
基于特征融合和改进卷积神经网络的环境音识别
2021-02-27 01:29:42李志华韩灿灿
计算机与现代化 2021年2期
徐 睿,李志华,韩灿灿
(河海大学能源与电气学院,江苏 南京 211100)
0 引 言
听觉是人类感知周边环境的主要手段之一,因此,想要达成使计算机有类人的感知能力这个目标,准确地通过声音来判别周围情况是一项极其关键的任务。根据声源的不同属性,音频可分为语音、音乐和环境音[1]。与另外2种声音不同的是,环境音的结构更加复杂;同时,语音和音乐都有特定的含义,如语音是由音素组成,而环境声音并不具有类似的特定含义。近年来,环境音的识别(ESC)得到了越来越多的关注,它已被成功应用在音频监控系统[2]、城市声音的降噪[3]等方面。环境音识别被重视不仅因为其广泛的应用,更是因为其复杂的结构。将针对语音或音乐开发的系统应用在ESC上,会由于无法提取足够具有代表性的特征,导致效率低下,因此,研究适用于环境音分类的高效识别模型是必然趋势。
环境声音识别的2个关键部分是音频特征的提取和分类算法的选择。一些研究人员将人工设计的音频特征(如MFCC特征,过零率等)与传统机器学习算法相结合,并在特定场景下取得一定的成果。Yu等人[4]提取MFCC作为特征,结合随机森林算法,完成了声音事件检测任务。随着深度学习技术的发展,神经网络已被证明比传统的分类器在解决复杂分类问题上更有效。其中,卷积神经网络(CNN)被广泛应用在音频领域中,如语音识别[5-6]、音乐分类[7-8]、环境声音分类[9-10]。它能捕获时域和频域特征,解决传统机器学习算法的不足,因此被认为是音频识别中最合适的模型。文献[9-10]中提取Log-mel频谱图,利用CNN进行分类。部分学者聚焦于端到端的学习,利用CNN直接从音频的原始波形中提取深层次的特征,无需用到人工特征[11]。也有一些研究者发现人工特征与波形特征能相互补充,使用平均融合策略将2种模型进行结合,性能超过了单个特征的模型[12]。但仍存在局限性:1)许多特征是为语音或音乐设计的,单个特征无法表征复杂的环境音;2)平均融合忽略了单个模型的变化趋势;3)固定尺寸的滤波器提取的特征不具有足够的区分度。
