
基于灰狼优化算法的车牌字符识别研究
2021-02-25 13:29陈科全吴耀光陈一铭穆协乐张铁异
物联网技术 2021年2期
陈科全,吴耀光,陈一铭,穆协乐,张铁异
(广西大学 机械工程学院,广西 南宁 530004)
0 引 言
为了便于机动车的管理,车牌识别系统的完善变得越来越重要。车牌识别系统中主要包含了图像提取、车牌定位、字符分割和字符识别四大模块[1]。字符识别作为识别系统中的最后一个环节,对车牌识别的成功与否起到了决定性的作用,识别方法主要包括模板匹配、特征提取识别、支持向量机(SVM),以及卷积神经网络等。模板匹配[2]识别通过模板匹配函数计算待识别字符与模板字符之间的相似度来实现,字符模板的质量对字符识别的准确率影响较大,待识别字符如果有一定角度的倾斜会造成识别错误。特征提取识别[3]利用字符特征的相似度进行字符识别,根据提取的字符特征进行判别和匹配,字符特征的选择决定了识别正确率。采用支持向量机[4]分类时,惩罚系数C和核参数g的选取会对字符的分类结果造成影响。陈政等采用粒子群优化算法对SVM的参数进行寻优,一定程度上提高了SVM的识别准确率[5]。随着深度学习的发展,CNN[6]被广泛应用于字符识别中,该方法通过监督学习自动进行图像提取和识别,具有较强的鲁棒性,但需要大量的样本进行网络训练,而且对硬件要求高。
基于以上分析,提出一种基于灰狼优化车牌字符识别方法,优化SVM参数,建立识别模型,提高字符识别准确率。
1 车牌字符的识别流程及理论基础
文中主要针对车牌识别系统四大模块中的最后一个模块—字符识别展开研究,其他模块此处不再赘述。为保证识别数据与训练数据集的格式相同,首先对分割后的图像进行归一化处理,并设定每种字符图片的标签信息,然后提取车牌字符的HOG[7]特征,建立SVM字符分类模型,利用改进收敛因子的GWO[8]对SVM参数C和高斯核函数参数g进行寻优,建立IGWO-SVM模型,获取车牌字符识别结果。
1.1 灰狼优化算法
灰狼优化算法(GWO)是一种启发式优化算法,由Mirjalili.S[9]等人提出,该算法所需设置的参数较少,原理简单,速度快,全局搜索能力强。灰狼种群等级分为四类,其中α狼为取得最优解的搜索个体,自适应度最优,β狼和δ狼分别为次优解和第三优解的搜索个体,自适应度同理,ω狼的等级最低,为其他候选解的搜索个体。

式中:D代表狼群个体与目标猎物之间的距离;C=2r1代表对猎物的扰动,r1为[0,1]之间的随机数;t代表迭代次数;XP为目标所在位置;X为狼群个体位置。
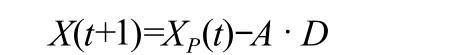

指导狼群靠近猎物,如图1所示。寻优过程:

Xα,Xβ,Xδ分别代表α狼,β狼和δ狼的当前位置。

式中:X1,X2,X3分别代表α狼,β狼和δ狼对ω狼指导后的位置;X(t+1)为子代灰狼的最终位置。
为了防止GWO算法陷入局部最优,采用改进收敛因子a的GWO算法[10],将原始的线性收敛因子改为非线性:

改进后的a将从2非线性递减到0,可降低衰减速度,更利于寻找全局最优解。
1.2 支持向量机(SVM)
SVM是一种非常高效的分类算法,通过降低结构化风险系数来提高分类模型的泛化能力,可以在样本数量较少时获得良好的分类效果。

式中:xi∈Rn,i=1, 2, ...,n,表示第i个特征向量,yi={+1, -1},表示特征标签,yi=+1时,xi为正样本,反之,xi为负样本,SVM通过在正负样本之间建立一个超平面,将样本分为两类。通过最大化正负样本的分类间隔,提高模型的泛化能力:

式中,w表示分离超平面的法向量,方向指向正样本。
除了线性可分问题外,SVM也适用于非线性分类问题,需引入松弛变量ξ≥0和惩罚因子C≥0,保证容错性:
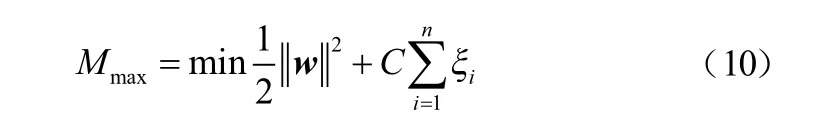
构造拉格朗日函数,并求解对偶问题:

