
基于面向对象随机森林方法的滨海湿地植被分类研究
2021-02-22 04:00李玉凤刘红玉
南京师范大学学报(工程技术版) 2021年4期
宗 影,李玉凤,刘红玉
(南京师范大学海洋科学与工程学院,江苏 南京 210023)
遥感因其数据获取方便、监测范围广被逐渐应用到农田湿地的分类研究中. 目前,利用遥感进行分类的方式包括基于像素和对象两种[1]. 基于像素的分类以单个像素为最小单元,分类时只考虑到地物的光谱、大小与位置信息[2],但这种分类方式会产生椒盐现象从而制约分类的精度. 而面向对象分类以合并之后的对象为基本处理单元,减少了分类破碎的现象,可以同时考虑地物的光谱、纹理等信息,分类精度更高、提取效果更好[3-5],目前被广泛应用于植被的分类中. 如邵亚婷等[6]使用面向对象的分类方法对盐城滨海湿地的植被进行分类,6个时期的影像分类精度均达到90%以上. 张蓉等[7]以Landsat多时相影像为数据源,用面向对象的分类方法对大珠江三角洲的红树林进行分类,分类精度均保持在85%以上. 随着大量遥感卫星的发射和计算机技术的发展,神经网络、决策树与随机森林等方法逐渐运用到地物分类中,并得到较高的分类精度[8-9]. 其中随机森林分类方法能够利用样本之间存在的差异,并且可以更好的处理高维数据[10-11]. 随机森林方法对农田、湿地植被的分类,都取得了较好的分类结果. 如张磊等[12]基于 Sentinel-2 数据利用不同的特征组合对黄河三角洲的植被进行提取,并用随机森林模型进行分类,总体精度高达90.93%. 刘家福等[13]利用融合后的Landsat OLI影像在特征优选的基础上构建随机森林模型提取黄河口滨海湿地植被,取得了较好的分类效果. 谷晓天等[14]基于Landsat OLI影像数据、DEM数据,用多种分类方法对复杂地形的土地利用类型进行分类,研究表明随机森林的分类效果最好. 目前已有部分学者使用随机森林与面向对象分类方法相结合进行滨海湿地植被的分类[15-17],但是大部分研究都是以高分辨率影像为数据源包括GF-2、QuikBird与无人机影像,这些高分辨率的影像价格昂贵,应用于大尺度遥感提取的方法成本较高.
另外,当前湿地分类研究主要集中于内陆湿地,对滨海湿地遥感分类研究较少,且存在不足. 由于滨海湿地是海陆相互作用形成的特殊地理区域,湿地形成与演变处于高度动态变化中. 江苏滨海湿地主要分布于盐城海岸,是典型淤泥质潮间带湿地,以草本湿地植被类型为主要特征,空间上动态演变十分明显,各类型之间交错带植被分布较为复杂. 因此,如何利用遥感方法对其进行分类,成为区域湿地分布研究的重要科学问题. 因此本文以Sentinel-2影像为数据源,通过面向对象与随机森林结合的算法,试验不同的特征组合方案的分类精度,找出适合盐城滨海湿地分类的最佳特征组合,以提高区域内植被的分类精度.
1 研究区概况与数据来源
1.1 研究区选择
选择江苏典型滨海湿地分布区为研究对象. 该区位于江苏盐城国家级珍禽自然保护区核心区,北临新洋港,南接斗龙港,面积1.92×104hm2(如图1所示). 湿地植被类型以芦苇、碱蓬和互花米草为优势种群. 由于区域位于淤长型海岸地段,湿地以每年50~100 m速度向海淤进[18],在地形、地貌、土壤与水文等生态环境要素综合作用下,湿地植被类型自陆向海呈带状分布格局,并且处于高度敏感和动态演变过程中,各类型之间交错带植被分布十分复杂.