为了解决以上问题,本文提出一种基于D-S证据理论多特征融合的环境音识别模型。首先提出2个网络MS-CNN和SF-CNN。MS-CNN提取4种互补特征进行训练,SF-CNN采用多尺度卷积核直接从原始波形中学习,最后用D-S证据理论融合2个网络,得出最终分类结果。
1 研究对象与方法
1.1 研究对象分析
本文主要针对室外场景的声音进行研究,如汽车鸣笛声、狗叫声、雨声等。经研究发现,这些声音主要有2种类型:1)连续稳定的声音,如下雨声等;2)单一的声音,如汽车鸣笛声等。如图1所示,以狗叫声与汽车鸣笛声波形图为例,可见狗叫声是连续稳定的,有一定的周期性,而汽车鸣笛声则是集中在某几秒。
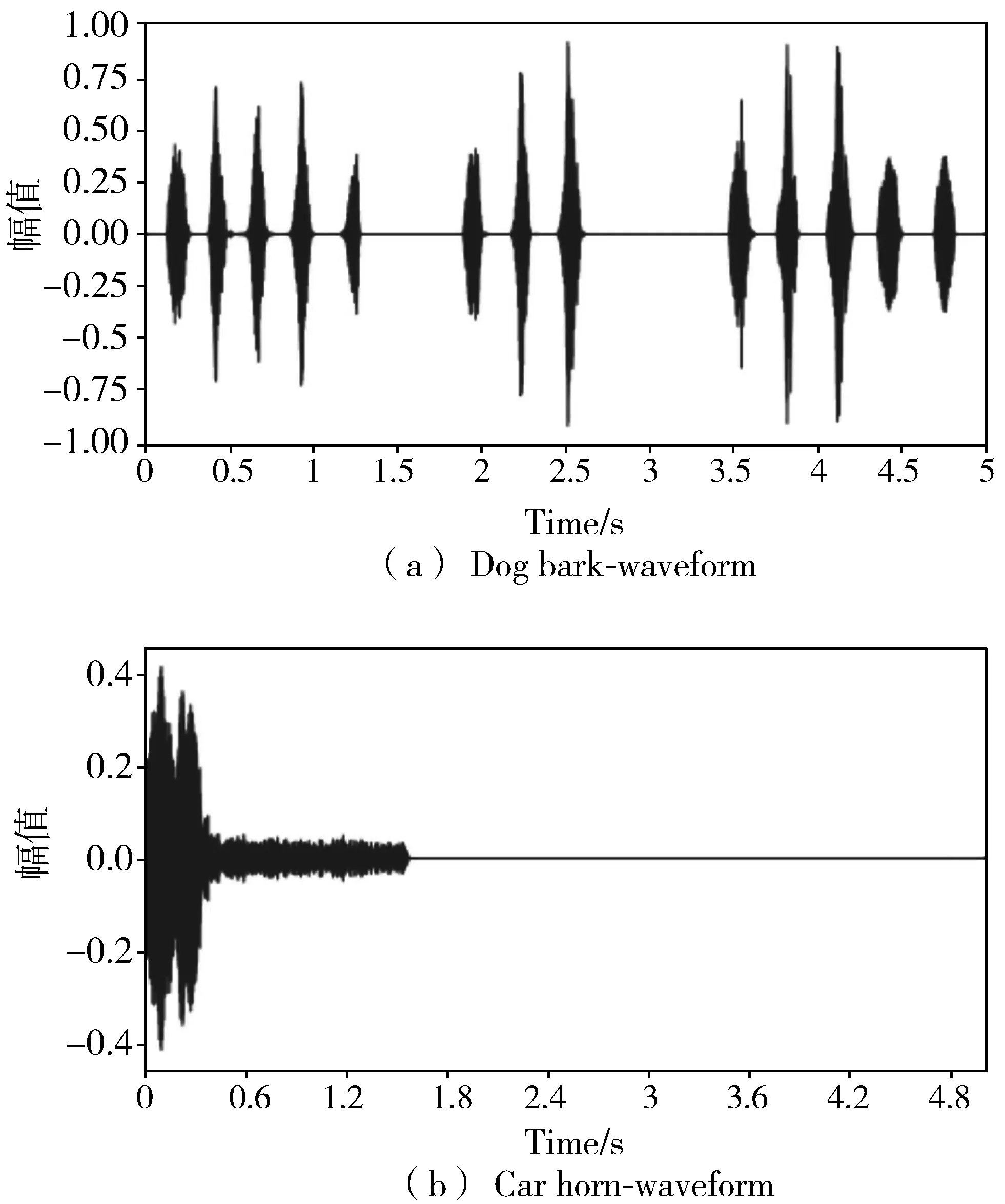
图1 狗叫声与汽车鸣笛声波形图对比
1.2 特征提取与融合
本文针对复杂的环境音识别问题进行了多特征融合。MFCC是应用最广泛的一种特征,是梅尔频率域提取出的倒谱参数,能够以一种紧凑的方式呈现音频总体特征,但是它对噪声很敏感,处理背景音杂乱的音频时表现较差。而GFCC是基于非线性的伽玛通滤波器组提取的倒谱系数,有良好的抗噪声、抗干扰能力,在识别复杂的环境音时,两者结合能够很好地弥补MFCC的不足。以上2种特征是模仿人耳听觉特性得到的,因此对低频部分更加敏感,为了补充其他频段的信息,引入CQT特征。CQT是一种可变窗长的信号谱分布计算方法,在低频段有更高的频率分辨率,高频段有更高的时间分辨率。最后,引入频谱对比度来补充结构特性,由于MFCC等特征会将子频段的频谱平均化,从而失去相对特性[15],例如相似规律的不同类别音频即使有不同的频谱分布,却可能会有相似的平均谱特性。而频谱对比度能够对比子频段的峰、谷值及之间的差异,提供更多的频谱结构信息。
