
基于知识增强与注意力机制的双通道图像描述研究
2021-02-25 03:09陶云松张丽红
测试技术学报 2021年1期
陶云松,张丽红
(山西大学 物理电子工程学院,山西 太原 030006)
0 引 言
图像描述是将图像输入到系统框架中自动生成描述的任务.图像能够生动地表示事件和实体,但之前的图像描述方法仅将图像作为输入,通过深度学习框架自动学习.例如,Oriol V等[1]设计出图像描述的基本框架,利用卷积神经网络提取图像特征,使用长短期记忆网络生成描述.Xu等[2]将注意力机制引入到图像描述的基本框架中,该机制可以使框架在生成描述时关注图片中的显著特征.但是,在深度学习框架学习的过程中,其内部具体参数的变化难以获取,不能获知图片的特征提取过程.此外,图像描述架构大都采用卷积神经网络提取特征,采用等分提取方法无法准确提取目标[3].为解决上述问题,提出一个新的双通道图像描述结构,该结构输入采用图像通道与主题通道双通道结构生成图像描述.主题通道采用知识强化方法产生图像中物体相对应的主题单词.知识强化方法是在图像描述中加入一些图片的内容词来规范图像描述.主题通道可以自动产生图片的内容词,而不需人为设置每张图片的内容词.图像通道采用极快速区域卷积神经网络(Faster Regional Convolutional Neural Network,Faster RCNN)提取图像特征,能自动确定图像中物体的大小.输出阶段将两通道预测的隐层信息进行整合并生成图像描述,进而实现主题通道对图像通道的知识强化.
