
面向深度学习的Las格式测井数据转换器设计
2021-02-25 03:07:56强伟帆刘庆彬郭艳军侯贵廷
科学技术与工程 2021年1期
强伟帆,潘 懋,刘庆彬,郭艳军,侯贵廷
(北京大学地球与空间科学学院造山带与地壳演化教育部重点实验室,石油与天然气研究中心,北京 100871)
近年来,深度学习方法被广泛应用于地质领域,如遥感影像的地物识别[1-2]、岩石图像(镜下图像)的岩性(矿物)识别[3-4]、地震数据的油气特征提取等[5-6]。在测井领域,深度学习已经在多方面进行了应用,如:测井岩性及测井相识别、测井裂缝自动识别、缺失测井曲线生成等[7-10]。
开展基于深度学习的测井应用研究需要生成训练数据集,CSV格式是一种逗号分隔值文件格式,在深度学习训练数据集中十分常见,目前常用的TensorFlow、Pytorch、Keras、Mxne、Caffe等深度学习框架都直接采用CSV格式文件[11]。测井数据记录测井ASCII码格式是Las格式,其具有文本可见,数据记录易读取和交换,不同型号的计算机均能直接对其进行读取、计算和分析,被大多数测井处理系统产品所支持,并被广泛应用,是业内广泛认可的数据格式[12-13]。但Las文件不能直接应用于深度学习,目前并没有程序包可以直接读取Las文件。因此在进行测井深度学习应用之前,需要进行格式转换工作:将测井数据文件转换为可以直接被应用程序包读取的文件,为深度学习训练和测试提供方便利用的数据。