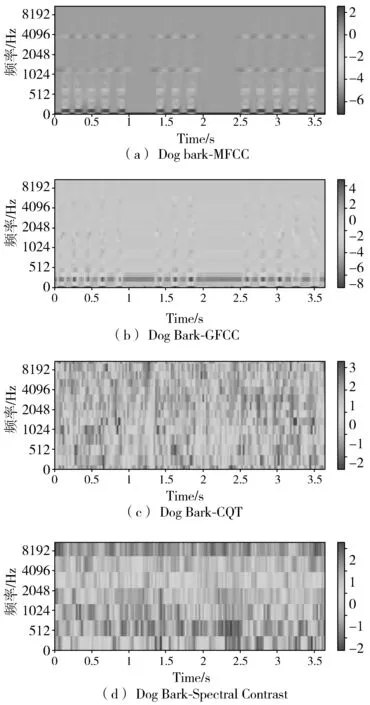
图2 3-157695-A.ogg样本提取的4种特征的可视化
本文以数据集ESC-50里3-157695-A.ogg狗叫样本为例,对特征进行可视化分析,所有的特征向量都进行了标准化处理。如图2所示,通过色块的颜色深浅来判断其能量值大小,明显可见,在尖峰区域MFCC能量值较大,而GFCC能量值很小,表明这2种特征以不同的形式表征音频信息,可以起到互相补充的作用。图中的CQT特征不止局限于低频段,能够捕获不同频段的特征,同时频谱对比度体现出各个子带中的差异性。
1.3 多尺度卷积运算
基于原始波形进行端到端的学习也是音频识别领域的一种热门方法。其中常用的CNN是使用固定大小的卷积核来提取波形中的特征,表达式如式(1)所示:
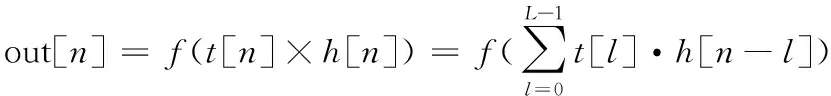
(1)
式(1)中,t[n]表示输入的音频信号,h[n]表示长度为L的滤波器,f(·)为激活函数,out[n]为经卷积核滤波后的输出结果。这就是标准卷积运算,由这样固定、单一的滤波器提取的特征没有足够的区分度。处理复杂波形时,若在波形上使用宽窗口,网络将更多地学习低频区域,而忽略了高频部分,反之则会更多地学习高频区域,很难达到一个平衡。
本文参考了文献[16]提出的多尺度卷积运算,将其应用在本文的MS-CNN网络结构内,多尺度卷积运算表达式如式(2)所示:
out(s)[n]=f(t[n]×h(s)[n])
(2)
式中,上标s表示不同的维度(s=1,2,3)。
根据多尺度的卷积核,通过改变步长,网络可以采用窄窗口来学习高频段的特征,反之采用宽窗口来学习低频段的特征,最后将不同尺度的特征图沿着频率轴拼接,利用最大池化将这几种特征图缩小到相同维度,形成能够全面表述该段音频信号的特征。标准卷积与多尺度卷积特征提取对比如图3所示。
