
异构去中心化存储中的LRC-RS混合编码
2021-02-25 09:11:16胡金平李贵洋江小玉韩鸿宇
计算机工程与设计 2021年2期
胡金平,李贵洋,李 慧,江小玉,韩鸿宇
(四川师范大学 计算机科学学院,四川 成都 610101)
0 引 言
Inkwood研究表示,全球云存储市场规模在2019-2027期间预计将以20.31%的复合年均增长率增长[1]。目前存储系统可按网络结构分为中心化存储和去中心化存储[2,3]。前者数据易泄露、价格相对昂贵;后者利用区块链[4]等技术解决了安全、可信、可控的存储要求。在这些系统内,纠删码[5,6]得到了应用。
常用的纠删码有RS码[7,8]、局部修复编码(LRC)[9,10]等。RS编码满足MDS[11]性质,能达到最高容错能力;LRC通过减少磁盘I/O来降低修复带宽。它们都运用在了中心化存储系统中,然而去中心化环境中仅使用了低码率的RS码,如Storj中RS(40,20)[12]、Sia中RS(30,10)[13]。其原因在于两者环境的差异:中心化存储内是性能优、稳定且可信的节点;而去中心化存储中却是性能和可靠不定的节点(拜占庭攻击[14])。
在去中心化存储中,RS码的可靠性基于所有节点不可信。然而实际的环境中,存在部分节点可信,这些节点将RS码可靠性提升到了规定之上,侧面体现出低码率编码浪费了可靠节点的资源。为合理利用可信节点的资源,可适当降低编码的可靠性,让改变后的编码可靠性处于在采用RS编码时所有节点不可信和部分节点可信的可靠性之间。基于此,提出了去中心化存储中基于可信度的LRC-RS混合编码。实验结果表明,在同等的冗余度下,LRC-RS能有效地降低修复带宽。
1 相关理论基础
1.1 定 义
首先是相关性质定义:
性质1 将原始数据分为等大小的k份,进行编码产生n-k个校验,将数据扩大到n份并存储到不同的n个节点上。任何k份数据都能恢复全部的n个节点中的数据。称这种性质为MDS性质。
定义1 纠删码(Erasure coding,EC):起源于通信传输领域,后逐渐应用到存储系统中。它把数据分割成片段并对这些片段进行编码,然后编码后的数据存储到不同位置的节点中。具有高磁盘利用率和高数据可靠性的优点。
定义2 一个码的第i位具有局部性r(localityr),则说明该位上的值可以通过读取码的其它不超过r个位上的值来修复。
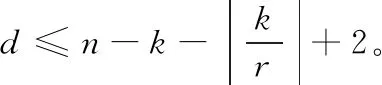
定义4 失效率(LR)是对数据编码后,数据失效的概率。

