面、分析手段及特征各有千秋,然而从系统恐龙学角度来看,它们都不能被称为“恐龙数据库”。但不论是从科普性还是科学性的角度来看,恐龙都是地球深时生命演化的重要组成部分,对于即将建设的DDE地学基础数据库有着重要的作用。因此,围绕DDE大科学计划的需求和总体设计,进行学科知识的全面梳理和数据化,建立专属于恐龙学的集数据抓取、标准化、共享和分析计算为一体的大数据平台显得极为重要(Sereno et al.,2005)。将恐龙学科与大数据相结合,开展数据驱动下的科研创新,不仅会极大的拓展恐龙学认知空间,提升获取恐龙学新知识的能力,同时可为恐龙学支撑的古生物学、地层学以及地质年代学等研究提供创新活力(Holtz et al.,2004;Raskin and Pan,2005)。
2 全球恐龙学及相关数据库建设情况概述
目前,全球已经出现了一些涉及恐龙分类学、形态学、埋藏学与古地理学等方面的数据库,搭载有数据抓取、分析和计算等技术,也在尝试使用数据库思维解决恐龙的深时演化问题。因此,总结概况全球已有的恐龙学相关数据库(表1),了解其架构与优缺点,对于在DDE大科学计划下建设系统全面的恐龙数据库有非常重要的参考作用。经过深入调研,按照数据库的数据类型、数据结构、实际应用、优缺点以及未来发展等,将现有的恐龙学相关数据库总结为以下三大类型。
(1)纯科普型:主要包含化石图片以及恐龙行为学和生态学等基础文本数据,以门户网站的形式呈现,用于满足用户的科学探索与互动需求,但这些网站通常也存在科学性差、数据规模小以及用户专业背景较弱等特点。这些数据库在恐龙的大众科普方面有很大的应用价值和发展空间。
(2)特定目标型:主要包含恐龙3D数据、照片、附表、馆藏信息文本等,以结合了如MySQL Access等数据库管理系统与GIS功能的独立系统或网页的形式呈现,其建设目的通常是为了解决建设者或团队特定的研究目的,因此在数据采集上也是有针对性地筛选数据。这类数据库具有建设目的单一、数据规模较小、用户群少、生命周期短等小规模数据库的普遍缺点,但在专业性及科学性方面较纯科普型数据库有显著提升,更有部分数据库实质上就是一个地区古生物化石标本的“百科全书”。
(3)全面型:这个类型的数据库最大也最复杂,全面汇集所有地质时代的古生物学数据,因此其中也包含了恐龙相关的各类型数据。其数据类型非常多样,并集成了比较强大的数字化、可视化和分析功能,因此可以方便用户查询、获取、共享和分析数据。这类数据库鼓励古生物学与信息科学、数据科学的交叉,通过数据驱动加深合作,以解决一些大规模的或全球尺度的古生物学甚至相关学科的科学问题。具体信息可以参见下文中的表1及后文的剖析。

表1 全球包含恐龙学或与之相关的数据库(项目)信息表Table 1 Table of databases containing or related to dinosaurs worldwide
3 纯科普型数据库
这类数据库以Kinetosaurs数据库为典型代表。该数据库由印第安纳波利斯儿童博物馆 创 始 于1999年(The Children’s Museum of Indianapolis, 2020-10)。数据内容上包含了异特龙属、甲龙属、迷惑龙属和圆顶龙属等近30个类群的恐龙图片、食性、行为学和生态学等字段不多的数据,支持访问者下载未上色的恐龙图片,亲手上色,因此具有较好的互动性。此外,该数据库还包含了艺术家利用各种科学和艺术的方式创作的可移动恐龙雕塑,因此科普效应以及大众反响都比较好。然而,该类型数据库通常科学性不强,缺少足够的科学内涵以及相应的数据分析功能,从学术角度来说参考意义不大。
4 特定目标型数据库