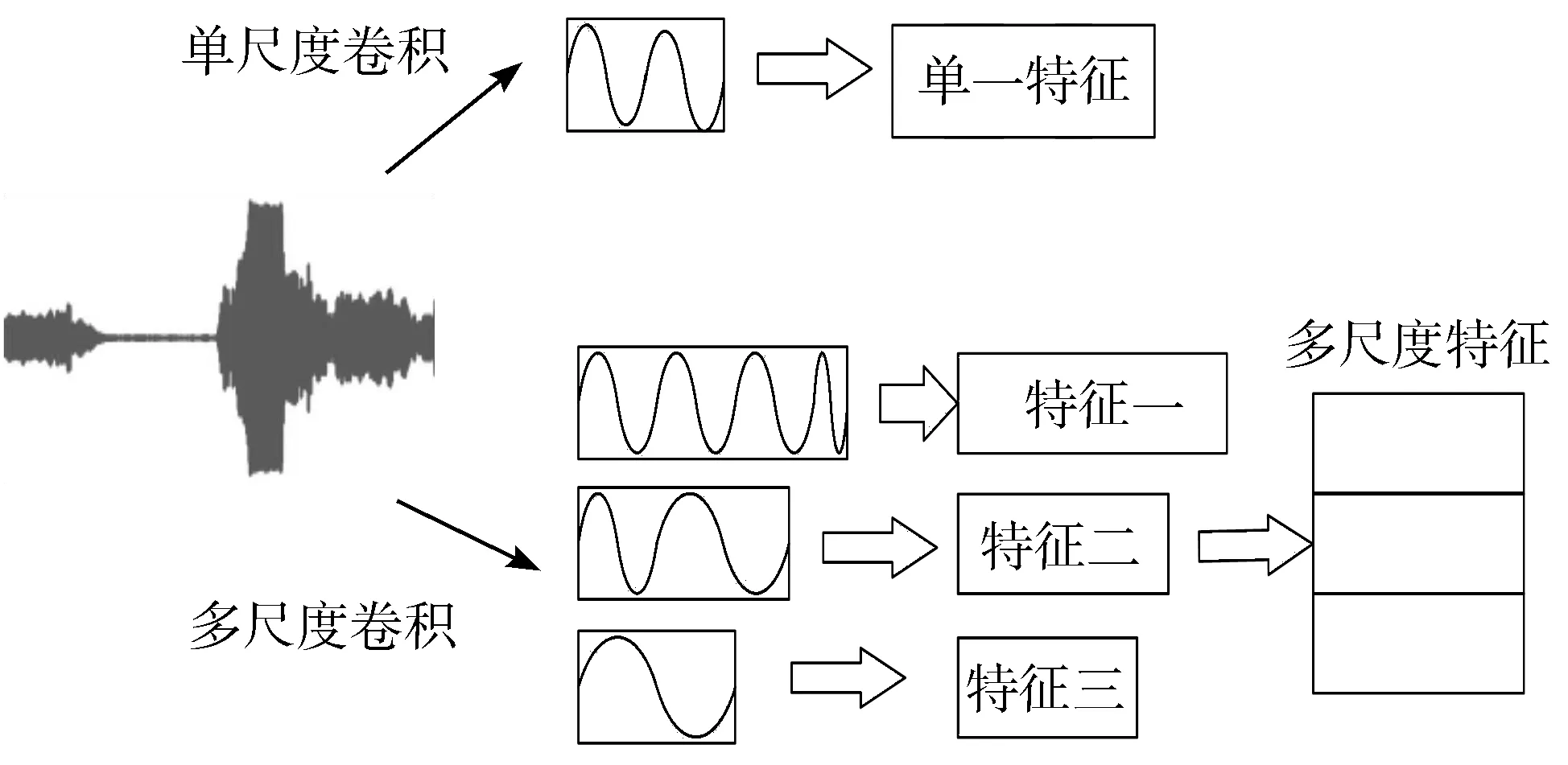
图3 标准卷积和多尺度卷积对比[16]
1.4 D-S证据理论融合方法
D-S证据理论是由Dempster首次提出,其学生Shafer结合具体应用范围改进得出的一种数据融合方法[17]。D-S证据理论能够以高效率处理不确定性的问题,主要作用是将多个主体(如不同分类器的输出结果等)相融合,利用证据的概念以及组合不同的证据来进行推论。目前在信息融合、故障诊断、人工智能等领域已被广泛使用[18-20]。
D-S证据理论基本的概念为:识别框架Θ和有限的假设子集{A1,A2,…,An}⊆Θ。在本文中,数据集ESC-50中每一类声音都被视为识别框架Θ下{A1,A2,…,An}中的一个元素。根据ESC-50类别可知n=50。同时,MS-CNN和SF-CNN网络通过Softmax层的输出值被看作mass函数m1和m2,本文根据D-S证据理论来对2个模型的输出进行融合,融合公式如式(3)、式(4)所示:
(3)
(4)
其中,k为归一化常数,B和C为2个网络对某一样本的预测结果。本文中将m1⊕2(A)作为模型融合的最终预测结果。
2 MFD-CNN网络结构与整体流程图
2.1 网络结构与参数
卷积神经网络一般将卷积层与池化层等进行不同的组合。卷积层利用卷积核与输入进行运算,得到特征图。池化是对卷积后提取出的特征进行子采样,降低计算复杂度。本文采用的是最大池化,即取局部区域中值最大的点,既能保留主要特征,又能减小特征图尺寸。为了避免反向传播时梯度消失问题,本文引入Batch Normalization(BN),其核心是把向极限饱和区靠拢的输入分布引入到均值为0、方差为1的标准正态分布,增大梯度。在卷积运算后,还需引入激活函数增加模型的非线性,提高模型表达能力。本文选用Relu函数,表达式为:f(x)=max(0,x),能够提高计算速度和收敛速度。