其次给出参数列表,方便后续讨论。见表1。

表1 参数
1.2 RS码
RS码[15]是经典的MDS码。一个(n,k)的RS线性码,在给定的有限域中,能纠正n-k=2t个已知错误。其中k是原始数据的总数,t代表纠正未知错误的个数。
MT=(m1,m2,…,mk)、GT= [gj,i](0 (1) 解码时,因RS的MDS性质,W中任意的k行都能恢复所有原始数据。若wf失效,应有 (2) (3) 校验节点丢失后下载原始数据,重新计算校验。 为了减少纠删码中的磁盘I/O开销,由Papailiopoulos等[16]分别提出局部修复编码(locally repairable codes),简称LRC,具体定义如定义1所示,使用符号集(n,k,r)表示。当r较小时,帮助节点的访问量也较小,从而修复带宽和磁盘I/O也较小。LRC码是构建在RS之上来减少节点访问量的编码。Gopalan等指出C Huang等[17]提出的金字塔码达到了其界限(定义3)。2012年,C Huang将金字塔码大规模运用于微软的Azure 云中[18],节省了大量的带宽资源。文中使用(n,k,l)的符号集来表示LRC。 图1为一般的局部修复码LRC(12,8,2)的结构。将8个数据块用RS编码得到2个校验p1,p2,称其为全局校验块(global parity block),分别包含了所有8个原始数据块的信息。接着将数据分为m1,…,m4和m5,…,m8两组,由分组m1~4的数据节点产生校验块lp1,1,由分组m5~8的数据节点产生校验块lp1,2,称由部分原始数据产生的校验为局部校验块(local parity block)。在生成lp1,1时,将m5~8前的系数置为0,得到的校验就是关于m1~4的;lp1,2同理。按照上诉方法,得到LRC(12,8,2)。易看出局部校验只添加在数据节点之上。 图1 Locally Repairable Codes的结构 文献[19]中给出了利用马尔科夫模型计算编码可靠性的方法。通过计算编码的平均失效时间(MTTF),从而知道该参数下编码的可靠性。该文章指出节点的失效和修复均服从指数分布,与此同时又给出了利用马尔科夫模型来计算编码的可靠性的方法。该模型规定可用节点的数量由马尔科夫链中的每个状态决定,其中λ为单个节点失效的概率,ρ为单个节点被修复的概率,得到编码的可靠性为 (4) 式中:n1,j为矩阵N中的元素,其中N=(I-Q)-1。I为单位矩阵、Q为转移矩阵P去掉吸收状态的行和列后的子矩阵。转移矩阵P是关于λ和ρ的矩阵 式中:εi=iλ+ρi。 2.1.1 节点特征 去中心化存储系统因环境的异构性,将节点分为高可信节点和低可信节点。其特点是:高可信节点能够提供高效服务;低可信节点不能提供稳定的服务。去中心化存储系统中的每个节点都有自身的信用元数据信息,如通过历史数据分析节点的在线时长、能提供的网络带宽大小、恶意攻击次数、节点的提供方等。系统根据这些特点综合考虑,给予不同的权重,求出编码的可信度,根据这个值,将节点分为低可信节点和高可信节点。为适应所有节点,立即修复和延迟修复是常用的两种修复方式[21]。其中立即修复用于高可信度节点,因为其可信任,需要马上修复;延迟修复适用于低可信度节点,因为该类节点具有不确定性。特别是低可靠节点,在不影响系统冗余度的情况下,只要在规定的阈值期间能重新上线,都认为该节点上的数据没有丢失。 2.1.2 可信节点数量 在RS码的某个可靠性下,去中心化存储系统中存在部分高可信节点和部分低可信节点。混合编码是对高可信节点使用LRC,低可信度节点使用RS编码,因此需要找到高可信度节点和低可信度节点的数量。 (5) 图2 可信节点弹性变化的编码架构 2.2.1 编码结构 2.2.2 编码过程 (6) (7) 例子:LRC-RS(40,20,23,14,2)。