1 Faster RCNN
Faster RCNN的结构如图1 所示.首先,将整张图片输入卷积神经网络中得到图像特征,其次,将图像特征输入到区域建议网络(Region Proposal Network,RPN)中自动生成候选框.候选框映射到图像特征得到兴趣区域特征,将兴趣区域特征通过兴趣区域池化层(Region of Interest Pooling Layer,ROI Pooling)得到相同大小的输出,再通过两层全连接层得到兴趣区域特征向量.最后,使用分类器判决兴趣区域特征是否属于一个特定的类,对于属于某一特征的候选框,用回归器进一步调整其位置.RPN与卷积神经网络之间的特征映射如图2 所示.
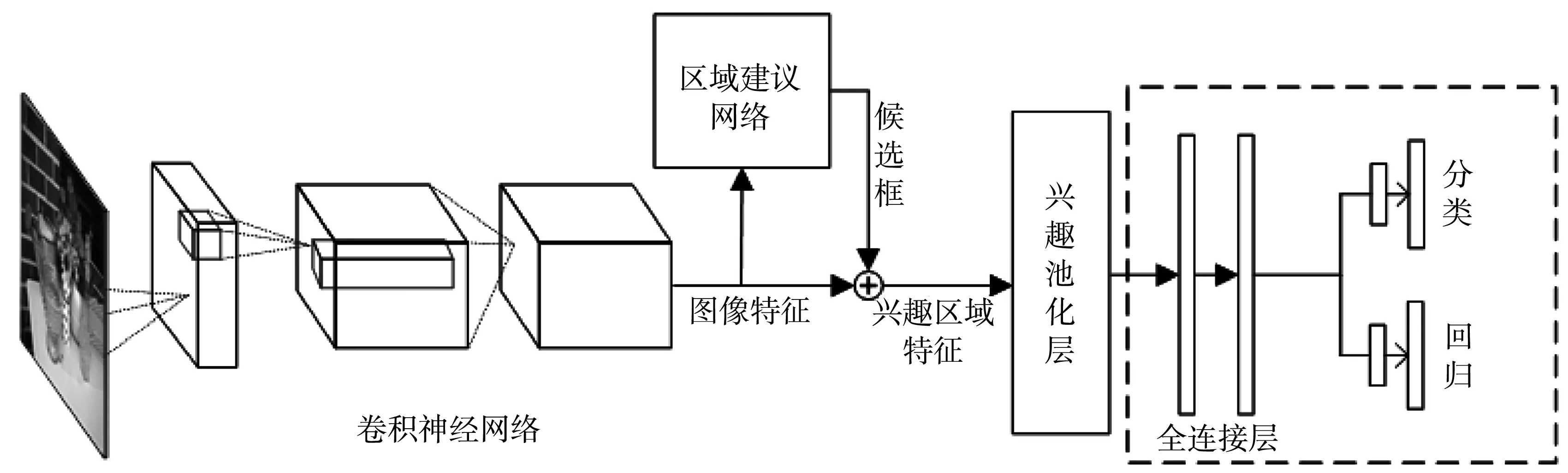
图1 Faster RCNN结构图Fig.1 Structure diagram of Faster RCNN
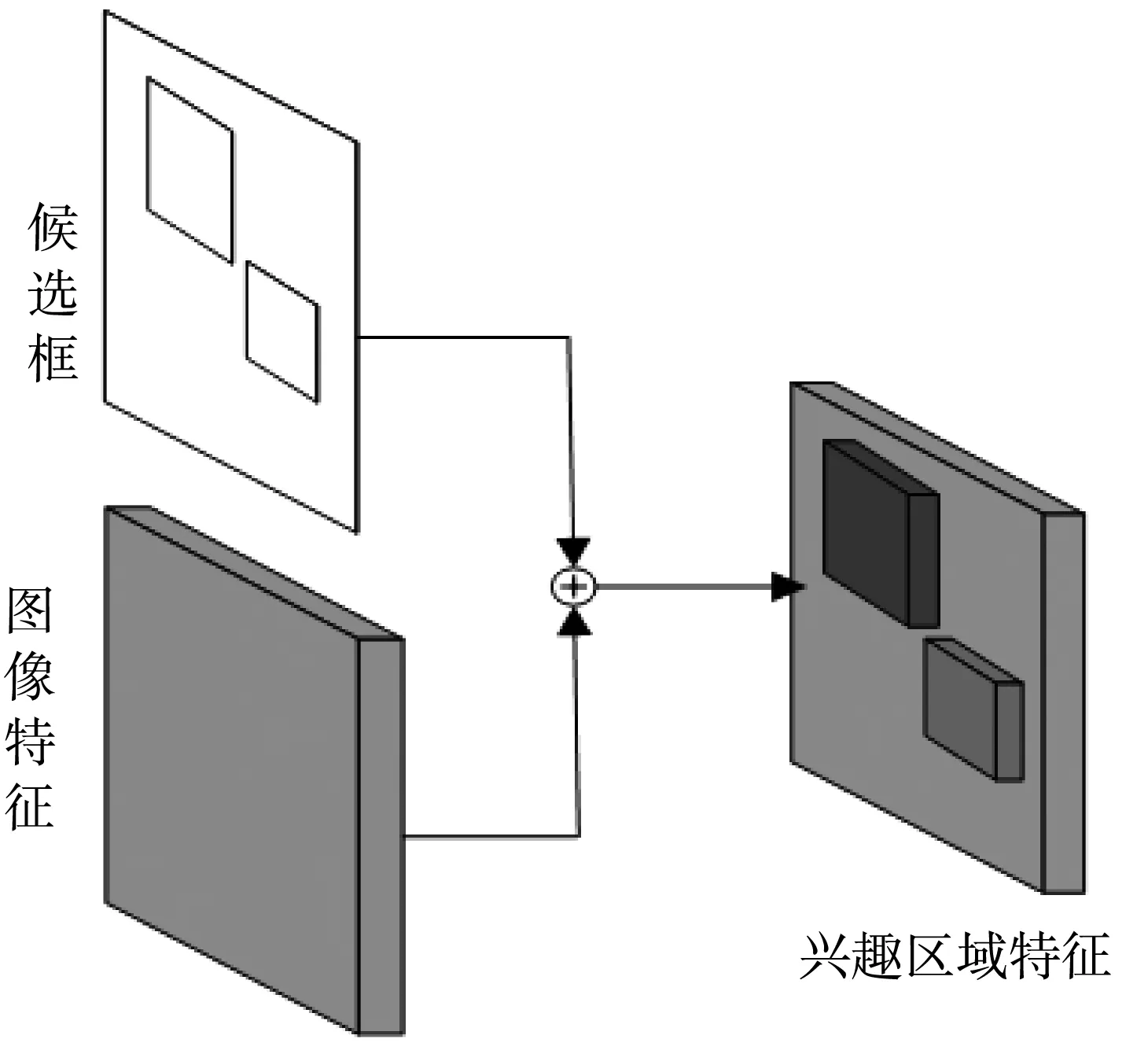
图2 特征映射图Fig.2 Feature mapping
RPN的功能是直接生成候选框并与特征融合,这也是Faster-RCNN的显著优势,能够极大提升候选框的生成速度.经典的传统检测方法如区域卷积神经网络、快速卷积神经网络都要采用选择搜索性算法生成大量的候选框,这些候选框与图像融合在一起,每个候选框内的图像都要输入到卷积神经网络中,计算量很大[4].RPN使每张图片一次性通过卷积神经网络,候选框在生成图像特征上进行映射从而得到各候选框内图像特征.