为了降低标本磨损、丢失造成的影响,英国建立了模式标本在线化数据库——GB3D Type Fossils(British Geological Survey, 2020-10),收录了英国化石标本的3D数字模型、高分辨率照片和化石记录信息等数据,数据主要来源于英国地调局及其合作伙伴,其中的3D模型也可以在线进行浏览。值得一提的是,2010年前后,为了便于摸清分布在全国各地的古生物化石标本,给与其更好地保护和研究,同时提供给大众便捷的在线科普体验,在中国国家古生物化石专家委员会开展的《全国重要古生物化石典型标本调查与数据库建设》项目支持下,我国部分地区的地质博物馆以馆藏化石标本为试点,建立起了地区典型标本数据库。这些数据库在建设手段上存在差异,比如各自采用了SQL关系型数据库、Access关系型数据库或ArcGIS、MapGIS等空间数据库进行建设,但在内容上包含了标本图像、表格、文本等多种数据,初步实现了古生物数据的一体化储存、管理、展示和应用。在上述地区数据库的基础上,最终建立起全国古生物化石标本数据库(http://192.168.6.45/sdc/gsw/dashboard/index.jsp),该数据库更像一个统一框架下建设的多个地方性数据库的集成。
ODP项目(Farke, 2020-10)是特定目标型数据库的一个典型案例。该数据库由Farke等人于2009年创建,聚焦鸟臀目演化(Farke et al.,2009),目前正逐渐发展为一个系统的恐龙附肢骨骼数据库。ODP项目的科学研究价值最高,与恐龙学的关联也最紧密。ODP的参与者不一定都是科研人员,任何人,包括一些化石爱好者都可上传数据。因此,ODP最具特色的一点是鼓励大众去发掘和产生数据,亲身参与研究,最终使科学家和普通人能以不同的方式参与、合作并解决特定科学问题。相较于其他恐龙数据库,ODP项目在科普与教育方面表现出截然不同的潜力(Dawson,2012a)。
ODP项目较少关注鸟臀目恐龙的多样性信息,如其产地、层位等,而是更注重收集恐龙骨骼长度、异速生长等形态测量数据。最初目标是收集恐龙附肢所有骨骼的长、宽等尺寸数据,后根据项目需要调整为仅需肱骨、股骨及前后爪的测量数据。其数据来源于美国自然历史博物馆等在线文献或公开展示的鸟臀目恐龙标本,以及志愿者提供的自有数据,如来自史密斯学会的Matt Carrano贡献了600多个标本的测量数据信息,包括未发表的数据。
在数据采集方面,ODP项目由志愿者或科研人员从上述数据来源人工读取原始测量值,利用Google电子表格进行数据汇总。数据采集的基本原则是:遴选某一恐龙类群中体型最大、化石保存最完整的标本,作为数据采集的目标,获得各种必需的原始测量值,并纳入数据表;通过传统的线性回归、几何形态测量学等方法进行计算,量化鸟臀目恐龙附肢骨骼异速生长模式,并借助于Mesquite系统进行系统发育分析。该过程中的一个难点是,系统发育分析的结果通常会随着数据集更新而发生改变。ODP项目通过Mesquite将系统发育与最新文献进行动态关联,形成了一个可联动的系统演化树,有效地解决了这一问题(Farke et al.,2009)。但2013年之后,网站上再无进展更新。
5 全面型数据库及举例剖析