引入核函数K(xi,xj)将低维数据映射到高维空间,并通过核函数的内积运算将高维的复杂运算转化为低维的简单运算,简化线性不可分问题。

式中,αi、αj为拉格朗日系数。
分离超平面:
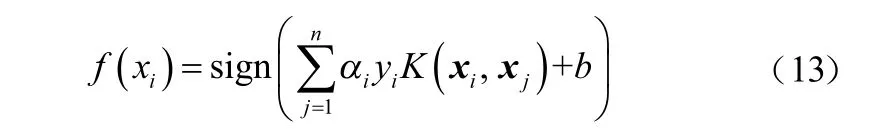
式中,b表示截距。
由于高斯核函数对不同的数据类型具有良好的适应性,且参数少,即选用高斯核函数:

SVM常用于处理二分类问题[11],车牌字符分类属于多分类问题,组合多个二分类SVM可以构建一个多分类SVM。本文组合构建两个分类器,分别用于汉字字符、字母和数字字符分类。考虑到字符的标签多样性,故采用字符的错误率作为自适应函数。
1.3 HOG特征提取
方向梯度直方图(Histogram of Oriented Gradient, HOG)是图像处理中常用的图像特征描述子。提取HOG特征时,先要对图像进行灰度化处理,对颜色空间进行归一化处理,然后将图像划分为多个cell单元,其中2×2个cell单元组成一个block块,由式(16)~式(19)计算每个block中cell单元的梯度信息,最后将所有HOG特征进行归一化处理,得到图像的HOG特征。
X方向梯度:

Y方向梯度:
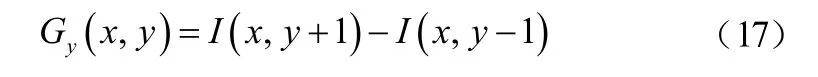
像素点梯度的幅度:

像素点梯度方向:

式中,I(x,y)表示图像中像素点(x,y)处的水平方向和竖直方向的像素值。
2 改进灰狼优化算法的SVM分类模型研究
GWO优化的SVM模型流程如图2所示。初始化参数时需对狼群数量、迭代次数、寻优参数上下界、优化参数的个数,根据设置的参数生成随机的惩罚系数C和核函数参数g的向量,每次循环取一组数据训练SVM,并得到自适应函数值。采用改进收敛因子的GWO算法优化SVM,以测试集分类错误的个数作为自适应函数,最小化错误率,求得自适应函数值,根据自适应度值更新α狼、β狼和δ狼的位置,然后在三种狼的指导下根据式(1)~式(7)更新其他狼群的位置,完成迭代,获得最优参数,训练SVM模型。
3 寻优算法实验对比分析
本文选取了13 033张车牌字符进行模型训练,其中汉字字符2 470张,数字和字母2 470张;3 439张车牌字符作为测试样本,其中汉字字符2 601张,数字和字母838张;拍摄650张车牌用于验证各算法的准确率,并进行实验分析。汉字SVM各优化算法对比见表1所列,字母和数字SVM各优化算法对比见表2所列。

图2 基于GWO优化的SVM模型流程
PSO-SVM的粒子群数为50,最大迭代次数为20,惯性因子ω=0.8,局部学习因子c1=2,全局学习因子c2=2,参数值的上界为20,下界为0.01;GA-SVM种群数为50,最大迭代次数为20,染色体数为20,基因长度为20,交叉概率阈值pc=0.6,变异概率阈值pm=0.01;GWO-SVM与IGWOSVM的狼群数量为20,最大迭代次数为20,参数值的上界为20,下界为0.01。

表1 汉字SVM各优化算法对比

表2 字母和数字SVM各优化算法对比
从表1和表2的数据可以看出,在测试向量集中,四种寻优算法对训练集和测试集的识别准确率差别不大。文中提出的IGWO-SVM在车牌字符识别中综合效果更好,其中汉字SVM中IGWO-SVM与未优化的SVM相比,车牌识别准确率提高了4%,与GA-SVM识别率相同,高达92.92%,在寻优时间方面,改进GWO算法比GA算法缩短了近37%;在字母和数字SVM中,IGWO-SVM准确率比未优化的SVM提高了0.62%,比PSO-SVM和GA-SVM高出0.57%,寻优时间缩短了31%和32%,优势明显。
4 结 语
针对车牌字符识别的问题,提出了应用改进收敛因子的灰狼优化算法对SVM的惩罚系数C和高斯核参数g进行寻优,建立SVM模型,并与其他方法建立的SVM模型对比。文中提出的方法与粒子群和遗传算法优化后的SVM分类准确率相当甚至更佳,但是在模型训练时间上几乎只用后两者的二分之一,实际应用过程中,在保证准确率的同时可以极大降低时间成本,综合表现优势明显。
猜你喜欢
电子制作(2019年12期)2019-07-16
小太阳画报(2019年1期)2019-06-11
数学大王·低年级(2018年5期)2018-11-01
成都信息工程大学学报(2017年3期)2017-11-09
电子制作(2017年22期)2017-02-02
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01
快乐语文(2016年15期)2016-11-07
华东理工大学学报(自然科学版)(2015年2期)2015-11-07
读写算(中)(2015年6期)2015-02-27
河南科技(2014年3期)2014-02-27