ROI Polling的功能是将大小不同的候选框内特征调整为相同大小输出,它可以看作是一个单层的空间金字塔池化层[5].空间金字塔池化层使用空间金字塔采样将每个窗口划分为4×4,2×2,1×1的块,然后每个特征块使用最大池化下采样,这样对于每个窗口经过空间金字塔池化层之后都得到了一个长度为(4×4+2×2+1)×256维度的特征向量,将此特征向量作为全连接层的输入并进行后续操作[6].
2 含有注意力机制的长短期记忆网络
长短期记忆网络(Long Short-Term Memory Network,LSTM)是一类用于处理序列数据的神经网络,它在几个时间步内共享相同的权重,不需要分别学习序列中每个位置的规则[7].LSTM的展开图如图3 所示,A代表内部单元,x为输入,y为输出,ht为LSTM单元在t时刻最后保留的信息.LSTM的重要思想是每个时间步都有输入,并且隐藏单元之间有循环连接的循环网络.
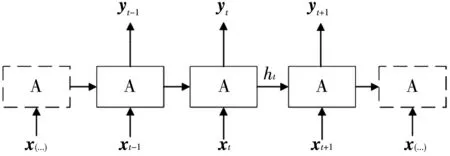
图3 LSTM的展开图Fig.3 Expansion diagram of LSTM
循环神经网络前期模型训练困难,其原因在于不稳定梯度问题,在反向传播时梯度越变越小,使得前期层学习非常缓慢.在循环神经网络中此问题更加严重,因为梯度不仅仅通过层反向传播,还会根据时间进行反向传播.网络运行很长一段时间后,梯度特别不稳定,使网络学习能力很差[8].引入LSTM可以解决上述问题,LSTM的内部结构如图4 所示.
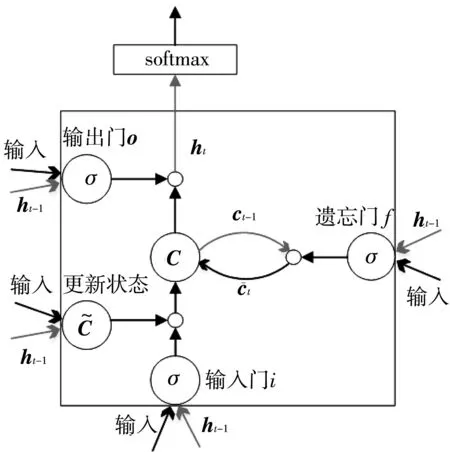
图4 LSTM内部结构Fig.4 Internal structure of LSTM
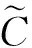
在图像描述生成时,每个输出的词语并不是与所有的图片特征相关,因此引入注意力机制.注意力机制在输出词语时能够关注图像中不同的特征.注意力机制结构如图5 所示.
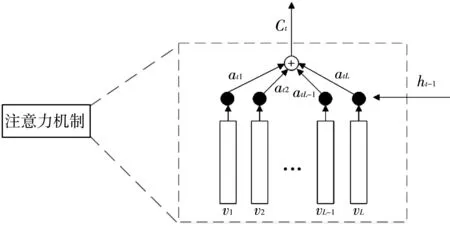
图5 注意力机制内部结构Fig.5 Internal structure of attention mechanism
图像特征集合V=[v1,v2,…,vL]通过压缩原始图像特征V的宽W和高H得到,其中L=W*H,vi∈RD,vi为D维度的空间图像特征,代表图片中的某个区域.
图像特征和LSTM的隐层状态被传入一个单层感知机中,再通过softmax函数产生图片K个区域的注意力分布.
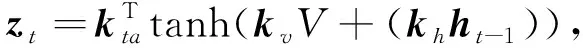
αt=softmax(zt),(2)
式中:kv,kta,kh为一组需要学习的权重参数;αt为图像特征的注意权重.基于注意力分布,图像显著信息为
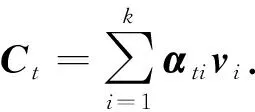
将注意力机制与LSTM结合在一起,如图6 所示,由注意力机制获得的图像显著信息作为LSTM的输入之一,Ct与隐层状态ht一起预测出结果.