图1 研究区地理位置图Fig.1 Geographic location of the study area
1.2 数据来源与预处理
1.2.1 遥感数据
Sentinel-2遥感数据有13个波段,包括10 m、20 m和60 m 3种空间分辨率(如图1(b))所示. 其中红光波段(B4)、绿光波段(B3)、蓝波段(B2)、近红外波段(B8)分辨率为10 m;红边波段(B5、B6、B7)、近红外波段(B8A)、短波红外波段(B11、B12)分辨率为20 m;海岸波段(B1)、水汽波段(B9)、卷云波段(B10)分辨率为60 m. 此数据分辨率较高,且包含易于植被区分的红边波段. 因此为开展盐城保护区核心区植被分类研究,选取2018年6月23日质量较好的Sentinel-2影像作为数据源. 数据从欧空局网站(https://scihub.copernicus.eu/)下载,数据级别为LIC级,此数据已经过几何校正和辐射校正,因此使用SNAP软件进行大气校正,大气校正后将所有波段分辨率重采样成10 m.
1.2.2 样本数据
本研究使用现场实测数据并结合2017年的GF-2影像(1m)采用目视解译方式进行样本点的选取. 2018年6月对研究区进行了现场采样,利用GPS对不同的植被类型样点进行定位,同时以GF-2影像为基础影像选取样本点以增加样本数量. 综合考虑影像的分辨率与前人研究内容,将研究区分为互花米草、芦苇、碱蓬、光滩和水体5种类别.
2 研究方法
2.1 面向对象影像分割
面向对象影像处理先对影像进行分割,分割之后对影像进行分类. 分割算法有棋盘分割、多尺度分割等[19]. 本研究使用的是多尺度分割算法,它对相邻像元或分割之后较小的对象进行合并,使对象内部像元之间的同质性最大[20],进行分割时分割尺度对分割的结果产生较大的影响. 本研究的分割尺度由eCognition9.0中的ESP2工具来确定,ESP2工具基于分割对象的局部方差(LV)及其变化率(ROC)度量尺度分割的合理性,ROC-LV曲线的峰值点所对应的尺度就是影像的最优分割尺度[21-22]. 本研究在ESP2分割结果的基础上,选出3个较高的峰值,然后分别试验峰值对应下3个尺度的分割效果. 由于本文研究植被的分类,形状参数对其分类影响不大,因此采用默认参数,其中形状因子为0.1,紧密度为0.5,各波段权重设为1,影像的分割结果如图2所示,选取95、120与127分别进行分割,对比植被在3个尺度下的分割效果,选取的最终分割尺度为95.

图2 最优分割尺度估计结果Fig.2 Optimal segmentation scale estimation results
2.2 特征变量提取
研究区主要由水体和植被组成,因为水中含有泥沙,其反射率会在可见光波段增加[23]. 植被光谱特征在可见光、近红外波段表现出双峰和双谷的特征,即在红光波段吸收而近红外波段高反射和高透射,常利用这两个波段进行相关运算对植被进行分类,同时纹理特征也可以提高分类的精度. 因此本文选取灰度共生矩阵计算纹理特征,共选取植被指数、水体指数、光谱特征与纹理特征4种类型的特征变量. 具体特征指标如表1所示.

