
网络入侵检测算法SPCA-ERoF
2021-02-25 09:11:52叶西宁
计算机工程与设计 2021年2期
杨 涛,叶西宁
(华东理工大学 信息科学与工程学院,上海 200237)
0 引 言
随着网络化的不断发展,网络安全变得越来越重要。目前以误用检测[1,2]和异常检测[3-6]为代表的入侵检测方法普遍存在检测率低、误报率高和特征提取率低等不足。为提高入侵检测系统的性能,使其能够利用不断更新的网络数据进行自学习,从而适应新的网络环境,基于机器学习的智能入侵检测系统被提出。
集成分类器[7]是一种组合学习算法,相比单分类器具有更好的泛化能力和对失衡数据集的处理能力,因而成为入侵检测算法的热点研究方向。目前,基于集成学习的入侵检测算法主要采用Adaboost和随机森林两种集成方式,但这两种集成方式存在基分类器强度不足或集成多样性受限问题。在文献[8,9]中提出的基于Adaboost的入侵检测算法,随着集成规模的增加会产生大量坏的基分类器,从而使得集成性能下降;文献[10-12]提出的基于随机森林的入侵检测算法随着集成规模的增长会产生大量冗余基分类器,无法进一步提升集成性能。
鉴于以上原因,本文提出SPCA-ERoF算法用于网络入侵检测。利用SPCA替换传统旋转森林中的PCA旋转作用,提升旋转后数据的可分性;利用增强型旋转森林提升集成模型的多样性和基分类器的强度,从而改善网络入侵检测算法的性能。并结合SMOTE采样,降低数据的不平衡度,进一步提升检测算法的整体性能。
1 监督型主成分分析(SPCA)
主成分分析[13](principal component analysis,PCA)是机器学习领域常见的一种特征提取方法,主要用于数据降维。PCA利用数据方差来表示数据信息量的分布,在保证原始数据信息尽可能少丢失的前提下,用尽可能少的特征维度来表示原始数据信息,从而降低数据维度,减少计算量。传统的PCA是一种线性无监督的变换方式,以总体样本方差为目标函数,依次寻找方差最大的方向,进而达到利用较少的特征维度就能近似表达原始样本信息的目的。这种以整体样本方差最大为目标函数的思想,虽然能够保证原始数据信息量尽可能少的丢失,但在分类问题上却不一定是最好的处理方式。在分类问题中,希望在保证整体样本方差最大的情况下,类内方差尽量小,即希望同类之间具有较好的聚合度,异类之间具有较好的区分度。因此,本文基于传统PCA,引入类内方差惩罚项,使其综合考虑整体样本方差和类内方差。由于改进引入类别信息,故称该算法为监督型主成分分析(supervision principal component analysis,SPCA)。SPCA算法的具体构造如下。
目标函数为
(1)
求w使f(X) 最大,其中X为样本集,Xmean为样本均值,Xinner是由不同类别样本经类内中心化处理后组合而成的类内距离矩阵,w为使f(X) 取得最大的方向向量,即第一主成分,C为惩罚系数。由式(1)可知,要想f(X) 最大,则X-Xmean应尽可能大,CXinner尽可能小。通过调整惩罚系数C可以改变Xinner对整体目标函数的影响程度,即改变类内聚合度对目标函数的影响程度,从而找到最佳w。为保证整体数据信息尽可能少的丢失,整体方差最大依然是最终目标,故CXinner对f(X) 的影响不宜过大,惩罚系数C在[0,1]之间取值,当C=0时SPCA即为传统PCA。
