
面向智能化软件开发的开源生态大数据探析
2021-02-11 06:15程平远
无线互联科技 2021年24期
王 峥,程平远
(南阳职业学院,河南 南阳 474500)
1 软件工程开源生态大数据概述
1.1 软件工程开源生态的大数据体系
通常情况下可将软件社区分为两大部分,即开发社区和应用社区,与软件工程相关的内容都可以被涵盖其中。而软件工程的主体部分可以是多种文本形式的,也就具有更为丰富的语义。在构建软件工程开源生态的大数据体系时,一定要充分考虑到开发的具体环节、软件的镜像和应用、开发制品、问题咨询以及应用过程等因素,并且能够覆盖GitHub,Docker Hub和Apache等多种类型的主流开源社区,使相关人员对软件工程进行实验和研究工作时,能够以此为依据从全局的角度去考虑各类问题。在所构建的软件工程开源生态的大数据体系中,主要总结并概括了3种数据的具体类型:开发数据、应用数据和交付数据。
1.2 软件工程开源生态大数据的采集处理框架
研究中所构建的大数据采集处理框架具有模式多样以及增量式的显著优势,而对于各种类型的软件数据都能够高效地完成收集、分析、处理和整合等工作。在研究中主要以定向采集、有效感知、增量检测和多元关联等先进技术为基础,有针对性地设置了分布式爬虫,可以直接下载相应的数据包,并且也能够获取到局域应用程序接口和网页爬虫的相关信息数据。在下载数据包时,很多软件社区不仅会压缩并且保存以往获得的历史数据,还会将数据存储的地址提供给软件工程的开发者;而针对网页爬虫中存在的信息数据,开发者应先针对具体的格式和实际特点进行深入研究,在充分考虑到网页爬虫常用的匹配方式的基础上获取数据信息。在实际工作中,经常会遇到重复爬行和效率偏低的问题,通常所采用的处理方式是应用分布式的网络爬虫技术,并行处理相关的信息数据从而提升工作中的实际爬取效率(见图1)。
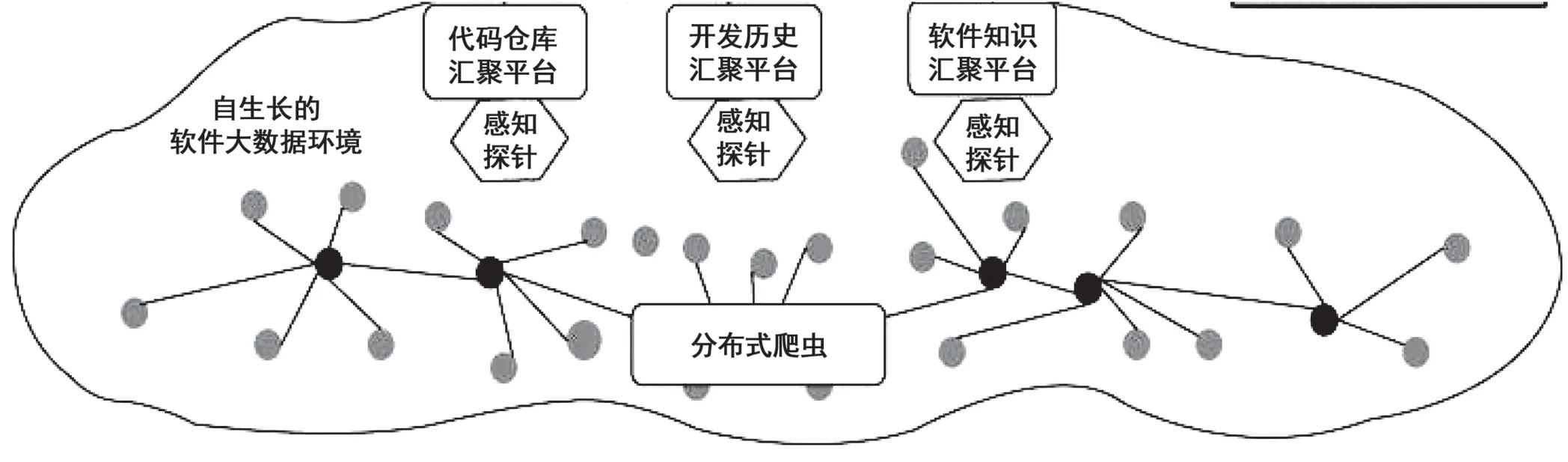
图1 软件工程开源生态大数据的采集处理框架
1.3 软件工程开源生态大数据的汇聚及共享
软件工程的开源生态大数据还具有多样化、大规模以及较强异构性的特点。为了构建一个更为全面并且科学的软件工程大数据的汇聚和共享平台,在实际工作中应严格遵循以实际需求获取、开放共享、平台汇聚以及分类存储的原则。在这种模式下,一般情况下都建议采用非结构化存储和结构化存储两种相结合的方式。对于本地数据应添加一个检索功能,在确定本地数据的查询、控制以及共享等功能的基本单位时建议提供相应的知识描述模块。为更好地表述出不同表之间的逻辑关联关系,这一平台还应具备知识描述和检索的功能。平台应将统一的访问门户提供给使用者,且在实时跟踪使用者使用需求的基础上不断改进和完善动态数据。数据资源的接口应具有全面性和统一性,让使用者能够迅速找到自身所需要的数据信息。在实际工作中可将平台放置在阿里云和UCloud上,在共享平台直接存储那些规模较小的数据,而对于那些较大规模的数据信息建议让共享单位对其进行单独管理[1]。
2 基于软件工程开源生态大数据的智能化软件开发
2.1 以数据开发为基础的软件知识图谱构造
