
融合Multiscale CNN和BiLSTM的人脸表情识别研究
2021-02-22 06:58李军李明
北京联合大学学报 2021年1期
李军 李明


[摘要]为了有效改善现有人脸表情识别模型中存在信息丢失严重、特征信息之间联系不密切的问题,提出一种融合多尺度卷积神经网络(Multiscale CNN)和双向长短期记忆(BiLSTM)的模型。BiLSTM可以增强特征信息间的联系与信息的维持,在Multiscale CNN中通过不同尺度的卷积核可以提取到更加丰富的特征信息,并通过加入批标准化(BN)层与特征融合处理,从而加快网络的收敛速度
,有利于特征信息的重利用,再将两者提取到的特征信息进行融合,最后将改进的正则化方法应用到目标函数中,减小网络复杂度和过拟合。在JAFFE和FER2013公开数据集上进行实验,准确率分别达到了95.455%和74.115%,由此证明所提算法的有效性和先进性。
[关键词]多尺度卷积神经网络;双向长短期记忆;特征融合;批标准化层;正则化
[中图分类号]TP 391.41[文献标志码]A[文章编号]10050310(2021)01003505
Research on Facial Expression Recognition Based on the
Combination of Multiscale CNN and BiLSTM
Li Jun, Li Ming
(School of Computer and Information Science,Chongqing Normal University,Chongqing 401331,China)
Abstract: In order to effectively improve the problems of serious information loss and inadequate connection between feature information in the existing facial expression recognition model, a model combining Multiscale Convolutional Neural Network (Multiscale CNN) and Bidirectional Long and ShortTerm Memory (BiLSTM) is proposed. BiLSTM can enhance the connection between feature information and the maintenance of information. In Multiscale CNN, richer feature information can be extracted by convolution kernels of different scales. After adding a Batch Normalization (BN) layer and feature fusion processing in order to accelerate the convergence rate of the network and increase the reuse of feature information, and then by fusing the feature information extracted by the two, the improved regularization method is applied to the objective function to reduce network complexity and overfitting. Experiments on the public data sets of JAFFE and FER2013 have achieved accuracy rates of 95.455% and 74.115%, respectively, which proves the effectiveness and advancement of the proposed algorithm.
