
面向组合投资预测的大数据生成算法
2021-02-25 09:12:12赵会群
计算机工程与设计 2021年2期
赵会群,曲 艺
(北方工业大学 信息学院,北京 100144)
0 引 言
为了解决组合投资预测问题,我们不仅需要各个投资项信息数据,还需要宏观经济因素、微观经济因素、行业因素等大量数据。然而真实、大量、多样的金融数据由于保密性、时间等一些问题的限制不易获取,因此需要一种可以基于真实数据集建模并保持真实数据集特征的大数据生成方法。
真实的金融数据一般以时间序列的形式表现。现关于时间序列数据模拟和生成的方法主要有:回归移动平均模型(autogressive integrated moving average,ARIMA)[1]、自回归条件异方差模型(autoregressive conditional hete-roscedasticity model,ARCH)[2]、支持向量回归模型(support vector regression,SVR)[3]、长短期记忆网络模型(long short term memory,LSTM)[4]等。由于本文所需模拟生成的数据表现出较明显的季度或月度的周期性变化,所以将采用季节性差分自回归移动模型(seasonal autogressive integrated moving average,SARIMA)来对各项时间序列数据进行自动模拟生成,为原有历史数据集补充部分未来数据,用于后续组合投资数据生成模型的更新。
为了解决组合投资预测的数据生成问题,需要先将其转化为影响因素和投资项的组合优化问题,通过模型分析各数据项之间的关系,最终生成大规模数据集。近年来,已有学者使用遗传算法[5]、粒子群算法[6]、蚁群算法[7]等解决组合优化问题的经典算法,来实现测试数据的自动生成。此外,由于贝叶斯网络模型[8]可清晰揭示节点变量间的关系及概率分布,该模型同样已应用于数据生成领域。但随着时间的变化和金融数据的增加,将更新的信息应用到投资组合预测之中是十分必要的。本文提出一种基于增量式贝叶斯网络的投资组合数据生成方法,可以实现基于动态更新的数据集,生成具有大数据4V(variety, volume, velocity, value)特性的[9]、保持一定准确度的数据集。
1 相关工作
迄今为止,已经有一些应用于大数据领域的数据生成器和数据生成算法的研究。金澈清等[10]在介绍数据管理系统评测基准的发展同时,也详细介绍了数据驱动的数据生成方式和查询驱动的生成方式在各数据库系统基准中的实现。詹剑锋等[11]详细介绍了其研制的BigDataBench,即一种开源的大数据系统评测基准。并提供了一种通过真实数据的建模分析,快速生成保持真实数据特征的指定规模数据集的大数据生成工具(BDGS)。目前该工具可生成文本、表和图这3种类型的数据。
