
改进的DDPG对话策略优化算法
2021-02-25 05:50:56赵崟江李艳玲
计算机工程与设计 2021年2期
赵崟江,李艳玲,林 民
(内蒙古师范大学 计算机科学技术学院,内蒙古 呼和浩特 010022)
0 引 言
任务型对话系统是对话系统领域的重要分支,主要包括自然语言理解(natural language understanding,NLU)、对话管理(dialogue management,DM)和自然语言生成(nature language generator,NLG)3个模块,旨在帮助用户完成某一特定任务,如航班预订、票务查询等。其中,对话管理模块是对话系统的核心,负责记录交互过程中的状态信息变化以及选择恰当的动作去执行,其设计的好坏直接影响了对话系统的性能和用户的满意程度,具有重大的研究意义和应用价值。
在目前的对话策略研究方法中,大部分学者都采用强化学习的方式建模对话管理,这种马尔科夫决策过程契合多轮对话的物理结构,较好解决了对话问题。但是当使用策略梯度方法寻求对话策略时,它存在模型难收敛的问题,很难找到成功的对话策略。除此之外,在对话领域中大部分学者使用规则用户模拟器作为环境模型来与代理交互,规则用户模拟器由于人为设计规则,与真实用户存在很大差距,在一定程度上也会对代理训练产生负面影响,因此降低规则用户模拟的负面作用是非常有必要的。
本文从强化学习的角度出发,提出并使用结合规划的离散DDPG优化算法在代理和环境两个方面进行改进,旨在解决策略梯度方法模型难收敛问题以及降低规则用户模型的负面作用。在代理方面,本文针对原有的DDPG算法只适合处理连续空间任务的这一缺陷提出了一种改进算法,使其能够处理离散空间的对话任务。在环境方面,本文借鉴了DDQ模型思想并将Dyna-Q框架[1]结合到代理中,使它与改进的DDPG算法结合起来,从策略梯度的角度提升代理的训练效果。实验结果表明,本文所提出的方法能够帮助代理更快找到成功的对话策略,取得了较好的实验效果。
1 相关工作
目前,学者们通常把任务型对话系统定义为强化学习问题[2,3],通过代理与环境交互进而学到较好的对话策略。在基于强化学习的任务型对话系统中,对话管理通常作为代理选择动作并作用于环境,用户模拟器作为环境负责对代理进行反馈,如图1所示。

图1 强化学习模型
在代理方面,学者们使用不同的强化学习方法构建对话策略。大体上,这些方法主要分为两大类:①基于值函数的强化学习方法[4,5];②基于策略梯度和基于值函数相结合的强化学习方法[6,7]。在基于值函数的强化学习方法中,它通过优化Q值选择动作,因此代理在选择每一步动作之前都需要计算相应的Q值,比较适合离散空间的任务。Li等提供了一个公共可用的用户模拟器框架和代理交互,让代理从样本中学习策略,其中在预订电影票的对话任务中,基于DQN(deep Q-network)代理的成功率远高于基于规则代理的成功率,说明了基于值函数的强化学习方法在处理离散任务上具有良好的效果[4]。Lipton等改进了DQN并提出BBQN(Bayes-by-backprop Q-network)对话管理模型,它通过使用汤普森采样(Thompson sampling)在状态空间中探索,使探索效率明显提升[5]。