
基于YOLOv5的道路病害检测与分类研究
2021-02-27 08:53李姗
现代计算机 2021年35期
李姗
(成都信息工程大学计算机学院,成都 610225)
0 引言
道路病害(裂隙、坑洞)检测一直以来在道路安全领域中起着举足轻重的作用,及时发现道路上的裂隙和坑洞并进行修补可以有效地减少路面病害(裂隙、坑洞)带来的损失,进而减少对路面行车安全的影响。早期的道路病害检测以传统LBP、Gabor等纹理特征提取为主,往往在实际中表现不佳。由于近年发展起来的深度学习技术可发挥从数据中学习表征的优势,基于深度学习的检测方法相对于传统的检测算法来说,其道路病害的检测精度已经有了很好的提升。
基于深度学习的道路病害(裂隙、坑洞)检测方法一般有三种:①图像分类。对不同病害类别或等级的路况图像进行标注,并在采集到的图像中进行重叠式区域划分,进行分类,可以是二类(有无病害)和多类(不同病害级别)。②语义分割。对道路病害进行像素级标注,使用U-Net等语义分割方法进行像素级分类。好处是可以刻画病害形态,但标注代价极其大。③目标检测。将病害位置标成目标框,在采集的图像中进行目标检测,既可得到位置也可以得到类别。本研究采用基于深度学习的目标检测算法进行检测。传统的目标检测算法主要是基于设计好的手工特征来进行检测,检测的效果主要与设计的特征质量有关。对于不同的目标而言,没有一种通用的特征,只能根据检测对象的特点有针对性地设计特征,所以鲁棒性很差[1-2]。近年来,基于深度学习的目标检测技术取得了长足的进步,无论是在检测效率还是准确率上都取得了很好的效果。
目前基于深度学习的目标检测算法大致可以分为两种方式:Two-stage目标检测算法与Onestage目标检测算法。Two-stage系列算法在目标检测过程中分两步完成,首先通过算法生成一系列的候选区域,然后再通过卷积神经网络进行分类 , 代 表 性 的 算 法 有 RCNN[3]、 Fast RCNN[4]、Faster RCNN[5]等,这一系列算法在检测的准确率和定位精度上相对要好一些,但在检测速度上无法满足实时性的需求。One-stage系列算法将目标检测问题直接当作回归问题来处理,不产生候选区域,直接预测出目标位置与类别;代表性的算法有 YOLO[6]、YOLOv2[7]、YOLOv3[8]、SSD[9-10]、RetinaNet[11]等,One-stage系列的算法精度上相对于Two-stage系列算法要低一些,但是检测速度要快很多。
相比于其他检测,道路病害检测具有两个非常大的困难:①道路图像拥有很多不规则形状的目标。②高分辨率致使背景复杂,语义信息丰富。因此,该文以One-stage系列算法中的YO⁃LOv5为基础,针对道路上的裂缝和坑洞目标,提出了一种基于pytorch实现的改进型YOLOv5。相比于YOLOv5,本文的贡献总结如下:①缩短算法的训练时间到以前的40%,这意味着我们在道路图像中可以更加高效地训练得到一个效果很好的目标检测器。②将注意力机制引入目标检测算法,并且以多个视角聚焦在我们感兴趣的区域去训练。③将Transformer模型引入目标检测算法,解决了图像在训练的过程中因分辨率降低所造成的信息丢失。
1 相关工作
1.1 目标检测算法介绍
基于深度学习的目标检测算法通常由四部分组成:input,backbone,neck,head。它主要有两个分支:一阶段和二阶段。二阶段算法主要由候选区域提取和目标的分类与回归组成。一阶段算法不用提取候选区域提取,可以直接确定物体的类别和位置。因此,两阶段算法精度高、速度慢,一阶段算法精度略低、速度快。
一个通用的目标检测器在backbone主要有以下 6 种 : VGG16, ResNet-50, SpineNet, Effifi⁃cient Net-B0/B7, CSPResNeXt50, CSPdarket53。它们都以一个视角去做特征提取,致使往往需要更多的层来达到提取相对充分的特征。但这远远不够,而且还使整个目标检测器的效率低下。