本文中所用到的各项金融数据本质上是一种时间序列数据。所以,当涉及到对数据集进行生成扩展时,可以通过训练时间序列模型来生成数据。目前已有时间序列模型和时间序列分析方法,通过序列的历史统计数据揭示现象随时间变化的规律,并按照需要将该规律延伸到未来。孙亚圣等[12]提出基于注意力机制的行人轨迹预测生成模型(AttenGAN),生成器使用LSTM算法根据行人过去的轨迹对未来的可能性进行预测,判别器用来判断一个轨迹是否真实,进而促进生成器生成符合社会规范的预测轨迹。敖建松等[13]针对数据的时序性,利用ARIMA模型对未来时刻数据进行预测生成,计算出各个状态数据偏离正常状态空间的程度,再使用滑动窗口对过去和未来的数据进行融合计算,实现工控系统网络的态势感知。Vasantha Kumar S等[14]通过SARIMA模型利用有限的历史数据,分析出长期趋势和季节性模式,并利用该模型对交通流量数据进行短期的准确预测,且发现SARIMA模型性能优于简单ARIMA模型。
用时间序列模型生成数据,扩展数据集,只保证了生成数据的时序性,但本文主要解决如何生成组合投资数据的问题,还需要生成的数据保持数据相关性等真实特征。本文将组合投资数据的生成模型构建转化成组合优化问题,并根据模型生成大数据集。以下是目前外关于该类问题的部分研究成果:曾梦凡等[7]采用一种解决组合优化问题的搜索算法——蚁群算法,应用于求解覆盖表的生成问题。为了挖掘蚁群算法生成覆盖表的潜力,文章对参数配置、演化策略等进行调整,并引入并行计算来节省时间开支。马骊等[15]先利用支持向量机对汇率进行短期的预测,然后提出基于Pareto排序理论的双目标非支配排序人工鱼群算法(nondominated sorting artificial fish swarm algorithm,NSAFSA)来求解生成外汇投资组合方案。
上述生成模型,可以生成各项变量的组合方案,但未能清晰体现各变量之间的相关关系。而本文通过增量式贝叶斯网络模型体现各项变量之间潜在的关系,并且可以随着新生成的数据集的加入,对原有的历史网络进行更新。以不同时间段的网络中各变量之间的关系及概率为基础,按照需求对网络进行路径搜索,并生成所需数据。目前已有研究将增量式贝叶斯网络模型应用于海量数据流的分析处理[16]和金融数据的预测等领域,但尚未被应用于组合投资数据内在关系的挖掘、生成用于组合投资预测的大数据集方向。
2 算法研究
2.1 时间序列生成算法
时间序列数据作为数据的表现形式之一,真实地记录了不同时间点(或时间片)的各种重要信息,其中蕴含着丰富而有价值的知识。本文使用SARIMA对多列金融时间序列数据进行生成。SARIMA模型来源于差分自回归移动平均模型(ARIMA)。ARIMA(p,d,q)模型中,p为自回归项数,q为移动平均项数,d为时间序列成为平稳序列所做的差分次数。若时间序列{Yt}是一个非平稳序列,ARIMA模型可表示为
Φ(B)ΔdYt=c+Θ(B)εt
(1)

SARIMA(p,d,q)(P,D,Q)s模型主要用于分析由于周期性(包括周度、月度、季度、年度等)变化或因其它因素引起的具有周期性变化的时间序列,对ARIMA模型进行基于周期的季节差分。设季节性序列的变化周期为s,季节差分算子定义为
Δs=1-Bs
(2)
Bs为s步滞后算子。若季节性时间序列用{Yt}表示,则一次季节差分表示为
Δs·yt=(1-Bs)yt=yt-yt-s
(3)
若{Yt}为非平稳季节性时间序列,则需进行D次季节差分,并建立关于周期为s的P阶自回归Q阶移动平均季节时间序列模型
(4)