基于策略梯度和基于值函数相结合的强化学习方法使用策略梯度方式建模对话管理,即把对话策略表达成一种参数模型的形式,通过直接训练参数进而找到较好的对话策略。如Peng等提出的对抗学习A2C(adversarial advantage actor-critic)模型成功结合了策略梯度和价值函数,然后通过对抗学习鉴别器的引导,学习到较好的对话策略[6]。虽然这种方法能够处理状态-动作空间很大的情况,但是与基于值函数的强化学习方法相比也存在收敛速度慢的问题。
在环境方面,使用真实用户和代理交互会产生很大的实际成本。学者们提出使用真实用户对话数据集构建用户模拟器,让用户模拟器替代真实用户以达到降低成本的目的[8,9]。目前,对话领域大多都采用了这种方法[10-12]。理论上,用户模拟器不会产生任何实际成本,但是用户模拟器和真实用户之间存在着很大的差距,在一定程度上也会影响代理的训练效果。Dhingra等已经对此做了很好的验证[13]。不仅如此,到目前为止也没有统一规范的标准来评价用户模拟器的优劣。后来,学者们在环境方面也展开了研究,如Peng等提出了一种DDQ(deep Dyna-Q)模型,该模型是在环境一方引入一个世界模型来模拟用户模拟器的响应进而生成模拟经验,在训练过程中同时使用两种经验学习,避免了代理对用户模拟器的高度依赖,并且取得了较好的实验效果[14]。Su等改进了DDQ模型并提出了D3Q(discriminative deep Dyna-Q)对话管理模型,它在DDQ模型基础上引入了基于RNN的鉴别器。该鉴别器能够区分模拟经验和真实用户经验,从而控制训练数据的质量,减少了DDQ对模拟经验质量的高度依赖。实验结果表明,D3Q对话管理模型相较于DDQ对话管理模型拥有更好的鲁棒性和泛化性[15]。
2 结合规划的DDPG算法
本文中结合规划的DDPG代理由5个模块组成,如图2所示:①一个基于LSTM(long short-term memory)的NLU模块用于识别用户意图和关键的语义槽[16];②对话状态跟踪:根据NLU模块识别的结果生成对话状态表示[17];③对话策略选择:根据对话状态选择一个动作去执行;④NLG模块:将对话行为转换为自然语言并反馈给用户[18];⑤世界模型:模拟用户模拟器生成模拟的用户行为和奖励。
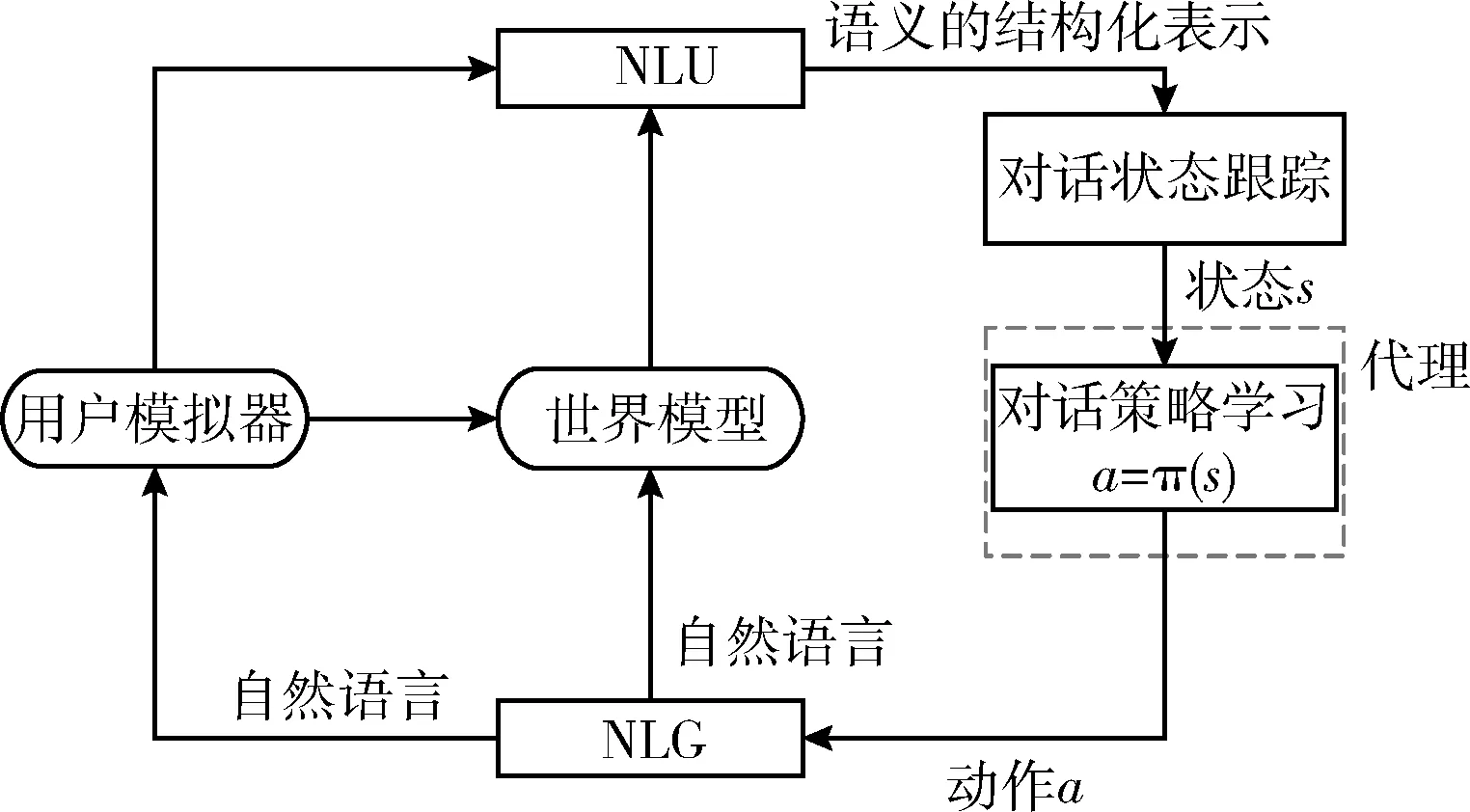
图2 代理训练过程模型
用户模拟器在训练过程中主要有两个重要作用,如图3所示:①它可以生成真实经验直接训练代理。②它生成的真实经验也可以用来改善世界模型。前者被称为直接强化学习,后者采用监督学习训练,使世界模型的表现更贴近真实用户,被称为世界模型学习。世界模型的作用是模拟用户模拟器的提问方式生成模拟经验,用于后续代理训练。

图3 结合规划的DDPG模型
本文使用预先收集的对话数据集初始化对话策略和世界模型,然后开始进行代理训练。代理的训练包括3个过程:①直接强化学习:代理与用户模拟器交互并使用真实经验改进对话策略;②世界模型学习:使用真实经验更新世界模型;③规划:代理使用模拟经验改进对话策略。算法1实现了此迭代过程。