下面以二分类问题为例,阐述Xinner的构造方式。假设样本集X为

(2)
样本集X对应的类标为
y=(0,1,0,1)
(3)
根据类别将样本集X划分成两个样本子集Xy=0和Xy=1, 并进行中心化处理。如式(4)、式(5)所示

(4)

(5)
按照原始样本排序将式(4)与式(5)进行组合,构造类内距离矩阵Xinner
(6)
(7)
根据PCA的求解原理,求解协方差矩阵M的特征值 (λ1≥λ2≥…≥λM≥0) 和对应的特征向量 (V1,V2,…,VM)。 特征值λi从大到小对应的特征向量Vi即为SPCA下方差依次最大的方向。
2 基于SPCA的增强型旋转森林算法(SPCA-ERoF)
2.1 增强型旋转森林算法(ERoF)
集成学习一直是机器学习领域研究的热点问题,其性能较其它分类器而言更为强大,常用的两种集成方式是Bagging和Boosting。影响集成算法性能的两个关键因素在于基分类器的强度和集成多样性,而Bagging和Boosting这两种集成方式均存在明显的不足。Bagging和随机森林虽能够保证基分类器的强度,但集成的多样性受限,其多样性仅来源于样本重采样和决策树节点划分时的随机特征选择。Boosting中以Adaboost为代表的算法则是通过牺牲基分类器强度来获取集成多样性的。Adaboost中每一个新增的基分类器都过分关注错分样本,从而获得丰富的多样性,但使得基分类器性能较弱。
综合考虑以上两种集成方式的优缺点,为保证在不牺牲基分类器性能的前提之下,引入更丰富的集成多样性,文献[14]提出一种新的集成方式——旋转森林[14](rotation forest,RoF)。旋转森林采用决策树作为基分类器,利用决策树对特征轴旋转敏感度高,而其分类性能又基本不受影响的特点,将训练样本通过旋转矩阵旋转至不同的特征空间,增加各基分类器训练样本的差异性,从而使得集成多样性更加丰富。旋转森林的关键在于旋转矩阵的构建,为引入更丰富的多样性,在构建旋转矩阵时,将数据特征集M分成K个不相交的特征子集,对每个特征子集进行重采样和PCA操作,获取特征子集的主成分系数。由于类别差异性大的信息对应的可能是小方差的成分,为保证其不会因方差小而被丢弃,在对每个子集进行PCA时,保留所有的主成分。获取到所有的主成分系数后,按照原始特征顺序对特征系数进行重排,构成旋转矩阵,再利用旋转矩阵对训练样本进行旋转,利用旋转后的样本训练基分类器。与随机森林相比,旋转森林由于在构造每一个基分类器的旋转矩阵时,特征集都是随机划分成K个不相交的子集,并且在对每个特征子集进行主成分分析之前都进行了重采样,所以,每个基分类器的旋转矩阵都不相同,最后得到的基分类器的训练样本差异性相对随机森林基分类器的训练样本差异性更大(随机森林的训练样本差异性仅来源于重采样),从而提高了集成多样性。