现有的SARIMA模型建立方法中通常先对数据进行平稳性检验及处理:观察序列是否为平稳的时间序列,如果序列是非平稳的时间序列,则需要对原序列进行普通差分和季节差分,并由此确定参数d,D;通过观察时间序列的自相关、偏自相关函数的截尾或者拖尾特性,确定模型的p,q,P,Q参数。
但本文中需要对数据集中多列时间序列数据进行数据自动生成。上述步骤大多需要人工观察确定参数取值,且对于不同的时间序列数据,模型的参数也会不尽相同。但通过文献阅读和多次实验发现,p,q,d,P,Q,D的取值范围都较为常规,所以本文使用网格搜索法确定模型最优参数组合。之后使用确定的参数组合,对模型进行检验和测试,若实用测试集中数据得出的预测值与实际值的相对误差小于5%,则说明建立的模型准确度较高,该模型可准确地模拟生成未来的数据。
算法1:SARIMA模型建模及数据生成算法
input:历史数据集D中的m列时间序列数据,参数的取值范围[i,j],需要生成的数据数量n
output:生成的n行m列新数据集D’
(1)begin
(2)fori←1…m/*处理数据集D中第i列时间序列数据*/
(3) 对读取的差分后平稳数据进行归一化处理
(4)pSet=(1,1,1)(1,1,1) /*为最优参数组合设置初始值*/
(5)minAic=-231
(6)forp,d,q,P,D,Q←i…j//寻找最优参数
(7) 将(p,d,q)(P,D,Q)带入SARIMA模型中,计算当前参数对应的模型aic值nAic
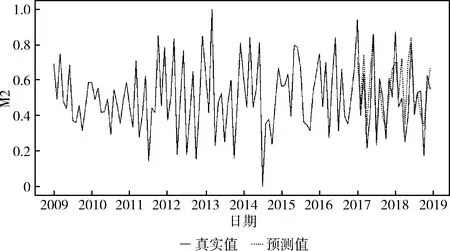
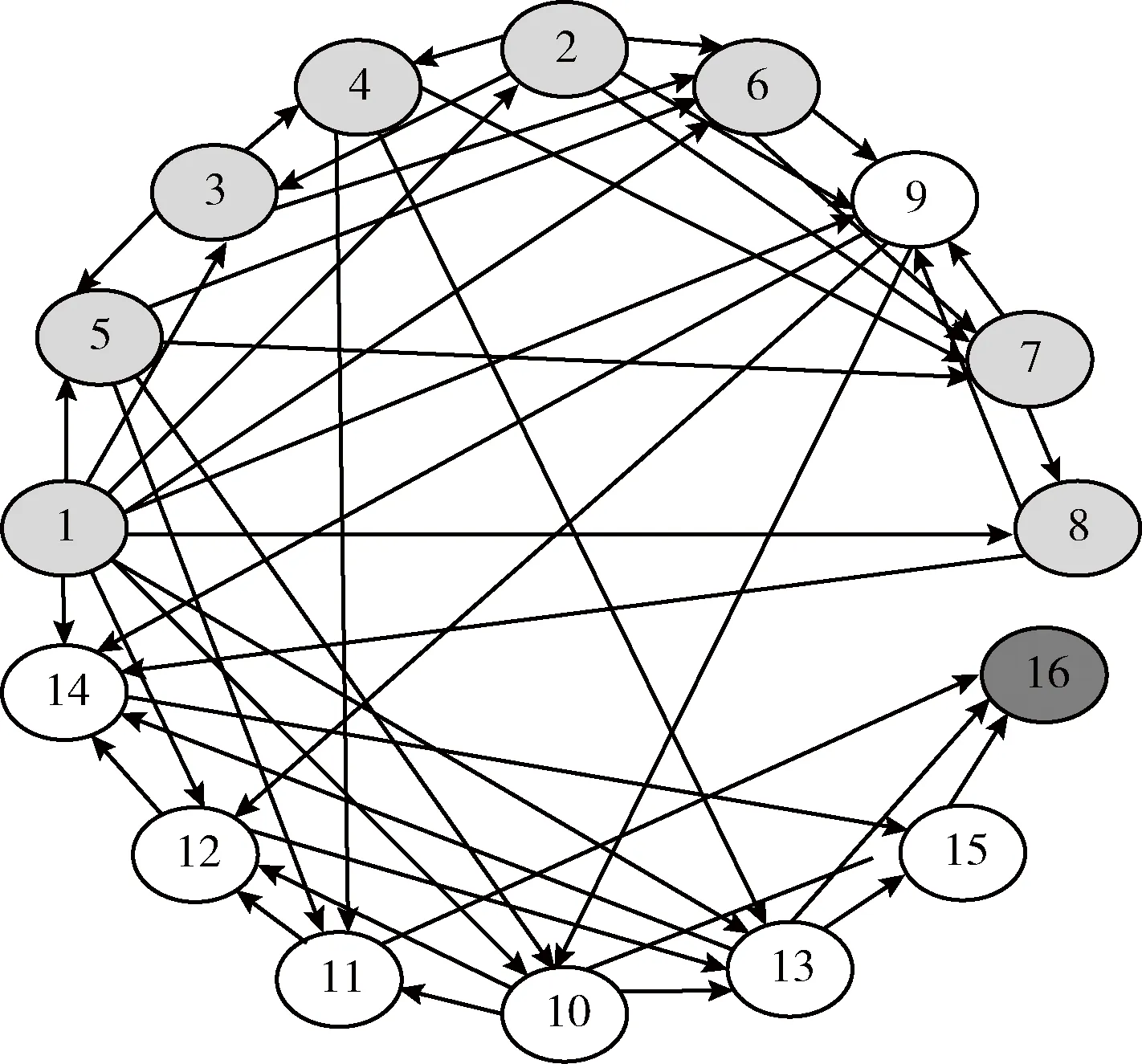
(8)IfnAic (9)minAic=nAic (10)pSet=(p,d,q)(P,D,Q) (11)fork←1…n (12)通过SARIMA(p,d,q)(P,D,Q)s模型进行滚动预测生成第k个值Pk (13)D’=D’∪Pk (14)End 贝叶斯网络是一种基于概率论和图论的不确定性知识表示和推理的模型,可以定量且定性地描述随机变量之间关系,可以形象、直观展示数据中所蕴涵的知识信息。但股票、房产、以及经济、政策等影响因素,均具有很强的时效性;而且模型在建立时本身就会有一定的误差,再加上数据随着时间而变化,就会出现构建的历史模型无法适应新数据的情况。所以若想生成长期的组合投资方案数据,网络需要随着新产生的数据进行调整。贝叶斯网络更新技术可以让原有的历史模型随着新数据加入发生变化,使贝叶斯网络模型具有更全面的描述能力,以便后续生成更可靠的数据。 目前常用的贝叶斯网络更新算法主要有两种:一种方法是naive方法,这是一种批量式算法,该算法在新数据到来时将新旧数据集整合到一起,在一个更大的数据集下舍弃已有结构重新学习,如图1所示,但这种方法需要消耗大量的存储空间和计算时间。另一种解决方法MAP方法,是把通过学习历史数据训练得到的模型看作历史数据的代表,这样可以避免重复多次地处理历史数据,如图2所示。但是这一模型过于依赖历史模型,可能会在多次迭代后,不能再根据新数据更新模型。 图1 naive方法 图2 MAP方法 本文将采用一种增量式学习方法对贝叶斯网络模型进行更新。