
基于改进GST算法的字符串相似度检测*
2021-03-05 04:08孙宇扬奉松绿周恺卿
吉首大学学报(自然科学版) 2021年5期
孙宇扬,欧 云,奉松绿,周恺卿
(吉首大学信息科学与工程学院,湖南 吉首 416000)
字符串相似度检测是计算机领域的基础研究问题之一,在抄袭检测系统[1]、防代码剽窃系统[2]、自动评分系统和生物DNA序列匹配[3]等领域都有非常广泛的应用.字符串近似匹配算法有编辑距离算法(Levenshtein Distance,LD)、最长公共子串算法(Longest Common Subsequence,LCS)、贪婪串匹配算法( Greedy String Tiling,GST)[4]等.
GST是字符串近似匹配的经典算法的代表[5].该算法设计的目的是为了检测2个字符串的相似度.由于算法执行过程中采取字符串逐个比较的机制,因而GST存在效率低、时间复杂度较大、扫描时间长等缺陷[6].徐黎明等[4]提出了一种将克努特-莫里斯-普拉特算法(Knuth-Morria-Pratt,KMP)和GST算法相结合的改进算法来提升GST算法的扫描速度.巫喜红等[7]采用2次Hash函数和双向并行匹配方法改进随机串匹配(Karp-Rabin,KR)算法,提高了模式匹配速度.金恩海等[8]将LCS算法应用到GST算法中的数据预处理阶段,提升了算法的准确性.受以上研究启发,笔者拟设计一种改进的双向的KR算法,并将其应用到GST算法中的扫描阶段,以期减少字符的比较次数,提高字符串相似度检测算法的运行效率.
1 相关概念和技术
1.1 GST算法
GST算法通过反复对模式串和文本串遍历搜索来实现字符串匹配功能,其中较短的字符串被称为模式串,较长的字符串则被称为文本串[5].GST算法的基本原理为:若比较的2个字符串相同,则返回一个与较短字符串的长度相同的值,反之,则返回最小值0.
1.2 KR算法
KR算法是使用散列函数从文本中搜寻单个模式串的字符串搜索算法[6].其算法思想为:定义一个Hash函数,利用Hash函数先对模式串进行数值化,得到一个散列码;将文本串中与模式串长度相同的每个子串进行数值化,得到相应的多个散列码;用模式串的散列值依次与文本串的散列值进行两两比较,若相等,则判断其对应字符是否相等,进而确定字符串是否匹配[7].
2 算法的改进
2.1 改进算法的思路
首先,对KR算法进行改进,在计算字符串的哈希值时,从文本串和模式串的开头和结尾两端同时求哈希值,并进行比较,判断字符串是否匹配.
其次,将改进KR算法应用到GST算法的扫描阶段,搜索所有相同子串.
2.2 改进算法的流程
Step1首先假设2个字符串分别为T和P,定义队列tiles,最小匹配长度为Lmin,最大匹配长度Lmax,搜索长度s.
Step2判断当前s和Lmin的大小关系,若s Step3遍历字符串T,若当前下标的字符没有被标记(初始状态均为未标记),若s小于Lmax,则移动下标,否则使用改进KR算法计算出T串的散列值. Step4遍历字符串P,若当前下标的字符没有被标记(初始状态均为未标记),则使用改进KR算法计算出该串中长度为s的子串的散列值;若T和P的散列值相等且当前下标的字符相等,则同时往后寻找一位,重新计算并比较散列值,直到T和P当前位置的散列值不同.此时若搜索长度s大于2倍的Lmax,则更新最大匹配长度并返回step 3. Step5记录最大匹配,每个队列记录相同长度的最大匹配,队列列表的次序按照长度依次递减.针对队列中的tile,循环最大匹配长度,对已经匹配的长度进行标记.若最大匹配中还有未做记号的部分,则替换列表队列上的未标记部分. Step6若当前搜索长度s大于2倍的最小匹配长度Lmin,则将s更新为s的一半,跳转到step 2;否则,若当前搜索长度大于最小匹配长度Lmin,则将s更新为最小匹配长度,跳转到step 2. Step7输出匹配结果,算法结束. 改进算法的流程如图1所示. 图1 改进算法的流程Fig. 1 Improved Algorithm Flow 表1 部分数据 表2 查重结果 由表2可知,模式串7抄袭的可能性较大,其他模式串抄袭的可能性较小. 在相同的数据集上进行代码查重实验,改进算法和GST算法的字符串比较次数结果见表3. 表3 2种算法的比较次数 由表3可知,改进算法相比GST算法,在运行次数上有了大幅度的降低,从而提高了算法的整体运行效率. GST算法在运行过程中存在时间复杂度高、效率低等缺点,为了克服这些缺点,提出了一种改进的KR算法.通过对KR算法采取双向并行搜索方式,来提高KR算法的匹配速度,进而将其应用在GST算法中的扫描阶段,提升GST算法的搜索效率.学生作业源代码为实验数据对改进算法和GST算法进行了性能测试,结果表明改进算法减少了匹配次数,降低了算法运行时间,提高了代码查重的效率.后续将从查重精度方面进一步改进算法.
3 实验结果与讨论
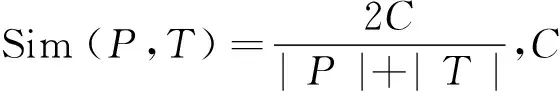



4 结语
猜你喜欢
集美大学学报(自然科学版)(2021年2期)2021-04-29
无线互联科技(2020年11期)2020-12-01
科学导报·学术(2020年26期)2020-10-21
汉字汉语研究(2020年2期)2020-08-13
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
小学生学习指导(低年级)(2019年12期)2019-12-04
电脑爱好者(2019年8期)2019-10-30
科教导刊·电子版(2016年30期)2016-12-26
青年文学家(2016年32期)2016-12-23