不同于前两类数据库,全面型数据库以汇聚地史时期完整的古生物学信息为目标。这类数据库涵盖的地质历史长、门类齐全,其中不仅包含了化石生物学数据,通常还收录了较为丰富的古生态、古地理和地层学相关信息。由于有着强大的团队支撑和专业的运维队伍,因此这类数据库通常也会定制开发一些专业的数据挖掘、可视化和分析软件和工具,在学界的影响也很大。其中, Paleobiology Database古生物学数据库(简称PBDB,University of Wisconsin-Madison, 2020-10)最具代表性。PBDB的参与者包括全球各个相关大学、博物馆、研究机构的古生物研究人员和学生;在数据内容方面涵盖了整个地质历史的所有化石类群,重点聚焦化石记录和分类数据等,并包括了古生态、古地理等相关数据内容;除了常用的文本检索功能,PBDB平台中还集成了图形化检索功能、多种多样性统计分析功能,并开放了API接口供用户直接写代码进行数据实时挖掘和分析。PBDB团队有着长期的、较为稳定的经费来源,经过二十年的发展,已经成为全球规模最大、发展最好、涉及面最广且科研产出最多的古生物学数据库。
PBDB是目前包含恐龙数据最多的数据库。对比于前两类数据库中科学性相对较高的ODP,PBDB具备多个方面的明显优势:(1)数据条目更丰富:PBDB发展历史久,仅恐龙方面已收录8720个化石采集层中17126个恐龙化石产出记录,远多于ODP的161项恐龙肢骨数据条目(数据条目为一项数据内容集合,可能包含多个同类型信息);(2)学术影响更大:利用谷歌学术分别对Open Dinosaur project和The Paleobiology Database dinosaur进行简单搜索,前者有684条搜索结果,其中首页有4篇学术论文检索结果,但均是关于开放性科学、互联网科技的讨论,其中ODP项目主要是作为一个研究实例被引用,未真正涉及恐龙学研究(Soares et al.,2010a,2010b;Dawson,2012a,2012b)。后者的检索结果有3660条,其中首页有7篇相关文献,小到各时期恐龙食性、体型分布演化,大到中生代恐龙形态多样性、古生态模式及地理分区,以及不同时间尺度的生物多样性及演化,甚至包括恐龙博物馆展品指导 等(Butler et al.,2009a;Butler et al.,2011;Noto and Grossman,2010;Brusatte et al.,2012;Benson and Mannion,2012;Carpenter,2012;O’Gorman and Hone,2012);(3)内容更丰富:PBDB提供了一个在线资料库,其中《非鸟恐龙的分类学与分类》提供了恐龙演化和化石记录研究方面的理论框架(Carrano and Sampson,2004;Carrano,2005);(4)应用领域更广:除了科研,PBDB还被广泛应用于一些高校的古生物学、地层学和古地理学等方面的课堂教学中,具有更多的科普、教学方面的价值。
综上所述,笔者认为PBDB对创建DDE恐龙数据库的参考意义更大,以下是对该数据库结构、模型以及相关研究实例的详细介绍。
5.1 PBDB数据库结构
PBDB(https://paleobiodb.org/#/)是基于Perl开发的MySQL关系型数据库,所有Perl代码可在GitHub(https://github.com/paleobiodb/pbdb - new)上查看,并且还为用户提供了原始数据接口,便于用户开发专门的数据分析工具(Peters and McClennen,2015)。PBDB有六个主要的数据表,分别是参考文献(published references)、分类单元名称(taxonomic names)、分类单元同异名及分类(taxonomic synonymies and classifications)、化石产出记录的重新鉴定(reidentifications of occurrences)、分类单元的化石产出记录(taxonomic occurrences)和主要采集数据(primary collection data)。此外还有用以记录生态学与埋藏学信息(ecological and taphonomic attributes of higher taxa and species)、标本尺寸(measurements of specimens)以及数字化石图像(data about the digital fossil images on the site)的数据表。上述数据表表现为一组关系表,每个化石产出记录、尺寸数据和分类鉴定都与该关系表关联,因此用户可以通过检索功能快速获得相关信息(详见邓怡颖等,2020)。