该方法的主要思想是,从历史数据中随机抽取一定量的数据样本,与新数据集合并之后,训练出贝叶斯网络结构,再将此贝叶斯网络结构与历史模型做并集处理,以完善贝叶斯网络结构。最后进行参数的学习,对网络参数进行更新,如图3所示。 图3 增量式方法 使用上述算法1时间序列生成结果作为新加入的数据集,结合历史数据及历史贝叶斯网络,得到更新的贝叶斯网络,并以时间为新贝叶斯网络命名保存于对应矩阵中,以便后续按照时间调用查询。具体实现算法如下。 算法2:贝叶斯网络模型更新算法 input:历史数据集D, 其中的变量集合为V={X1,X2,…,Xn},历史数据集训练的贝叶斯网络S(G,θ),其有向无环图G(V,E),新数据集Dnew,且其变量集合Vnew={X1,X2,…,Xm} output:更新的贝叶斯网络S(G’,θ’) (1)Begin (2)ifn!=mthen: (3) 从D中随机抽取p条数据,组成数据集D’ (4)Dt=D’∪Dnew (5) 使用K2算法通过Dt训练出贝叶斯网络结构 (6)Gnew(Vnew,Enew) (7)V’=V∪Vnew (8)E’=E∪Enew (9)G’=(V’,E’) #更新的贝叶斯网络结构 (10)Endif (11) 原参数θ变成贝叶斯网络中的先验参数 (12) 通过Dt内数据,使用最大似然估计求得更新的参数θ’ (13)End 用于组合投资预测的大数据生成算法主要分成两步实现。首先是在分析对应的贝叶斯网络结构及其概率分布表,按照需求在贝叶斯网络模型上进行路径搜索,生成可用于组合投资方案测试的路径数据集合,及集合中各路径的概率;之后,根据集合中的路径节点取值及对应的概率生成所需数量的大数据集。 选取指定时间段的贝叶斯网络,此贝叶斯网络是对该段时间内新旧数据中各项关系的精确刻画。按需求选取起始节点Xs和终止节点Xe,按照给定的条件概率阈值Pmin和每条组合数据的规模Len,使用回溯法生成出以Xs为起始节点,Xe为终止节点的所有路径长度大于最低阈值的节点序列,并计算每个序列节点不同取值的概率,保留概率大于设定概率阈值的序列变量的取值。最后根据需求,对不同贝叶斯网络迭代生成数据集。 以图4为例,图中X1节点到X4、X5节点的路径:X1->X3->X4,X1->X4,X1->X3->X5,X1->X2->X5。以X1到X4路径为例,假设概率最低阈值为0.7,由概率表计算X1->X4路径上节点不同取值概率,P(X4=1|X1=1,X3)=P(X4=1|X3=0,X1=1)*P(X3=0|X1=1)+P(X4=1|X3=1,X1=1)*P(X3=1|X1=1)=0.676,同理可求P(X4=0|X1=1,X3)=0.324,P(X4=0|X1=1,X3)=0.028,P(X4=1|X1=1,X3)=0.972,在这条路径上,X4=1,X1=1时概率最大且超过所定阈值,保存该路径节点取值及相应概率。按照此方法,生成网络路径节点取值及概率的集合,此集合可用于组合投资预测的分析研究。 