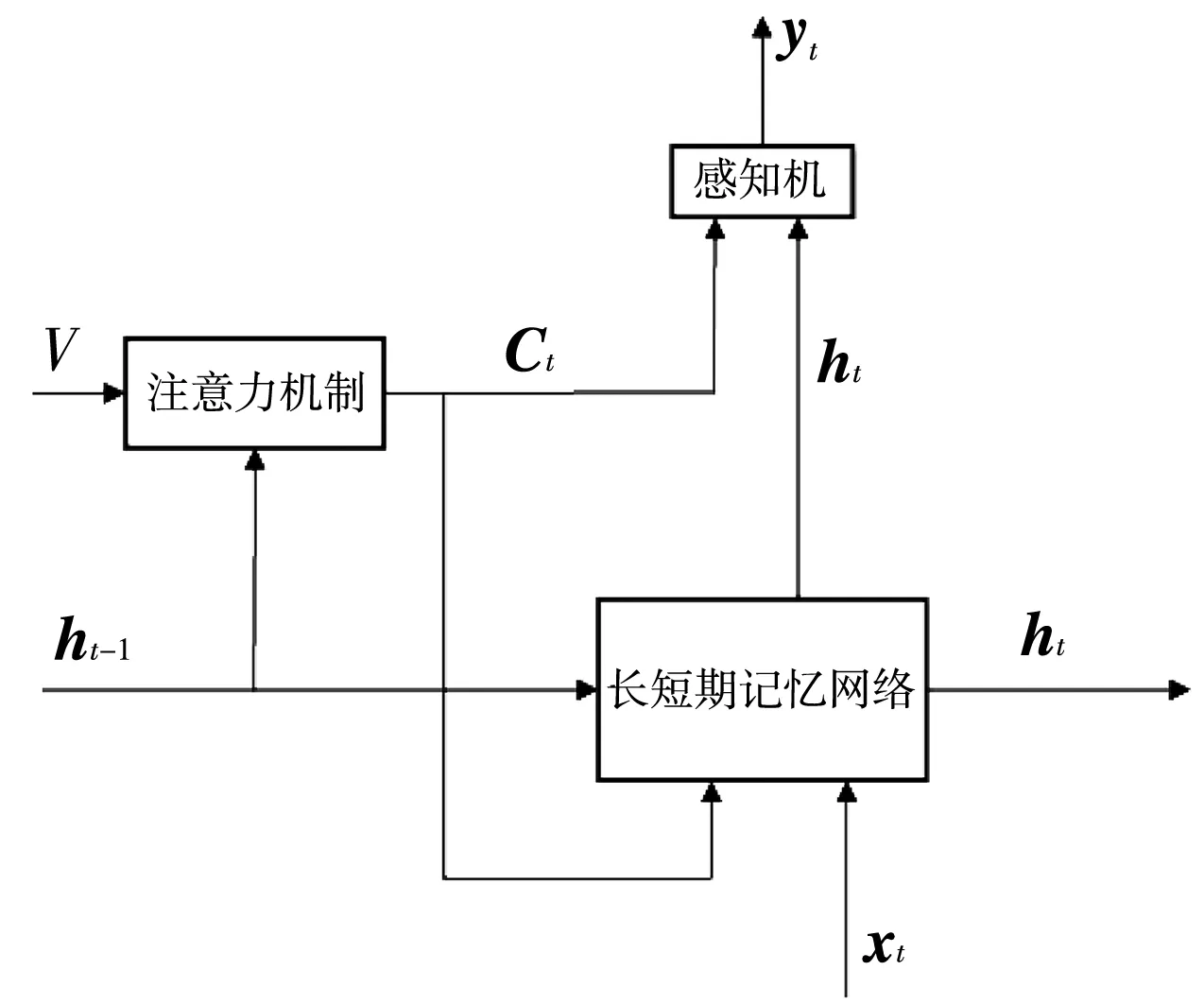
图6 与注意力机制组合的LSTMFig.6 LSTM combined with attention mechanisms
3 系统框架
基于Faster RCNN、LSTM及注意力机制对双通道图像描述网络进行了设计,如图7 所示,该网络由主题通道与图像通道组成.
