
基于DNN与规则学习的机器翻译算法研究
2021-02-22 11:34:28陶媛媛
计算机测量与控制 2021年1期
陶媛媛,陶 丹
(1.西安交通大学城市学院,西安 710000; 2.西安市曲江第一中学,西安 710000)
0 引言
随着翻译需求的增加,信息技术与语言学理论以及人工智能研究中自然语言理解模型的蓬勃发展,使得机器翻译逐渐受到了各领域专业技术人员瞩目[1-3]。Liu等[1]报道并系统地探索使用针对统计机器翻译(SMT)的深度(多层)神经网络(DNN)学习新功能的可能性。为了解决深度信念网络中特征学习的输入原始特征太简单,每个短语对的4个短语特征有限的问题,作者将一些简单但有效的短语特征作为新的DNN特征学习的输入特征进行了调整和扩展,并且这些特征已显示出SMT的显著改进,例如短语对相似性等。此外,在传统SMT和神经机器翻译(NMT)中,学习源语言的连续空间表示法已经引起了广泛的关注。目前已经提出了各种模型,主要是基于神经网络的模型来表示源句子,主要用作编码器-解码器框架中的编码器部分。在解码过程中仅对源句子的“相关”部分进行编码,Devlin等[4]提出的神经网络联合模型(NNJM),该模型扩展了n元语法目标语言模型,通过额外增加源句的固定长度窗口,实现统计机器翻译的最新性能。实验结果表明,与比较模型算法相比,基于深度神经网络与规则学习的统计机器翻译模型具有更好的效果,更快的收敛速度和更高的可靠性。深度神经网络作为一种新的机器学习方法,可以自动学习抽象特征表示并在输入和输出信号之间建立复杂的映射关[5-6]。
本文提出了一种新的卷积架构,以动态编码源语言中的相关信息。该模型涵盖了整个源句子,可以在目标语言的信息指导下有效地找到并适当地总结相关部分。利用解码过程中的引导信号,经过特殊设计的卷积体系结构可以查明与预测目标单词相关的源语句部分,并将其与整个源语句的上下文融合在一起以形成统一的表示形式。将之与目标词一起馈入深度神经网络(DNN)。联合模型的两个变体tagCNN和inCNN,并在解码过程中使用了不同的指导信号。联合模型集成到最新的依存关系的字符串翻译系统中用以评估其有效性,为统计机器翻译研究提供了新的切入点。
1 方法论
1.1 联合语言模型
CNN编码器的联合模型在图1中进行了说明,其中包括CNN编码器,即tagCNN或inCNN,以表示源语句中的信息,以及基于NN的模型CNN编码器的表示和目标句子中的历史单词作为输入来预测下一个单词。
在联合语言模型中,en表示目标词的概率,给定前k个目标词{en-k,…,en-1}和CNN编码器对源句子S的表示为:

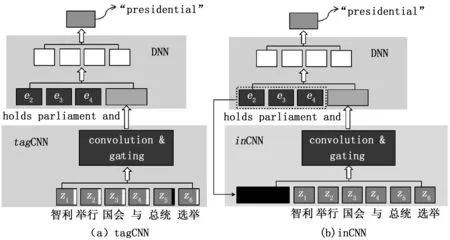
图1 基于CNN编码器的联合LM的示意图
例如图1的示例中,翻译的中文句子如下。
中文: 智利 举行 国会 与 总统 选举;
Pinyin: ZhiLi JuXing GuoHui Yu ZongTong XuanJu。
转换成英语,在评估目标语言顺序“holds parliament and presidential”时,以“holds parliament and”作为进行词(假设为4-gram LM),而“presidential”的从属源词1为“zongtong”(由单词对齐方式确定),tagCNN产生φ1(S,{4})(“ Zongongong”的索引为4),而inCNN产生φ2(S,{h(holds parliament and)})。之后,DNN组件将“ holds parliament and”和φ1或者φ2作为输入,以给出下一个单词的条件概率,例如p(“presidential”|φ1|2,{holds,parliment,and})。
1.2 卷积模型
1.2.1 通用CNN编码器
从卷积编码器的通用架构开始[7-8],然后继续将tagCNN和inCNN作为两个扩展。
通用CNN编码器的基本架构如图2所示,其固定架构由如下6层组成。
第0层:输入层,采用嵌入矢量形式的单词。工作中将句子的最大长度设置为40个单词。 对于短于此的句子,常在句子开头放置零填充。
第1层:第0层之后的卷积层,窗口大小为3。引导信号被注入到该层中作为“引导版本”。
第2层:第1层之后的本地门控层,仅对大小为2的非相邻窗口中的特征图进行加权求和。
第3层:在第2层之后的卷积层,开始执行另一个卷积,窗口大小为 3。
第4层:在第3层上对功能图执行全局选通。
第5层:完全连接的权重,将第4层的输出映射到该层作为最终表示。
如图2所示,第1层中的卷积在单词的滑动窗口(宽度k1)上运行,并且窗口的类似定义会延续到更高的层。形式上,对于源句子输入x={x1,…,xN}第L层上的f型特征映射的卷积单位为式(1):
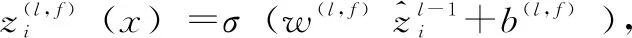
(1)
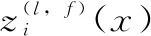

