
Ceph云存储中基于强化学习的QoS优化
2021-02-25 05:51:22李新鹏
计算机工程与设计 2021年2期
李新鹏,王 勇,叶 苗
(1.桂林电子科技大学 计算机与信息安全学院,广西 桂林 541004;2.桂林电子科技大学 广西云计算与复杂系统高校重点实验室,广西 桂林 541004;3.桂林电子科技大学 信息与通信学院,广西 桂林 541004)
0 引 言
随着全球数据总量的迅速增长[1],人类已经进入大数据时代,为了可靠的存储这些海量数据,云存储应运而生,其专注于解决海量数据的存储和处理,且随着云存储的广泛应用,如何提高云存储系统的服务质量QoS(quality of service)性能已成为一个研究热点[2,3]。
在设计一个云存储系统时,面临的首要问题就是如何将海量的数据分布在不同的存储节点上,且尽可能分布均衡,解决这个问题的关键就是要设计一个好的数据分布策略,其对云存储系统的QoS性能起着至关重要的作用。以一个具体的云存储系统为基础展开研究,Ceph作为最近几年热门研究的云存储系统,不仅具有高扩展性、高性能和高可靠性的特点,而且实现了集群真正意义上的无中心节点。但是,Ceph的数据分布算法CRUSH(controlled replication under scalable hashing)存在数据在设备空间上分布的不均衡问题,从而影响分布式存储系统的读写QoS性能。针对此问题,从算法的数据分布过程着手进行研究、实验,得出放置组PG(placement group)在存储节点OSD(object storage daemon)间分布不够均衡,会造成用户数据在各存储设备上分布不均衡。在此基础上,首先将PG在OSD上分布不均衡问题建模为分布的PG数量标准差的优化问题;然后利用强化学习与环境不断交互、反馈、自动决策及优化目标的能力,建立强化学习模型,训练调整PG在分布过程中的OSD权重,从而在不改变原有CRUSH算法逻辑的基础上,使得数据在各设备上分布更加均衡,提高分布式存储系统的资源利用率和QoS性能。
1 相关工作
如何提高云存储系统的QoS性能已成为一个研究热点。研究者从各个方面尝试提高存储系统的QoS性能,方法包括:使用多副本与纠删码方法提高系统的可靠性[4,5];使用网络编码与数据索引方法降低系统的开销[6,7];以及使用数据分布与数据迁移方法提高分布式存储系统负载的均衡性[8,9]。以下从数据分布的角度来介绍其是如何影响存储系统的QoS性能,以及对当前的研究现状、问题和改进方案展开描述。