5.2 古地理与时间信息
PBDB数据库建立之初,在古地理重建方面使用的是Chris Scotese的古地理重建模型,2014年后引入了新一代的GPlates模型(http://www.GPlates.org),将之作为默认的重建模型。PBDB中收录的化石记录均包含了当今地理坐标和对应的地质年代信息,将这两类信息与GPlates模型结合,就可以为化石记录分配相应的古地理坐标,实现古地理位置的恢复(Wright et al.,2013)。
5.3 PBDB数据模型
PBDB的数据主要分为两种类型:一是化石产出记录(occurrences),指在具体地理位置(如剖面或露头等)产出,可被分类学鉴定并被PBDB收录的化石材料;二是分类学信息(taxonomy),指使用PBDB中的生物分类法进行划分,得到的具有若干共同特征,但等级不同的分类群体(Peters and McClennen,2015)。
5.3.1 化石产出记录
化石产出记录指经过了分类学鉴定的化石,化石产出记录来自具体的地理位置(即产地),因此通常具有详细的地理信息。来自同一地点、同一层位的化石产出记录,通常会以化石采集层(collection)为单位进行收录。PBDB里的化石采集层通常标注了所属的地层单位名称,并且多数具有详细的地理位置信息,此外有部分采集层为博物馆藏,因此还具有藏品信息或者样品号等(Peters and McClennen,2015)。PBDB中的化石记录多数具有明确的分类名称,但也有部分使用了开放命名,如亲近种、相似种、类群种、存疑种等等,在使用时需要注意区分。此外,化石产出记录中仅保存了分类单元名称,未包含任何分类系统信息,后者是由另外一类数据定义的,即分类学信息数据。
5.3.2 分类学信息
这一数据是PBDB中分类系统信息的基础。在古生物学文献中经常存在不同观点或命名冲突的问题,比如同一标本被不同专家命名为不同的分类单元,或者同一分类单元名称被用于不属于一类的标本上,因此在一个成熟的古生物学数据库中,应当将分类学信息作为一种相对独立的子系统进行建设和维护。在PBDB中,分类学信息包括两部分内容(Peters and McClennen,2015):(1)分类单元名称,由权威参考文献定义的某个分类单元的名字;(2)观点,用于确定分类单元名称状态或彼此间关系。在PBDB中,将参考文献中提炼出来的观点分为四类,分别是“有证据观点”、“无证据观点”、“暗示观点”和“二手观点”。通过将分类单元名称与观点相结合,就可以生成一个代表了最新分类观点的分类系统。这一分类系统是一个不断动态更新的系统,随着包含观点的新的文献的不断加入,这一分类系统也会不断更新。经过长期积累,PBDB已经建立起一个包含了20个大型数据集的在线系统分类学档案,并附有分类单元名称和观点的下载链接。其中包括了《化石海洋动物科属纲要》、《四足动物分类》、《北美化石哺乳动物系统分类学数据库》以及《非鸟恐龙的分类单元及定义》等(Carroll,1988;Sepkoski,2002;Alroy,2003a;Carrano,2005)。
5.4 应用程序接口(API)