关于测井数据处理前人做过很多工作。胡振平等[14]、龚福秀[15]先后对常用测井数据格式进行整理,分析了每种数据格式的组成方式,并实现了各种测井数据格式之间的相互转换。孔玉霞[16]对比了数字化软件Neuralog和Forward得到的Las文件的格式差别,并将由Neuralog得到的Las成功转为可以在Forward中使用的Las。郭海敏等[17]对Las测井数据解析、合并和批量格式转换进行了深入研究。刘振等[18]开发了一个测井数据过滤器规范了Las数据格式,能快速剔除大量无用数据,降低计算机使用内存。但是目前中外对测井文件的研究大多集中在测井数据格式编码解读和不同测井文件相互转换方面,对测井数据转换为其他格式数据,尤其是深度学习所需的数据格式研究较少。
基于Visual Studio 2012平台,采用C#语言的Windows窗体应用程序开发了一套Las测井数据到CSV逗号分隔值文件格式的转换软件,该软件界面简洁易懂,数据操作交互性强,能够快速、有效地对数据进行操作和转换。
1 数据格式介绍
1.1 Las数据格式
Las(LogASCIIStandard)测井数据格式是1990年由加拿大测井协会制订的一种标准的测井数据格式。Las采用ASCII编码格式,储存了图头信息和实际的测井数据。Las格式为传统石油工作者和普通电脑用户提供基本的数字测井数据,它的格式要求简单易于使用而且易于程序分析[17]。一个标准的Las文件由多块组成,每一块都包含特定的信息或数据,并且每一块都有相应的标记来帮助标识格式和辅助Peterl等程序解析。Las测井文件标准格式包括:文件来源;版本信息,以“~Version information”为标识;井信息,以“~Well”为标识,包括起始点位置、终止点位置、时间、无效值说明等;曲线信息,以“~Curve”为标识,记录曲线名称和单位等信息;ASCII段数据,以“~Ascii”位表示,记录了每一条数据,如图1所示。掌握标准测井文件数据格式后就可以对文件进行读取、剔除无效值、数据转换等工作[18]。