其包含23个高可信节点和17个低可信节点。形成了LRC(23,14,2)和RS(17,6)的混合编码。LRC中有23个节点,其中有14个系统节点{m1,m2,…,m14},2个局部校验{lp1,2,lp2,1}、7个全局校验{p1~7},按照式(6)和式(1)编码,其中lpi,j=ci,j。剩下的17个低可信节点使用RS(17,6)编码,将6个数据节点进行RS编码得到17个数据。如图3所示。对于高可信节点而言,需先按照RS(21,14)编码产生全局校验。然后将全局校验p1和p2拆分,即p1=lp1,1+lp1,2、p2=lp2,1+lp2,2。 图3 混合编码LRC-RS(40,20,23,14,2)的编码过程 局部校验lpi,j的产生如图4所示。每一组中有2个局部校验,产生lp1,1,lp2,1将m8~14的系数置为0,产生lp1,2,lp2,2将m1~7置为0。按照这种变化后,局部编码实际上就是RS(9,7),每一组用于编码的子生成矩阵为原生成矩阵对应行,并且lp1,1,lp2,2不存储。 图4 混合编码中LRC(23,14,2)生成局部校验 2.2.3 解码过程 当节点丢失后,系统会指定替代节点利用网络向帮助节点请求所需的数据,并利用其修复。若有低可信节点丢失,就利用RS的解码算法进行解码。若有高可信节点的节点丢失,解码前需要衡量丢失的位置,并将丢失的节点分配到局部校验或者全局校验中,最后利用局部校验或全局校验修复失效的节点。分配方式分为3步:一是利用丢失的节点数量和位置来判断能否解码;第二步给有丢失节点的组中分得局部校验可以解码的数量;第三步将剩下的节点分摊到全局校验节点上。如算法1所示。发生数据丢失后,有两种情况不能解码,分别是:一是丢失节点数量大于校验节点的数量;二是某一组丢失节点的数量比全局校验数量与组内局部校验之和还大,如图5(a)、图5(b)所示。 算法1: LRC失效节点分配到校验节点算法 输入: 丢失节点数量sumL, 每组丢失的数量gloArr, 全局校验数量glbP, 每组的局部校验数量grPArr, 全局和局部校验节点之和sumPX。 输出: 解码方式。 步骤1 判断是否能够解码。 IF sumL > sumP THEN exit(0) For gloArr i in gloArr IF gloArr i > glbp THEN exit(0) 步骤2 分配局部校验节点。 定义每组中需要全局校验修复的数量globRepairArr For gloArr i in grPArr globRepairArri = gloArri-grPArri 步骤3 分配全局校验节点。 For globRepairArri in globRepairArr IF globRepairArri > 0 THEN tempsum = tempsum+ globRepairArri IF tempsum > ∑glbpiTHEN exit(0) 步骤4 返回丢失节点对应的解码校验集合。 图5 丢失节点后不能修复的情况 同样以LRC-RS(40,20,23,14,2)为例,LRC编码中丢失m2,m3,m4,m7,m8,m9,m11,m12这8个节点。按照算法1的恢复方式进行分配失效节点。根据图6可知,丢失的8个节点小于9个校验节点且8个节点分布在不同的组,因此可以解码。 修复第一组的m2,m3,m4,m7分两步:先下载p1,lp1,2得到lp1,1,然后下载m1,m5,m6,p3,p4,lp2,1。利用lp1,1与lp2,1得到关于节点m1~7的两个方程,利用p3,p4得到关于节点m1~14的两个方程。