
能量高效的WSNs分簇路由协议
2021-02-25 09:11王宗山丁洪伟李艾珊
计算机工程与设计 2021年2期
王宗山,丁洪伟+,李 波,李 浩,李艾珊
(1.云南大学 信息学院,云南 昆明 650500;2.复旦大学 电子信息科学与技术,上海 200433)
0 引 言
随着无线通信技术的发展,无线传感器网络(wireless sensor networks,WSNs)得到了越来越广泛的关注,WSNs通常用于监测指定区域的环境[1],但传感器节点能量有限且无法更换电池。因此,设计一种高效节能的路由算法尤为重要[2-4]。Heinzelman W等提出的经典分簇路由协议LEACH[5],通过周期性轮换簇首平衡网络能耗,提高网络性能。但LEACH随机选取簇首导致分簇不理想,缩短了网络生命周期。文献[6]对LEACH进行改进,提出QABC算法,算法考虑节点的能量与地理位置提出适应度函数,采用量子人工蜂群算法确定最优解作为簇首,从而形成网络分簇。QABC算法使簇首分布更均匀,成簇更合理,进一步提升了网络性能。文献[7]提出HEED算法。依据节点的剩余能量,迭代选取能量较高的节点作为簇首,保证簇首分布均匀。文献[8]提出PROPOSED协议,采用“先聚类分簇,后选举簇首”的方式,首先采用粒子群算法分割网络区域,然后在每个区域内选举簇首。文献[9]在非均匀聚类的基础上引入多跳,通过合理的方式选择中继节点,有效均衡了网络能耗。文献[10]引入模糊规则,结合节点的剩余能量和位置信息提出FLECR算法。文献[11]引入“网格”概念,并考虑节点剩余能量完成簇首选举,显著提升了网络生存期。文献[12]引入蚁群算法,结合节点的地理位置和剩余能量,提出一种基于蚁群的新路由算法。文献[13]提出基于K-Means的均匀分簇路由(KUCR)算法,在网络初始化时期利用K-Means分簇,在每个簇内考虑节点位置坐标和剩余能量选举簇首。文献[14]提出基于Fuzzy C-Means的改进LEACH协议,初始阶段利用Fuzzy C-Means对网络节点聚类分簇,在每个簇内利用考虑节点剩余能量的LEACH算法完成簇首选举和数据传输。
本文将遗传算法(GA)优化的K-Medoids聚类用于WSNs,提出了能量高效的均匀分簇路由协议—GAKMDCR协议,通过选举高质量簇首、改善通信机制的方式,在均衡网络能耗的同时,提高了网络吞吐量。
1 网络模型
1.1 网络模型
假设所研究的WSNs具有以下性质:
(1)监测区域内的N个节点同构且固定,基站位于无线传感网内部;
(2)所有节点均具备身份标识(ID),且各不相同;
(3)任意节点能够根据接收到的信号强度计算与发送端的距离,能够感知自身剩余能量、计算自成为簇首的轮数;
(4)任意节点能够直接与基站通信,能够进行数据去冗处理,具备担任簇首的能力;
(5)网络部署完成后,再无人为干涉。
1.2 能耗模型