经过二十年的发展,PBDB已经成为了一个体系成熟、数据高度开放共享的数据库系统。为了使数据库中的数据利用率最大化,PBDB向访问者开放所有公共数据,鼓励访问者利用这些公共数据开发web、移动和桌面端的软件。在数据使用方面,除了常规的在线文本检索和图形化检索之外,PBDB还开放了应用程序接口(Application Programming Interface,简称API),供有编程能力的用户编写网络应用程序,实时对PBDB中的数据进行检索和分析。例如,Varela等(2015)基于PBDB API开发了一个名为paleobioDB的R语言包,用于对PBDB中的数据进行灵活的查询,包括对选定数据的可视化、下载和处理。通过这一R语言包,用户可以快捷地获得化石产出记录、分类学信息、物种丰富度以及其他有关信息,并且这些信息会以简洁、美观的图表形式呈现。此外,开放API的另一个重要意义在于,它提供了跨平台整合多源数据库的数据的可能,比如,将古生物学数据库和现代生物学数据库里的数据进行整合检索,从而可以用古生物的数据帮助我们理解现存生物的历史演化过程,反之亦然(Varela et al.,2015)。
5.5 PBDB的文本挖掘系统——PaleoDeepDive(PDD)
现有的古生物数据库,均由人工方式进行数据采集,因此无法保证数据的完备性,也无法避免数据采集过程中产生的人为偏差。为了解决这一问题,PBDB团队尝试开发了一个古生物信息的机器自动阅读系统——PaleoDeepDive(简称PDD;Peters et al.,2014)。PDD可以从文献的文本、表格和图表中自动提取数据,建立数据间的关联,并最终实现统计推理与学习(图1)。PDD目前支持多语言文献的阅读,包括英文、德文和中文等。实验表明,相较于人工数据采集方式,PDD可以从文献中提取更加丰富、完整的数据。比如,分类单元名称方面,PBDB通过人工方式供提取了79913个分类单元名称和观点,PDD则可以自动提取出192365个,其数量远多于人工提取的方式(Peters et al.,2014)。
6 数据驱动下的恐龙学研究实例
在过去20多年里,尤其是随着PBDB逐渐发展成型,与恐龙学相关的数据驱动下的古生物研究实例不断涌现。此处仅选取其中具代表性的案例简述如下,以期为DDE开展大数据驱动下的生命演化研究提供借鉴。
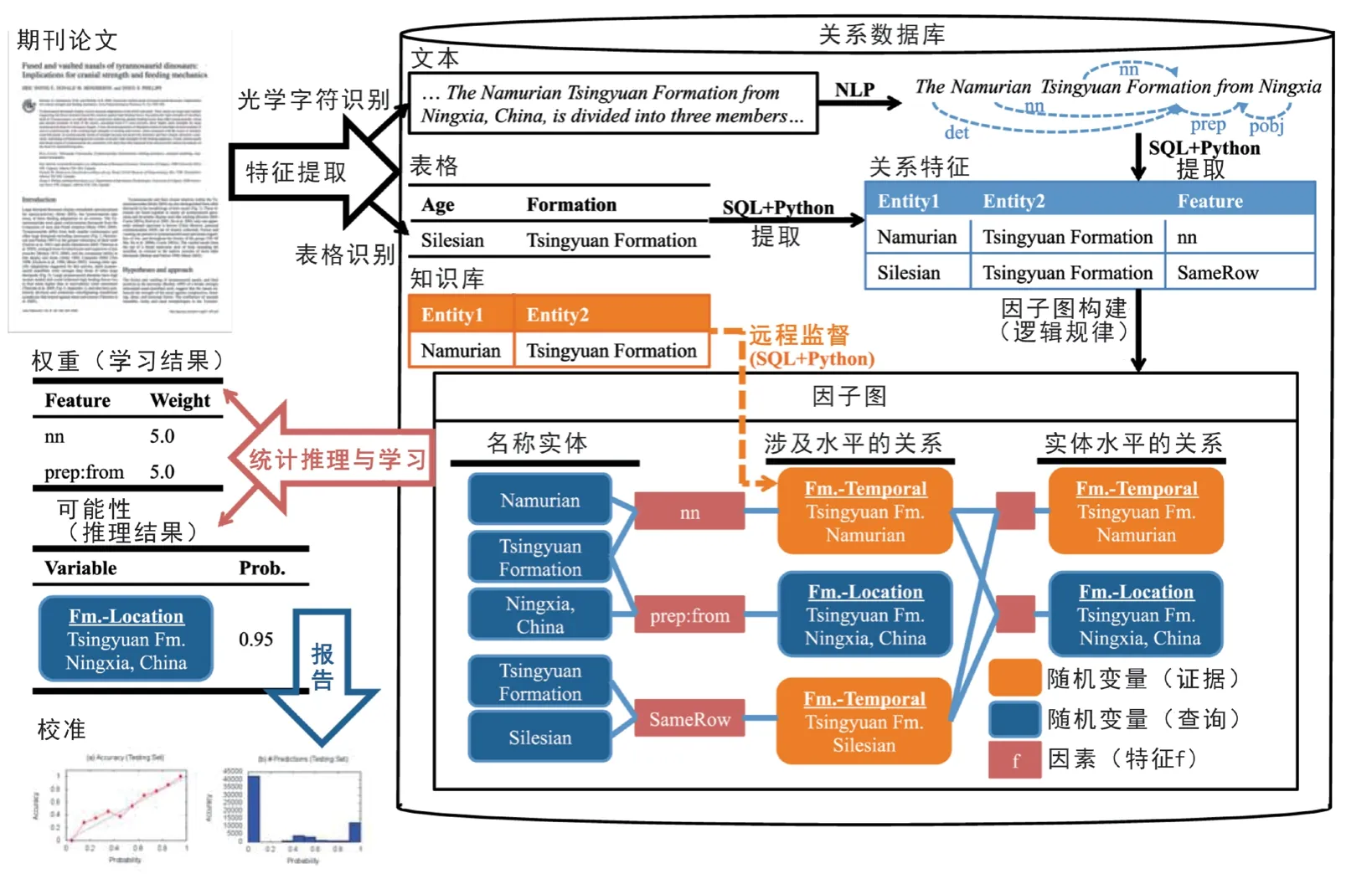
图1 PDD工作流程示意图(据Peters et al.,2014)Fig. 1 Schematic representation of the PaleoDeepDive workflow
6.1 白垩纪恐龙与植物协同演化
生命演化会受到一些非生物因子的影响,从而在生物类群之间产生协同演化,即两个生物类群相互作用发生共同演化的现象,如捕食与被捕食、共生与寄生等。协同演化在现代生态系统中普遍存在,并被认为是群落形成的重要过程(Janzen,1980),对理解新型演化的起源、激励机制以及生物辐射现象至关重要。受到这种观念的影响,古生物学家也开始在地质时间尺度上讨论古生物类群的协同演化现象(如Macfadden,2000;Beerling and Osborne,2006;Friis et al.,2006)。在根据化石记录证据提出的众多协同演化假说中,关于白垩纪植食性恐龙与被子植物的协同演化假说(如Tiffney,2004;Coria and Salgado,2005),一直是古生物演化的研究热点之一。然而化石记录能储存的有效信息毕竟有限,这就使得验证古生物学的协同演化假说比较困难。通常来说,发生协同演化的多个生物类群,它们的多样性在时间上具有明显的一致性,即多样性一致是证明协同演化假说成立的必要条件,但不足以证实协同演化确实发生过(Butler et al.,2009a;2009b)。因此,可以通过多样性的不一致性,证伪生物类群之间存在协同演化。