同理修复第二组m8,m9,m11,m12也分为两步:先下载p2,lp2,1得到lp2,2,再下载m10,m13,m14,p5,p6,lp1,2。利用lp1,2与lp2,2得到关于节点m8~14的两个方程,利用p5,p6得到关于节点m1~14的两个方程。综上一共有8个线性无关的方程和8个未知数,解方程得到8个丢失节点。如图7所示。 混合编码在减少下载带宽的同时需要保证数据的可靠性。在2.1节中,根据节点的特征,验证了高低可靠性节点分布在去中心化环境中。其中高可信节点的不易失效;低可信节点的失效的概率较高。在1.4节中,给出了根据节点失效概率计算整个编码的可靠性的方法。将RS和LRC编码通过马尔科夫模型来模拟。假设使用RS和LRC编码节点的失效概率λ和修复概率ρ相同,每个小时间片内只丢失或修复一个节点。现给出RS(10,6)和LRC(10,6,2)的马尔科夫模型。根据参数可知RS能容忍任意4个节点失效,LRC能容忍任意的3个节点和86%[17]的任意4个节点失效。两种编码的马尔科夫的状态转移图分别如图8(a)、图8(b)所示,其中Pd=86%。 图6 失效节点分配到校验节点 图7 混合编码中LRC(23,14,2)恢复失效的8个节点的解码过程 图8 LRC和RS的马尔科夫模型 在RS与LRC的n,k取值相同的情况下,来分析节点失效概率对可靠性的影响。现用rs_λ和lrc_λ分别表示RS和LRC的节点失效概率。分两种情况:①当rs_λ=lrc_λ时,因RS能修复任意k个节点,而LRC只能修复任意k-1个节点和部分任意k个节点(l=2),所以RS的可靠性高于LRC的可靠性;②当rs_λ>lrc_λ时,RS的节点失效概率变大,而LRC节点的失效概率减小或不变,当rs_λ增加到一个临界值,RS的可靠性将会低于LRC的可靠性。 保证与RS(40,20)具有相同的n,k参数结构,来比较RS码与混合编码的可靠性。参数见文献[20],RS编码中λ=0.03;LRC-RS混合编码中的LRC码的节点失效概率lrc_λ=0.03,RS码的节点失效概率rs_λ=0.034。如表2所示。从表中可以看出,利用LRC-RS(40,20,23,14,2)混合编码的MTTF值均大于RS编码的MTTF值,可以得出混合编码的可靠性更高,满足目前工程上所能容忍的失效率。 表2 LRC-RS(40,20,23,14,2)与RS(40,20)可靠性对比 LRC-RS混合编码通过减少节点访问量来降低数据修复的总下载带宽。现以例子来对比在相同的节点数量、冗余度和失效节点数量下两种编码的修复带宽。由于混合编码的失效节点数量会分布在两种编码中,因此将所有分布的情况进行排列组合,选取下载量最大的作为比较对象。如图9所示,LRC-RS(40,20,23,14,2)的总修复下载量处于[7,192]的范围以内,最小的下载量为丢失一个节点,需要下载7个节点;最大下载量是一共丢失20个节点,需要下载192个节点。RS(40,20)编码的总修复下载量处于[20,400]的范围以内,最少的下载量是丢失一个节,需要下载20个节点;最多是丢失20个节点,需要下载400个节点。 图9 混合编码LRC-RS与RS码的总修复下载量对比 针对去中心化存储中节点的异构性,给出了LRC码在去中心化环境中详细的编解码的算法,并对LRC码中节点如何存储进行了详细的阐述[21]。通过使用LRC编码,改善了RS中修复一块数据需要下载k倍数量级的数据的问题。虽然两种编码同时运用在同一个去中心化系统会增加少量的编解码的复杂度,但是LRC-RS混合编码在数据的下载量(修复带宽)上的明显优势让其非常值得。最后,它不仅能够降低网络中的修复带宽,同时带来了可观的经济效益。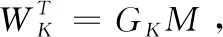
1.3 LRC