本文采用的无线电能量模型与Heinzelman等讨论的模型相同[15]。图1是该模型传输数据的基本流程。如图1所示,根据发射端到接收端的距离与阈值dinit的大小关系,选择性使用自由空间信道模型和多路径衰减模型。节点发送数据所需能量的数学表达式为[16,17]

(1)
(2)
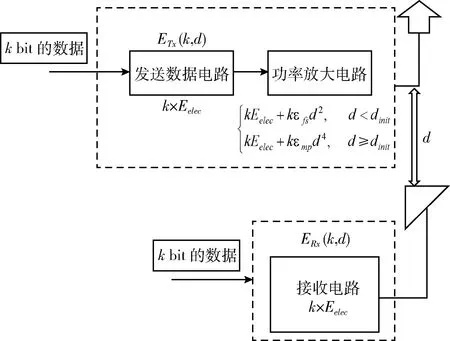
图1 数据传输过程与能量消耗
节点接收数据所需能量的数学表达式为
ERX=k×Eelec
(3)
其中,d为无线电的传输距离,k是传输的比特数,Eelec是无线通信的发送端/接收端每发送/接收1比特数据所需要的能量。εfs和εmp为两种信道模型中功率放大电路的能量耗散系数。
2 GAKMDCR算法
GAKMDCR算法中,网络按轮运行。网络初始化时期,基站根据节点的地理位置,采用遗传算法优化的K-Medoids迭代计算,形成h个固定的分簇。首轮簇首由簇内中心点担任。此后每轮,由当前簇首综合考虑簇内节点状态决定是否更换簇首,如需更换,指定条件最优的节点成为下轮簇首。这样就避免了因频繁更换簇首带来的能量消耗,有效延长了网络生命周期。
2.1 簇的构建
2.1.1 最优簇数
K-Medoids需要指定分簇数目,基于上述网络型和能耗模型,网络运行一轮消耗的能量为[18-20]

(4)
其中,DtoBS为节点到基站的距离,EDA为簇首融合1 bit冗余数据带来的能耗。
对聚类数h求偏导,令偏导数为零,可求得使网络能耗最低的h。求得的最优簇数为
(5)
2.1.2 K-Medoids聚类算法
K-Medoids聚类算法是一种基于代表对象的划分方法,用绝对误差标准来定义一个类簇的紧凑程度[21]。每次迭代后选取簇内的实际样本点作为聚类中心,解决了K-Means算法对“噪声”敏感的问题。绝对误差公式为
(6)
其中,p为ci簇中的样本点,oi为ci簇的中心点。基于K-Medoids的成簇步骤见表1。
2.1.3 遗传算法优化K-Medoids初始中心点
K-Medoids虽然解决了K-Means算法对噪声数据和孤立点敏感的问题,但其性能仍受初始中心点的影响,易陷入局部最优解。为解决这一问题,用遗传算法改善K-Me-doids的初始中心点,提高聚类质量。遗传算法优化K-Me-doids的步骤[22,23]为:

表1 基于K-Medoids的成簇步骤
(1)初始化参数(种群数目p、聚类数目h、交叉概率pc、变异概率pm、最大迭代次数);
(2)初始化种群,每个个体编码代表一种聚类结果;
(3)对个体进行K-Medoids迭代计算并评价适应度;
(4)进行遗传算法中的相应操作,产生新一代种群,判断是否可以终止迭代;
(5)如果可以终止迭代,输出K-Medoids的初始中心点。否则,转至步骤(3)。
其中,适应度函数设计为
(7)
(8)