MFD-CNN网络结构如图4所示,具体参数如下:
在SF-CNN中,主要有4个卷积层、5个Relu层、1个池化层和1个全连接层。卷积层可分为2组,第一组(conv1和conv2)中每层为32个卷积核,大小为3×3,步长为1,不同之处在于conv2后增加了最大池化层来减少特征的维度。第二组卷积层(conv3和conv4)为提取更高层次的特征,每层为64个卷积核,大小为3×3。conv3的步长为1,为了进一步减少维度,conv4的步长设置为2。将第4个卷积层输出数据经过一系列的操作后输入到全连接层中,其中有1024个隐藏单元。输出层由50个神经元构成,采用Softmax函数。每个卷积层和全连接层后都应用了BN和Relu函数。
在MS-CNN中,第一卷积层C1采取多尺度卷积运算,有32个卷积核,利用卷积核大小及步长的不同实现了3种不同尺度的运算,分别为A(大小11×1,步长为1)、B(大小51×1,步长为5)、C(大小101×1,步长为10)。第二卷积层C2有32个卷积核,大小为11×1,并采用池化层将特征图统一到相同维度上,得到多尺度特征图。接着依次为4个卷积层,卷积核数量分别为64、128、256、256,卷积核大小均为3×3。最后使用了具有4096个神经元的全连接层和相应的输出层。卷积层C2、C3、C4、C5、C6后均连接了对应的池化层进行降维操作。
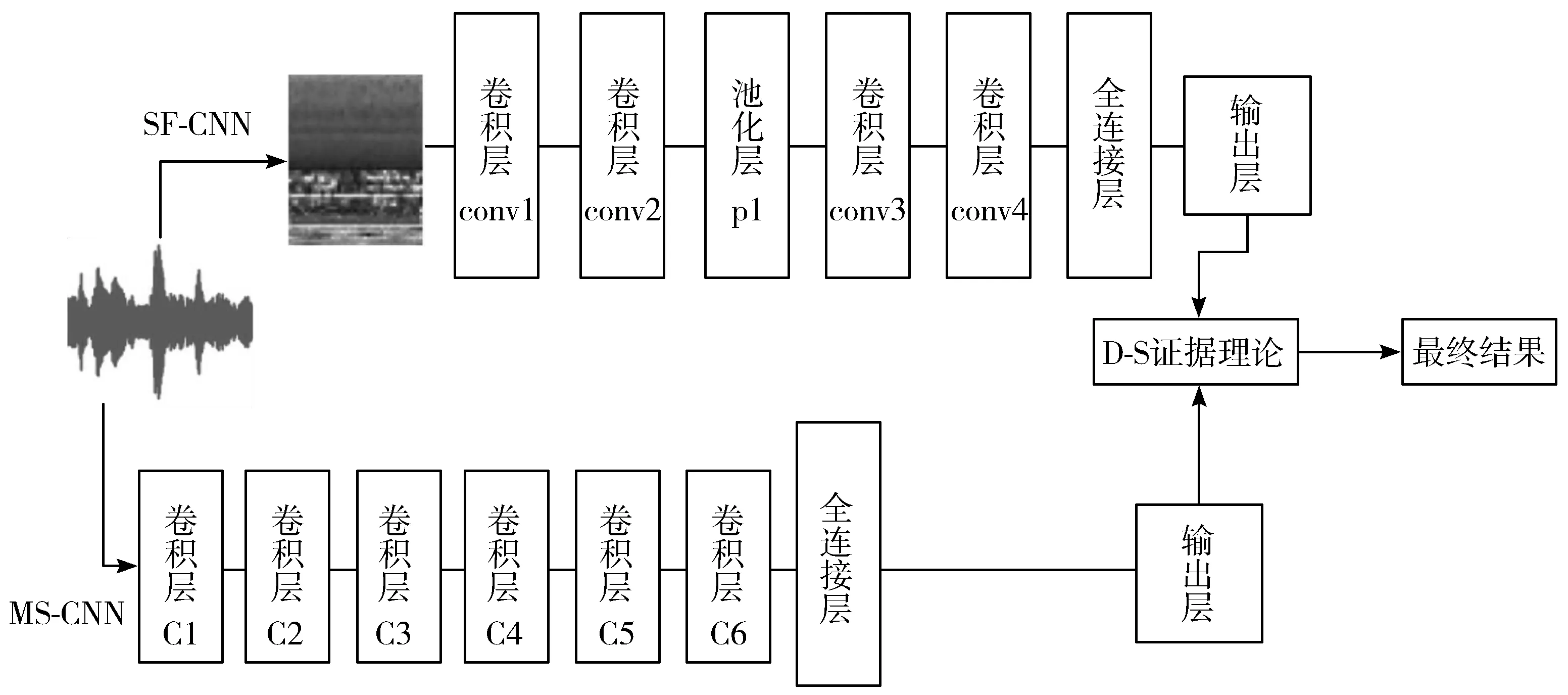
图4 MFD-CNN网络结构图
2.2 整体流程图
本文方法的整体流程如图5所示。首先将数据集划分成训练集与测试集。接着从训练集提取特征数据输入到网络中,经过多次的迭代训练,直至网络收敛,保存模型。再把测试集中的样本数据输入到训练好的MFD-CNN中,得出识别准确率。