Keywords: Multiscale Convolutional Neural Network(Multiscale CNN); Bidirectional Long and ShortTerm Memory(BiLSTM); Feature fusion; Batch Normalization(BN) layer; Regularization
0引言
人臉表情是人与人之间信息沟通的有效途径之一[1],随着科技的不断发展,人脸识别技术应用的领域越来越广泛,例如教育、交通、医疗等领域。传统的人脸表情识别技术有几何特征[2]、稀疏表示[3]和局部二值模式[4],人工智能与大数据的发展使得神经网络备受瞩目,研究者开始将卷积神经网络[5]和3D卷积神经网络[6]应用于人脸表情识别中。卷积神经网络是特征提取的最有效方法之一,所以被广泛应用于图像处理和图像识别领域中,并且取得了较好的研究成果。当前主流的方法是CNN与RNN的结合[7]和特征融合[8]等,但仍然存在信息丢失与组件间联系不密切等问题。造成这些问题的原因是卷积神经网络对图像的理解粒度太粗,池化操作丢失了一些隐含信息,从而限制了模型的学习能力。卷积核能够理解非常细微的局部特征,池化操作能够让局部特征更加明显,而对人脸表情识别必须突出局部特征来学习表情的分类,所以池化操作在人脸表情识别中是非常重要的,也是必不可少的一部分。但是,也不能忽略特征信息之间的综合联系,例如,不能仅仅通过嘴角上扬就判断出人脸表情为开心,如果嘴角上扬的同时眉头紧皱,那么这种表情则为伤心。所以,在神经网络训练的过程中,要综合全部信息来决定分类结果,特征信息需要满足信息丰富、特征信息之间联系密切及特征信息维持时间长等条件。
多尺度卷积神经网络的出现使得特征信息更加丰富,研究者开始将多尺度卷积神经网络应用于单目深度估计[9]、图像增强[10]和人脸识别中[11]。本文将多尺度卷积神经网络与双向长短期记忆相融合,提出一种融合多尺度卷积神经网络(Multiscale CNN)与双向长短期记忆(BiLSTM)的模型。
1理论基础
1.1BiLSTM
LSTM可以很好地解决梯度消失和梯度爆炸的问题,LSTM元胞中有输入门、输出门和遗忘门。输入门决定输入哪些信息,遗忘门决定保留哪些信息,输出门决定输出哪些信息。相关公式如式(1)~(5)所示[12]。
ft=Q(w1×[at-1,xt]+b1),(1)
It=Q(w2×[at-1,xt]+b2),(2)
Ut=tanh(w3×[at-1,xt]+b3),(3)
Yt=Q(w4×[at-1,xt]+b4),(4)
Ot=tanh(ft×Ct-1+It×Ut)×Yt。
(5)
其中,xt代表输入信息,at-1和Ct-1代表上文信息,在xt和at-1堆叠后被复制成4份;w1代表遗忘权重,w2代表输入权重,w3代表生成候选记忆权重,w4代表输出权重;Q代表sigmoid激活函数,映射到[0,1]区间中,0代表全部抑制,1代表全部激活;tanh函数用于生成候选记忆,值域为[-1,1]。
双向LSTM存在两种类型的元胞,即前向元胞和后向元胞,双向LSTM的输出层不仅依赖之前的输入,还会依赖后面的元素,这就增加了信息的交流与维持,充分利用了数据。具体过程如式(6)~(8)所示[12]。
A1=f(X1×U+w×A2),(6)
a1=f(X1×u+a0×W),(7)
Y1=S(V×A1+v×a1)。(8)