其中,Jc为类内距离,zij为第i条染色体所表示的第j个聚类cj的中心点,p为cj中的其余点。从式(7)可以看出,类内紧凑程度越大,类内距离Jc的值就越小,适应度也越大。这样保证了一个聚类结果的适应度越大,聚类效果越理想。编码方式与文献[24]相同,从{1,2,…h…,n-1,n}中随机选取一组值α={α1,…αi…αq}代表一条染色体,αi代表一个聚类中心点,α中元素的个数代表聚类数目。
2.2 簇首选举
成簇之后,首轮簇首由簇内中心点担任。从第二轮开始,当前簇首基于节点剩余能量、到基站的距离、与簇内其余节点的紧凑程度、担任过簇首的轮次4个因素决定是否需要更新簇首,若需要,则指定条件最优的节点担任下轮簇首。
节点的剩余能量因素设计为
(9)
式中:f1(i)表示在当前轮次,节点i的能量值比上该节点所在第j簇的平均能量值。f1(i)与节点i的当前能量值成正比,f1(i)越大,表示节点i在当前轮次的能量值越高。
网络节点与基站的位置关系因素设计为
(10)
其中,dtoBS(i)为节点i到基站的距离,dtoBS(max)为节点i所在簇内,任意节点到基站距离的最大值。比值f2(i)越大,表示节点i距离基站越近,与基站通信时的能量消耗越小。
与簇内其余节点的紧凑程度因素设计为
(11)
其中,dtoCH(i)为节点i到簇首的距离,dtoCH(ave)为节点i所在簇内所有节点到簇首的平均距离。当前簇首的dtoCH取值为dtoCH(ave)。这样设计的好处是:当前簇首由上轮簇首综合考虑后选定,这就意味着当前簇首与簇内其余节点的紧凑程度比较理想。利用到当前簇首的距离作为评判标准,可以有效衡量各节点与簇内其余节点的紧凑程度。比值f3(i)越大,节点i与簇内其余节点相对更紧凑。
担任过簇首节点的轮次因素设计为
(12)
其中,rtotal表示网络运行过的轮数,rCH(i)表示节点i担任簇首的轮数。担任簇首次数越多,比值f4(i)越小,则节点i再次当选簇首的概率相对较小。这样很好的将网络能耗分摊到每一个节点
f=αf1+βf2+λf3+μf4
(13)
其中,α、β、λ、μ为权重参数,用于调整4个因素的重要程度,且满足和为1。随着网络的运行,根据4个因素对网络影响力的改变动态调整权重参数,以选出最优簇首。权重参数的更新公式设计为
α=(Emax-Emin)/(Eres(i))
(14)
β=λ=μ=(1-α)/3
(15)
其中,Eres(i)为节点i的剩余能量,Emax和Emin分别为节点i所在簇内任意节点剩余能量的最大和最小值。这样设计的好处是:网络不断运行,节点剩余能量因素愈加重要,节点的剩余能量不断减少,得到的α值动态增大,即能量因素越来越重要。同时,簇内节点的剩余能量两极分化越严重,对应式(14)中的分子越大,该簇节点得到的α值也越大,能量因素在该簇的簇首选举中所占比重更大。这样就避免了能量消耗集中于部分节点使网络生存期减短。