算法1:迭代训练算法
(1)初始化actor-online、critic-online的神经网络参数:θQ和θμ;
(2)初始化actor-target、critic-target神经网络参数:θQ′←θQ,θμ′←θμ;
(3)初始化世界模型M(s,a|θM)的参数:θM;
(4)采用热启动方式对actor-online、critic-online网络以及世界模型M初始化;
(5)初始化真实经验回放池Du,模拟经验回放池Ds设为空;
(6) for each episode:
直接强化学习开始
(7) 使用规则用户模拟器开始一个用户动作aμ,并且生成一个对话状态s;
(8) whiles非终止状态 do:
(9) actor-online网络按照确定性策略μ(s|θμ)选择动作a执行;
(10) 规则用户模拟器根据动作a给出下一个用户动作aμ′,并给出反馈奖励r;
(11) 根据aμ′更新下一个对话状态s’;
(12) 保存(s,a,r,aμ,s′)到真实经验回放池Du中;
(13)s’=s;
(14)end while;
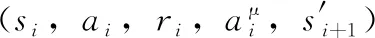
(16)使用式(1)和式(2)计算critic-online的损失函数:
(17)根据损失函数值采用Adam optimizer 更新critic-online的θQ;
(18)使用式(6)计算actor-online网络的损失函数;
(19)采用Adam optimizer更新actor-online网络θμ;
(20)使用式(7)更新actor-target、critic-target网络参数:
直接强化学习结束,开始训练世界模型
(21)从Du中随机抽取小批量样本采用监督学习方式训练M(s,a|θM);
(22)使用SGD更新θM;
世界模型学习结束,规划开始
(23)for k=1:K do:
(24) t=FLASE;
(25) 世界模型随机生成一个用户目标G;
(26)从G中采样一个用户动作aμ,并且生成一个对话状态s;
(27) while t 非FLASE do:
(28) actor-online网络按照确定性策略a=μ(s|θμ)选择动作a执行;
(29) 输入(s,a)到世界模型生成aμ,r和t;
(30) 根据aμ更新对话状态到s’;
(31) 保存(s,a,r,s′)到模拟经验回放池Ds;
(32)s=s’;
(33) end while
(34) 从模拟经验池Ds中随机抽取小批量样本(s,a,r,s′);
(35) 转到算法的(16)-(20)行,执行DDPG网络参数更新;
(36)end for;
规划结束
(37)end for;
2.1 直接强化学习