其中,U和u代表输入层到隐藏层的权重,V和v代表隐藏层到输出层的权重,W和w代表隐藏层之间的权重,f是激活函数,S是分类函数,通常用于二分类的是sigmoid函數,用于多分类的是softmax函数。
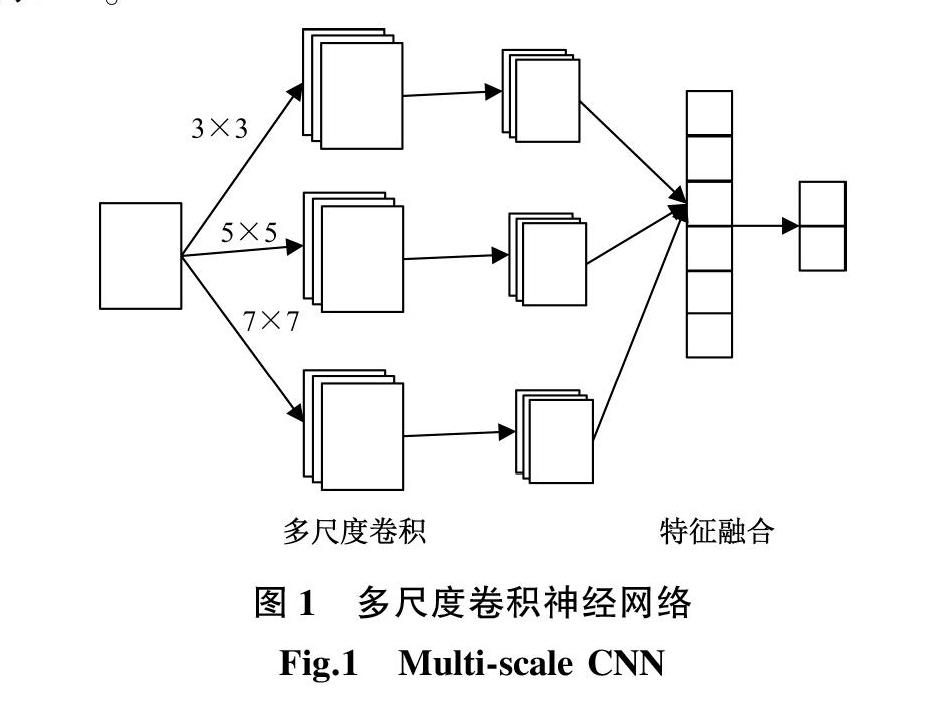
1.2多尺度卷积神经网络
多尺度卷积神经网络是使用多个不同尺寸的卷积核对图像进行卷积,再分别进行池化操作,然后将结果连接,最后进行分类处理,如图
1所示[13]。
多尺度卷积神经网络通过不同尺寸的卷积核提取特征,可以增加特征图的数量,使得提取的信息更加丰富。多尺度卷积神经网络的
训练效果虽然优于基准卷积神经网络,但是存在训练不稳定的缺陷,主要原因是特征信息之间联系不密切和特征利用不够充分。
2模型建立
首先,通过Multiscale CNN和BiLSTM分别对图像进行特征提取;再将提取到的特征信息进行融合,丰富特征信息;最后,通过全连接层和分类层得到输出结果,模型结构如图2所示。BiLSTM可以加强特征信息之间的联系与信息的维持,Multiscale CNN通过不同尺度的卷积核可以提取更加丰富的特征信息。在Multiscale CNN中每个卷积层后加入BN层,能够加快网络的收敛速度,将上一层的特征信息与多尺度卷积后的特征进行融合,有利于特征信息的重利用,在BN层后加入最大池化操作,使得特征信息更加明显。
2.1改进的Multiscale CNN
本文改进的多尺度卷积神经网络的具体结构如图3所示。
1) 多尺度卷积:通过不同的卷积核提取特征,可以得到更加丰富的特征信息,一定程度上减少了信息的丢失。
2) 特征融合:在每一次卷积操作后,都会将前一层的特征信息进行融合,并将每层不同尺度的卷积神经网络提取出的特征进行融合,可以增强信息的重利用。
3) BN层:在卷积层后加入BN层,能够加快网络的收敛速度,使网络更加稳定。
4) 池化层:池化层可以让特征更加明显,本文采用最大池化操作,池化区域为2×2,步长为2,池化后的特征图分辨率变为原来的1/2。
BiLSTM中的前向元胞与后向元胞的神经元个数均为360个,经过BiLSTM后输出为
720,对其进行变形,使大小与Multiscale CNN输出的大小一致,变为6×6×20;再与Multiscale CNN的输出进行特征融合,输出由像素为6×6的916个图像组成,将这些图像展开为一个一维向量,长度为6×6×916;将这个向量作为输入传入含有625个神经元的全连接层,最后再传入输出层,由含有7个神经元的全连接层组成。
2.2改进的正则化方法
正则化方法是指通过在模型中加入某种指定的正则项从而达到某种特定目的的方法,常用来减小测试误差,增强模型的泛化能力。传统的正则化方法有L1正则化和L2正则化。
L1正则化通过对原目标函数加上所有特征系数绝对值的和来实现正则化。具体公式如(9)和(10)所示,其中C0是原始的损失函数,λnni=1Wi是L1正则化项,λn是正则化系数,W是权值,sgn是符号函数。L1正则化对于所有的权重均给予同样的惩罚,所以较小的权重也很容易产生特征系数为0的情况,由于大量模型参数变为0,因此达到了稀疏化的目的。但是如果盲目使用L1正则化,在遇到共线性很高的多个特征时,只会选择其中一个特征,所以会导致误差较大的结果。
C=C0+λnni=1Wi。(9)
CW=C0W+λnsgn(W)。(10)
L2正则化通过对原目标函数加上所有特征系数的平方和来实现正则化,L2正则化的优点是面对多个共线性特征的时候,会将权值平分给这些特征,从而保留有用的特征。具体公式如(11)和(12)所示,其中C0是原始的损失函数,λ2nni=1W2i是L2正则化项,λ2n是正则化系数,W是权值。可以发现,L2正则化对于绝对值较大的权重给予较大的惩罚,对于绝对值很小的权重给予非常小的惩罚,当权重接近于0时,基本不惩罚,因此使得模型的参数趋于0,而不是等于0,也就是做不到稀疏化。