每轮的最后阶段,簇首根据节点发来的位置坐标、剩余能量和担任簇首的轮数,按式(13)计算其参量值f,并选出f值最大的节点i,乘以网络系数θ后与自身参量值作比较
fCH≤θfmax(i),θ∈(0,1]
(16)
若式(16)成立,簇首指定节点i成为下轮簇首,否则,不更新簇首。相比于每轮更新簇首,这种方式避免了频繁更新簇首带来的能耗,延长了网络生存期。网络系数θ影响簇首更新的速度。θ取值过大则簇首更换频繁,加大了网络能耗。θ取值过小则簇首更新慢,导致小部分节点因长期担任簇首过早死亡。
2.3 数据传输
2.3.1 选择通信对象
簇首更新之后,新簇首根据簇内成员节点的位置坐标计算其到基站的距离dtoBS和到簇首的距离dtoCH,并按式(17)进行比较
dtoBS(i) (17) 若式(17)成立,则节点i在当前轮次直接与基站通信,簇首将节点i从轮询表中删除(本文算法的簇内通信采用轮询机制),后面节点的轮询顺序依次前移。这样通过缩短通信距离有效减少了数据传输带来的能耗。 2.3.2 通信机制 大多数WSNs分簇路由协议中,簇内节点采集信息后,采用时分多址(TDMA)机制将信息发送给本簇簇首[25]。节点根据簇首建立的TDMA时隙表工作或休眠。簇内成员节点在自己的时隙被唤醒,打开发射器,与簇首通信。如果有节点在一段时间内没有采集到有效数据,那么簇首节点分配给该节点的时隙被浪费,并且带来不必要的能量消耗。针对这一问题,本文算法的簇内通信机制采用轮询机制[26,27]。每轮由簇首根据簇内节点信息建立轮询表,节点轮流接受服务。当节点能量耗尽、直接与基站通信或处于休眠状态时,簇首将其从轮询表中删除,后面节点的轮询顺序依次前移。一个轮询周期结束后,簇首对采集到的数据进行去冗,并单跳发至基站。这样就解决了时隙被浪费的问题,并且有效避免了簇内节点被不必要地唤醒,从而减少了网络能耗,并显著提高了网络吞吐量。 GAKMDCR算法流程如图2所示。 图2 GAKMDCR算法流程 本文在MATLAB R2014b上对LEACH算法、KUCR算法(参考文献[13]算法)、基于Fuzzy C-Means聚类的改进LEACH算法(参考文献[14]算法,下文称改进的LEACH算法)、GAKMDCR算法进行仿真实验,并对4种算法的成簇效果、能量均衡性、网络生命周期和网络吞吐量进行了对比。仿真参数[28]见表2。其中,遗传算法参数设计为[29]:种群大小为50,交叉概率pc=0.25,变异概率pm=0.05,最大迭代次数T=110。 LEACH算法、改进的LEACH算法、KUCR算法和本文算法的成簇对比如图3所示。传统的LEACH算法随机选举簇首成簇,簇的大小和簇首分布不均匀。KUCR采用K-Means形成网络分簇,簇首分布较为均匀,但K-Means性能受初始聚类中心影响,导致簇的大小不均匀。改进的LEACH算法采用FCM对监测区域进行分割,每个区域内的节点即为一簇,但FCM同样受初始聚类中心选取的影响,簇的大小也不均匀。