
基于时序卷积网络的词级语言模型研究与应用
2021-02-25 05:51:16李大舟于广宝孟智慧
计算机工程与设计 2021年2期
李大舟,于广宝+,高 巍,孟智慧
(1.沈阳化工大学 计算机科学与技术学院,辽宁 沈阳 110142;2.中国移动集团设计院有限公司河北分公司 山西综合生产所,山西 太原 030000)
0 引 言
语言模型发展一共经历3个阶段,在第一个阶段的统计语言模型中最具特点的是N-gram模型[1]。该模型有结构简单、时间复杂度低等特点,但也有语言表达能力弱、维度灾难和模型泛化能力弱的缺点。第二个阶段是前馈神经网络语言模型,该模型能更好使词被计算机识别和利用,从而提升接受输入的长度,但该模型的训练复杂度高,需要使用特定的语料库和词表,并有一定的局限性。第三个阶段是深度神经网络,其代表是循环递归神经网络,该网络在语言模型一定的优势,但也存在一定的弊端,如梯度爆炸、梯度消失、训练速度没有前馈神经网络快、需要的硬件要求也更高。
根据之前研究的不足之处,本文提出了时序卷积神经网络,该网络的结构特点是可以保证输入序列和输出序列相同。这样就可以解决传统循环递归网络结构中的输入序列和输出序列不一致的情况。另一方面本文通过使用扩大卷积层,可以保存更多的文本信息,解决了传统卷积神经网络因输入序列过长导致文本信息的丢失,使预测的准确率的降低的问题。
1 相关研究
近年来,随着语言模型的飞速发展,国内外相继出现了很多的研究成果,关于语言模型的发展历史,先是从传统的统计型语言模型(n-gram模型)发展到神经网络语言模型(NNLM),随后向循环神经网络语言(RNN)的方向进步,由Bengio等提出了前馈神经网络[2]语言模型,实验结果表明该模型比传统的统计型语言模型(n-gram模型)优秀。之后,由Bengio等将神经网络技术应用在高维离散数据的联合概率分布[3]建模,用于解决维度灾难的问题。随着科学技术的进步,基于深度神经网络的技术也被广泛的应用到语言模型中,Mikolov等[4]提出利用循环神经构建语言模型,将其历史信息(即上一个隐含层的状态)也作为输入,利用好更多的上下文信息进行预测,使语言建模的能力有了很大的提升。Sundermeyer等[5]实现了基于LSTM网络[6]构建语言模型。该模型通过网络的门结构可以更好选择需要保留的上下文信息,在LSTM网络架构中,词向量非常重要,词向量可以表示语言的深层信息,词向量可以解决传统one-hot表示带来的维度灾难和词汇问题[7]。能够有效地对单词之间的语义信息进行计算。Le等在词向量的基础上尝试构建句子和短语的向量表示,用来克服词袋模型的缺点,以及提高信息检索的能力。
2 时序卷积网络
语言模型的一个难点在于如果输入的序列过长,导致网络会丢失之前的语义信息。本文提出利用扩大卷积方法来解决这个问题。扩大卷积会增加更大的感受视野,从而保留更多的语义信息,另一个难点是输入序列和输出序列的长度不一致,导致计算的难度增加。