目前,在neck阶段的方式主要有:FPN,PAN。 NAS-FPN, Fully-connected FPN, Bifpn,ASFF,SDAM。按照融合和预测的分类顺序,它们的融合方式主要分为早融合和晚融合。它们在融合过程中并没有关注到所有的特征层,仅仅通过简单的堆叠和叠加操作进行融合,并且在融合阶段过多地使用下采样损失了过度的位置和细节信息,直接导致了算法的性能没有达到一个更好的水平。
1.2 YOLOv5介绍与基本思想
YOLOv5算法作为一种端到端的目标检测模型,只需要在输入端输入图像数据即可,在输出端得到一个预测结果,预测结果为边界框的位置信息、置信度以及所属类别。如图1所示,其基本思想是将输入图片分割成S×S个网格,如果标注的目标中心坐标落在某个网格中,那么就由该网络来检测这个目标。每一个网格都会预测出B个边界框,每个边界框都包含位置信息(x,y,w,h)、置信度(Confidence)以及C个类别的概率,对于输出层来说,最终的输出维度为S×S×B×(4+1+C)的张量。置信度是指边界框包含目标的可能性Pr(object)以及包含目标情况下边界框准确度IoU的乘积。
当检测目标位于该网格中,Pr(object)=1,否则为0。IoU用于表达真实框与预测框的重叠度,表示的是预测框和真实框的交集与并集的比值。当一个目标被多个检测框所预测时,通过设定阈值,将置信度低于阈值的边界框去除,并且对高于阈值的边界框进行非极大值抑制,去除多余的边框,最终得到最佳边界框。
1.3 YOLOv5特征提取网络
YOLOv5采用Cspdarket53作为特征提取网络。Cspdarket53相对于darket53来说,加入了cross stage partial结构,拥有特征复用和截断冗余梯度信息传递的优点。Cspdarket53有一个Darket⁃Conv2D_BN_Mish和数个Resblock_body组成。YOLOv5在cspdarket53之后介入了FPN+PAN结构,增加了模型的感受域,借用了PANET的思想,用来聚合不同尺度的特征层对应的参数。
2 YOLOv5算法改进
由于YOLOv5的最初版本在backbone阶段,有过多卷积层的无效堆叠。这造成了三个现象:特征提取并不充分和目标检测器的泛化能力差。为此,我们将Transformer模型引入backbone。并且与注意力机制相结合。这样,我们的目标检测器就可以得到不同的数据表示并时刻聚焦在我们感兴趣的区域。
在neck阶段,没有对特征进行有效融合,采用无效的卷积操作。直接导致了目标检测器效果差、训练时间长和实时性低下的问题。在深度学习的目标检测算法中,为了提高算法的性能,在neck阶段主要做的工作是融合不同尺度的特征。低层特征的分辨率更高,包含更多的位置和细节信息,但语义性更低、噪声更多。高层特征的分辨率更低,对细节的感知能力较差,但其包含更多的语义特征。为了将两者做一个有效的融合,很多人做了大量的工作。针对这些问题,本文将backbone提取的所有的特征层都引入到neck,在融合阶段加入注意力机制,去除了在neck阶段的多余卷积操作。
在backbone部分。其改进主要如下:①在SPP之后引入Transformer模型和SE注意力机制;②采用C3特征提取模型和注意力机制交叉结合的方式。
在head部分。其改进主要如下:①将C3TR Transformer模型替代Yolo-v5中的C3特征提取模型,将backbone提取的所有特征层都接入neck。②在concat阶段,采用和注意力机制结合的方式。
3 开源路面数据集
这项研究使用的是2020年IEEE大数据国际会议大数据杯组织的全球道路损伤检测挑战赛(GRDDC)的数据集,该数据集是从印度、日本和捷克共和国收集的26336个道路图像。包括三个部分:Train,Test1,Test2。Testl和 Test2 包括2631和2664张图像,约50%的图像来自日本,37%来自印度,约13%来自捷克共和国。Train则包括带有PASCAL VOC格式XML文件标注的道路图像,包含来自日本的10506张图像,来自捷克共和国的2829张图像和来自印度的7706张图像,如表1所示。所有路面裂缝分为纵向裂缝、横向裂缝、鳄鱼裂缝和坑洼裂缝,如图1所示。每个损坏类型都用类名(如D0)表示。从表2可以看出,损害类型分为七类。