直接强化学习是代理直接使用用户模拟器生成的真实经验改进对话策略(见算法1中的第(7)行-第(20)行)。本文将任务型对话过程视为马尔科夫决策过程,代理和用户模拟器在多次的交互中选择一系列动作以实现用户目标。本文使用改进的DDPG算法,在每一次交互中,代理观察用户模拟器给出的对话状态s,根据确定性策略μ(s|θμ)选择动作a,其中μ是由参数为θμ的多层感知机(multi-layer perceptron,MLP)实现的,用户模拟器根据动作a反馈给代理奖励r,并给出下一个用户响应aμ,然后对话状态更新为s’。最后将经验(s,a,r,aμ,s′)存储在真实经验回放池Du中,循环继续,直至对话终止。本实验中的参数更新主要有两个网络:actor-online网络、critic-online网络,如图4所示。

图4 DDPG算法模型
在critic-online网络中,本文通过调节θQ来最小化均方误差损失函数以优化Q值,其优化目标如下
yi=ri+γQ′(s′i+1,μ′(s′i+1|θQ′))
(1)
(2)
其中,γ∈[0,1]是折扣因子,θQ和θQ′为critic-online和cri-tic-target网络的参数,根据loss更新actor-online网络参数。在actor-online网络中,原有的DDPG算法是处理连续型空间的任务,它的梯度如式(3)所示[19]

(3)

(4)
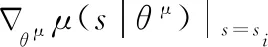
(5)
其中,μ(s|θμ)|si表示参数化的确定性策略,在本文中表示某个离散动作值的编号。prob(μ(s|θμ)|si)表示选择某个动作的概率值。因此,式(3)就可以写成如下形式

(6)
其中,yi用式(1)表示。通过式(6)我们就可以更新actor-online网络的参数。而actor-target网络、critic-target网络采用soft机制更新,如下所示[19]
(7)
最后,我们采用批次训练的方式在每次迭代中改进对话策略,见算法1的第(15)行-第(20)行。
2.2 规 划
在规划步骤中(见算法1的第(23)行-第(36)行),世界模型会生成模拟经验以改进对话策略,算法1中第(23)行的K是代理在直接强化学习中执行规划步骤的数量,即世界模型如果可以准确模拟用户模拟器,那么代理就可以使用K步规划来改进对话策略。在本文的实验中,Du用于存储用户模拟器生成的真实经验,Ds用于存储世界模型生成的模拟经验。Du中的真实经验直接用来学习对话策略,Ds中的模拟经验则用来进行规划。下面描述模拟经验的生成过程。
在每次对话开始时代理都需要采样用户目标G,用户目标通常由约束语义槽和请求语义槽组成G=(C,R),其中,C表示一组约束语义槽,用户可以用它进行约束搜索。以预订电影票的任务为例,约束语义槽通常包括电影的购票数量、日期等;R表示请求语义槽,用户可以用它请求某个具体语义槽的值,请求语义槽通常包含影院的位置、开始时间等。
在每轮对话中,世界模型会将当前的对话状态s以及当前代理执行的最后一个动作a表示成one-hot形式并作为模型的输入,接着世界模型会输出用户响应aμ、奖励r以及二进制变量t,t表示对话是否终止(见算法1的第(29)行),其中世界模型M(s,a|θM)使用多层神经网络表示,如图5所示。

图5 世界模型结构
aμ、r和t的计算过程如下