为了解决上述问题,本文提出了一种卷积网络称为时序卷积网络,它有两大特点:①输入序列和输出序列保持一致;②预测时不会使用未来的信息而只会使用历史的信息。为了保证输入序列和输出序列相同,在全卷积的时候输入层和隐含层相同,并且使用0填充来保证使后续层与先前的层保持相同的长度。为了保证预测时不使用未来的信息,使用因果卷积。为了得到一个较长的历史信息,本文需要一个非常深的网络或者非常大的卷积核,本文使用扩大卷积。为了防止模型过拟合,使用Relu激活函数和Dropout。所以本文提出的结构是由扩大卷积层、因果卷积层、RELU层和Dropout层组成,如图1所示。
2.1 因果卷积
因为要处理时序问题,即要考虑时间问题,因果卷积可以考虑时间的问题,对于序列问题,可以把问题抽象成x1…xt和y1…yt-1去预测yt。这里的x1…xt为时刻1至t的输入序列,yt为t时刻的输出。y1…yt-1为中间输出结果,但yt包含之前的所有输入信息及中间输出结果的信息。例如,输入为“I am a good boy”,x1为“I”,x2为“am”,输入因果卷积中,假设输出J1为“B”,x2和x3作为输入,进入网络后,假设J2输出为“C”,依次类推,输出J3和J4,接来下,J1和J2作为输入,J2和J3也作为输入,J3和J4也作为输入,输出K1、K2和K3,直到最后的输出结果为“OK”,这个“OK”就包含了之前的x1…x5的所有信息,这就是因果卷积的作用。
如图2所示。因果卷积总结公式为,设因果卷积函数为F(x),即因果公式如式(1)
y0,…,yt=F(x0,…,xt)
(1)
2.2 扩大卷积
如上文提到,因果卷积包含的输入信息很有限,为了得到更长的输入信息保证预测的准确性,因果卷积需要非常多的层级数来保证它具有更大的感受野或使用较大的卷积核来扩大感受野,而较大的感受野是保证更多的输入信息的输入。若不想用增加计算量的办法,使用扩大卷积可以解决这个问题。扩大卷积最大的特点就是扩大感受野。扩大卷积通过控制扩大因子来增加感受野。在一维的扩大卷积中,扩大因子相当于将卷积核变大,如图3所示。总结扩大卷积的公式如式(2)
(2)
其中,d为扩大因子、k为卷积核的大小,s-d·i计算了采用上层的某个单元。扩大因子控制了每两个卷积核间会插入多少零值,当d=1时,扩大卷积就会变为一般的卷积运算。一般在使用扩大卷积时,我们将随着网络深度i的增加而指数级地增大d,如式(3)
d=O(2^i)
(3)
当扩大因子为1时,扩大卷积就退化为因果卷积,感受野为2,当扩大因子为2时,扩大卷积的卷积核变为4,即感受野为4,当扩大因子为4时,扩大卷积的卷积核为8,即感受野为8,依次类推,最终输出包含所有输入信息。通过控制扩大因子,增加卷积核的大小从而达到增加感受野的目的。

图2 因果卷积作用
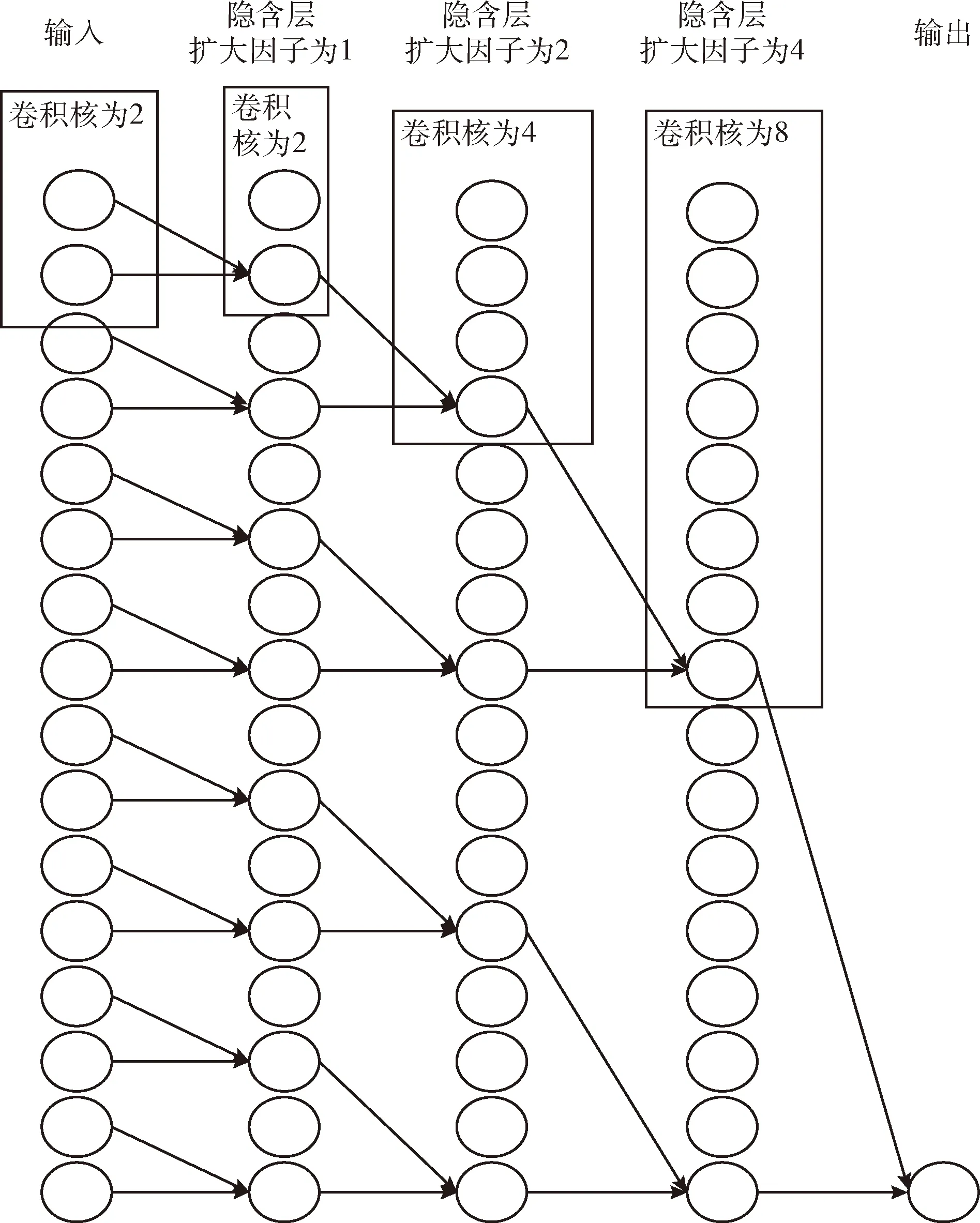
图3 扩大卷积效果
2.3 ReLu函数