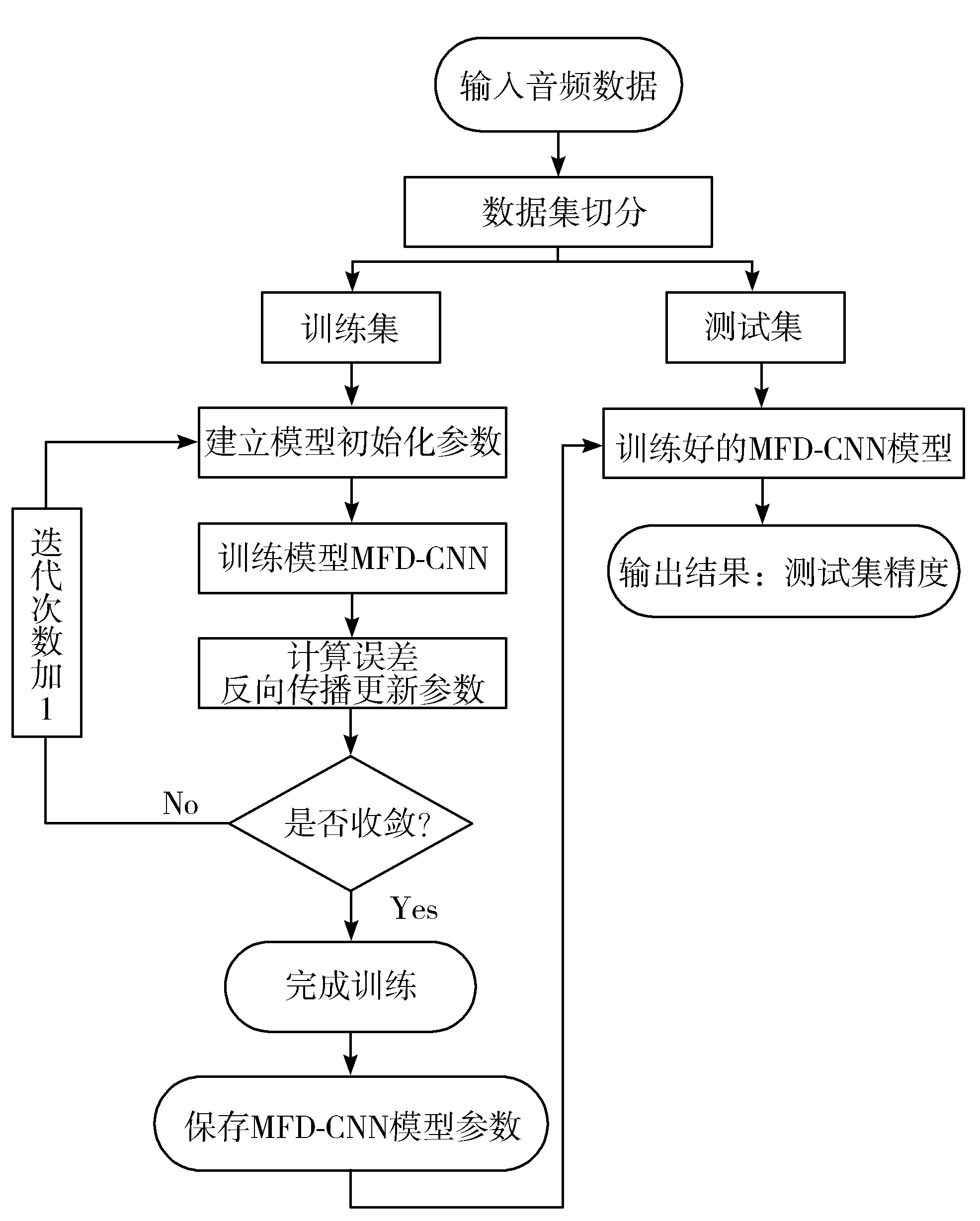
图5 整体流程图
3 实验结果与分析
3.1 数据集
本文使用著名的环境声音数据集ESC-50,来训练并测试所提出的MFD-CNN模型。ESC-50是使用最广泛的环境音识别基准数据集之一,由2000个时长为5 s的音频片段构成,分别以16 kHz和44.1 kHz进行采样[21]。数据集分为5大类:动物声、自然声音和水声、人类非语音声音、室内声音以及城市室外声音。本文以五折交叉验证的方式来评估该模型的效果。
本文将音频样本重采样至22.05 kHz,对其进行分帧操作,窗口长度为1024,帧重叠率为50%。在SF-CNN的特征提取中,使用Python第三方音频信号处理库Librosa0.7.2和Spafe0.1.2来实现。以帧为单位,提取了13维的MFCC参数作为特征,同时为了更好地体现其动态特性,分别提取MFCC的一阶差分和二阶差分各13维,拼接后组成一个新的MFCC特征向量,共计39维。除此之外,还提取了30维的GFCC,14维的CQT以及7维的频谱对比度。在完成特征提取这一步后,为了更好地训练网络,对特征向量进行了归一化操作。学习率设置为0.001,dropout参数设置为0.5,训练轮数为100。实验设备为NVIDIA GeForce GTX 1660 Ti显卡和Intel(R) Core(TM) i7-9750H CPU处理器。
3.2 实验结果分析
本文以模型在ESC-50数据集上的识别准确率为评估指标。表1列出了所提出网络在数据集上的结果,其中SF-CNN将几种互补特征进行融合,准确率较高,达到了81.20%。为了体现多尺度卷积运算的有效性,将多尺度卷积和标准卷积的实验结果进行对比,Sta-CNN模型将第一、第二卷积层替换为标准卷积层,后端网络采用与MS-CNN一样的结构。结果表明,采用多尺度卷积运算的MS-CNN准确率达到了70.80%,而标准卷积下的Sta-CNN,准确率为66.20%。