分布式云存储系统都有自己的数据分布算法, Niu SQ、Wu WG、Zhang XJ等在哈希算法的基础上提出一种跳跃Hash算法[10],利用二维矩阵来定位目标存储节点,但是该算法通用性比较受限,在集群中节点失效的情况下,容易造成集群中同一行内的其它节点负载过重,使集群负载不均衡。针对Ceph数分布算法CRUSH伪随机性导致的数据分布不均衡问题,贺昱洁由CRUSH算法改进提出了一种B-CRUSH算法,该算法通过设计新的哈希算法、新的Bucket类型并设计一种自适应模型来优化数据分布不均衡的问题[11],但是该算法对原有算法的逻辑改动较大,破坏了原有算法在集群扩容时数据迁移量小的优点。穆彦良等提出一种Ceph存储中基于温度因子的CRUSH算法改进方案[12],所提的算法通过计算用户写请求访问集群中某个节点的频率,动态增加该节点的温度因子,利用温度因子对原始CRUSH算法进行加权计算,得出更适合的存储节点,但该算法的实验数据不足以说明对多副本数据的分布具有同样的效果。Ceph的新版本Luminous针对数据分布算法CRUSH存在的PG分布不够均匀的问题,在集群上线之前,利用新增的balancer模块对PG分布进行优化,但优化效果有限且需要手工配置参数。
针对Ceph中数据分布算法CRUSH在数据分布均衡性方面的不足,在深入研究CRUSH算法的基础上,结合强化学习提出RL-CRUSH算法,该算法尝试通过利用强化学习与环境不断交互、反馈、自动决策及优化目标的能力,改进原有CRUSH算法PG在OSD上的分布不均衡问题。
2 问题描述
在Ceph云存储中,对象是数据存储的基本单元。数据存储的过程主要是通过两次映射完成:首先客户端按要求将用户文件切分成一个个固定大小的对象,然后在对象之上添加一个逻辑层PG,对象都会被唯一映射到一个PG中,最后通过CRUSH算法按照设置好的副本规则把每一个PG映射到一组OSD节点中。分析上述过程可知,造成用户数据在各个设备节点上分布不均衡的原因可能有两方面:一方面是对象的数量在各PG中分布不均衡,另一方面是PG数量在各个OSD节点上分布不均衡。已有文献说明对象可以被均衡地映射到各PG中,下面将通过实验分析验证PG数量在各个OSD间分布不均衡是造成集群中数据分布不均衡的原因,从而导致系统瓶颈的产生,影响集群整体QoS性能,本节将通过实验验证数据分布不均衡对集群性能和磁盘利用率的影响。搭建如图1所示的Ceph集群拓扑结构。
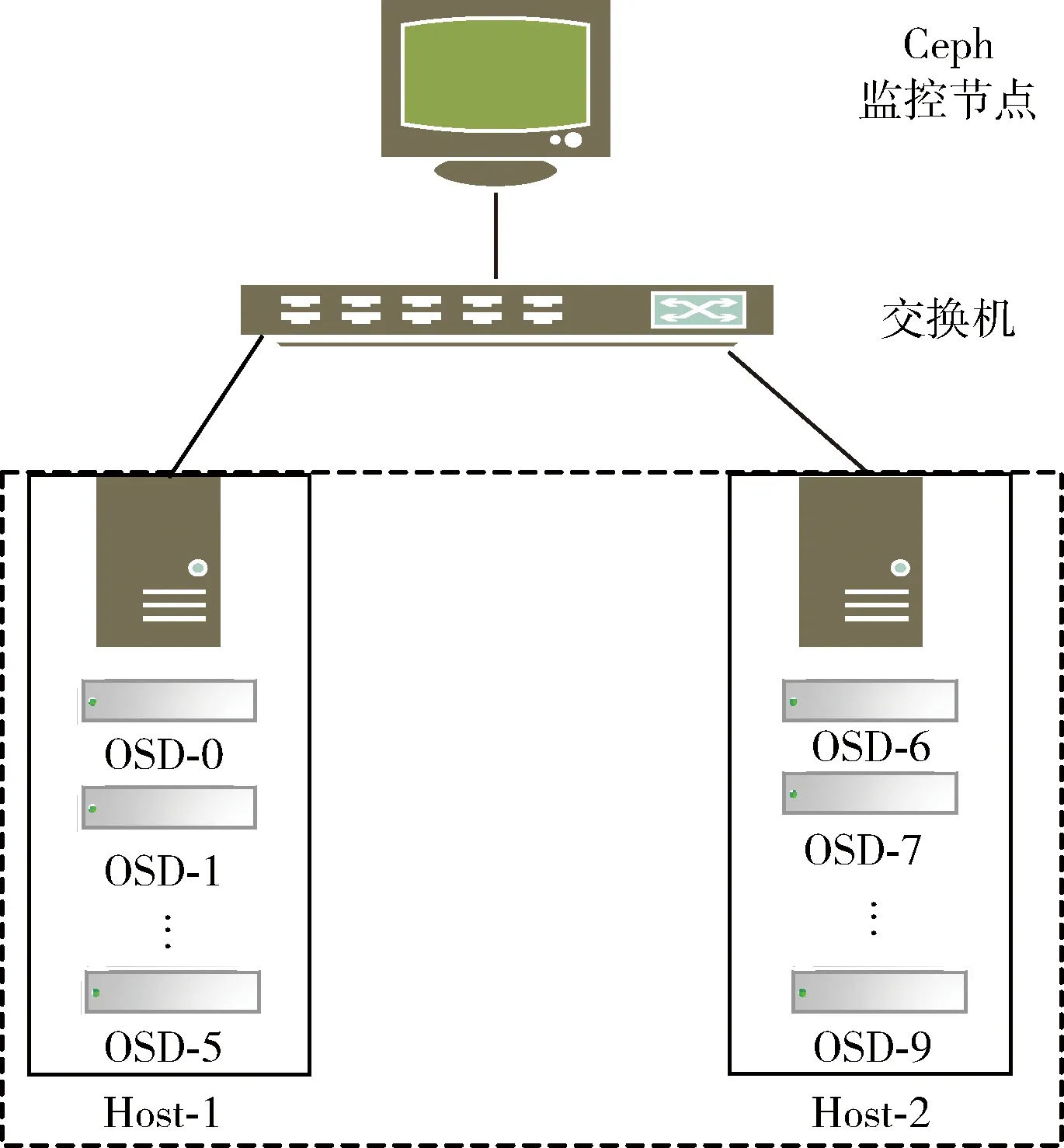
图1 Ceph集群拓扑结构