ReLu是神经网络中的一个常用的激活函数,使用ReLu的原因:第一,传统的sigmoid等函数,参数反向传播求误差的梯度时,求导复杂,会加大计算量,若采用Relu激活函数,在整个过程中会节省很多的计算量和计算时间。第二,在深层的网络中,传统的sigmoid函数参数反向传播时,梯度消失或梯度爆炸的情况就会很容易出现,以至于深层网络的训练无法完成。第三,使用ReLu函数迫使部分神经元的输出为0,使网络变得稀疏,而且使参数之间减少了相互依赖,使过拟合的问题得到了缓解。第四,Relu函数更易学习优化,因为是分段线性的属性,使求导更加容易,而传统的sigmoid函数,由于两端是饱和的,在传播过程中容易丢弃语义信息。所以本文选择了Relu函数作为激活函数。Relu函数公式如式(4)
y=max(0,x)
(4)
2.4 Dropout层
在大规模的神经网络中有这样两个缺点:①太费时;②容易过拟合。而Dropout层可以解决这个两个问题,Dropout是在模型的训练中随机丢失一些隐藏单元,使其剩下的隐藏单元继续工作,这样使网络更简单,削弱了隐藏单元之间的依赖性。Dropout的功能是防止所有的特征提取器共同作用,一直放大或者缩小某些特征,若样本小,则容易出现过拟合和泛化能力弱的现象,使用了Dropout能避免训练过程中出现的这些问题,增加了网络的泛化的能力。对于Dropout率的选择,经过本文验证,隐含点Dropout率等于0.45的时候效果最好,复杂度最低。所以本文选择Dropout层用于优化网络。选取结果见表 1。

表1 Dropout选取对比
3 语言建模与实验结果分析
3.1 数据集
本文使用PennTreeBank(PTB)数据集进行词级语言建模,该数据包含3个文件,分别是测试集数据文件、训练集数据文件和验证集数据文件,这3个数据集包已经经过预处理,相邻的单词之间用空格隔开,数据集含了9998个不同的单词词汇,加上稀有词语的特殊符号和语句结束符在内,一共是10 000个词汇。做词级语言语料库时,包含888 K单词用于训练,70 K单词用于验证,79 K单词用于测试,这是一个经过高度研究但相对较小的语言建模数据集。如图4所示。

图4 PennTreeBank数据集的部分显示
3.2 建模过程
3.2.1 数据准备
为了将文本转化为模型可以读入的单词序列,需要将这10 000个单词分别映射到0-9999之间的编号。按照词频顺序为每次词汇分配一个编码,将词汇表保存到一个独立的vocabary的文件中(前6个单词与ID)ID和单词对应见表2。

表2 ptb.vocabary
在确定词汇表后,将训练文件、测试文件等根据词汇文件转化为单词编号,每个单词标号就是它在词汇文件中的行号,单词编码见表3。

表3 根据词汇文件转化为单词编码
当单词编码完成后,将数据集中的文本分割成序列,最大长度为50,分成16批,为随机度下降的需要,需要把数据整理成一系列小的批次,每次为一个批次的数据来更新权重。让数据进行批处理,这样既可以节约时间又加快运算速度。