1.2 CSV数据格式
CSV是逗号分隔符文件,也被称为字符分割符文件。其文件以纯文本形式存储数字或文本的表格数据。CSV记录若干条数据,每条数据由换行符分割,字段间用字符分割,通常为英文逗号“,”或制表符“|”,如图2所示。CSV存储表格数据,可以使用EXCEL直接打开,但.CSV和.Xls的区别是CSV是纯文本文件,可以使用Txt记事本软件打开,也可以使用EXCEL打开。而.Xls是表格文件,只能用EXCEL打开。CSV是单纯的以文本格式存储,无法生成和保存运算公式或数据关联,所以造就了其读写方便、易获得、可表格化展示、易于导入各种PC表格及数据库等优点,多用于不同程序之间数据的交互[19]。
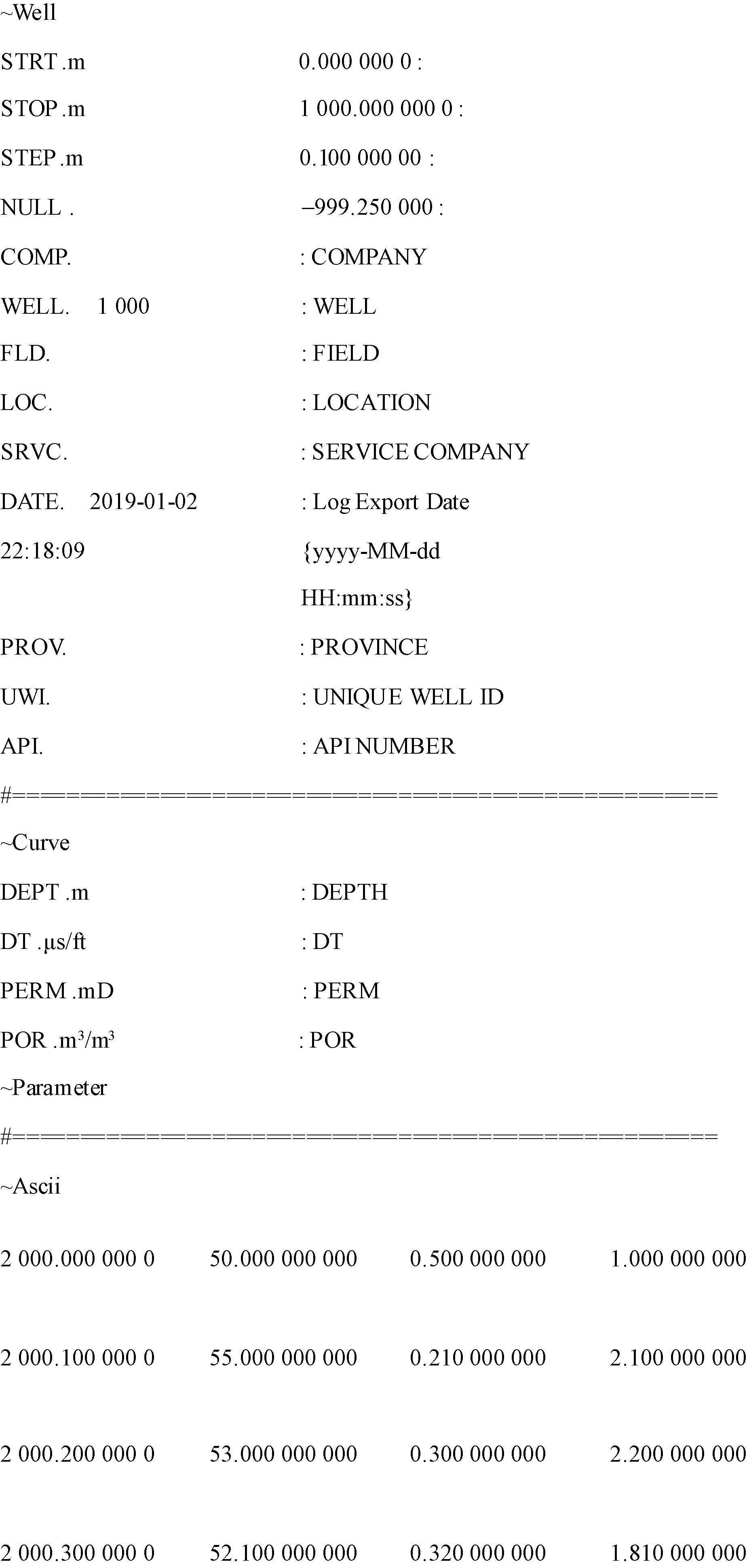
图1 Las格式数据文件Fig.1 Las format data file

图2 CSV格式数据文件Fig.2 CSV format data file
2 程序设计思路
LastoCsv格式转换软件主要工作包括以下几个方面:①按照Las文件编码格式进行读取Las文件;②对Las文件进行简单分析和数据处理(如剔除无效值,选择指定值);③Las到CSV格式文件的转换;④将处理后的数据写入CSV文件;⑤对CSV文件进行指定路径输出和合并输出。