基分类器强度是决定集成性能的关键因素之一,虽然旋转森林的引入提升了集成检测模型的集成多样性,但基分类器依旧是弱分类器。而特征轴的旋转虽不会很大程度上影响决策树的分类性能,但还是存在基分类器性能降低的情况。因此,为取得更好的集成性能,本文用强分类器随机森林替换决策树作为旋转森林的基分类器,构建增强型旋转森林(enhanced rotation forest,ERoF)。随机森林是一种组合学习器,即使特征轴的旋转降低了决策树的分类性能,但组合而成的随机森林的分类性能依然很高且比单分类器决策树更好,故保证了在基分类器层面上,ERoF相对于RoF得到了增强。此外,虽然特征轴的旋转对随机森林的分类性能没有影响,但其底层的决策树受旋转作用的影响,故依然可以利用旋转引入多样性。同时,利用随机森林替换决策树可以实现对旋转后的数据再进行一步重采样作用,从而进一步增加多样性。图1为传统旋转森林与增强型旋转森林的对比,其中两算法旋转矩阵的不同将在2.2节介绍。
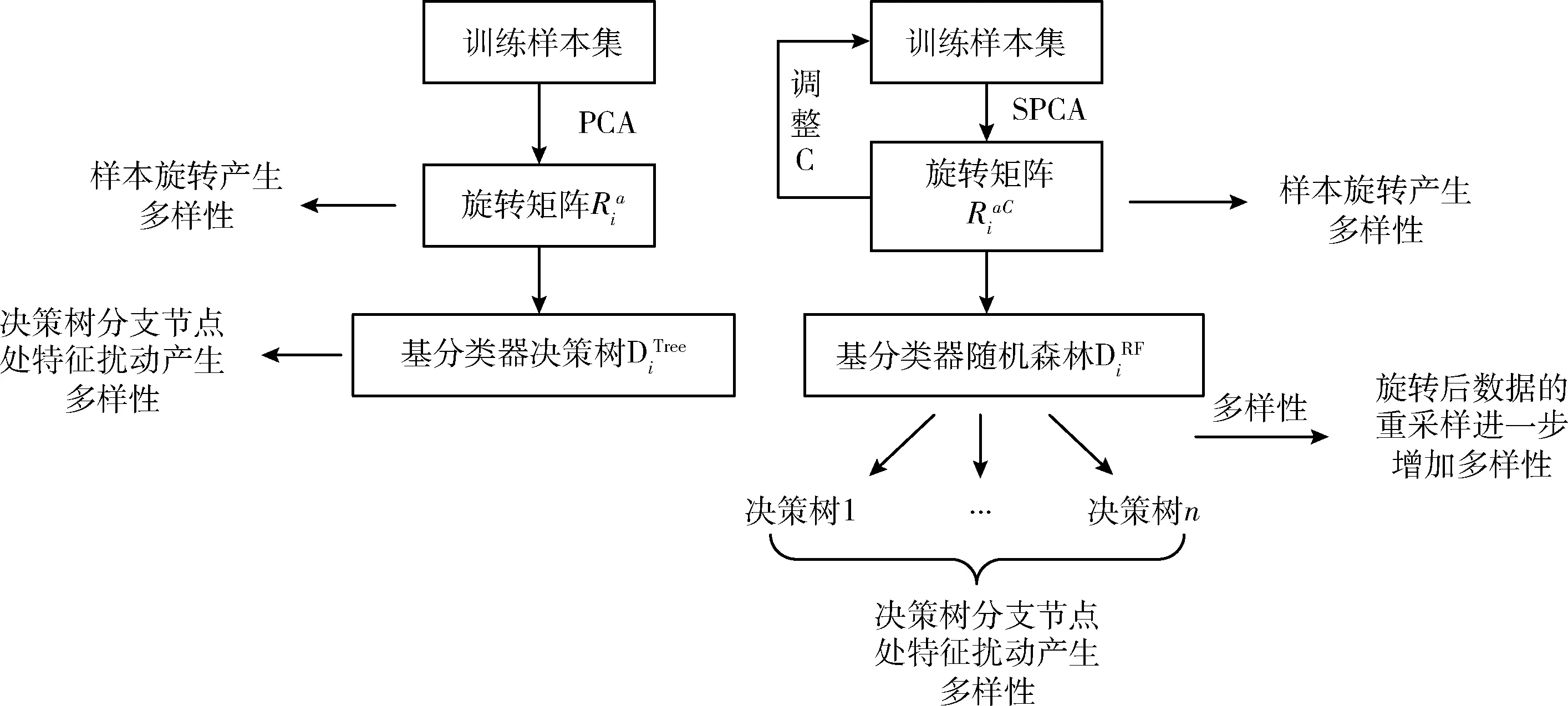
图1 RoF与ERoF的比较
2.2 基于SPCA的旋转矩阵的构造
传统旋转森林所构建的旋转矩阵只能保证作为一种集成多样性的产生方式,并不能保证旋转后的数据具有更好的可分性。针对这个问题,为尽可能保证旋转后数据具有较好的可分性,本文基于PCA基础之上,提出SPCA算法,用SPCA替换PCA对特征子集进行旋转,通过调整SPCA中的惩罚系数C寻找最佳分类效果的特征空间,将原始数据样本旋转至该特征空间中,得到最佳的分类结果。旋转矩阵的具体构造方法如下:
(1)训练数据集X=[x1,x2,…,xn]T为包含n个M维样本的矩阵,Y=[y1,y2,…,yn]T是训练集所对应的类标,其中yi∈{0,1,2,3,4}, 分别对应正常访问和4类攻击方式。 D1RF,D2RF,…,DLRF为L个基分类器。


(4)对每个特征子集都进行步骤(3)操作,得到所有特征的主成分系数,存入系数矩阵Ri
(8)
(5)调整SPCA的惩罚系数C,不断纠正系数矩阵Ri中的主成分系数,寻找旋转后数据可分性最好的特征空间。
按照原始特征顺序对系数矩阵进行重排,得到最终的旋转矩阵RiaC。 将XRiaC作为基分类器DiRF的训练样本。重复以上步骤L次,获取L个基分类器(随机森林)即完成基于SPCA的增强型旋转森林的构造。
2.3 SMOTE过采样
由于入侵方式的复杂化和多样化,导致捕获到的数据样本存在分布严重失衡、样本稀缺问题。大部分样本为正常网络连接数据,部分入侵数据样本稀缺。传统的机器学习算法大都以准确率为目标,在面对分布严重失衡的数据集时往往更偏向于强势类样本,导致弱势类样本错分率较高。而对于入侵检测系统而言,更多的是希望系统对入侵行为具有很好的识别性。失衡样本的处理一直以来都是机器学习领域所研究的重点问题,目前,解决这类问题的方案主要有两个:①重构数据集分布,降低不平衡程度;②设计或改进学习算法,改变传统方法在解决不平衡数据集分类问题时的缺陷[15]。考虑网络入侵数据集中U2R类入侵样本仅有52个,相对其它类别样本实在太少,模型无法学习到足够的该类样本信息,故本文采用第一类非平衡处理方法,利用经典的SMOTE过采样算法对数据分布进行重构,降低数据集的不平衡度。
3 算法步骤与流程图
训练部分:令X=[x1,x2,…,xn]T为训练样本集,包含n个M维网络连接样本。
(2)对训练集X按特征子集进行抽取,获取K个由特征子集所表示的样本子集Xi, 并对每个样本子集Xi进行重采样,采集原始训练样本数75%的样本构成新的训练样本集X′i。
(3)对每个样本子集X′i进行SPCA分析,得到M个主成分系数,存入矩阵Ri中。