在上述搭建的Ceph集群中,利用FIO对Ceph云存储系统进行小、大规模的读写性能测试。在小规模场景下,对5000个大小均为10 MB的对象进行随机读操作,此时,集群的吞吐率可以达到节点间最大网卡带宽;在大规模场景下(其它测试参数与小规模测试保持一致),对9000个大小均为10 MB的对象进行随机读操作,此时,与小规模场景下相比,集群的吞吐率下降了25%,如图2所示。

图2 小、大规模随机读性能的测试
另外,统计上述测试过程中各个OSD上的PG数量和磁盘使用率的关系,横坐标表示OSD设备节点编号,第一纵坐标表示PG数量,第二纵坐标表示OSD节点磁盘使用率。结果如图3所示。

图3 OSD上的PG数目与数据量的正比关系
分析图3可知,首先可以看出各个OSD上的PG数量分布很不均匀。例如,OSD4上的PG数目最多有119个,使用率为94.04%;而OSD2上的PG数目最少,只有88个,使用率为70.54%。根据Ceph官方文档所推荐的经验式(1)所示
(1)
可以计算出上述搭建的Ceph集群的PG总数量应设置为10*100/2=500,考虑到PG数目最好为2的整数次幂,故取值512。可以计算出,每个OSD节点经过CRUSH算法分配后的平均PG总数量应为512*2/10=102.4,从图3中分析可知,与每个OSD的平均PG数量相比,平均值的变化范围从-15%到18%,PG分布的标准差为8.85,可以看出,PG在OSD节点分布很不均匀。其次,图3中的两条折线基本重合,这表明OSD节点上的PG总数量和节点使用率两者之间有直接关联,基本成正比关系。因此可以将数据在集群中的分布不均衡问题转化为PG在各OSD节点间的分布不均衡问题,也就是说,各个OSD节点间PG数量分布不均衡直接导致了用户数据在各设备上分布不均衡。
为了进一步探究在进行大规模随机读测试时,集群吞吐量下降的原因,统计了PG数量最多的OSD4和PG数量最少的OSD2节点在测试期间的利用率,如图4所示。
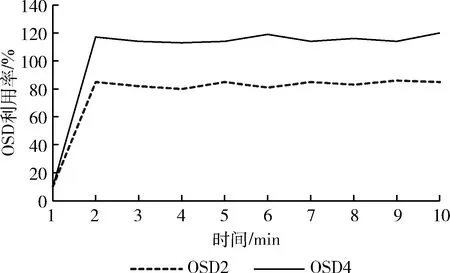
图4 OSD的利用率对比
分析图4可知,在大规模随即读测试的场景下,PG数量最多的OSD4节点的利用率一直处于超负荷状态,说明该OSD负载过重,达到了瓶颈;而PG数量最少的OSD2节点的利用率一直处于较低的水平,说明该OSD节点未得到充分利用。可以看出,集群在读写过程中,数据量较多的OSD节点必然将承受过重的负载,很容易成为系统性能瓶;而另一方面对数据量少的OSD节点,又是一种资源的浪费,降低系统的QoS性能。
综合上述实验分析以及Ceph的存储过程,可以得出PG数量在各个OSD间分布不均衡是造成集群中数据分布不均衡的原因,从而导致磁盘使用率不均衡、系统瓶颈的产生和降低集群吞吐量。
3 RL-CRUSH:基于Q-learning的数据分布算法