表2 损伤类型统计
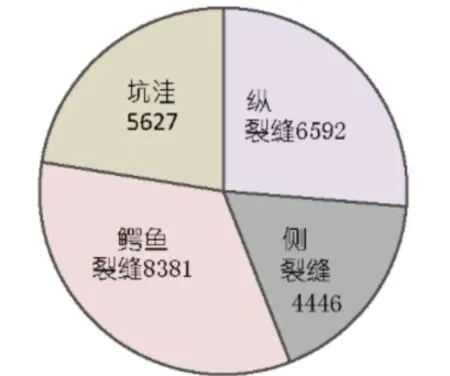
图1 训练数据中不同损伤类型实例的分布
4 实验结果与分析
文中算法是在Pytorch深度学习框架上实现的,实验使用的配置NVIDIA TITAN RTX GPU、16 G内存、操作系统为Ubuntu20.04的硬件平台上训练与检测。模型训练策略如表3所示。

表3 检测模型训练策略
文中通过计算一张图片耗时、帧率、准确度与平均精度进行模型性能评估。
为了加快训练速度,提高检测精度,采用了SE注意力机制和Transformer模型,在计算机视觉和深度学习领域,注意力机制被广泛用于学习技术。本研究使用在ImageNet上预先训练的yolo权值作为道路损伤检测任务的初始化权值。由于训练数据集由三个不同国家的图像组成,路面和开裂纹理之间存在一定的差异。虽然日本和捷克共和国的图像有一些相似之处,但它们与印度的路面图像仍有很大差距。因此,很明显,在一个综合的三国数据集上训练的单一模型会产生较差的检测和表征结果。因此,考虑到这一点,本研究训练了一个模型仅检测日本和捷克共和国的路面损害,而另一个模型则训练检测印度的路面病害。在NVIDIA TITAN RTX GPU上运行时,提出的模型实现了大约每秒65帧的推理速度。类似地,一个针对日本和捷克共和国数据集提出的模型经过54个epoch训练的模型大约为381兆字节。经过66个epoch训练的模型平均约为729兆字节。在这里,总训练时间大约是15小时。为了了解基于YOLO模型的性能,网络以恒定的学习率、权重和动量训练了300个epoch。从实验结果可以看出,在50-70个epoch训练的模型性能要优于150-300个epoch训练的模型。
为了验证文中提出模型的性能,将改进算法与YOLOv5进行性能测试对比,结果见表3和表4。通过对表格数据的分析可以发现改进之后的算法在均值平均精度(mAP)和检测耗时上都较YOLOv3有了不同程度的提升,这反映出了文中算法改进的有效性。

表4 改进算法与YOLOv5模型检测准确率对比
5 结语
本研究提出了一种路面自动化处理方法使用深度学习的遇险检测和表征。研究表明,模型在检测鳄鱼裂缝和横向裂缝检测困难。特别是,从印度获得的数据库非常少可以看到横向裂缝的实例。这引起了一些错误的分类来自印度的图像,并导致了一个与纵向裂缝混淆。此外,从印度和捷克共和国的数据显示,道路损伤等级似乎有些不平衡。不管怎样,来自日本的数据集帮助模型实现了非常准确的检测。本文在道路病害图像检测的实际问题的启发下,针对基于深度学习的目标检测算法在道路图像具有的复杂背景和目标难以分辨的特点下难以充分提取特征和有效进行特征融合的问题。在YOLOv5的基础上,引入了C3TR Transformer模型和注意力机制。经实验表明,该模型能更充分的提取特征与更有效地进行特征融合,提高了检测性能。并且在检测精度方面也优于现有的目标检测方法。其中,由于第一次将Transformer模型引入目标检测算法,有着很好的效果。因此,今后的研究方向可能更关注Transformer模型在目标检测领域的应用。
猜你喜欢
农业工程学报(2022年10期)2022-08-22
今日农业(2022年3期)2022-06-05
当代水产(2022年2期)2022-04-26
当代陕西(2022年4期)2022-04-19
房地产导刊(2022年4期)2022-04-19
小猕猴学习画刊(2022年3期)2022-03-28
金桥(2019年10期)2019-08-13
初中生世界·九年级(2018年12期)2018-12-22
读写算·高年级(2015年1期)2015-07-25
读者(2015年9期)2015-05-04