(4)调整惩罚系数C,不断纠正旋转矩阵Ri中的主成分系数。
(5)按照原数据集特征顺序对矩阵Ri进行重排得到最终旋转矩阵RiaC。
(6)对原始训练集X进行过采样降低数据不平衡度,得Xover。
(7)用XoverRiaC为训练样本训练基分类器DiRF。
(8)重复进行上述步骤L次得到L个基分类器。
测试部分:
(1)获取第i个基分类器的旋转矩阵RiaC, 对某个未知样本进行旋转,得xRiaC。
(2)获取第i个基分类器,对xRiaC进行预测,假设预测结果为yij,yij表示第i个分类器预测x为第j类样本。
(3)重复进行上述步骤L次,得L个预测结果,通过投票法确定样本x的类别。
算法流程如图2所示。

图2 算法训练过程流程
4 实验结果与分析
4.1 SPCA实验分析
SPCA是基于PCA基础之上,为提升数据旋转后的可分性而提出的一种监督型主成分分析算法,其中惩罚系数C是算法中的一个超参数。针对不同的数据集分布,惩罚系数C的取值不同。为验证SPCA的可行性,本文选用UCI机器学习数据库的Breast-cancer、Digits、Iris、Ionosphere、Bupa(肝病)、Glass、Banknote、Dermatology、Cmc(避孕方法的选择)、Poker-hand这10个数据集进行验证。表1为10个数据集的描述信息。
为保证实验的可信度,所选的10个数据集同时包含二分类与多分类问题以及高维数据与低维数据问题。此外,考虑本实验重在研究SPCA相对PCA旋转作用的优越性,因此,在实验过程中保留所有主成分,只对数据做旋转作用。表2为SPCA和PCA旋转森林在10组数据集上的分类结果,结果为5倍交叉验证取均值所得。每行加粗数据为两种方法中取得的最好结果,对比指标为Accuracy。
由表2可知:10组数据集的SPCA与PCA旋转森林的实验结果中,有8组数据集在SPCA下通过调整惩罚系数C获得了比PCA更好的结果,只有一组数据在PCA旋转作用下获得最好的分类效果。这说明,数据集方差最大的方向并不一定就是数据可分性最好的方向,类内方差惩罚项的引入,能够在一定程度上纠正最大方差方向,增加数据可分性。当C=0时,SPCA即为PCA,实验中超参数C可以通过网格搜索方式进行确定。

表1 数据集描述

表2 SPCA/PCA旋转森林实验结果(Accuracy)
4.2 基于SPCA-ERoF的网络入侵检测实验结果与分析
4.2.1 数据集
本次实验采用UCI机器学习数据库中10%的KDD-CUP99网络入侵检测数据集。该数据集共有494 021条网络连接数据,包含Dos、Probing、U2R、R2L这4种入侵类和Normal正常类。由于数据集过于庞大,Normal和Dos两类样本中存在过多冗余样本,故实验时这两类样本只取10%用于实验。表3为抽取前后各类样本数据量。

表3 样本分布
4.2.2 实验数据预处理
网络入侵数据的41维特征中包含标称型特征和连续型特征,标称型特征无法参与算法运算过程,故将其转换成数值型特征。同时,为消除因特征的量纲不同所带来取值上的差异,对连续型特征进行标准化处理,使各特征之间数据具有可比性。
4.2.3 评价标准