一个优秀的数据分布算法应当考虑的因素包括:时间复杂度、数据分布均衡性和数据迁移量。时间复杂度方面,在集群上线之前,通过CRUSH算法将PG分布在各个OSD上,此时,PG和OSD的映射关系就确定下来,只有在添加、删除OSD节点的情况下,才需要重新计算PG在OSD上的映射,因此服务端对时间要求不严格,并且这种模式不会影响到客户端访问Ceph集群时计算OSD的过程,这就为使用强化学习来改进CRUSH算法奠定了基础。数据迁移量方面,Ceph提供了多种选择一个item的算法,这些算法统称bucket算法,CRUSH默认使用的bucket算法为straw,straw算法可以做到新增和删除OSD时,只有少量PG产生迁移,从而保证了数据迁移量较小。因此,在Ceph集群上线之初时,使用下面提出的RL-CRUSH算法通过利用强化学习与环境不断交互、反馈、自动决策及优化目标的能力,改进原有CRUSH算法PG在OSD上的分布不均衡问题,并保留了原有CRUSH算法数据迁移量小的优势。
3.1 模型建立
基于Q-learning的数据分布算法的模型建立包括两部分:首先将PG数量在各个OSD间分布不均衡的问题规划为标准差的优化问题;然后将标准差优化问题转化为可以使用Q-learning算法解决的RL问题。
首先介绍第一个问题,将PG数量在各个OSD间分布不均衡的问题规划为求较小标准差的问题。假设Ceph集群中共有:m个OSD存储节点表示为:OSD_Number=(OSD0,OSD1,…,OSDm-1),n个PG表示为:PG_Number=(PG0,PG1,…,PGn-1),每个OSD节点最大的不同就是它们的容量,根据容量大小每个OSD有各自的权重,m个OSD的权重集合表示为:Weight=(W0,W1,…,Wm-1)。
CRUSH算法要解决的目标就是如何将n个PG映射到有各自权重的OSD上,为了便于理解后续问题的建模,这里简单介绍一下CRUSH算法的流程。当集群中有了上述m个OSD、n个PG和m个OSD的权重集合,使用CRUSH算法为每一个PG选择一组OSD的过程如下:
第一步:给定一个PGi,作为CRUSH_HASH的输入,CRUSH_HASH(PGi,OSDir)得出一个随机数。第二步:对于所有的OSD用它们各自的权重乘以OSDi对应的随机数,得到乘积。第三步:选出乘积最大的OSD节点,这个PG就会保存到这个OSD上。
在计算第i个PG的OSD映射位置时,当前每个OSD中的PG数量分别为
(2)
(3)

CRUSH_PG_Number=(t0,t1,…tm-1)
(4)
下面介绍第二个问题,将标准差优化问题转化为可以使用Q-learning算法解决的RL问题。