本文算法用K-Medoids对网络节点聚类分簇,并采用遗传算法优化初始中心点。通过图3可以看出,本文算法簇首分布合理,簇的大小均匀,成簇效果理想。 表2 仿真参数 图3 成簇结果对比 LEACH算法、改进的LEACH算法、KUCR算法和本文算法生命周期的比较。表3统计了不同个数的节点死亡出现的轮数,图4是4种算法生命周期的对比,图5统计了死亡不同比例节点对应的轮数。可以看出,从网络初期到最后,本文算法的存活节点数始终多余其它3种算法,这得益于本文算法成簇效果理想,簇首更换机制合理,有效延长了网络生存期。 表3 不同死亡节点占比出现的轮数 LEACH算法、改进的LEACH算法、KUCR算法和本文算法网络能耗的对比。图6横坐标为网络运行的轮数,纵坐标为网络剩余能量,可以看出,本文算法的网络剩余能量始终高于其它3种算法,这得益于本文算法分簇理想,网络能耗均衡。 LEACH算法、改进的LEACH算法、KUCR算法和本文算法吞吐量的对比。图7横坐标为网络运行的轮数,纵坐标为基站接收到的数据包个数,可以看出,由于本文算法的生命周期更长,基站最终成功接收到的数据远多于其它3种算法。在网络初期,本文算法的吞吐量也有很大优势,这得益于簇内通信阶段,本文算法用轮询机制替换了其余3种算法的TDMA机制,有效解决了时隙利用不充分的问题。 图4 生命周期对比 图5 死亡节点数对比 图6 网络剩余能量对比 图7 网络吞吐量对比 本文提出一种基于遗传算法和K-Medoids聚类的分簇路由算法,初始阶段利用遗传算法优化的K-Medoids对网络节点聚类分簇,综合考虑节点的多种因素进行簇首更新,数据传输阶段,节点根据通信距离选择最佳通信对象,簇内通信引入轮询机制。仿真结果表明,相比于LEACH、KUCR、改进的LEACH算法,本文算法能耗均衡性更优,显著延长了网络生命周期,提高了网络吞吐量。
3 算法仿真及性能分析
3.1 仿真环境
3.2 仿真实验一

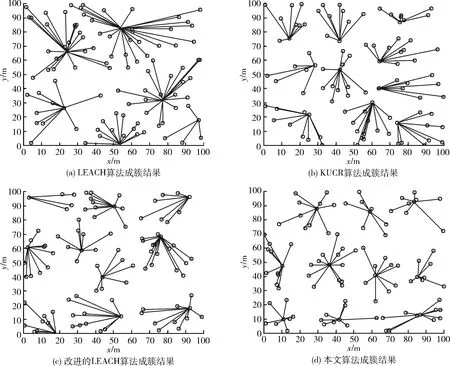
3.3 仿真实验二

3.4 仿真实验三
3.5 仿真实验四
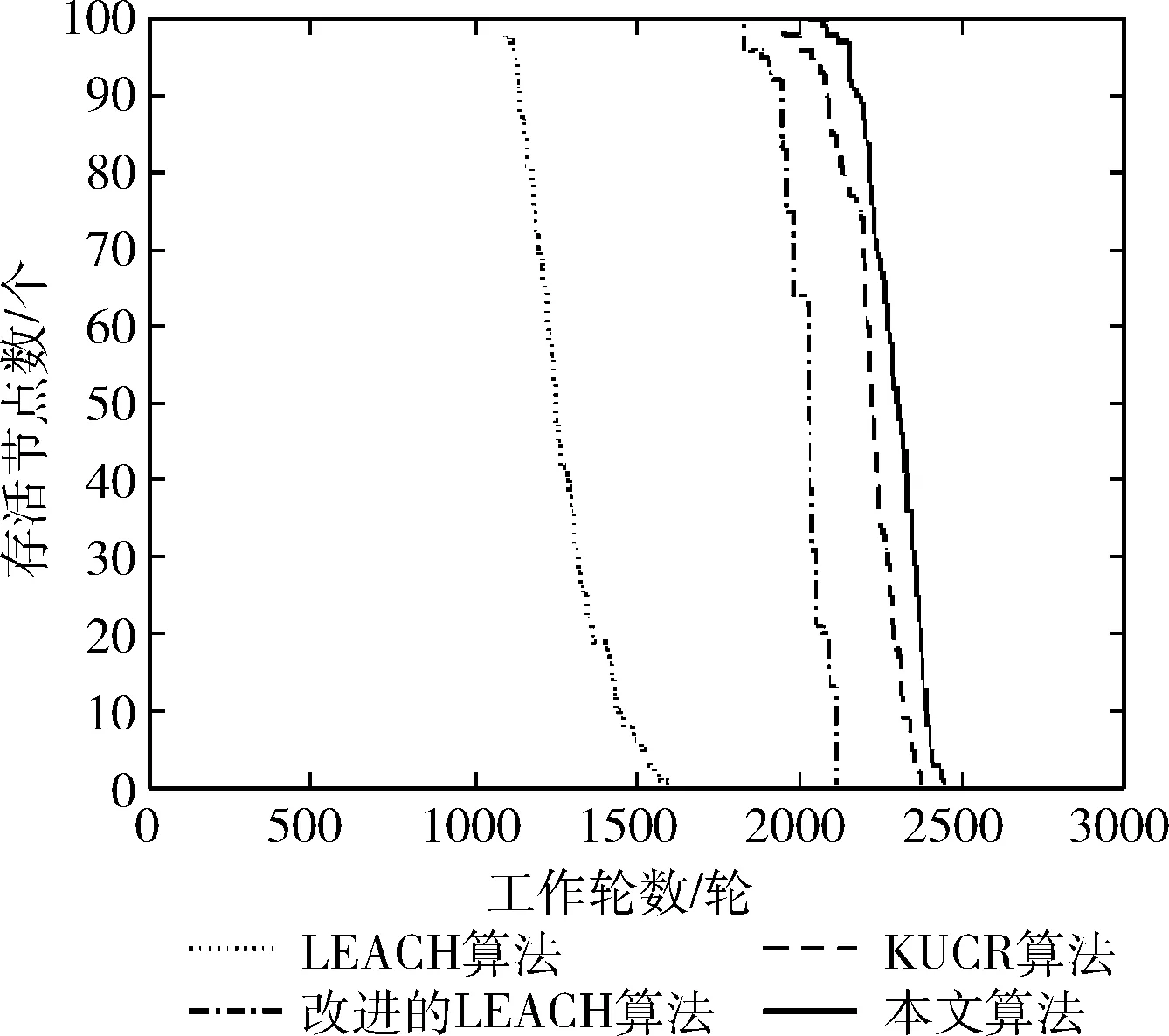



4 结束语
猜你喜欢
计算机与数字工程(2019年2期)2019-02-28
石油地球物理勘探(2017年2期)2017-11-23
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
电子制作(2017年8期)2017-06-05
探索科学(2017年4期)2017-05-04
统计与决策(2017年2期)2017-03-20
中国交通信息化(2016年8期)2016-06-06
自动化学报(2016年8期)2016-04-16
火控雷达技术(2016年1期)2016-02-06
智能系统学报(2015年4期)2015-12-27