图4 贝叶斯网络例图 算法3:组合数据集生成算法 input:贝叶斯网络集,需要预测生成的年份y,开始节点Xs,终止节点Xe output:贝叶斯结点不同取值的路径序列,及其概率的集合 (1)Begin (2)G=BN[y],SS{}=∅,ES=∅,Xvisit[n]=0/*取时间标记为y的贝叶斯网络矩阵,初始化序列集合,其中n为网络结构中的节点数目*/ (3)Generate_ES(Xs,Xe,Len,Pmin) /*生成Xs…Xe节点序列,Len是序列长度的阈值,Pmin是概率的最低阈值*/ (4){ (5)ES∪Xs (7) { (8)SS∪ES (9)ES=ES-Xlast/*回溯到上一个访问节点*/ (10) return (11) } (12)Xvisit[Xs]=1 //标记Xs已被访问过 (13)if(Xs存在邻接点) (14) { (15)for(k←1…m) //m为Xs的邻接点数 (16)if(Xvisit[Xk] == 0) //Xk未被访问过 (17) Generate_ES(Xk,Xe,Len,Pmin) (18)ES=ES-Xlast//回溯 (19) } (20)else (21)ES=ES-Xlast//回溯 (22) } (23)generate_probablity_ES() (24){ (25) generate_ES(Xs,Xe) (26)if(SS!= null) (27) { (28)for(i←1…n) /*计算每个序列发生的联合概率,保留概率大于最低阈值的序列*/ (29) P(Si) =P(Xi|X1…Xi-1)P(Xi-1|X1…Xi-2)…P(X1) (30) if(P(Si)>Pmin) (31) { (32)OutS=Si (33) } (34) } (35)else (36)Xs,Xe条件独立 (37) } (38)End 可根据已有网络路径和路径节点取值概率数据集,通过权重随机生成方法,生成所需数量的大数据集。 在配置为Intel Xeon 3.00 GHz,NVIDIA Tesla K40c GPU,64 G内存,Windows10操作系统,Python 3.6的实验平台环境下编程实现本文算法。 投资项2008年12月到2019年10月历史数据来源如下:选取在十大行业中具有较大影响力的10支股票,分别为中国石油、宝钢股份、中国建筑、中国联通、中国中车、长江电力、格力电器、恒瑞医药、贵州茅台和中国平安,在Tushare数据库中,获取以上10支股票的收益率,以及沪深300指数的收益率数据;房价数据来源于安居客网站北京市石景山区房价月平均数据。 另外,宏观经济因素2008年12月到2019年10月数据来源如下:央行存款利率、存款准备金率、贷款利率均下载自中国人民银行官网;货币和准货币供应量M2、商品消费总额、证券投资者信心指数来自东方财富网数据中心;商品住宅销售额、房地产投资额来自于国家统计局网站公布的月度数据。其中2008年12月到2018年12月的所有数据为训练数据,2019年1月到10月数据作为测试数据。 首先,由于数据时间频率不一致,我们按照月份做平均值重采样处理。另外,由于构建贝叶斯网络的需要,对数据进行离散化处理。先对数据做一阶差分,对于时间序列数据{Xt},p阶差分运算公式为 ΔPXt=ΔP-1Xt-ΔP-1Xt-1 (5) 一阶差分后即获得所有数据的变化值,然后对求得的变化值做如式(6)的离散映射处理,用于贝叶斯网络的训练。