Butler等人基于PBDB数据库以及从其他大量原始文献中整理出来的信息,使用Microsoft Access建立了一个关于白垩纪植食性非鸟恐龙与植物分布的新数据库,并将动物区系信息与古生态、地质时期及沉积学等数据结合分析(Butler et al.,2009a)。在这一数据库的基础之上,根据有效属和化石记录的数量,可以生成白垩纪植食性恐龙与主要植物类群的绝对和相对多样性曲线图(图2)。从中可以获知,除了晚白垩世的肿头龙,其他植食性恐龙的多样性与被子植物多样性并不具有相关性。也就是说,从主要类群的角度来看,植食性恐龙和被子植物之间存在协同演化的假说并不能成立。而肿头龙类与被子植物的多样性呈正相关(图2a,b),有可能受采样不足的影响。同时,剑龙目与被子植物的多样性呈负相关,但与苏铁的多样性却呈正相关。针对这点,Butler等人又进行了更深入的研究,他们发现苏铁的系统发育中几个比较关键的类群演化特征,都在一定程度上受恐龙类群的影响,与前人认为恐龙是中生代苏铁种子传播者的理论相符(Butler et al.,2009b),但仍未能证明二者之间存在协同演化现象。

图2 植食性非鸟类恐龙(a-d)与主要植物类群(e-f)的比较(据Butler et al.,2009a)Fig. 2 Comparison of major groups of herbivorous nonavian dinosaurs, and major plant groups
6.2 量化采样偏差对恐龙多样性研究的影响
古生物学揭示了宏演化理论中生物多样性的深时模式,而衡量生物多样性的标准之一,是分类单元的多样性。但是,所有地史时期生物多样性研究的基础数据都普遍存在不同程度的偏差,比如化石记录的时空分布不均会产生采样偏差,这种偏差在大化石的研究中的影响表现得更为明显。因此,有学者提出一种“共同原因”(common cause)假说:认为采样和生物多样性,可能都受到某些共同因素的影响,这一假说近些年来成为古生物学的热点之一(Sepkoski,1976;Peters and Foote 2001;Smith et al.,2001;Peters,2005,2006;Benton and Emerson,2007;Wall et al.,2009)。为解决这一争议,部分学者开始尝试量化采样、多样性和共同原因之间的关系,然后通过统计建模或采样标准化来改善采样偏差(Butler et al.,2011)。其中,“采样校正”主要用于改善古生物多样性曲线(Smith and McGowan,2007;Alroy et al.,2008;Barrett et al.,2009;Mannion et al.,2011),但是,如果深时多样性和采样多样性都受到共同原因的影响,那么采样指标和多样性之间的相关性,则不能完全反映出真实的因果关系。此时,试图“校正”古生物多样性曲线,反而可能会扭曲真正的多样性信号(Butler et al.,2011)。
海平面变化通常被认为是一个共同原因,它会影响浅海生物化石记录的形成。陆地上产生的洪水会导致海平面发生变化,海平面升高可以促进海洋环境的形成和扩张,使得海洋生物多样性和含磷化石呈增长态势。但是,对陆地共同原因的机制的了解和讨论都很少(Sepkoski,1976;Peters,2005;Wall et al.,2009)。Butler等人借助于PBDB的海量化石记录,对恐龙多样性、采样强度与陆地洪水和海平面变化之间的关系进行了定量分析,为识别陆地共同原因提供了新的思考角度(Butler et al.,2011)。