C=C0+λ2nni=1W2i。(11)
CW=C0W+λnW。(12)
对正则化参数的选择一直是一个较难解决的问题,参数选择过大容易产生欠拟合,参数选择太小容易产生过拟合。针对以上问题,本文对正则化方法进行了改进,将L1正则化与L2正则化进行融合,结合两者优点,再设计自适应的正则化参数,具体公式如式(13)和(14)所示。
minw=(λt‖W‖1+λt‖W‖22)。(13)
λt=λmin+(λmax-λmin)
e-10iN。(14)
其中,‖W‖1代表W的1范式,‖W‖2代表W的2范式,λmin代表最小值的正则化参数,λmax代表最大值的正则化参数,i代表当前的迭代次数,N代表模型迭代的总次数。根据公式(14),当迭代次数为0时,λt为λmax;当迭代次数增加时,e-10iN随之减小,无限趋近于0,也就是当迭代次数达到迭代总次数时,λt为λmin。由此,使得模型在最大值与最小值之间选取出最合适的参数,本文中λmax为1,λmin为0.001。
3数据集与实验结果
3.1数据集
本文采用的数据集有两种:一种是JAFFE人脸表情数据集,包括213张图片,由10名日本女性的正面人脸表情组成,本文将数据集裁剪为48×48,随机打乱数据,并以9∶1分为训练集和测试集;另一种是FER2013人脸表情数据集,是由Kaggle人脸表情识别挑战赛提供的数据集,由35 887张人脸表情图片组成,训练集有28 709张,公共测试集和私有测试集各有3 589张,本文在私有测试集上进行测试。两种数据集均有7种表情,分别为愤怒、厌恶、恐惧、高兴、悲伤、惊讶和中性。
3.2实验结果和分析
实验环境为Windows 10操作系统、python编程语言,采用TensorFlow深度学习框架,在谷歌提供的Colab平台上使用GPU资源进行实验。
首先,在JAFFE数据集上进行實验,批处理样本设为32,学习率设为0.000 5,总迭代次数为70次,经过27次迭代训练之后,在JAFFE测试集进行测试,准确率达到95.455%。达到最优时,通过公式(14)计算,λt的值为0.021。本文所提方法与其他方法在JAFFE测试数据集上准确率的对比,如表1所示。
其次,在FER2013数据集上进行实验,批处理样本设为128,学习率设为0.005,总迭代次数为380次,经过170次迭代训练后,在FER2013私有测试集上进行测试,准确率达到74.115%,达到最优时,通过公式(14)计算,λt的值为0.012。本文所提方法与其他方法在FER2013测试数据集上准确率的对比,如表2所示。
4结束语
本文提出了融合Multiscale CNN和BiLSTM的模型,可以融合各自的特点,丰富特征信息,增强特征信息之间的联系,并将改进的正则化方法应用到目标函数中,减小了过拟合。实验证明,与其他方法相比,本文方法在JAFFE和FER2013人脸表情识别数据集上的准确率较高,下一步的研究目标是在保证准确率的前提下减少模型训练的时间。
[参考文献]
[1]叶继华,祝锦泰,江爱文,等.人脸表情识别综述[J].数据采集与处理,2020,35(1):21-34.
[2]COOTES T F, TAYLOR C J, COOPER D H, et al. Active shape modelstheir training and application[J]. Computer Vision and Image Understanding, 1995, 61(1): 38-59.
[3]WANG W, XU L H. A modified sparse representation method for facial expression recognition[J].Computational Intelligence and Neuroscience, 2016:5687602.