对于入侵检测算法而言,既需要考虑算法的检测率,也需要考虑算法的误报率。故实验中需要考虑模型精确率P、召回率R和F1_Score这3个评价指标。计算方法如式(9)~式(11)所示。精确率反映模型的误报情况,P越大误报率越低;召回率反映模型的检测情况,召回率越高检测率越高;F1_Score度量模型的综合能力
(9)
(10)
(11)
上述公式中:TP(true positives)为真阳率,FP(false positives)为假阳率,TN(true negative)为真阴率,FN(false negative)为假阴率。
4.2.4 实验结果分析
本文重在研究集成入侵检测算法问题,首次将旋转森林算法应用到入侵检测系统中,同时对其进行改进,提出基于SPCA的增强型旋转森林网络入侵检测算法(SPCA-ERoF)。为验证该集成模型在入侵检测中的优越性,本文将与目前具有代表性的其它集成模型进行对比,如随机森林算法(random forest,RF)、SMOTE-RF算法、代价敏感随机森林算法(cost-sensitive random forest,Cost-RF)、Adaboost算法[9]。实验结果为10次实验的平均值,对比结果见表4~表6。
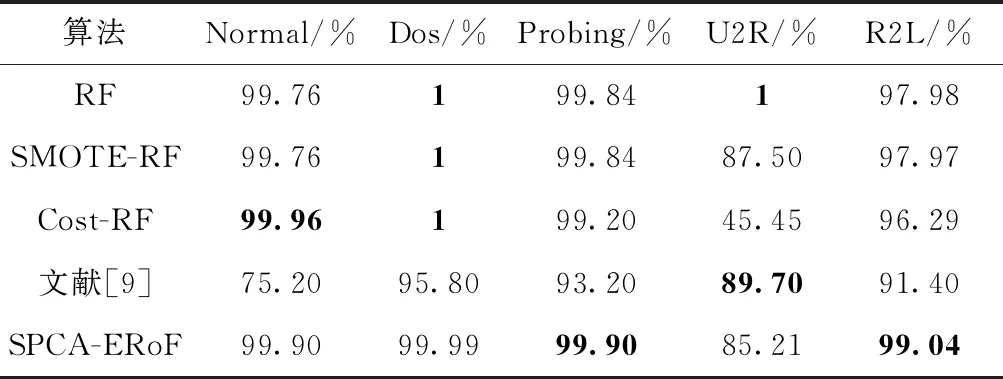
表4 入侵检测精确率

表5 入侵检测召回率
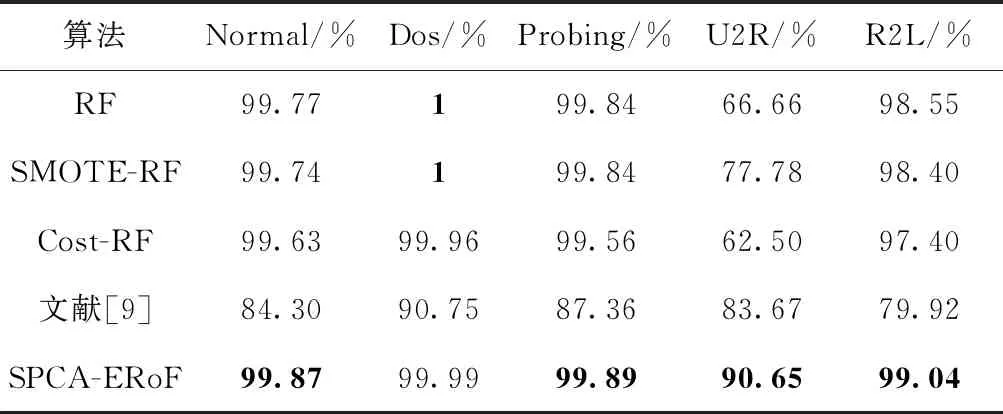
表6 入侵检测F1_Score
由表4~表6可知,由于Normal、Dos和Probing这3类样本较多,5种检测模型均能学习到较丰富的类别信息,故5种模型在这3类样本上的检测效果均表现良好。相反,对于U2R和R2L这两类稀缺样本而言,5种检测模型的性能差异较为明显,尤其是U2R攻击。这符合检测模型的建立目标,即检测模型对新型攻击亦能拥有较好的检测率(新型攻击往往样本稀缺,甚至缺乏样本)。因此,后面将从U2R类攻击样本的精确率、召回率和F1_Score这3项指标对5种检测模型进行分析。
首先,由表6中模型综合性能评价指标F1_Score的实验结果可知,本文所提出的基于SPCA的增强型旋转森林网络入侵检测模型较其它集成检测模型而言具有更好的检测性能。该算法在正常类、Probing攻击、U2R攻击和R2L攻击4类样本上均取得最佳分类效果,分别为99.87%、99.89%、90.65%和99.04%,在Dos攻击上的检测效果仅次于RF检测模型和SMOTE-RF检测模型,仅相差0.01%。其次,结合表4和表5中RF、SMOTE-RF和Cost-RF这3个检测模型在U2R攻击上的精确率和召回率可知,SMOTE采样对提升稀缺样本的检测性能具有十分重要的意义。SMOTE-RF模型比RF模型在U2R上的检测率提升了20%,且依旧能保持较高的精确率;Cost-RF模型虽未进行采样操作就能在U2R攻击上获得100%的检测率,但其误报率太高,达到了54.55%。因此,为提升模型对稀缺样本的综合检测性能,SMOTE采样必不可少。最后,SMOTE-RF和SPCA-ERoF两检测模型在均进行采样前提下,SPCA-ERoF相比SMOTE-RF在U2R上的召回率 R提升了20%,综合性能指标F1_Score提升了12.87%,具有明显提升效果。综上所述,实验结果表明了本文提出的SPCA-ERoF算法能有效提升入侵检测系统性能。