3.2 基于强化学习Q-learning的RL-CRUSH算法
Ceph集群中的bucket类型均指定为默认的straw类型,CRUSH默认使用的straw算法流程如下,首先给定一个PGi作为CRUSH_HASH的输入,利用crush_hash32_rjenkins(PGi,OSDi,r)函数进行哈希得到一个随机数;然后,对于所有的OSD,用每个OSD的随机数乘以其对应的权重,得到乘积并进行比较,选出乘积最大的OSD,最终得出PGi映射到该OSD上,上述两个过程均会导致PG在OSD上的分布不均衡。接着依据3.1的标准差问题模型设计Q-learning算法,从而改进CRUSH算法的PG在OSD上的分布不均衡问题,命名改进的算法为RL-CRUSH。结合上述所提的PG数量在各个OSD间分布均衡问题,设计Q-learning算法模型的状态空间、动作集合和收益函数,可分别将其定义如下。

定义2 动作集合A。考虑到要在上述权重列表的基础上,并结合CRUSH算法计算OSD的过程中要利用RL动态调整各个OSD的权重值,设计如下两组动作集合
left,right分别表示状态s向左、右移动;left_up,left_down,right_up,right_down分别表示状态s向左、右移动后选择的OSD节点的权重值向上、下按照步长调整权重。

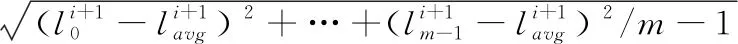
(5)
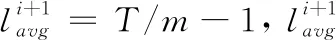

图5 RL-CRUSH算法流程
RL-CRUSH算法中Q值函数是状态和行为的评价值,计算公式为
Q(st,at)=R(st,at)+gmax{(st+1,at+1)}
(6)
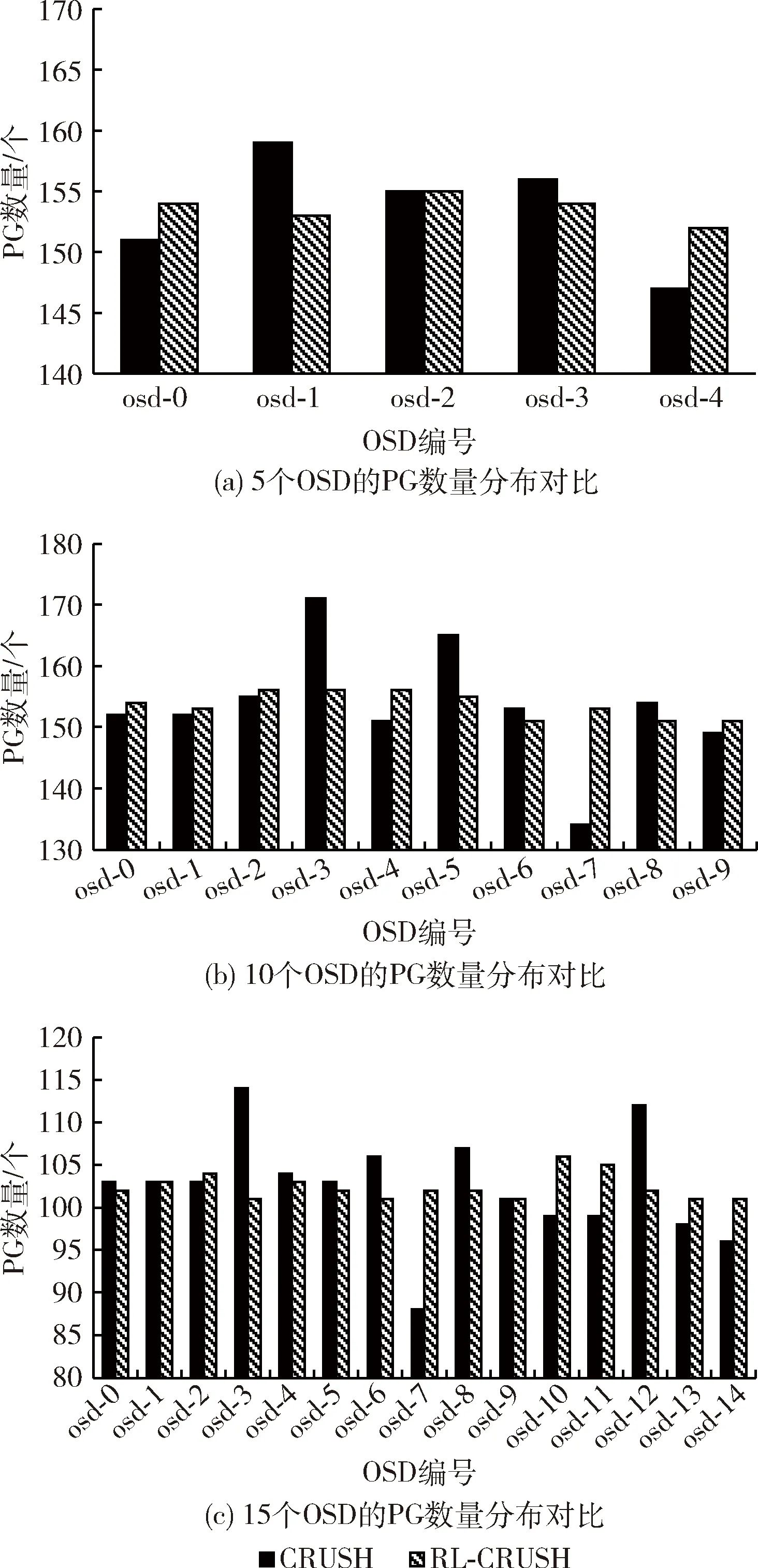
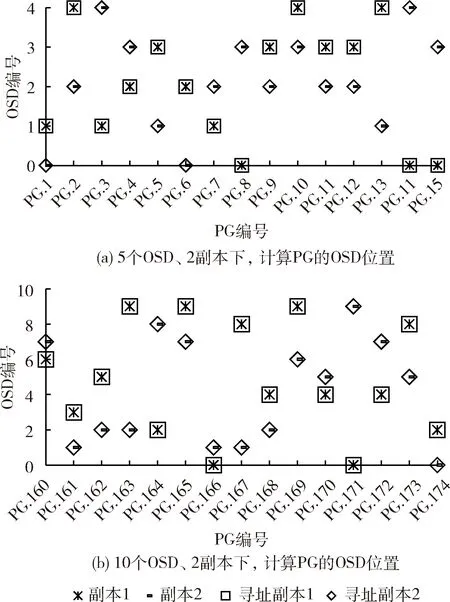
其中,st和at表示时刻t的下一个状态和行为,衰减因子g是满足0 Qt+1(st,at)=(1-g)Qt(st,at)+g[R(st,at)+gmaxQ(st+1,at+1)] (7) 有了Q值就可以进行学习,然后根据Q值来选取能够获得最大收益的动作。 为全面评估提出的基于Q-learning的RL-CRUSH算法的有效性,以下将从3个方面进行详细的仿真实验。 (1)在不同规模OSD的情况下,分别对比RL-CRUSH算法及CURSH算法的PG数量分布、PG数量标准差。 (2)在不同规模OSD的情况下,分别对比RL-CRUSH算法及CURSH算法的PG分布训练时间、PG计算时间。 (3)在双副本、不同规模OSD的情况下,模拟客户端读取过程中,计算PG在OSD上的映射位置,验证同一个PG映射的OSD集合是否固定。 为了验证本文设计的数据分布方法的性能和效果,在配置为Windows 10 64位操作系统的Intel Core i3-2330M @2.20 GHz、8 GB内存的PC机上进行仿真实验。使用Python 语言编写算法RL-CRUSH及CRUSH算法中PG到OSD映射机制的功能,并利用PyCharm工具运行算法及对实验结果进行收集、分析。 4.2.1 不同规模OSD,PG数量及PG数量标准差对比 图6是在3副本的场景下,执行CRUSH算法、RL-CRUSH算法分别计算5、10、15个OSD上的PG分布,图6(a)、图6(b)、图6(c)每个OSD上的平均PG数量分别应该为153.6、153.6和102.4。可以看出CRUSH算法PG在各个OSD上的分布很不均匀,图6(a)、图6(b)、图6(c)各OSD上的PG数目相对平均值的变化范围分别为:-6.6%到5.4%、-19.6%到17.4%、-14.4%到11.6%,PG分布的标准差分别为4.17、9.23、6.1;分析RL-CRUSH算法的PG分布结果,从图6(a)、图6(b)、图6(c)计算可得各OSD上的PG数目相对平均值的变化范围分别为:-1.4%到1.6%、-2.6%到2.4%、-1.4%到3.6%,PG分布的标准差分别为1.02、2、1.5。 图6 不同规模OSD的PG数量分布对比 4.2.2 不同规模OSD,PG分布时间及计算时间对比 表1是在3副本、不同数量的OSD的场景下,分别执行CRUSH算法、RL-CRUSH算法时,PG在OSD上的分布训练时间以及客户端读取Ceph集群时,计算PG在OSD节点映射位置的平均时间。CRUSH算法没有训练过程,这里只统计RL-CRUSH算法的分布训练时间。从表中可以得出相比CRUSH算法,提出的RL-CRUSH算法由于PG在OSD分布过程中加入了强化学习训练的过程,导致PG在OSD上分布的训练时间较长。PG在OSD节点的分布时间和均匀性,后者对Ceph集群使用的作用更为重要。原因有两点:第一,PG在OSD上的分布操作,是在创建Ceph集群时一次性完成的,此时,集群中还没有存储对象,对PG分布进行优化收益最大,且对创建集群时间要求不严格(借鉴Ceph的新版本Luminous新增的balancer模块对PG分布进行优化);第二,当客户端读取Ceph集群时,RL-CRUSH算法收敛后,保存最佳OSD权重值,从而不影响计算PG在OSD节点映射位置的时间,从表中可以看出这一点,CRUSH算法和提出的算法读取时计算一个PG映射位置的平均时间都是0.9 ms。 