[4]GOYANI M M, PATEL N. Recognition of facial expressions using local mean binary pattern[J]. Electronic Letters on Computer Vision and Image Analysis, 2017, 16 (1): 54-67.
[5]LOPES A T, AGUIAR E D, SOUZA A F D, et al. Facial expression recognition with convolutional neural networks: coping with few data and the training sample order[J]. Pattern Recognition, 2017, 61:610-628.
[6]BYEON Y H, KWAK K C. Facial expression recognition using 3D convolutional neural network[J]. International Journal of Advanced Computer Science & Applications, 2014, 5
(12): 107-112.
[7]LIANG D, LIANG H, YU Z, et al. Deep convolutional BiLSTM fusion network for facial expression recognition[J]. The Visual Computer, 2020, 36(3):499-508.
[8]HUANG G, LIU Z, VAN DER MAATEN L, et al. Densely connected convolutional networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 4700-4708.
[9]LIU J W, ZHANG Y Z, CUI J H, et al. Fully convolutional multiscale dense networks for monocular depth estimation[J].IET Computer Vision, 2019,13(5):515-522.
[10]AUDEBERT N, LE SAUX B, LEFVRE S. Semantic segmentation of earth observation data using multimodal and multiscale deep networks[C]//13th Asian Conference on Computer Vision (ACCV 2016).Taipei: Springer, 2016:180-196.
[11]MIN W, FAN M, LI J, et al. Realtime face recognition based on preidentification and multiscale classification[J]. IET Computer Vision, 2019, 13(2):165-171.
[12]ZACCONE G, KARIM R M, MENSHAWY A. TensorFlow深度学习[M].李志,译.北京:人民邮电出版社,2018.
[13]李金洪.深度学习之TensorFlow工程化项目实战[M].北京:电子工业出版社,2019.
[14]GU W F, XIANG C, VENKATESH Y V, et al. Facial expression recognition using radial encoding of local Gabor features and classifier synthesis[J]. Pattern Recognition, 2012, 45(1): 80-91.
[15]何志超, 赵龙章, 陈闯. 用于人脸表情识别的多分辨率特征融合卷积神经网络 [J]. 激光与光电子学进展, 2018, 55(7): 370-375.
[16]UCAR A, DEMIR Y, GUZELIS C. A new facial expression recognition based on curvelet transform and online sequential extreme learning machine initialized with spherical clustering[J]. Neural Computing and Applications, 2016, 27(1): 131-142.
[17]张立志,王冬雪,陈永超,等.基于GMRF和KNN算法的人脸表情识别[J].计算机应用与软件,2020,37(10):214-219.
[18]刘涛,周先春,严锡君.基于光流特征与高斯LDA的面部表情识别算法[J].计算机科学,2018,45(10):286-290+319.
[19]CHANG T Y, WEN G H, HU Y, et al. Facial expression recognition based on complexity perception classification algorithm
[Z/OL].(2018-03-01)[2020-11-06].https://arxiv.org/ftp/arxiv/papers/1803/1803.00185.pdf.
[20]吕诲,童倩倩,袁志勇.基于人脸分割的复杂环境下表情识别实时框架[J].计算机工程与应用,2020,56(12):134-140.
[21]李旻择,李小霞,王学渊,等.基于多尺度核特征卷积神经网络的实时人脸表情识别[J].计算机应用,2019,39(9):2568-2574.
[22]兰凌强,李欣,刘淇缘,等.基于联合正则化策略的人脸表情识别方法[J].北京航空航天大学学报,2020,46(9):1797-1806.
[23]张爱梅,徐杨.注意力分层双线性池化残差网络的表情识别[J/OL].计算机工程与应用,(2020-08-06)[2020-11-06].http://kns.cnki.net/kcms/detail/11.2127.TP.20200805.1832.032.html.
(責任编辑白丽媛)