4.2.5 实验参数分析
在本文提出的模型中,影响结果的超参数较多,包括决策树中各项参数、SMOTE采样和SPCA惩罚系数C等。此处重在分析SMOTE采样和惩罚系数C对检测模型的影响,决策树中各项参数可根据随机森林入侵检测模型的经验进行设置。利用控制变量法分别分析两参数对模型的影响。此外,本文提出的检测模型在Normal、Dos、Probing和R2L这4类样本上的综合性能指标F1_Score均能达到99%左右,且变化很小,故此处以U2R的F1_Score作为分析指标。图3为U2R的F1_Score在不同惩罚系数C下与SMOTE采样量的关系图。图中每条折线为惩罚系数C固定,U2R的综合性能指标F1_Score与SMOTE采样之间的关系;每一纵向上的6个不同颜色不同形状的点为SMOTE采样固定,U2R综合性能指标F1_Score与惩罚系数C之间的关系。

图3 F1_Score与C的关系
由图3可知:当U2R的采样小于200时,惩罚系数C对模型性能的影响较大,此时,当C=0时SPCA即为传统PCA,U2R的分类效果最差;当采样大于200时C对模型的影响变小,每一纵行的6个不同颜色不同形状的点更加聚拢;当采样为200,惩罚系数C=0.8时,检测算法取得最佳检测性能,F1_Score=90.65%。此外,当采样小于200时,随着采样的增加,检测算法性能整体呈上升趋势且上升幅度较为明显;当采样大于200时,检测算法性能整体呈下降趋势。通过分析可知,过采样虽然能使检测算法学习到更多该类样本的信息,但随着采样量的增加,将会产生噪声样本,噪声样本的产生会使检测算法整体性能下降,而且随着采样的增多,噪声样本也会越多,算法性能也会越差。
5 结束语
针对随机森林和Adaboost两种集成方式在入侵检测应用中存在的不足之处,本文将旋转森林算法用于构建入侵检测系统,提出了SPCA-ERoF算法。针对旋转森林算法在PCA旋转作用时无法保证数据在旋转后的特征空间具有更好的可分性的问题,提出SPCA算法,提升旋转数据可分性。为进一步提升旋转森林集成方式的整体性能,采用随机森林作为基分类器对旋转森林算法进行增强,既可以利用决策树的特性引入更丰富的集成多样性,又可以提升基分类器的强度。实验结果表明,与其它集成网络入侵检测算法的性能相比,基于SPCA-ERoF的网络入侵检测算法的性能具有明显提升,该方法为后期集成入侵检测算法的研究提供了一个新的方向。
猜你喜欢
电子测试(2018年1期)2018-04-18 11:52:35
作文大王·笑话大王(2017年1期)2017-02-21 16:08:53
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
作文大王·笑话大王(2016年10期)2016-10-18 14:58:58
作文大王·笑话大王(2016年7期)2016-08-08 11:28:43
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
作文大王·笑话大王(2016年2期)2016-02-24 11:27:15
南都周刊(2015年4期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