整个设计过程分为预处理、处理以及导出数据三个部分,如流程图3所示。其中预处理阶段分为单文件预处理与文件夹预处理;处理阶段分为选择所需属性、剔除或选择指定范围数据、Las文件格式转换为CSV格式;导出数据阶段分为单文件导出和合并导出。
3 算法实现
3.1 预处理阶段
测井数据文件的读取分为文件头和数据域。文件头主要声明数据来源、版本、井信息和所包含的曲线。其中包含的曲线以“~Curve”为标识,记录曲线名称和单位信息。这里的曲线信息和后面的数据一一对应,因此拾取曲线类型和个数对后续数据域数据对应匹配、选择属性和数据剔除等都起到了关键作用。数据域在“~Ascii”数据标识符之后。每行数据都代表一组数据,依次读取每行数据,去除空格、换行符的干扰,按照顺次依次存入相应曲线的数组中。相应的变量声明如图4所示。
预处理阶段分为单文件处理和文件夹处理。由于深度学习需要大量的训练数据集,因此实际实验中数据转换一般是文件夹级别的转换,单文件处理主要起到单个文件的验证作用。预处理结束后得到文件夹中的所有Las文件中曲线属性的并集。

图4 声明的数据储存变量Fig.4 Declared data store variables
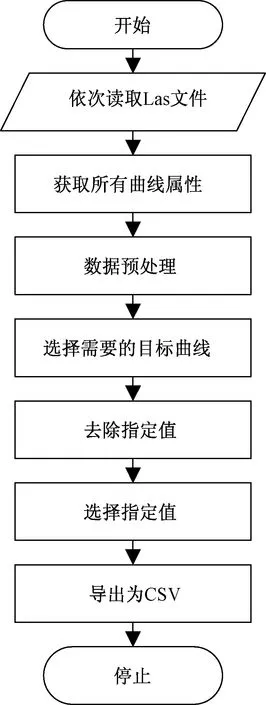
图5 数据转换处理流程图Fig.5 Data conversion process flow chart
3.2 处理阶段
整个数据转换处理流程图如图5所示。基于深度学习算法的测井曲线预测研究其基本的思路是从现有的测井文件中进行大量的曲线间的关系特征学习,从而针对存在缺失曲线的测井文件中根据已有的特征学习来对缺失的曲线进行预测。根据深度学习预测的实际需要,往往人为地选择相应曲线,比如从测井文件中获取声波时差、井径、自然伽马、自然电位、电阻率等目标曲线。