表1 影像对象的分类特征描述Table 1 Description of classification features of image objects

表2 不同试验方案组合Table 2 Combination of different test scenarios
在eCognition9.0中分割的基础上,计算表1所示的不同特征. 为了提高湿地植被的分类精度,并探究不同的特征对于分类的重要性,将表1所示的分类特征进行不同的组合,设计如表2所示的5种不同的组合进行试验,研究适合本研究区植被分类的特征组合.
2.3 随机森林分类算法
随机森林于2001年首次提出,以决策树为基本单元,将多棵决策树集合在一起的一种算法[24-25]. 每个决策树相当于一个分类器,随机森林包括两层的随机选择:随机选择样本数据和随机选择分类特征,这使得随机森林不易过拟合,具备很好的抗干扰能力[26].
随机森林建立可分为以下三步:(1)在所有样本中,采用随机且有放回的方式进行抽样,组成训练样本集,每个训练样本集的样本数大约为总样本数量的2/3. (2)对抽取的训练样本集进行训练,在决策树生长过程中,每棵树的每个节点处任意抽取特征,每个决策树根据输入的样本数据与特征进行分类. (3)重复(1)、(2),通过多次样本抽取和训练得到多个决策树模型,最后根据不同的决策树分类结果投票决定最终的分类结果.
2.4 特征优选方法
特征选择可以在多维特征中筛选出最有利于分类的特征子集,进而提升随机森林模型的效率和分类精度[27]. 选择袋外数据(out-of-bag,OOB)误差和Kappa系数进行模型评估以确定模型最优特征数量. 在模型训练过程中,通常将训练数据按7∶3的比例分为训练集和测试集,对测试集的预测值与真实值计算得到Kappa系数[28]. 而OOB误差是指在抽样的过程中约有1/3的原始样本数据未被选中. OOB误差是随机森林用未进行模型训练的袋外数据计算得到的泛化误差,可以表征特征的重要性(variable important,VI)[29]. 公式为
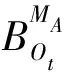
在特征重要性的基础上,采用递归消除法进行特征选择. 步骤如下:(1)计算所有特征的重要性并进行排序,选定要消除特征的比例. (2)以特征重要性为基础消除排序靠后的特征,得到新的特征集. (3)用新的特征集再次进行随机森林建模同时计算袋外误差率,重复此步骤,最后剩下M个特征[31]. 通过以上方式得到不同特征集和每个特征集对应的袋外误差率,选择袋外误差率较低和Kappa系数较高的特征作为最优特征集.
2.5 分类精度评价
以2017年9月14日经过融合后的GF-2影像数据为依据,在ArcGIS中生成500个均匀分布在整个研究区范围内的随机点作为验证样本. 通过对验证样本和分类结果的比较,得到混淆矩阵,从混淆矩阵中计算总体精度(OA)、制图精度(PA)、用户精度(UA)和Kappa系数对不同特征组合的分类结果进行评价.
制图精度(生产者精度)指影像被分类为A的像元数与实际A的像元数之比. 用户精度指影像正确分类为A的像元数和与分出的所有A类像元数之比. 总体精度指被正确分类的像元总和与总像元数之比. 而Kappa系数与总体分类精度相比,将漏分和错分的像元也同时考虑进来[32].

图3 2018年不同地物光谱曲线与指数图Fig.3 Spectral curves of different features and vegetation in 2018
3 结果与分析
3.1 地物光谱与特征优选分析
在ENVI5.3中以影像为基础,选取不同地物的纯净样本,统计不同地物类型的光谱反射率与部分植被指数值,组成数据集. 根据这些统计值做典型地物的光谱曲线,如图3所示. 图中地物的光谱特征存在差别,光滩、水体与植被单独使用光谱特征便可以进行区分. 3种植被的光谱信息较为相近,其中芦苇在红边波段至近红外波段(B6-B8A)与其他2种植被的光谱差异较大,但互花米草与碱蓬的光谱值极为相近,使用光谱特征难以区分. 由图3(c)可知,芦苇的各种指数反射率值较高且与其他两种植被差别较大,可以与其他2种植被进行区分,3种植被在REDNDVI的反射率有所差别,可以用来植被间的区分,而碱蓬与互花米草的另外3个指数的值十分相近,很难进行直接的区分. 虽然单波段与单指数可以实现个别地物的区分,但是区分效果不同且全部地物不能依靠单一特征进行有效区分,因此要对特征进行组合. 不同的植被指数、水体指数与光谱的组合对地物分类的作用不同,多个特征的组合会优于单个特征,但是特征数量过多又会增加数据的冗余度,因此找出合适地物分类的特征组合十分重要.
根据表1的分类特征与表2的实验方案,本文采用R软件实现随机森林模型的构建. 在模型训练中,需要对参数进行寻优,包括决策树的数量、特征数量、树的最大深度与叶节点最大数目等. 其中决策树的数量与特征的数量对模型分类精度影响较大,因此对这两个参数进行优化[33]. 首先采用逐一增加变量的方法建模,根据OOB误差确定用于分类的特征数量. 在特征数量确定后,建立相应的模型,并对其进行可视化分析,绘制模型误差与决策树数量的关系图,从而确定决策树的数量. 如图4为对所有的特征进行建模的决策树的数量与误差精度图. 可见,当树的数量大于700后,模型精度基本无变化,因此最终选取的决策树的数量为700.