h=tanh(Wh(s,a)+bh)
(8)
r=Wrh+br
(9)
aμ=softmax(Wa+ba)
(10)
t=sigmoid(Wth+bt)
(11)
其中,(s,a)表示s和a进行拼接。世界模型根据生成的用户响应aμ更新下一个对话状态s’,最后,我们将模拟经验(s,a,r,s′)保存到Ds中,用于后续代理进行规划。
2.3 世界模型的学习
世界模型的学习采用监督学习的方式(见算法1中的第(2)行-第(22)行),它可以被看作为多任务分类的神经网络,其中aμ和t被视为两个分类任务,r被视为一个回归任务。世界模型学习的时候,每次从Du中随机抽取小批量样本并采用随机梯度下降法更新模型的参数。
3 实验设置
本文是在预订电影票的对话任务上评估结合规划的DDPG算法的有效性和可行性。
3.1 数据集
本文使用的电影数据集是通过Amazon Mechanical Turk收集的且已经标注完毕。其中包含11个对话行为和16个语义槽,总共包含280个带标记的对话,每个对话回合大约11轮,见表1。

表1 意图和语义槽
3.2 不同代理的描述
基于规则的代理:该代理使用人工定义的规则构建对话策略,即本文的热启动部分。
DQN代理:该代理使用标准的DQN算法实现。
A2C(advantage-actor-critic)代理:该代理使用带优势值的标准actor-critic算法实现。
DDPG代理:该代理使用本文所提出的改进的DDPG算法实现,并使用直接强化学习训练。结合规划DQN代理:在标准的DQN算法中引入世界模型,并结合规划步骤进行学习。
结合规划的A2C代理:在标准的actor-critic算法中引入世界模型,并结合规划步骤进行学习。
结合规划的DDPG代理:本文所提出的改进的DDPG算法中引入世界模型,并结合规划步骤进行学习。
3.3 实验内容
在后6种代理中,actor网络、critic网络以及世界模型的网络,隐藏层的激活函数均为tanh函数,节点数目为80。本文设置了折扣因子γ=0.9,Du和Ds大小设置为5000。在规划步骤中,模拟对话的最大回合数为40(L=40)。此外,为了提高对话训练的效率,本文还应用了模仿学习的一种变体RBS (response buffer spiking)。除此之外,本文还采用热启动策略对所有代理进行100轮对话的预训练,并对真实经验回放池进行预填充。
3.4 用户模拟器
本文采用Li等提出的用户模拟器[4]。在训练过程中,用户模拟器在每个对话回合中为代理提供一个模拟的用户响应,并在对话结束时提供一个奖励信号。只有成功预订了电影票并且代理提供的信息满足用户的所有约束时,对话才被认为是成功的。对话任务成功时,代理将收到2*L正奖励;对话任务失败时,代理将收到负奖励-L,其中L是每次对话中的最大回合数。此外,在每个对话回合进行时,代理将获得-1的奖励,目的是引导代理使用更少的对话轮数完成预订电影票的对话任务。有关用户模拟器的详细信息请参考文献[4]。
3.5 实验结果分析
表2中的每个结果都是代理重复5次以上的平均结果,并不涉及规划步骤(K=0)。它是从代理的角度来比较各个算法的优劣,具体包含以下3个评估指标{成功率,平均回报,平均轮数}