不同的测井文件包含不同的曲线。对所有目标曲线,有些Las文件中可能不包含所需要的所有曲线或只包含部分,而有的文件则包含所有需要的曲线。所以在处理阶段,需要标记属性不全的测井文件,在导出阶段则对这些经过标记的文件不再进行数据格式转换和导出操作。并且如果其中某一个属性值都是无效值,则认为这个文件也是没有学习意义的,也进行标记处理。
测井Las文件往往开头和最后部分都包含一些无效数据,如使用“-999.250000”代表“NULL”。这些无效数据如果参与深度学习的训练,可能会对学习的结果产生一定的影响,因此需要在处理阶段对这些无效数据进行处理。处理方法可以分为两种,第一种是直接对无效数据进行剔除处理;第二种是对无效数据进行赋值,加以区分。现采用剔除处理的方法。
在选择所需要的曲线并进行数据无效值处理后,需要对所选择的属性数据进行指定值处理。根据实际需要选择某个属性的指定区间值,例如选择深度DEPT在1 000~2 000 m的各属性数据。处理分为选择指定值和去除指定值两类操作。其实两类操作正好相反。这里以选择指定值为例进行说明。选择指定值可以设置上限和下限的阈值。阈值设置分为4种情况:①上限和下限值都为空,则认为对数据不进行操作;②上限有值、下限为空,则选择所有小于上限值的数据;③上限为空、下限有值,则选择所有大于下限值的数据;④上下限都有值,则选择上下限之间的数据,如果上下限值相等,则选择等于上限(也就是下限)的数据。
对数据进行处理后,根据CSV文件的数据组织格式将数据进行重新组织。第一行记录不同属性的英文缩写名称及单位,之后每行记录每一条有效数据,每条数据由换行符分割,字段间用字符“,”分割。