1.4 编码的可靠性
2 去中心化存储中的LRC-RS码
2.1 节点分类



2.2 LRC-RS混合编码


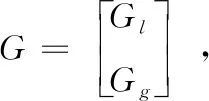
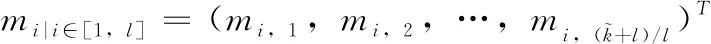
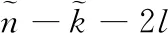

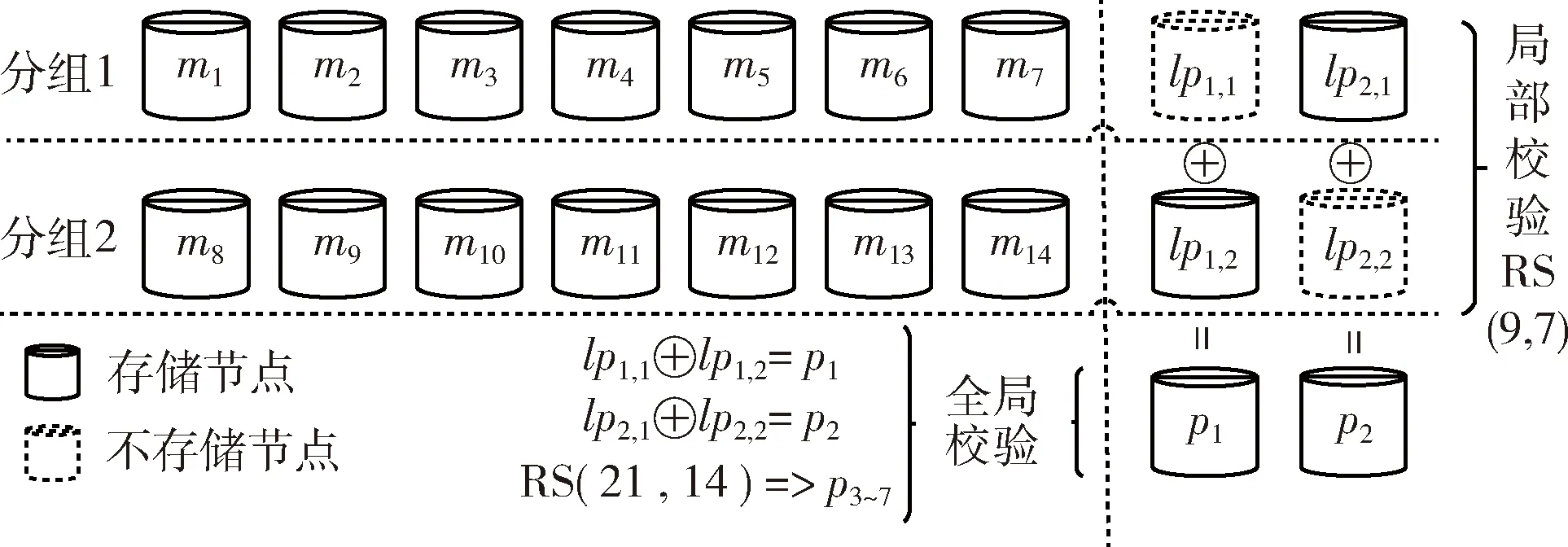

3 分 析
3.1 理论可靠性分析

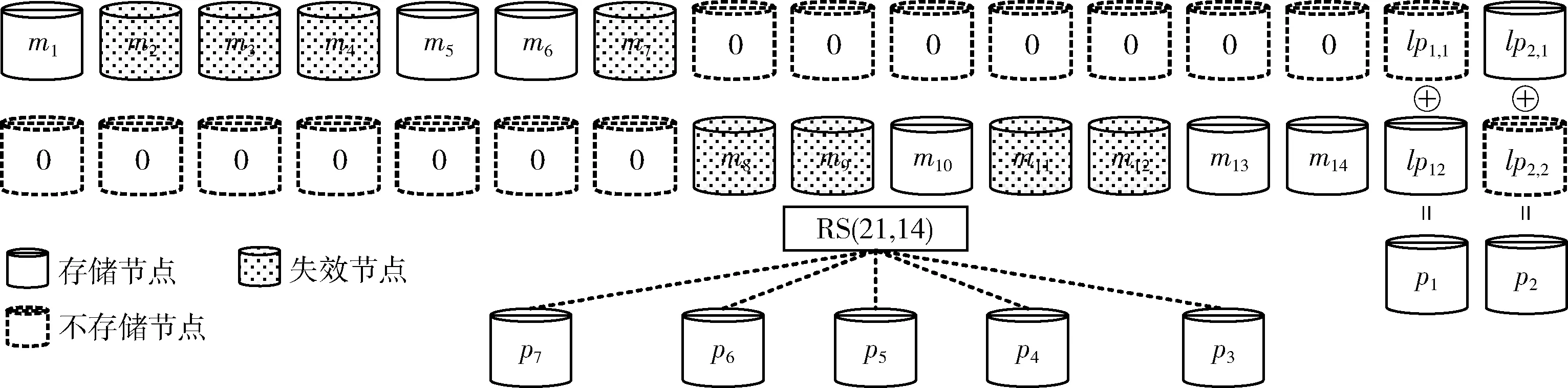
3.2 实验可靠性分析

3.3 总修复下载量


4 结束语
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:07:12
中国石油石化(2022年12期)2022-07-16 08:28:28
数学物理学报(2022年2期)2022-04-26 14:08:04
中国外汇(2019年19期)2019-11-26 00:57:32
家庭影院技术(2018年11期)2019-01-21 02:20:50
家庭影院技术(2018年11期)2019-01-21 02:20:48
金桥(2018年4期)2018-09-26 02:24:54
中国铸造装备与技术(2017年6期)2018-01-22 01:50:04
电测与仪表(2015年1期)2015-04-09 12:03:02
电测与仪表(2015年19期)2015-04-09 11:32:44