图2 CNN编码器示意图
1.2.2 门控
相关文献中CNN采用简单的卷积池策略[9],其中“融合”决策是基于要素图的值。在本质上而言,是一种软模板匹配,适用于诸如分类的任务,但对于保持卷积的合成功能作用不显著,然而,上述功能对于句子建模至关重要。本文使用单独的门控单元从卷积中释放得分函数的占空比,并使其更加注重于句子的合成。
采用两种类型的门控:(1)对于第2层,在第1层卷积的特征图上采用不重叠窗口的局部门控,以表示段;(2)对于第4层卷积,采用全局选通融合所有片段以实现全局表示。 并发现,这种选通策略可以显著改善tagCNN和inCNN的池化性能。
1)本地门控:在第1层上,对于每个门控窗口,首先在第0层上找到其原始输入(卷积之前),然后将它们合并为门控网络的输入。 例如,对于两个窗口:第0层上的单词(3,4,5)和单词(4,5,6),使用由嵌入单词(3,4,5,6)组成的串联矢量作为输入本地门控网络的输入以确定两个窗口(在第1层上)的卷积结果的权重,而加权和是第2层的输出。

(2)
1.2.3 CNN编码器训练
CNN编码器训练过程与神经网络语言模型的训练过程相同,除了使用并行语料库而不是单语语料库外,力求最大程度地提高训练样本的对数似然性,并为平行语料库中的每个目标单词提供一个样本[10]。优化是通过常规的反向传播来实现的,该实现是使用小批量的随机梯度下降实现的。
1.2.4 inCNN

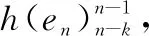
2 联合模型解码
本文的联合模型纯粹是词汇化的,因此可以作为功能集成到任何SMT解码器中[11-12]。对于分层SMT解码器,采用了Devlin等人提出的集成方法。正如从用于执行分层解码的n-gram语言模型继承的那样,应将每个组成部分中最左边和最右边的n-1个单词存储在状态空间中。通过扩展状态空间,以包括这些边词中每个词的关联源词的索引。对于对齐的目标词,将其对齐的源词作为其关联的源词。对于未对齐的单词,同样使用Devlin等人采用的从属关系启发式方法。在本文中,将联合模型集成到最新的依赖项到字符串机器翻译解码器中,作为案例研究来测试提出的方法的有效性。本节简要描述依赖项到字符串的转换模型与MT系统。
本文使用一般的对数线性框架。令d为将源依赖关系树转换为目标字符串e的推导。d的概率定义为式(2):