同时可知,由于多尺度卷积运算的引入,网络的可解释性显著增强,多尺度卷积层可以提取不同的特征,能够更好地代表音频信号,而标准卷积模型无法学习到明显的可解释性信息,表现相对较差。最后,评估了利用D-S证据理论融合后的模型MFD-CNN的表现,准确率达到了83.45%,比SF-CNN模型提高了2.25个百分点,说明原始波形中的特征能够补充人工堆叠特征中缺少的信息,验证了模型融合的成功。

表1 模型在不同网络结构下的准确率对比
3.3 模型对比
为了进一步验证本文模型的优越性,将其与现有的一些环境音识别模型进行对比。根据表2的前3行,不难发现,同样是以原始波形为特征进行端到端的学习,本文所提出的MS-CNN准确率与EnvNet相比提升了6.8个百分点,文献[22]中首次利用CNN对环境音进行端到端的学习,而RawNet[23]进行了改进,在网络中采用了较小尺寸的卷积核并且取得了一定的成效。本文结合了多尺度卷积运算与小尺寸卷积核,准确率显著提高,表明多尺度卷积运算成功地从原始波形中学到了更多有代表性的特征。
如表2所示,DA-Net[24]提取了12维的MFCC特征向量,得到了68.40%的准确率,加入基于伽玛通滤波器的特征TEO-GTCC,准确率提升到72.25%。本文的主要创新点之一是引入音乐检索常用特征:除了以MFCC为主干外,还引入了GFCC、频谱对比度和CQT,能够捕捉各个频段的特征,准确率提高至81.20%。该结果表明,特征的选取及维度对识别精度影响较大,多个特征能代表输入的不同信息,表现优于单个特征。
最后,将融合后的MFD-CNN模型与几种现有模型进行了比较。DS-CNN模型[23]采取了与本文模型相同的融合策略,即D-S证据理论方法,而本文提出的模型识别精度达到了83.45%,高于DS-CNN模型的准确率。同时WaveMsNet[16]中使用了多尺度卷积进行特征融合,但是后续将提取的特征图与log-mel频谱图融合在一个模型中,本文融合后的MFD-CNN与其相比,精度提高了4.35个百分点,验证了本文模型中特征选择与模型融合策略的有效性。