3.2.2 创建模型
为了使用之前的单词来预测接下来的单词,本文将使用时序卷积网络,该网络的结构是由一个扩大卷积、一个因果卷积、一个ReLu和一个Dropout的基本结构组成,4个基本结构组成一个卷积网络的基本单位,而该网络是由4层基本单位组成,这样下来时序卷积网络组装完成,接下来将一个批量的数据(10 000维)送入编码器成为一个批量的词嵌入向量(600维)编码器的作用是对数据降维,通常将文本信息转化为向量编码使用one-hot编码,然而这样做的结果会造成维度灾难,也无法表示语义的相似性,将数据送入编码中,编码器中的隐藏神经元设为600,可以使数据由1 0 000维降成600维,形成词向量。然后再将词向量输入时序卷积网络中(其中扩大卷积和因果卷积的隐藏单元为600,卷积核大小为3),输出为一个词向量(600维),再将词向量送入解码器中,输出为10 000维的数据,解码为单词(其中编码器和解码器的权重和隐藏单元是相同的),编译模型。到现在为止,整个模型已经创建完成。模型如图5所示。
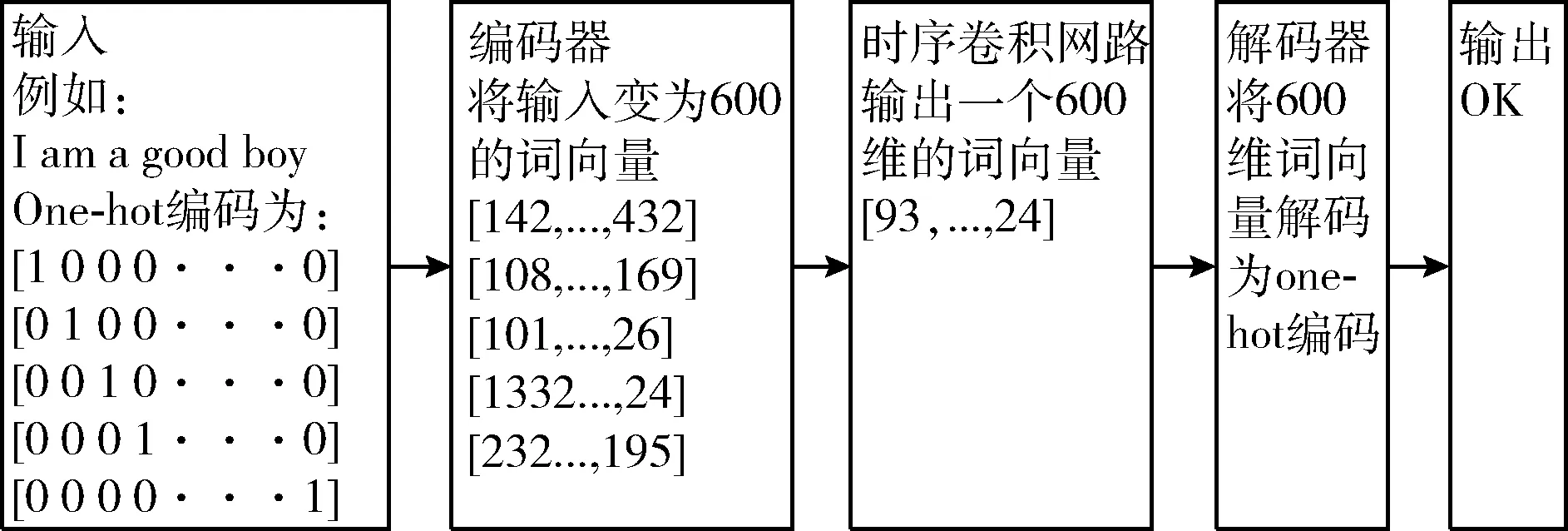
图5 语言模型结构
3.2.3 训练模型
训练模型,本文使用batch(大小为16)进行分批训练,使训练的速度加快。在训练时,先让模型可以按批次读取数据,将数据编码,随后送入网络中,在网络中执Dropout,随机从句子中舍弃词,迫使模型不依赖于单个单词完成任务,选择损失函数(交叉熵)和优化器(SGD),网络使用梯度下降来更新权重,使得模型的预测更加准确。最后将得到的模型应用于测试集,检验模型的优劣。
3.2.4 评估指标
本文选择的评估指标是语言模型通常选用的评价标准,即复杂度,复杂度是衡量一个语言模型的好坏,复杂度可以认为是平均分支系数,即预测下一个词时可以有多少种选择,若模型的PPL下降到90,可以直观地理解为,在模型生成下一个词时有90个合理选择,可选词数越少,认为模型越准确。所以复杂度越小,语言模型越好。
因为是语言模型,即预测的出来的词是否准确,也可以从预测的误差中看出模型的好坏,若预测的误差越低,则说明预测的准确。误差为预测值和真实值做差,所以误差也作为一个评价指标。
3.3 实验与结果分析
为了验证时序卷积网络语言模型的有效性,本文选择递归神经网络RNN和LSTM神经网络在相同数据集上做相同的实验作为比对。
基于LSTM的语言模型使用TensorFlow实现,它使用两层LSTM网络,且每层有200个隐藏单元。我们在训练中截断的输入序列长度为50,且使用Dropout和梯度截断等方法控制模型的过拟合与梯度爆炸等问题。基于RNN的语言模型也是使用TensorFlow实现,由两层基本的RNN网络构成,输入序列长度为50,基于时序卷积网络的语言模型使用PyTorch实现。实验完成后比较复杂度的结果如图6所示。