该研究表明(图3),陆洪/海平面与恐龙多样性/采样之间存在显著的相关性,但经过去趋势和消除自相关性后,这种相关性不再存在。相比之下,多样性和抽样之间存在强相关性,经过多种数据转换后,仍呈稳健的相关性。这表明,陆洪/海平面与分类多样性/取样之间的相关性,是所有数据中均存在的长期一致的上升趋势所造成的。也就是说,恐龙多样性与海平面波动无关,陆地共同原因假说未能得到证实。相反,化石记录的采样强度发生变化,可能是中生代陆地生物多样性发生短期变化的主要原因。

图3 海平面、恐龙多样性与沉积量等参数的比较(据Butler et al.,2011)Fig. 3 Comparison between sea-level curves, dinosaur diversity and sedimentary volume
6.3 评估化石出版的历史数据对恐龙多样性研究的影响
重建地质历史时期的生物多样性一直是古生物学领域的研究热点和难点。在大型数据库(如PBDB)、采样校准方法与计算机建模技术等不断发展的基础上(Alroy,2003b,2010;Smith and McGowan,2007;Lloyd,2012;Starrfelt and Liow,2016),古生物多样性的研究也逐渐开启了新的研究视角。如何根据化石记录中承载的信息客观地分析地球深时生命的宏观演化模式与过程,成为古生物学家日益关注的热点。这一研究深度依赖于化石记录的数量与数据的科学性和准确性,学者已经发现,采样强度、含化石岩石数量和分类学等因素会对生物多样性研究产生干扰(如Uhen and Pyenson,2007;Benton,2008;Tarver et al.,2011;Smith et al.,2012;Smith and Benson,2013)。但是,化石出版的历史数据,或者说研究强度是否会对恐龙宏观演化产生影响,却很少有人考虑。
Tennant等人(2018)使用PBDB中的恐龙化石记录数据,对化石数据积累对生物多样性评估的影响进行了分析。他们选择了鸟臀目、蜥脚亚目和兽脚亚目三个恐龙类群为研究目标,使用属级化石记录数据进行评估,以原始多样性和二次抽样方法进行分析(图4,5)。研究表明,随着时间的推移,化石记录的不断补充使得采样基础得到了很大的提升,但仍有一些时段或地区的恐龙多样性极不稳定。也就是说,历史数据直接作用于数据库收录的信息内容,从而对恐龙多样性研究产生实质性的影响。尤其是基于化石记录的全球生物多样性分析,会严重受到化石记录不完整甚至是截然不同的区域性数据的影响。研究也表明,分类单元细化可以改善采样偏差,科学采样会对分类单元的分布记录产生正向影响,从而提高恐龙多样性研究的可信度(Tennant et al.,2018)。既然化石出版的历史数据变化会对恐龙多样性计算产生实质性的影响,那么分类单元、系统分类学及采样偏差等方面的历史数据变化,是否也会对恐龙多样性分析产生不同程度的影响,值得我们进一步的思考。

图4 新出版19世纪以来的恐龙化石记录和属名出现频率(a,b)和累积频率(c,d),失效或修订的恐龙分类单元(e)(据Tennant et al.,2018)Fig. 4 Frequency (a, b) and cumulative frequency (c, d) of newly published dinosaur occurrences and genera through publication time, and invalidated or revised dinosaur taxa number (e)
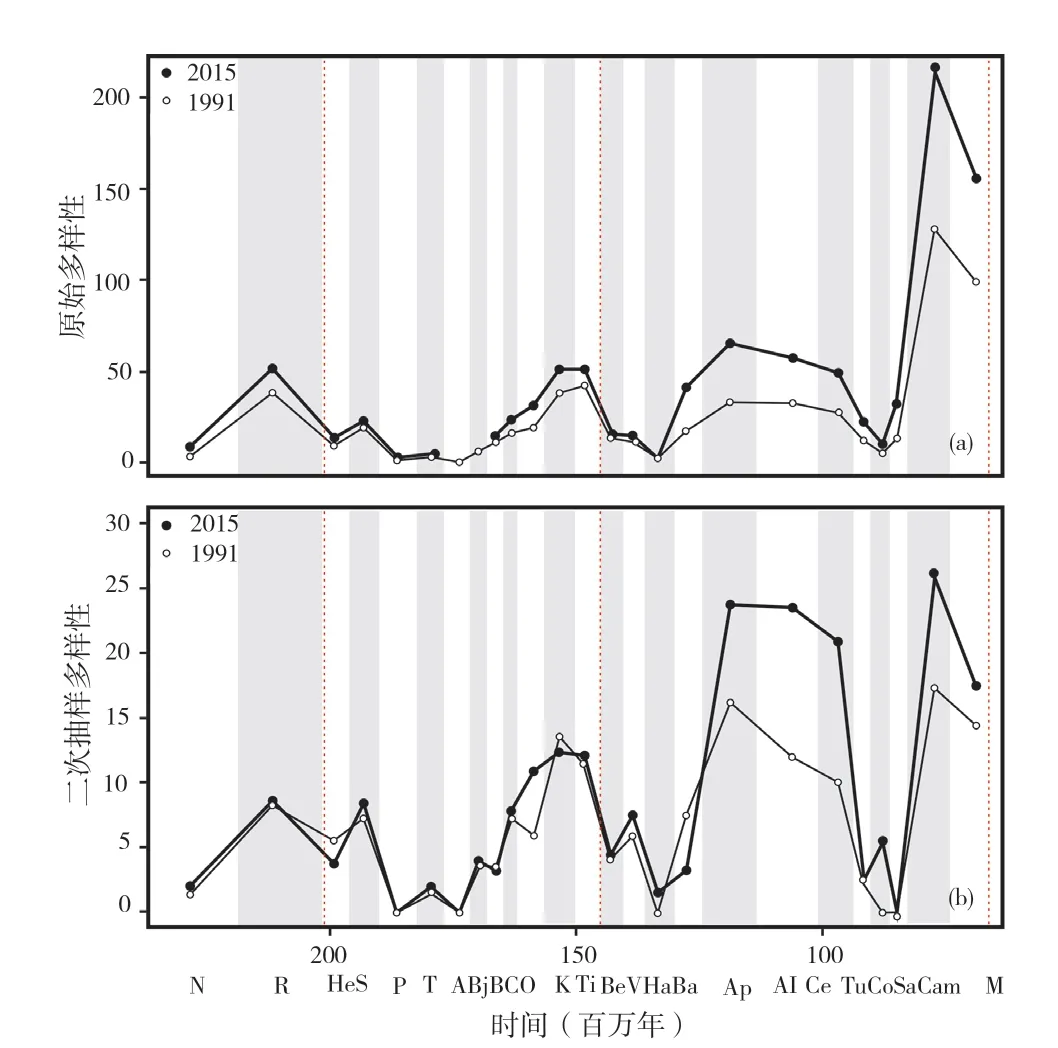