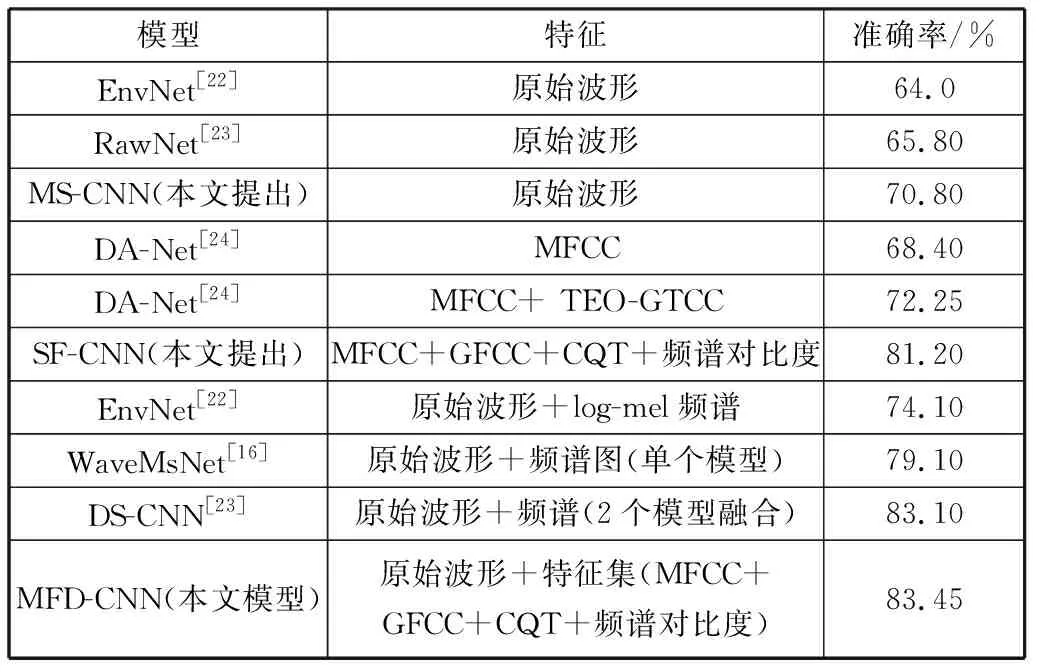
表2 不同模型在ESC-50数据集准确率对比
4 结束语
本文针对环境音的识别问题提出了一种基于多特征的改进卷积神经网络模型。该模型由2部分组成:SF-CNN(基于多特征融合)和MS-CNN(基于多尺度卷积运算)。在SF-CNN中,将常用于音乐检索领域的特征与其他常见特征结合起来,提取4种人工特征进行堆叠,分别为MFCC、频谱对比度、GFCC和恒定Q变换。实验结果表明,这些特征能够互相补充,提供更全面的信息来表征一段音频,对提高识别精度均做出了贡献。在MS-CNN中,利用多尺度卷积运算来替代标准卷积,针对不同频段作相应的处理,显著增强了网络的可解释性。最后使用D-S证据理论将2种模型融合。今后的研究重点将会集中在如何选取网络的超参数和网络结构,来进一步提升识别的准确率。
猜你喜欢
成都信息工程大学学报(2021年5期)2021-12-30 06:25:30
空间科学学报(2021年6期)2021-03-09 06:20:14
家庭影院技术(2018年11期)2019-01-21 02:20:52
测控技术(2018年7期)2018-12-09 08:58:22
电子制作(2018年19期)2018-11-14 02:37:08
电子制作(2017年9期)2017-04-17 03:00:46
人间(2015年8期)2016-01-09 13:12:42
无线电通信技术(2015年3期)2015-12-23 11:37:00
河北科技大学学报(2015年5期)2015-03-11 16:16:37
电测与仪表(2014年2期)2014-04-04 09:04:00