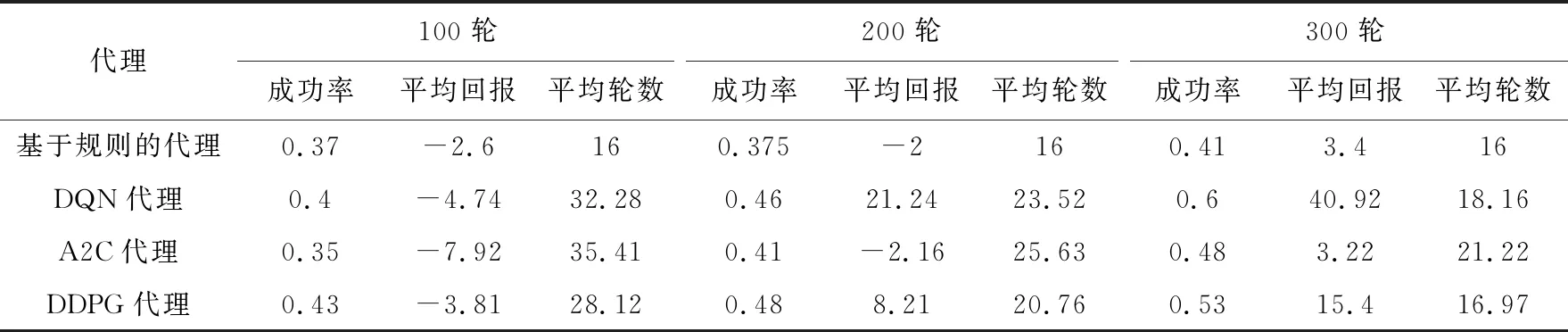
表2 不同代理在epoch={100,200,300}回合的表现
成功率用来衡量系统的总体性能,考验对话系统从整体上完成任务的能力,平均回报、平均轮数则用来衡量系统鲁棒性,我们不仅需要系统具有较优秀的任务完成能力还需要对话系统具有良好的决策能力,通过较少的轮次得到更多的回报。
通过表2可知在代理学习的开始阶段,DDPG代理的学习速度要高于其它的代理,其主要原因是本文采用确定性策略能够帮助代理更快找到成功的对话策略,而在学习的后面阶段(300轮左右),结合规划的DDPG代理学习速率要低于DQN代理,其主要是因为DDPG代理需要学习两种参数不同的神经网络:actor-online网络和critic-online网络,这两个网络存在学习不同步的问题,actor-online网络选择动作的优劣取决于critic-online网络的打分,在criticonline网络训练好之前,很难对actor-online网络进行有效的训练,而DQN代理只需要训练一种神经网络参数,并不存在多网络协作问题,所以它的效果要优于A2C、DDPG等代理。但是与A2C代理相比,本文所提出的方法要优于A2C代理,验证了从策略梯度角度出发,本文所提出的方法能够在一定程度上加快模型的收敛速度,带来更好的对话性能。
表3展示了在代理中引入规划步骤,并探索了不同K值对代理训练的影响,通过表3可知,在环境一方引入世界模型的确可以减少用户模拟器对话代理训练的负面影响,不同的K值对代理训练产生的效果并不相同,只有最佳K值才能够最大程度减小负面作用。其主要原因是世界模型在代理训练过程中也需要更新学习,世界模型生成的模拟经验会在规划步骤中直接影响代理的训练效果,较差的模拟经验会减低代理的训练效果,因此需要在世界模型学习和代理学习之间进行权衡才能得到最佳的训练效果,本文通过设置不同K进行多次实验并选择了K=i(i=5,10,20)进行展示,得出当K=10时,世界模型会生成较优的模拟经验,训练出的代理效果最佳。

表3 不同K的代理在epoch={100,200,300}回合的表现
表4展示了不同代理在运行10 k轮模拟对话之后所得到的最终表现,通过对比分析可知,结合规划的DDPG算法从策略梯度的角度建模对话管理,在一定程度上提高了基本的策略梯度方法(advantage-actor-critic)的性能,大约提高了15%,进一步验证了该方法的有效性。但是与基于值函数的强化学习方法相比,并没有达到与DQN代理相似的效果,说明了当处理动作离散(或动作空间有限)的对话任务时,基于值函数的强化学习方法确实要优于策略梯度的方法。在本文预订电影票的对话任务中,它只包含43个离散动作,因此通过计算Q值选择动作足以解决该任务。本文所提出的方法虽然没有基于值函数的强化学习方法效果好,但是与基于值函数的强化学习方法相比,它也拥有策略梯度算法的优势:①它是直接针对对话策略建模,避免了基于值函数的强化学习方法中对Q值的计算。当遇到离散动作空间很大时,DQN将会面临Q值计算困难的问题,而结合规划的DDPG算法则不会出现,从理论角度出发,本文所提出的方法更适用于离散动作空间规模较大的对话任务。②它借鉴了经典DDPG的思想,通过结合经验回放机制降低了样本数据的相关性,以及双网络机制稳定了学习目标,带来更好的实验效果,加快了模型的收敛速度。