图5 原始数据(a)和二次采样数据(b)的恐龙“全球”多样性模式(据Tennant et al.,2018)Fig. 5 Raw (a) and subsampled data (b) of the dinosaur ‘global’ diversity model
7 总结与思考
总的来说,现有的恐龙学相关数据库已经有了二十年的历史,并在不同程度上涉及到科普性、专一性、综合性和分析性这四大方面,但在系统性、专业性和互通互联等方面尚未完善,即尚未出现如PBDB之于古生物学、GBDB之于古生物学与地层学的这种意义上的系统的恐龙学数据库。新一代的恐龙数据库,应当是一个整合了恐龙分类学信息、化石产出信息、地理位置信息、生物地层信息和文献信息等多项数据资源,打造而成的基于互联网和数据库技术的数字化科研平台,满足恐龙学的科研、科普、教育等全方位需求。并且,在技术方面,还需重视与当今大数据、人工智能等技术的融合。具体而言,笔者对新一代恐龙数据库的创建产生了以下思考:
(1)在建库的宏观思路方面,需要重视以下几点:(a)学科知识体系梳理和数据库框架建设方面,应该由精通大数据技术和恐龙学的学科专家负责,软件开发人员为辅;(b)数据集成过程中应由国际专家把控数据的权威性与科学性,并切合用户当前及未来可预见的科研、科普、教育和应用的实际需求;(c)记录历史数据,避免数据多解性和时效性的影响,开发多种常用的数据可视化、数据建模和数据分析工具等;(d)加强与全球其他恐龙学相关数据库的共享与集成;(f)针对恐龙的科普性做针对性开发,科普性要呈现出互动感与参与感。
(2)在数据内容方面,应包含以下方面:(a)具体地理位置产出的具有分类学鉴定特征的化石记录,以及相关的文献出处或数据来源;(b)包含年代地层、生物地层等可指示地层或地质年代属性的数据;(c)基于GIS的采样点经纬度或基于GPlates的古地理重建数据,从而可以将数据直观地呈现在数字化地质图、地形图、地理图和古地理图上。此外,还需要同时记录与上述信息相关的历史数据,即使某些历史数据曾被认为是无效甚至是错误的,从而保证数据库的客观性。
(3)在数据分析功能方面,应支持以下的功能:(a)分类学研究:可协助用户确定标本的系统分类、制作同异名录等;(b)生物多样性研究:支持分异度统计、新生率/灭绝率分析、样品采样偏差校正及生物地理演化等分析手段;(c)系统发育研究:与最新文献联动,提供支持多种构建算法与分析方法的系统发育树;等等。
(4)其他值得重视的问题:(a)必须考虑数据版权和数据共享的问题,首先要肯定数据录入、整理专家的数据所属权,并客观、清晰地体现数据来源与原始生产者,再赋予数据可计入引用量的DOI等指标,尊重数据贡献者的劳动成果;(b)关于数据库的长期可持续发展,需要确保稳定的人力投入与项目经费的支持,并且需要收集量大且覆盖面广的数据资源,开发实用的数据分析功能,设计便捷的用户体验等,从而获得广泛的用户群的支持。
致谢:感谢中国科学院古脊椎动物与古人类研究所潘照晖助理研究员的细心修改与指导;感谢评审专家对本文提出了宝贵的修改意见和建议。本文系“深时数字地球”(Deep-time Digital Earth)大科学计划的系列成果之一。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
小学阅读指南·低年级版(2016年11期)2017-02-06
科技知识动漫(2016年12期)2016-12-23
漫画月刊·哈版(2016年1期)2016-02-22
小学科学(2015年11期)2015-12-01
小学科学(2015年2期)2015-03-11
小学科学(2015年1期)2015-03-11