3.3 导出数据
将Las数据格式转换为CSV数据格式后导出为以“.csv“为后缀的文件。用户可以根据实际需求选择文件存储路径并保存数据。有两种导出方案。第一种是单文件导出,将经过处理后的数据按照Las井文件名进行单文件导出。但这里要注意,导出后的CSV文件个数可能小于Las文件个数,原因在于处理阶段对不存在所选曲线的文件或某个曲线数据都是无效值的文件进行了标记处理,这些文件不会导出成CSV格式。第二种方案是合并导出,因为在实际的深度学习流程中,只需要学习一个文件即可满足需求。因此将所有数据都合并到一个CSV文件中,将此CSV文件命名为文件夹的名字。为了区分,同时在CSV数据中新加一列,用于记录文件名数据,说明这条数据来源于哪个Las文件。
4 效果检验
实验所用的计算机配置为:Intel i5、3.20 GHz处理器,12 G内存,64位操作系统。程序运行界面如图6所示。测试时选择工区13条测井文件,数据量38.2 MB。打开文件夹读取所有属性用时1.89 s,所有曲线属性显示在左边列表框中,如图7(a)所示。选择深度(DEPT)、声波时差(DT)、渗透率(PERM)、孔隙度(POR)4条曲线属性,点击“=>”按钮即可将所需要的曲线添加到右边列表框中。对所选属性进行选择指定值操作,例如给DT设置上限90,即选择所有DT属性小于90的数据,如图7(b)所示。首先进行单文件导出用时2.94 s,导出4个文件,如图8(a)所示。合并导出用时3.11 s,合并为一个文件,如图8(b)所示。图9是某条测井曲线的导出数据的一部分,可以看出4条属性数据成功转为了CSV文件格式。