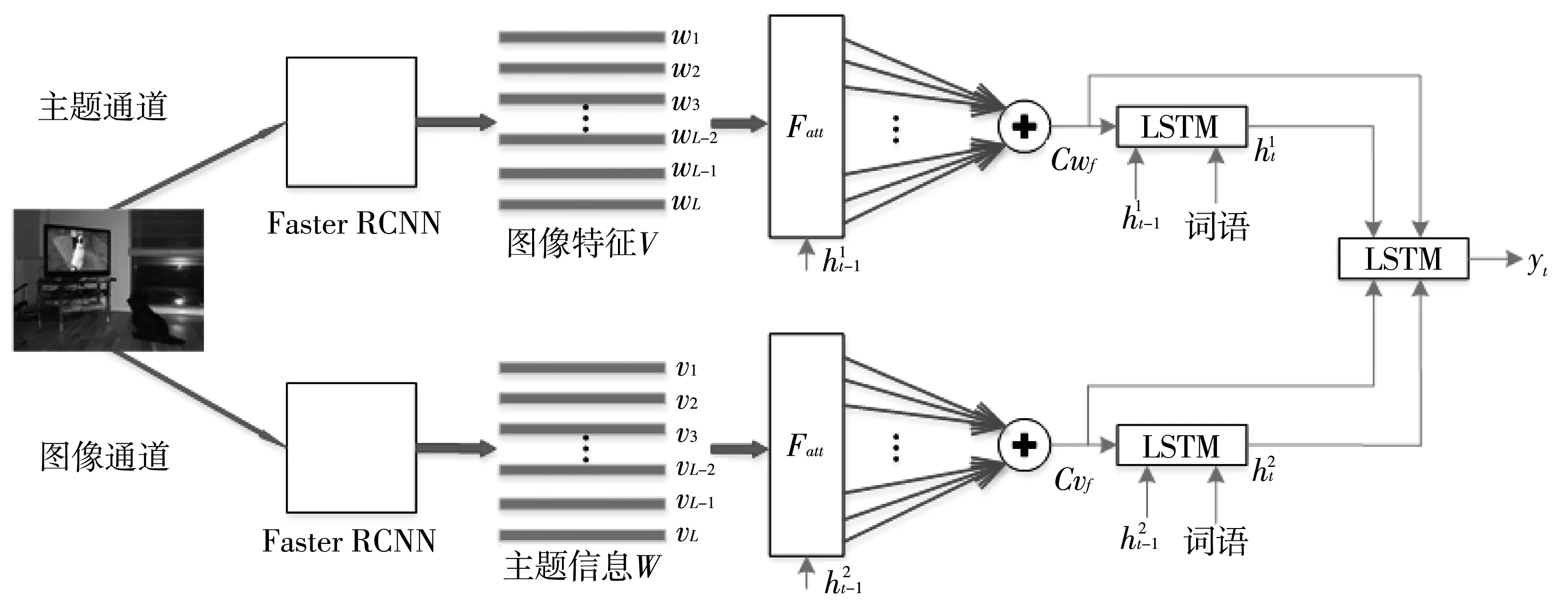
图7 双通道图像描述结构Fig.7 A two-channel image description structure
主题通道引用知识增强方法,在图像描述结构中加入一些图片内容的主题单词进行知识增强,即明确描述的范围.主题通道采用极快速卷积神经网络提取文本特征,该通道与图像通道不同,文本特征来自极快速卷积神经网络的全连接层.主题信息通过注意力机制筛选之后输入LSTM进行语义推测.主题通道的优势在于能够自动生成主题信息而不是提前为每张图片准备好主题词.
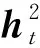
V=Faster-RCNN(I),(4)
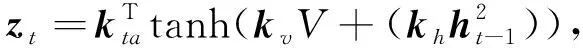
at=softmax(zt),(6)
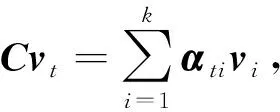
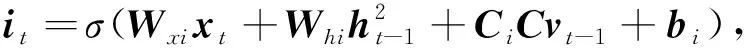
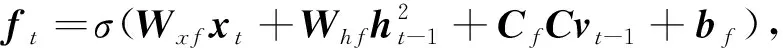
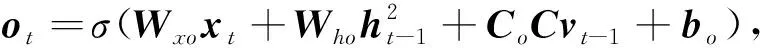
CcCvt-1+bc),(11)
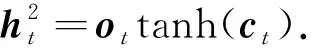
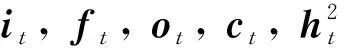

yt=softmax(Whht+b),(14)
式中:yt为网络的输出单词,是下一个时间的输入单词xt+1.
4 实验结果
实验采用MS COCO数据集与Flickr30k数据集.MS COCO数据集是图像描述中最大的数据集,拥有训练样本82 783张,验证样本40 504张和测试样本40 775张,每张图片对应5个人的描述.在训练时,验证和测试图片都是5 000张.Flickr30k数据集中含有31 783张图像,模型在该数据集上测试泛化性.表1 和表2 为本文模型在MSCOCO数据集和Flickr30k数据集上与其他模型评估分数对比表,使用的评估指标有基于共识的图像描述评估(Consensus-based Image Description Evaluation,CIDEr)、双语评估替换分数(Bilingual Evaluation Understudy,BLEU)、自动文摘评测方法(Recall-Oriented Understudy for Gisting Evaluation,ROUGE)和机器翻译评价方法(Machine Translation Evaluation System,METEOR)[9].