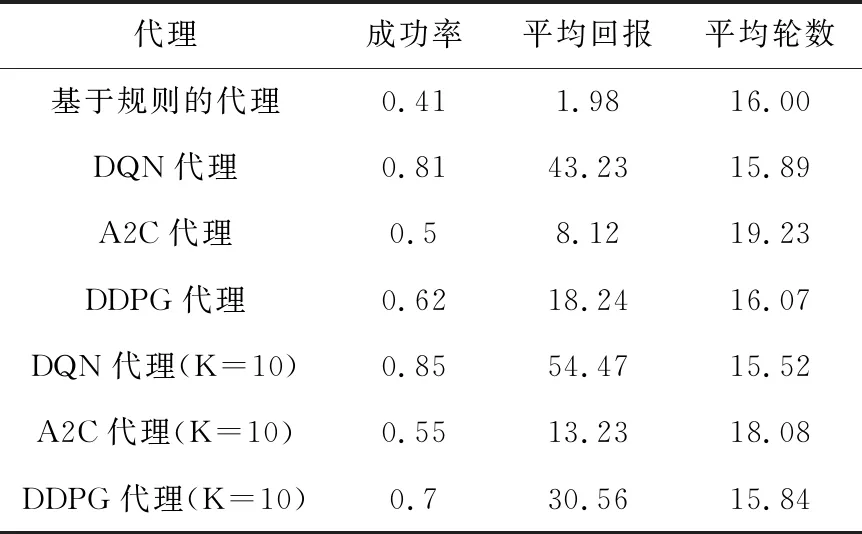
表4 不同代理在10 k个模拟对话的最终表现
4 结束语
本文所提出的结合规划的DDPG代理在环境和代理两方面做出改进。在代理一方,本文并未使用基于值函数的强化学习方法(DQN),而是使用了策略梯度方法建模对话管理,它是使用策略梯度方法处理对话任务的一次尝试,借鉴了DDPG的模型框架,引入了经验重放机制以及双网络机制,加快了模型的收敛速度,得到了较好的对话性能。在环境一方,通过引进世界模型使代理不必完全依赖于用户模拟器,减少用户模拟器设计的不完善而造成对代理训练产生的负面影响。本质上,世界模型可以看作另外一种具备学习能力的用户模拟器,与基于规则的用户模拟器相比,世界模型最大的特点就是具备学习能力,它能够学习用户模拟器的提问方式,提供更优质的训练样本数据,从而提高代理的训练效果。但是再优秀的世界模型也同样需要一个优秀的学习目标(用户模拟器),验证了在当前对话任务中通过改进用户模拟器来提升代理性能的重要性。
当前本文提出的方法仍然有需要进一步改进的地方:第一,本文从策略梯度的角度建模对话管理,但是并未取得和DQN类似的效果,其主要原因是actor网络、critic网络拥有两种不一样的训练参数,所以存在网络学习不同步的问题,并且actor动作选择的优劣完全取决于critic的评分,因此导致模型收敛困难。本文虽然采用了双网络机制在一定程度上缓解了该问题,使代理的性能优于标准的AC代理,但是如何让这两个网络共同协作,步调一致地进行更有效学习是策略梯度方法进一步发展的关键,也是接下来本文工作继续深入研究的重点。第二,当前对话领域中的用户模拟器构建并不完善,它与真实用户之间依旧存在很大的差距,对代理的训练有可能产生负面影响,进而影响代理的学习效率。因此后续工作将通过改进用户模拟器进而提升代理性能。
猜你喜欢
党课参考(2021年20期)2021-11-04 09:39:46
小哥白尼(趣味科学)(2021年6期)2021-11-02 05:23:48
故事作文·高年级(2021年4期)2021-05-06 03:20:04
小哥白尼(神奇星球)(2021年11期)2021-03-08 09:00:18
小哥白尼(军事科学)(2019年6期)2019-03-14 05:49:56
趣味(数学)(2018年12期)2018-12-29 11:24:00
党课参考(2018年20期)2018-11-09 08:52:36
现代营销(创富信息版)(2018年8期)2018-09-08 08:51:50
学生天地(2016年23期)2016-05-17 05:47:15
都市丽人(2015年4期)2015-03-20 13:33:22