为了检验数据的准确性,将源数据Las文件导入Petrel进行测井曲线可视化,同时将CSV文件处理为制表分隔符后的文本文件也导入Petrel进行可视化对比,如图10所示。图10中左边3条曲线来源于Las文件数据,右边3条曲线来源于CSV文件数据,可以看出Las文件和CSV文件的声波时差(DT)、渗透率(PERM)、孔隙度(POR)曲线完全一致。同时CSV文件对深度为3 200 m附近多余的声波时差(DT)属性进行了过滤,方便了深度学习训练数据集的准确性。为了测试转换器的运行效率,采用多组不同数量级的数据进行单文件导出和合并导出实验,具体实验运行时间结果如表1所示,绘制柱状图如图11所示。总体而言,数据转换程序运行效率较高,能准确、快速地将Las文件转换为CSV文件。随着数据量的增大,文件读取时间和导出文件时间都呈正相关增长,计算机即时性能也是影响程序运行效率的一个关键因素。
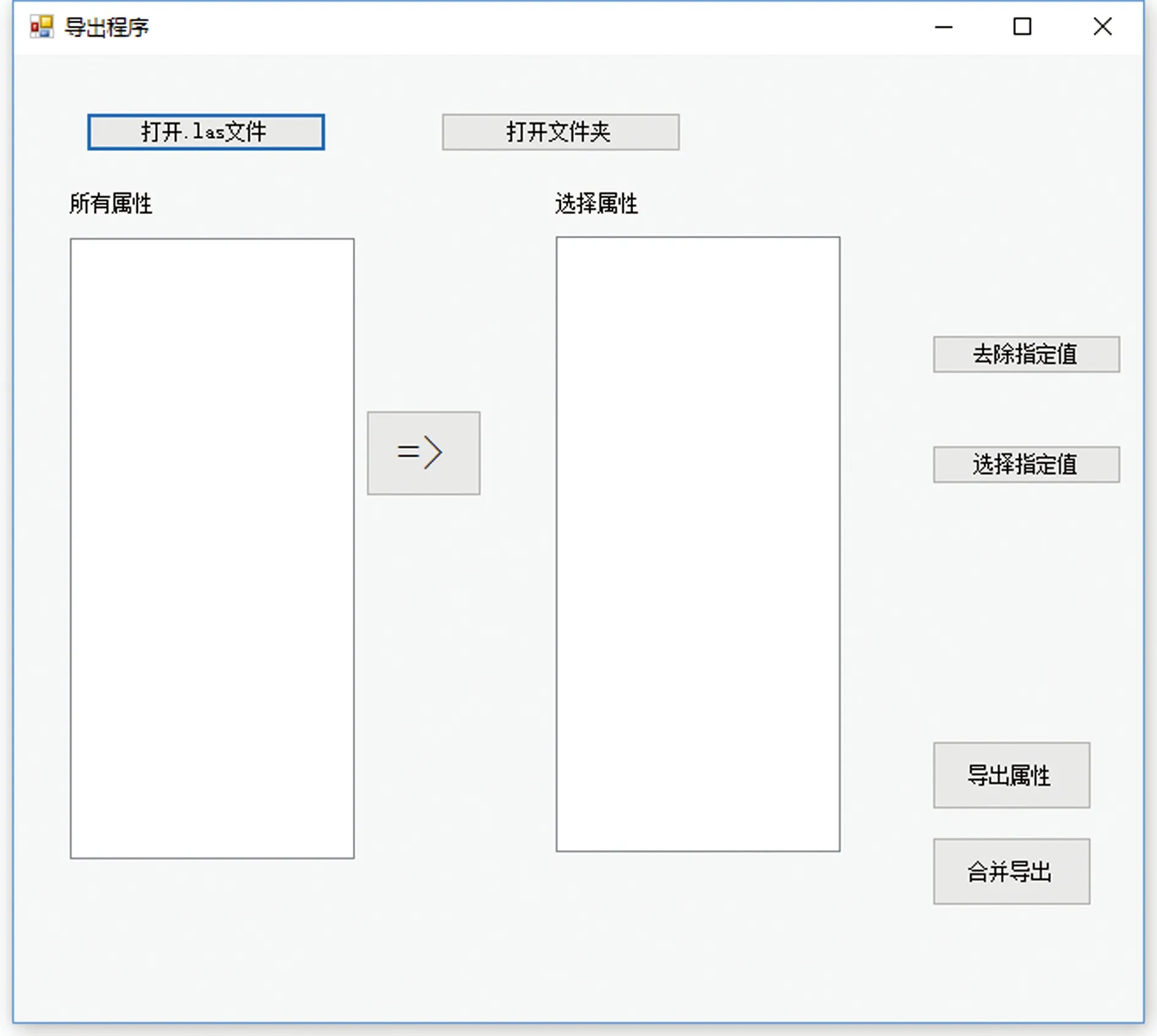
图6 程序主界面Fig.6 Main interface
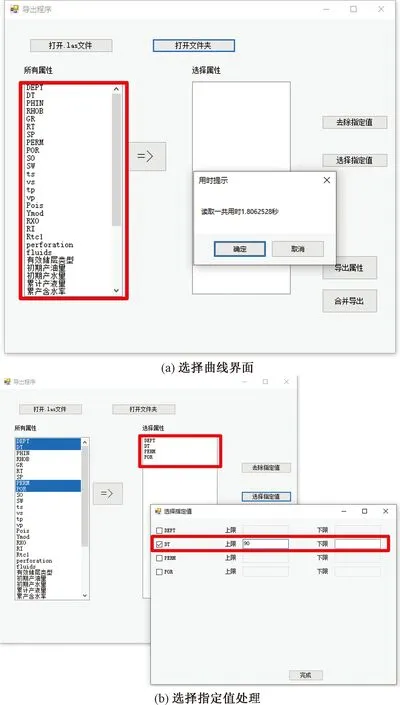
图7 数据处理操作Fig.7 Data processing operation

图8 导出结果Fig.8 The results derived
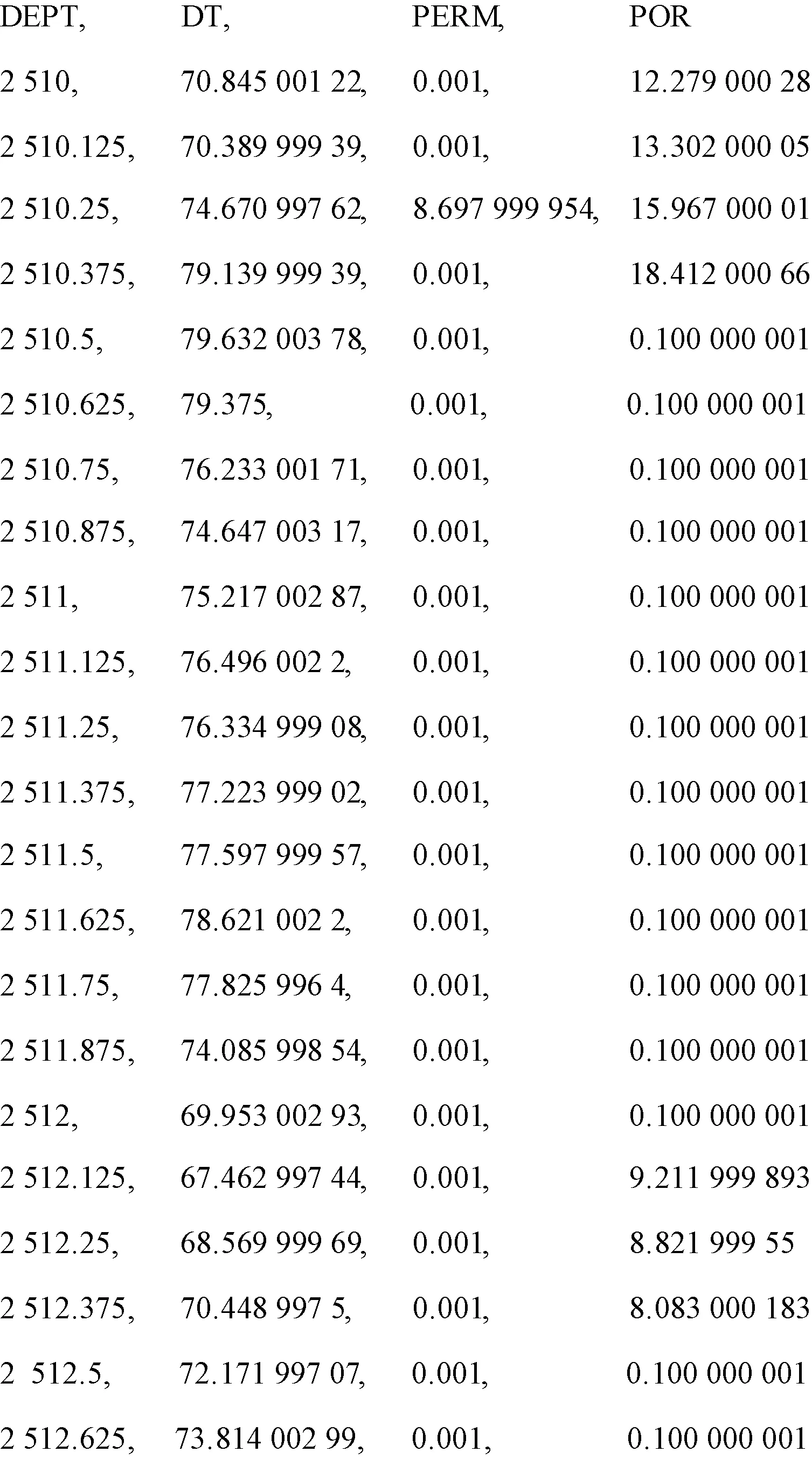
图9 选择曲线后导出的CSV文件Fig.9 The CSV file exported with the selected curves