表1 OSD上的PG分布训练时间、计算时间比较 4.2.3 不同规模OSD,计算PG的OSD映射位置 图7(a)、图7(b)是在2副本的场景下,模拟客户端读取Ceph集群时,RL-CRUSH算法计算PG在OSD上映射位置的过程。分别在5个OSD、10个OSD的情况下,随机选取10个PG进行计算OSD映射位置的寻址操作,例如,图7(a)中,副本1和副本2的散点分别表示PG.6的第一、第二个副本存在OSD.0、OSD.2;寻址副本1和寻址副本2的散点分别表示客户端访问Ceph集群时,计算PG.6两个副本的映射位置为OSD.0、OSD.2。从图7中可以看出经过RL-CRUSH算法分布到各个OSD上的PG,在客户端进行访问操作时,都可以准确计算出PG在OSD上的映射位置,验证了RL-CRUSH算法的有效性。 图7 不同规模OSD、2副本下,计算PG的OSD位置 针对CRUSH算法存在PG映射到OSD分布不均匀的问题,利用强化学习改进CRUSH算法,提出RL-CRUSH算法来优化PG分布不均匀的问题。该算法首先将PG数量在各个OSD间分布不均衡的问题规划为PG数量标准差的优化问题,建立问题模型;然后依据问题建立强化学习模型,包括状态空间、动作空间和奖励函数的设计;最后依据上述设计的RL模型,使用Q-learning算法来解决问题。通过实验与结果分析可知,提出的RL-CRUSH算法在不影响客户端访问Ceph集群时,计算PG到OSD映射时间的前提下,较好解决了PG分布不均匀的问题,使得PG可以近似均匀的分配到各个OSD上,消除了数据分布不均衡带来的系统瓶颈,提高OSD磁盘使用率和云存储负载均衡QoS性能。4 实验设计与结果分析
4.1 实验环境
4.2 实验设计与结果分析

5 结束语
猜你喜欢
数码设计(2020年16期)2020-12-08 02:12:05
哈尔滨轴承(2020年2期)2020-11-06 09:22:36
计算机系统应用(2019年2期)2019-04-10 05:08:46
发明与创新·大科技(2019年12期)2019-03-17 09:23:31
计算机与生活(2016年11期)2016-11-22 02:07:32
电子技术与软件工程(2016年8期)2016-07-10 08:07:53
中兴通讯技术(2016年2期)2016-03-24 00:14:53
中国教育信息化(2015年12期)2015-08-24 07:58:36
电测与仪表(2015年10期)2015-04-09 11:48:20
计算机工程与科学(2015年3期)2015-03-27 07:46:15