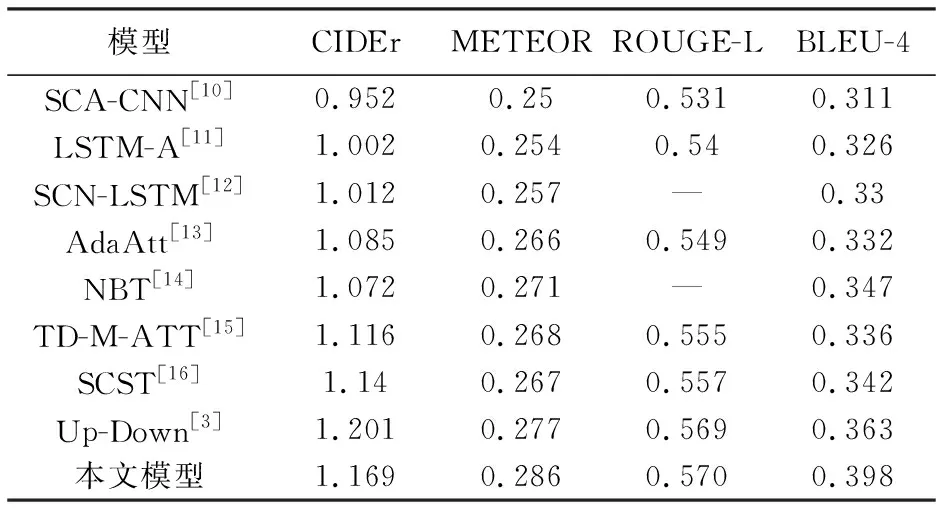
表1 MSCOCO数据集上各模型参数Tab.1 Model parameters on MSCOCO dataset
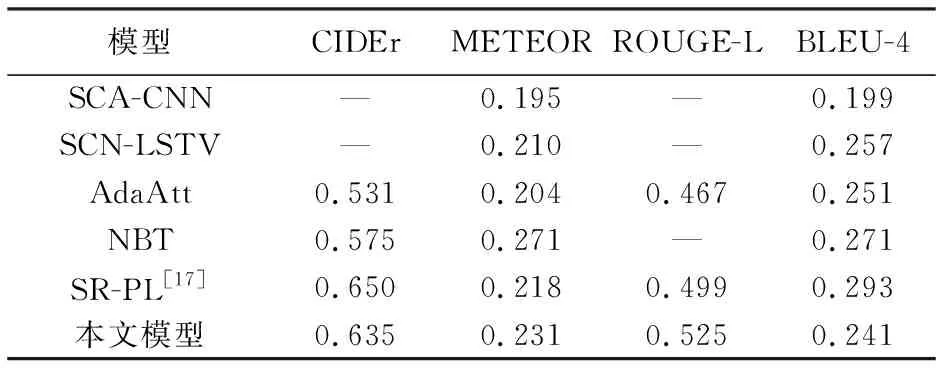
表2 Flickr30k数据集上各模型参数Tab.2 Model parameters on Flickr30k dataset
双通道图像描述网络与多种图像描述网络进行比较,从表1 与表2 中可以看出,双通道图像描述网络在数据集MS COCO和Flickr30k上的准确率获得了提高,在数据集Flickr30k上的测试结果也表明本文模型有良好的泛化性.
图8 为双通道图像描述网络在MS COCO数据集上相关参数的检验值,图9 为双通道图像描述网络在Flickr30k数据集上CIDEr和METEOR参数的检验值,纵坐标为参数精度值,精度值越大,代表某次图像描述效果越好,横坐标为检验次数.对检验值取期望得到模型某指标的参数值.
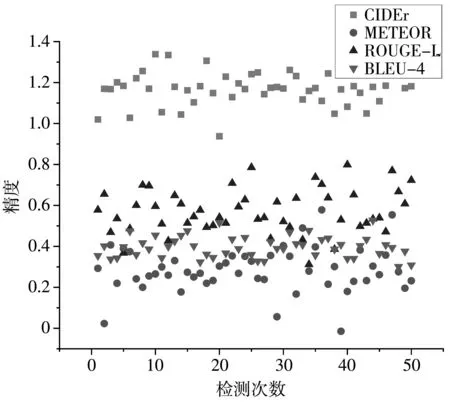
图8 MSCOCO数据集下各参数检验值图Fig.8 Test values of each parameter under MSCOCO datase
如图8 所示,CIDEr与BLEU-4检测值分布较集中,表明在这两个标准下图像描述波动较小,ROUGE-L分布较分散,表明在此标准下图像描述好坏波动较大.去掉METEOR中接近0的错误值,其整体参数较好,并且有一定的参数值超过平均期望,即图像描述效果较好.图9 与图8 相比较,参与CIDEr与METEOR分布离散度变大,但整体趋势一致,表明在验证集Flickr30k上模型的泛化性较好.损失函数图如图10 所示,可以看出该算法是收敛的.图11 为模型的生成图.