图4 模型误差与决策树数量关系图Fig.4 Plot of model error versus number of decision trees
本文首先使用所有的特征进行建模,并对特征重要性进行计算排序,每次去掉排序靠后的20%的特征,然后使用其余的特征再次进行随机森林建模,在此基础上共进行13次迭代消除. 每次迭代消除后计算OOB误差与Kappa系数,根据OOB误差与Kappa系数进行特征的优选.
由图5可知,Kappa系数随着分类特征数量的不断减少呈现波动下降趋势,当分类特征数量减少到25时,模型精度上升. 随着特征数量的不断减少,精度总体呈下降趋势. 随着分类特征数量减少,OOB误差总体呈现较大的波动,可能是本研究选取的特征数量较少,因此每次迭代消除的数量也较少,使OOB缺乏规律. 最终,当剩余25个特征时Kappa系数最高为0.81,此时OOB误差也较小,因此选择重要性前25的特征作为最优特征集用于植被分类,选取的25个特征重要性排序如图6所示. 在排序靠前的特征中,植被指数占得比例较大,且得分较高.

图5 模型误差与特征数量关系图Fig.5 Map of relationship between model error and number of feature

图6 特征重要性得分图Fig.6 Map of feature importance ranking chart
3.2 提取结果及精度评价
5种不同方案的分类结果如图7所示,从分类图中可以定性地判断不同分类方案的分类效果. 方案1、方案2与方案3的分类效果较差,方案1中互花米草被错分为碱蓬的较多,部分芦苇也错分为碱蓬,方案2中较多芦苇被错分为互花米草,方案3中碱蓬与互花米草的交错带被错分为芦苇,方案4与方案5的分类效果相比于前3种方案分类效果较好,但方案4中也有部分的芦苇被错分为互花米草. 在所有的分类方案中,芦苇与互花米草交错带都出现了不同程度的错分,分析原因可能是相邻植被常常混生分布,之间没有明确的界限,在中等分辨率的影像中常以混合像元形式存在,从而导致湿地类型的误判断.
对5种试验方案的分类结果进行对比,由表3可知,方案1的总体精度为83%,Kappa系数为0.78,在所有方案里的分类精度最低. 方案2中植被指数与水体指数利用了波段之间的相互运算,分类精度有所提高. 方案3是光谱、植被指数与水体指数的综合分类,总体精度达到了84.50%,Kappa系数提高到了0.80,分类效果进一步提升. 方案4中在方案3的基础上加入了纹理特征,总体精度比方案3增高了0.1%. 方案5是按照特征重要性排序选出的优选组合,相比于前4种分类方案,总体精度为87.07,Kappa系数为0.84,在所有的分类方案中精度最高,分类效果较好.