(2)
其中:φi是在导数上定义的特征,λi是相应的权重。其中解码器包含以下功能。
1)基准功能:
HDR规则的翻译概率P(t|s)和P(s|t);HDR规则的词法翻译概率PLEX(t|s)和PLEX(s|t);伪翻译规则惩罚exp(-1);目标词惩罚exp(|e|);n元语法模型PLM(e)。
2)提出功能:
n-gram tagCNN联合语言模型PLEX(e);CNN联合语言模型PLEX(e)中的n-gram。
3 实际应用
3.1 数据获取与预处理
1)数据获取:本文的培训数据是从LDC数据中提取的[13]。仅保留源对部分长度不超过40个单词的句子对,该句子对覆盖了90%以上的句子。双语训练数据由221 k句子对组成,其中包含500万个中文单词和680万个英文单词。经过长度限制过滤后,开发集为NIST MT03(795个句子),测试集为MT04(1499个句子)和MT05(917个句子)。
2)预处理:使用GIZA ++在语料库上使用“增长-确定-最终和”平衡策略[14],在两个方向上获得单词对齐。并采用SRI语言建模工具包在英语Gigaword语料库(3.06亿个单词)的新华语部分上训练了经过改进的Kneser-Ney平滑处理的4-gram语言模型。随后使用Stanford Parser将中文句子解析为映射依赖树。
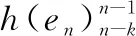
4)指标:本文使用不区分大小写的4-gram NIST BLEU3作为评估指标,在提出的模型和两个基准之间进行带有标志检验的统计学显著性检验。
3.2 设置模型比较
将tagCNN和inCNN联合语言模型用作依赖项到字符串基线系统(Dep2Str)的附加解码功能,并将它们与具有11个源上下文词的神经网络联合模型进行比较。除了全局设置外,还使用具有默认配置的开源工具包。由于本文提出的tagCNN和inCNN模型是从源到目标和从左到右的(在目标侧),因此,仅采用源到目标和从左到右的NNJM类型进行比较。以下将这种类型的NNJM称为BBN-JM。尽管Devlin等人中的BBN-JM最初是在基于分层短语的SMT和字符串到依赖关系SMT中进行测试的,但它可以很容易地集成到Dep2Str中。
3.3 实验结果与分析
表1给出了不同模型的主要结果。在进行更详细的比较之前,可获得以下信息:
1)基线Dep2Str系统的BLEU比基于开源短语的系统Moses高0.5+。
2)与Dep2Str相比,BBN-JM的得分约为+0.92 BLEU。
从表1可以明显看出,在相同设置下,tagCNN和inCNN在Dep2Str基线上的改善幅度为+1.28和+1.75 BLEU,在相同设置下,其BBN-JM分别优于NIST MT04和MT05的平均值+0.36和+0.83 BLEU。这些表明tagCNN和inCNN可以在解码中分别提供区分性信息。值得注意的是,inCNN似乎比单词对齐(GIZA ++)建议的附属单词更具信息性。因此,推测这是由于以下两个事实才成立的:
1)inCNN避免了在已经学习的单词对齐方式中错误和伪影响的传播;
2)inCNN中的指导信号提供补充信息以评估翻译。
此外,当将tagCNN和inCNN都用于解码时,可以进一步在BBN-JM上的获胜余量提高到+1.08 BLEU点。
通用CNN还能在BLEU上获得类似于BBN-JM的增益,因为,通用CNN编码整个句子,并且表示形式通常应远离联合语言模型的最佳表示形式。因此,可能是由于CNN对该句子产生了相当有益的总结,这弥补了其在分辨率和源词相关部分上的某些损失。换言之,tagCNN和inCNN中的引导信号对于基于CNN的编码器的功能至关重要,这可以从通用CNN,tagCNN和inCNN获得的BLEU得分之间的差异中看出。对于有了来自已经习得的单词对齐的信号,tagCNN可以比其通用对应词获得+0.25 BLEU,而对于inCNN,来自目标单词的引导信号,其增益更显著为+0.72 BLEU。
tagCNN可以进一步受益于在输入中用源语言编码的依赖关系结构。依赖项首词可用于进一步完善tagCNN模型。在tagCNN中,在输入层中的单词嵌入后附加一个标记位(0或1)作为它们是否隶属源词的标记。为了合并依赖头信息,本文扩展了标记规则,为原始tagCNN的词嵌入添加了另一个标记位(0或1),以指示它是否是附属词的依赖头的一部分。例如,如果xi是相关源词的嵌入,而xj是词xi的依赖头,则tagCNN的扩展输入将包含,式(3):
xi(AFF,NON-HEAD)=[xiT,1,0]T
xj(NON-AFF,HEAD)= [xjT,0,1]T
(3)
若从属源词是句子的词根,则由于词根没有依赖项头,因此本文仅将0作为第二个标记位附加。从表2中可以看出,借助依赖项头信息能够在两个测试集上将tagCNN平均提高+0.23 BLEU点。

表2 tagCNN模型的BLEU-4分数(%)
以inCNN模型的比较为例,研究了门控策略可在多大程度上改善最大池化的翻译性能。 对于使用最大池的inCNN实施,本文用大小为2(简称2池)的最大池替换本地门(第2层),用k个最大池(“第4层”)替换全局门(“第4层”),其中k为{2; 4; 8},然后将k池输出的平均值用作第5层的最终输入。这样可以确保第5层的输入维与具有门控的架构相同。从表3可以看出,门控策略可以比最大合并提高0.34,0.71 BLEU点的翻译性能。此外还发现8池收益率性能要优于2池。所以推测这是因为翻译中有用的相关部分主要集中在源句子的几个单词上,可以通过较大的库大小更好地提取这些单词。

表3 使用门控策略和k个最大池实施的inCNN>模型的BLEU-4分数(%)
4 结束语
本文提出了卷积架构,以获取整个源句的引导表示,该卷积架构可用于增强n-gram目标语言模型。利用来自目标端的不同指导信号,并设计了tagCNN和inCNN,两者都通过增强字符串对依赖关系的SMT进行了测试,其SMT比基线高+2.0 BLEU点。所提出的模型分别优于NIST MT04和MT05的平均值+0.36,+0.83 BLEU,比传统DNN机器翻译平均提高了+1.08 BLEU点。该模型为统计机器翻译方法研究提供了借鉴。
猜你喜欢
中国石油石化(2022年12期)2022-07-16 08:28:28
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
中国外汇(2019年19期)2019-11-26 00:57:32
家庭影院技术(2018年11期)2019-01-21 02:20:50
家庭影院技术(2018年11期)2019-01-21 02:20:48
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
电子设计工程(2017年20期)2017-02-10 03:39:29
电子器件(2015年5期)2015-12-29 08:42:24
语言与翻译(2015年4期)2015-07-18 11:07:45