图6 3种算法的复杂度比较
图6可以看到,横轴代表训练次数,竖轴代表复杂度,随着训练次数的增加,各模型的复杂度在下降,刚开始时序卷积网络收敛的速度最快,LSTM次之,RNN最慢。由于复杂度的变化在1000之内的变化幅度比较明显。由图7可以看出,时序卷积网络的复杂度始终低于其它两种算法,而最终的比较结果也是显示时序卷积网络的复杂度最低。
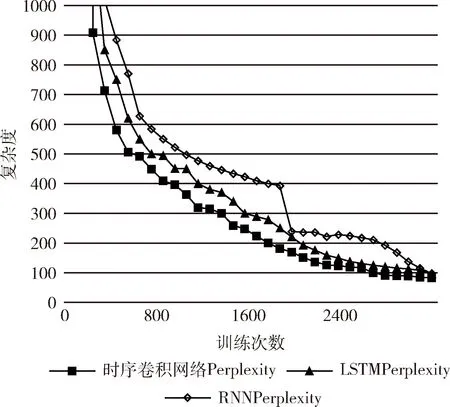
图7 3种算法局部复杂度比较
图8是3种模型的误差图像,可以看出,刚才始时序卷积网络的误差比其它两种模型的误差低,而且时序卷积网络的语言模型误差始终比其它两种模型的误差低,收敛速度快,说明模型的学习能力强,能快速的降低误差。最终同其它两种模型相比,时序卷积网络的误差也是最低的,说明该网络结构在语言模型优于其它两种结构。

图8 3种算法的误差对比
其综合对比结果见表4。
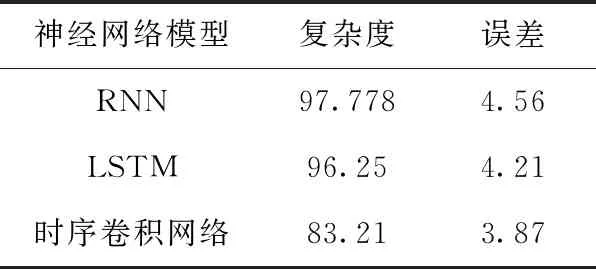
表4 3种算法综合对比
由表4可知,3种模型中,时序卷积网络最好,复杂度达到83.21,其次是LSTM达到96.25,最差的是RNN达到97.778。误差方面时序卷积网络最低为3.87。实验结果表明,基于时序卷积神经网络的模型在词级语言建模的任务中和递归神经网络以及LSTM神经网络相比表现最好。复杂度为83.21,误差为3.87,是一种有效的词级语言建模方法。
4 结束语
本文基于时序卷积神经网络的模型实现了词级级语言建模,与RNN、LSTM神经网络模型在PennTreeBank数据集上的实验结果对比表明,在这几种方法中时序语言模型的语言建模最好,复杂度为83.21。说明该方法适合处理词级语言建模的任务,能充分挖掘数据特征,降低复杂度。本文将扩大卷积网络运用到语言模型的研究中,使用扩大卷积可以保留更多的历史信息,从而提高语言模型预测的准确率。本文的研究结果会作为接下来语言模型的研究基础。
猜你喜欢
《学习方法报》历史中考版(2024年8期)2024-12-31 00:00:00
中国农业信息(2021年3期)2021-11-22 06:44:48
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
中国惯性技术学报(2019年6期)2019-03-04 09:50:10
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
中央民族大学学报(自然科学版)(2017年2期)2017-06-11 07:14:54
电子制作(2016年15期)2017-01-15 13:39:08
火控雷达技术(2016年3期)2016-02-06 02:30:28
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01 02:54:43