式(6)的意义为,当某变量数据值呈上升趋势时取值为1,下跌趋势时为0,平稳趋势时为2。离散化处理完后的部分数据见表1 (6) 表1 离散后的部分数据 利用处理好的历史数据训练模型,得到贝叶斯网络结构结果如图5所示,浅灰色的节点表示宏观经济因素,白色节点为股票和房地产等投资项。表2为网络中节点变量对照。 图5 历史数据生成的贝叶斯网络 表2 贝叶斯网络变量声明 央行存款、贷款利率、存款准备金率数据值较稳定,采用权重随机生成方法,此方法较于随机生成更符合现实情况。本实验中,生成3年数据。实验结果如图6所示。 图6 存款利率、贷款利率、存款准备金率数据生成结果 对其余数据使用SARIMA算法生成新数据,以便后续贝叶斯网络的更新。由于生成数据种类较多,此处以第一列数据货币和准货币供应量M2变化量为例,展示使用SARIMA时间序列算法,通过学习历史数据对未来3年新数据进行生成的过程。由于处理过的数据已较为平稳但数值较大,实验中使用min-max标准化处理数据。其中2009年1月-2016年12月的数据用于模型标定,2017年1月-2018年12月数据用于模型预测评估。 数据处理完后对SARIMA(p,d,q)(P,D,Q)s模型参数进行确定。由于进行1阶差分已使数据平稳,d=D=1,s为时间序列的周期,本实验中使用的是月度数据,s取12。运用算法1确定其余参数,并将确定的参数组合带入模型中,对两年数据进行预测。如图7所示,灰色实线表示真实值,黑色点线为预测值。 图7 2年数据预测结果 从图中可看出预测结果与真实值较为接近,且基本拟合真实值的变化趋势。计算出预测的MSE(均方误差)为0.02,验证该模型的预测精确度较高。模型建立且经过评估后,生成未来3年的数据。最后将生成的数据从归一化的形式还原,结果见表3。 表3 生成3年数据部分结果 按照以上方法,生成其余各项的3年数据,按照年份分成3个数据集,且分别加入历史数据集中未使用的股票数据,模拟新数据集中出现的新变量。 按照算法2从历史数据集中随机抽取部分数据,与上一节新生成的2019年数据集合并,并用此合并的数据集训练出一个新的贝叶斯网络。如图8所示。 图8 合并数据集生成的贝叶斯网络 与图5对比可看出,新数据集训练的网络中,有编号16的深灰色新节点,该节点代表贵州茅台,且增加了以下边:(1, 12),(7, 9), (2, 9), (2, 7), (1, 3), (3, 4), (1, 6), (9, 10), (13, 16), (15, 16), (3, 5), (13, 15), (5, 7), (6, 9), (11, 16), (2, 6), (6, 7), (3, 6), (5, 11)。合并历史数据、新数据集训练出的贝叶斯网络,实现贝叶斯网络更新,生成可以对2019年各节点关系更准确描述的贝叶斯网络,结果如图9所示。并对该网络进行参数学习,获得各节点的概率分布表。 图9 更新后的2019年数据贝叶斯网络模型 按照以上方法,继续生成对应2020年数据的贝叶斯网络,其中的新节点17,18分别代表恒瑞医药,格力电器的收益率;以及2021年数据的贝叶斯网络,图中新加入的节点19,20分别代表长江电力,中国中车股票的收益率。最后结果如图10所示。 