图7 不同方案分类结果图Fig.7 Classification results of different scenarios
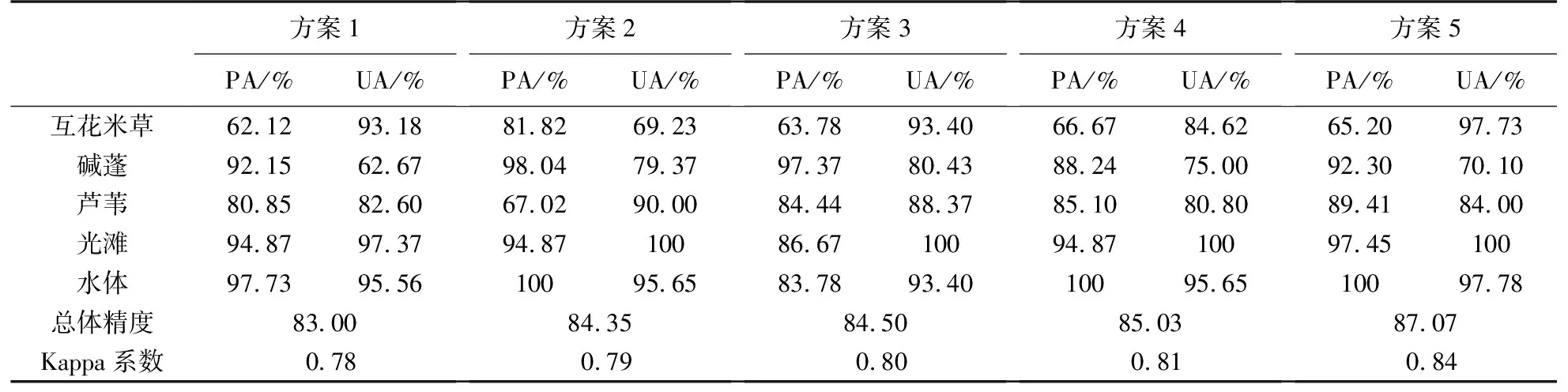
表3 分类结果精度统计Table 3 Classification results precision statistics
从植被的分类效果来看,5种分类方案中水体与光滩的分类精度均较高,这与分类图中展现的一致. 对于植被分类精度,经过特征优选的方案5互花米草的用户精度达到了97.73%,精度较高. 芦苇的用户分类精度为84%,而碱蓬分类精度较差. 本研究区内的3种植被的光谱特征较为相近,因此想通过增加分类特征进行区分,但是特征数量过多会增加数据的冗余,也不利于分类精度的提高. 通过特征优选对变量进行了部分筛选,通过分类图来看,植被整体的分类效果较好,但对于3种植被类型交错带部分,因植被之间的混生分布,导致植被的分类精度有所下降.
4 结论
本研究以Sentinel-2遥感影像为数据源,通过面向对象方法进行分割,结合ESP2工具确定分割尺度为95. 在分割的基础上计算光谱特征、植被指数、水体指数以及纹理特征4种基本特征变量,并且使用R构建随机森林模型进行特征重要性的计算及植被分类研究. 为了研究不同特征变量的分类精度设计了 5种试验方案,并用随机森林算法对不同方案的分类精度进行分析. 结果表明:以光谱数据为基础,增加不同特征变量对湿地分类的精度影响不同. 单独以光谱数据进行分类,分类效果较差,Kappa系数为0.78. 使用植被指数与水体指数结合分类,相比于使用光谱特征分类的效果好,Kappa系数提升为0.79. 光谱特征、植被指数与水体指数共同参与分类,分类效果进一步提升. 通过特征重要性选择出的特征优选组合相比于前4种方案,分类效果最好,总体精度为87.07%,Kappa系数为0.84. 说明基于特征优选的面向对象与随机森林相结合的分类算法对滨海湿地植被的分类效果较好,可以用于湿地的植被分类研究.
猜你喜欢
中国交通信息化(2022年7期)2022-10-27
科学技术创新(2022年30期)2022-10-21
航天返回与遥感(2022年2期)2022-05-12
波谱学杂志(2022年1期)2022-03-15
华北理工大学学报(自然科学版)(2021年3期)2021-07-03
课外生活·趣知识(2021年2期)2021-05-24
学校教育研究(2021年24期)2021-03-28
数码世界(2020年4期)2020-06-18
科学与信息化(2019年28期)2019-10-21
制导与引信(2017年3期)2017-11-02