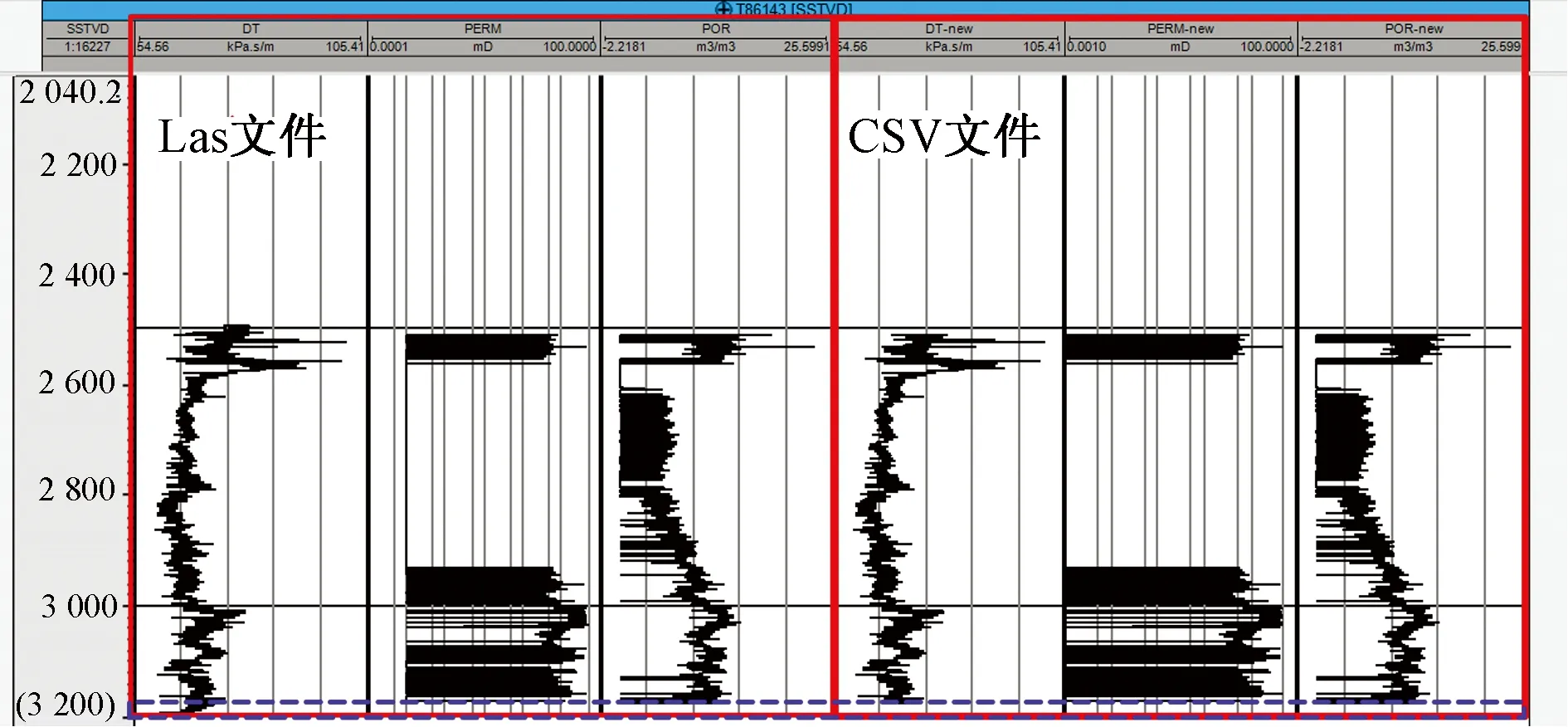
图10 测井曲线可视化比较Fig.10 Log visualization comparison
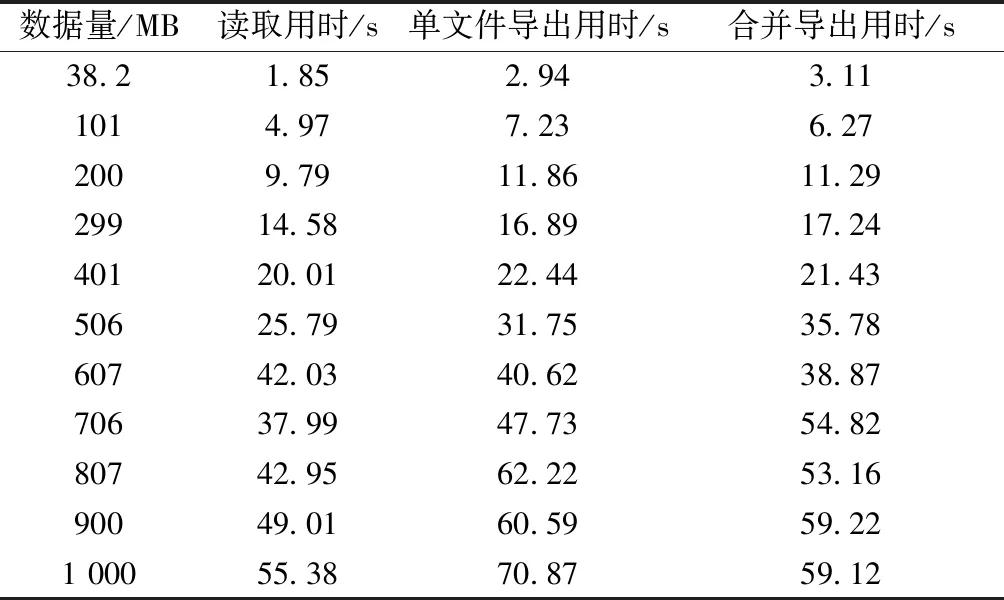
表1 转换器运行用时表Table 1 The converter operation time table

图11 转换器运行效率Fig.11 Converter operating efficiency
5 结论
(1)测井文件存在多种数据组织格式,其中Las格式文件是目前测井领域比较通用的文件,通过将其组织结构进行解析,转换为CSV格式文件,便于深度学习方法的应用。
(2)转换器用户交互界面良好,主要实现了:读取解析Las文件,后台自动剔除无效数据;可以选择需要的曲线属性;可以对所选曲线进行选择或去除指定值;可以成功导出CSV格式文件,并提供分文件和合并文件导出选择。
(3)使用实例数据进行了效果检验,表明转化效率较高。
猜你喜欢
测井技术(2022年3期)2022-11-25 21:41:51
中国煤层气(2021年5期)2021-03-02 05:53:12
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26 06:03:48
电子测试(2018年1期)2018-04-18 11:52:49
中国煤层气(2015年4期)2015-08-22 03:28:01
淮南师范学院学报(2015年3期)2015-03-22 01:16:16
中国质量与标准导报(2015年2期)2015-02-28 22:27:15