图10 2020年、2021年数据的贝叶斯网络模型 以图9:2019年数据的贝叶斯网络模型为例,根据该模型生成可用于2019年的组合投资测试数据集。将联合概率阈值设置为0.6,实验起始节点设置为9,终止节点为16,生成投资项的组合,结合算法3生成的节点序列和节点取值数据见表4。 可根据上述方法生成网络中所有节点路径序列集合,及路径中节点不同取值对应的概率,确定节点之间取值变化趋势的关系,用于指导生成可用于组合投资预测的大数据集。本实验中生成以天为时间单位的365行,16列的2019年的离散数据集,部分数据见表5;生成的离散数据集可确定数据变化的趋势,数据集中每列数据的均值和方差可用来确定生成数据值的范围,可由此进一步生成连续值数据。 表4 部分路径节点取值及概率 表5 生成的离散数据集 将生成的2019年前10个月每月所有的离散数据,与测试集中2019年的10个月真实数据分别进行比较,使用余弦相似度来衡量生成数据与真实数据的接近程度,余弦值越接近1,表示两个向量相似度越高。测试集相似度值如图11所示,从图中可看出,生成数据集与样本数据集相似度均超过70%,基本保留真实数据的事件分布特征。 图11 2019年生成数据相似度 针对当下组合投资预测对数据需求问题,本文提出一个基于增量式贝叶斯网络模型的大数据生成方法。本文涉及时间序列生成算法,可自动批量地对多列时间序列数据进行较准确的生成;构建增量式贝叶斯网络,使得贝叶斯网络可以随着新数据的产生动态更新,便于后续生成长期准确数据;对贝叶斯网络进行路径搜索生成各节点的路径集合,在集合中各个路径节点取值及其对应的概率基础上,生成大数据集。结果表明,大数据生成系统可以生成保持时序性与相关性特征的数据,弥补了实际数据的不足,生成数据可满足组合投资预测研究所需。然而本文在更新贝叶斯网络选取历史数据的方法较为简单,只是选取历史数据最后几项数据;另外,由生成的离散值转换为连续值数据的方法也有待进一步研究。2.2 贝叶斯网络更新算法



2.3 数据生成算法

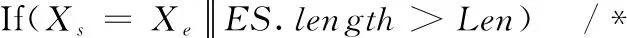
3 实验分析
3.1 实验环境搭建
3.2 实验数据来源和处理


3.3 历史数据模型构建


3.4 新时间序列数据集的生成


3.5 贝叶斯网络的更新


3.6 组合数据及大数据集生成



4 结束语
猜你喜欢
汽车电器(2025年1期)2025-02-03 00:00:00
机械工业标准化与质量(2022年6期)2022-08-12 02:07:42
智能制造(2021年4期)2021-11-04 08:54:36
国际眼科杂志(2021年9期)2021-09-15 03:24:42
河北电力技术(2021年2期)2021-07-29 09:16:24
装备制造技术(2020年2期)2020-12-14 03:09:16
电脑知识与技术(2017年16期)2017-07-14 13:46:17
数理化解题研究(2017年4期)2017-05-04 04:07:54
铁道通信信号(2016年6期)2016-06-01 12:10:20
电子器件(2015年5期)2015-12-29 08:43:15