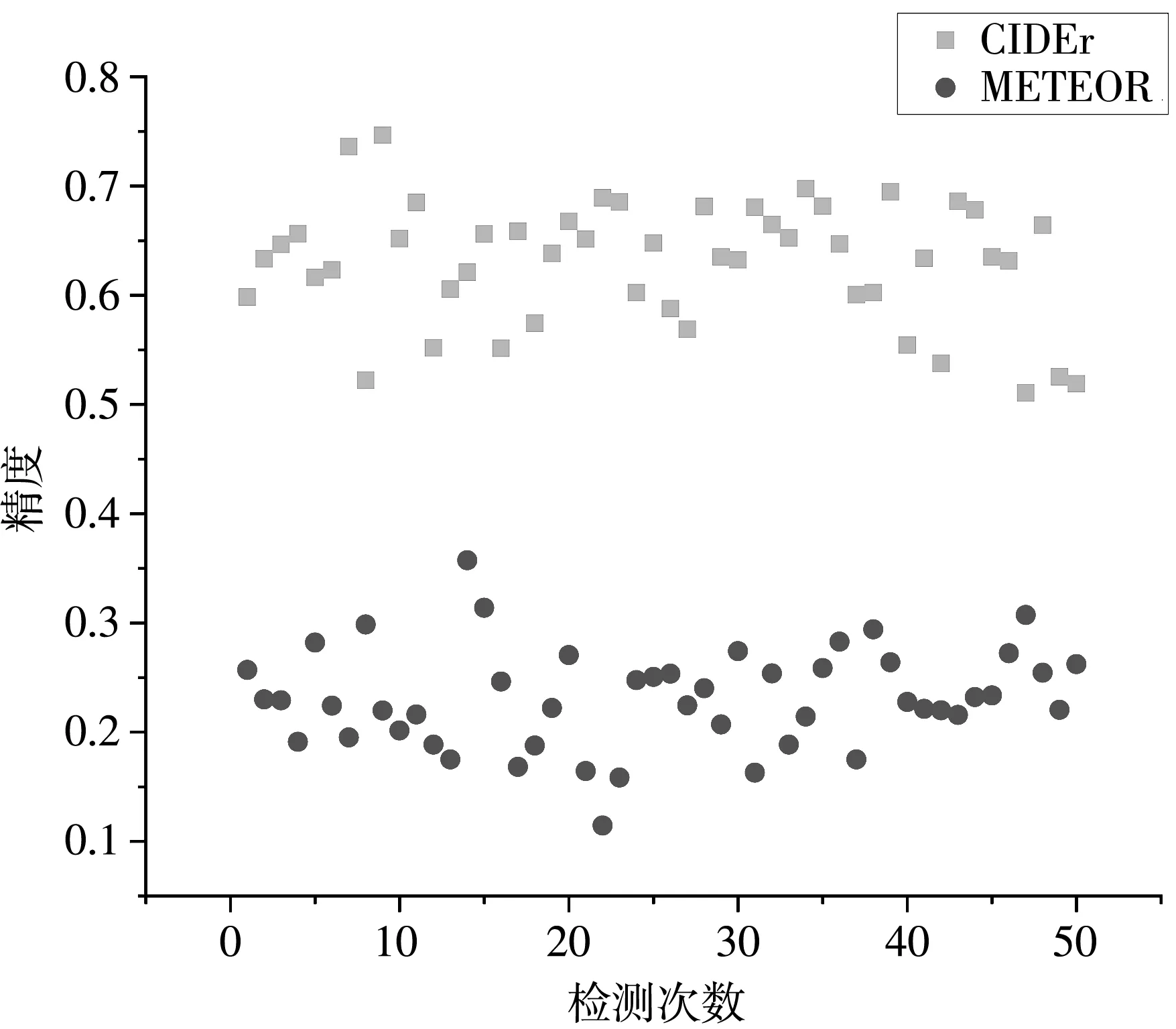
图9 Flickr30k数据集下各参数检验值图Fig.9 Test values of each parameter under Flickr30k dataset
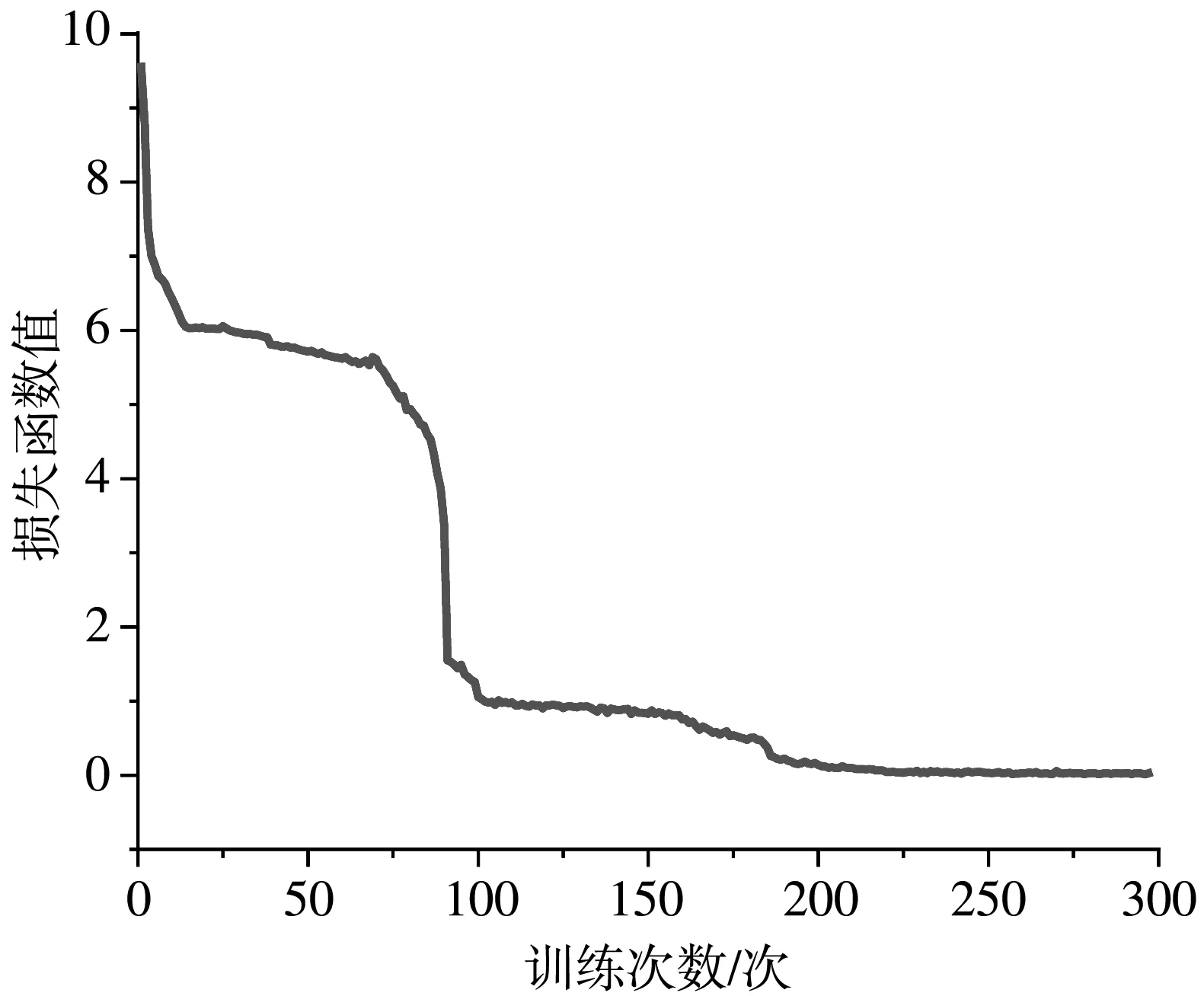
图10 损失函数图Fig.10 Loss function graph

图11 图像样例图Fig.11 The sample graph
5 结 论
在图像描述任务中引入知识增强方法来改善端对端训练过程中内部参数不可控的影响.提出了一种新的双通道图像描述网络,该网络包括图像通道与主题通道两大部分,主题通道首先提取生成图像中的主题信息,并通过注意力机制筛选主题信息进行语义推测;图像通道的主要作用为提取图像特征,通过注意力机制筛选特征进行语义推测.最后,主题通道的语义信息与图像通道的语义信息进行增强融合后进行语义推断,生成图像描述.与此同时,在结构中使用极快速卷积神经网络替换卷积神经网络提取图像和主题特征以便更准确提取特征.该结构在双语评估替换分数等评价指标上取得了较好的效果.
猜你喜欢
现代临床医学(2022年5期)2022-09-28
光学精密工程(2022年13期)2022-08-02
小雪花·成长指南(2022年1期)2022-04-09
计算机工程与应用(2022年1期)2022-01-22
昆明医科大学学报(2021年4期)2021-07-23
计算机技术与发展(2020年2期)2020-04-15
火力与指挥控制(2018年3期)2018-04-19
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
电子设计工程(2015年16期)2015-02-27