针对软件工程中存在的主要问题,应先建立更为全面的软件缺陷知识图谱,而这一图谱则要在科学运用主题模型LDA和文本相似度算法的基础上来更有针对性地抽取关系并识别实体,其并不支持所有数据源的知识扩展工作,缺陷报告的数据以及源代码数据对其有重要的影响。社区平台中的工作人员应对所构建的CWE KG模块进行有效编辑,与软件弱点有较强关联的各类文档数据对其会产生直接影响。为保证软件开发过程中的在线问答效果,笔者有针对性地建立了HDSKG模块。同样,为了更好地识别实体并抽取关系,笔者采用了基于规则和依赖解析的方式,这一模式必须具备所收集到的在线问答数据作为支持,其扩展性也会受到一定限制。以数据开发为基础的软件工程开源生态大数据所提炼出的软件知识图谱,语义更为丰富、规模更大并且所涵盖的内容更广泛,且具备有效查询、搜索和储存知识图谱的功能,以此为基础进行数据分析、融合和深度挖掘等工作。在数据分析的工作中,图谱可与Word文档、邮件列表日志、PDF文档、网页文档、软件源代码和各类系统的版本记录等多种类型的软件工程数据相融合,同时具备更高的智能化程度,能够及时地补全各类有较强关联性的软件数据以及整合出更易于被理解和接受的数据知识。
2.2 基于缺陷与社区问答数据的软件代码缺陷智能定位与修复技术
在软件工程开源生态大数据中,相关的开发数据和应用数据作用十分关键,在实际的研究工作中一定要重点关注基于缺陷和社区问答数据的软件代码缺陷的智能定位与修复技术。软件缺陷出现的概率与代码的实际规模呈现出正比例关系。同时,缺陷报告文本附着的元数据以及缺陷报告与关联代码之间的密切关联性都是其自身的显著特点。在实际工作中所构建的文本主题模型应不仅能起到有效的监督作用,还能明确具体预测和训练方法。这一方法比传统更具修复能力,无论是实时的数据还是历史数据都能够将其有效修复,还能够将语义相似度和文本相似度这两大内容紧密结合,缺陷智能定位的精度更高。在实际所采用的开源项目包含着多个子项目,如JDT,PDE和Platform等子项目,在进行相同内容的工作时,这些子项目对信息数据的预测准确度得到了较大提高。由于缺陷定位的精准性会受到缺陷报告中文本附加信息影响,研究人员提出了L2SS+模型簇的概念,并对多个数据集合进行了实验工作,从实验中也更为明确了所构建的产品模块信息是能够直接影响到缺陷定位的准确性的,在同类工作中其准确率提高了20%左右[2]。
2.3 基于上下文感知的软件问答资源推荐技术
研究人员为了更好地认知并掌握软件工程开源生态大数据中交付数据和应用数据,在工作中还可以根据对上下文的感知情况来更有针对性地推荐软件的问答资源,这一研究内容在软件问答推荐领域中都具有前瞻性。以往也有一些研究感知考虑到上下文的感知情况,但其主要还是考虑代码本身的关键词,对于其中的语义内容以及存在于系统中的大量问答知识都没有被充分地考虑到,本系统研究人员主要采用的方法是将代码上下文中的关键词抽取出来并借助于检索功能来缩小问答数据的实际集合,使每一个问答数据与上下文之间的关联性能够被计算出来,在整体排序各类计算结果后,直接推荐给软件工程的开发者。
3 结语
通过以上的论述,本文对软件工程开源生态大数据概述及基于软件工程开源生态大数据的智能化软件开发两个方面的内容进行了详细分析和探讨,对其大数据的体系以及框架中的各类功能进行了深入研究和探索,并对其知识图谱构造、缺陷智能定位与修复以及问答资源推荐等关键技术进行了阐述,在对面向智能化软件开发的各类开源生态大数据的研究工作中具有很强的实际应用价值。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
少先队活动(2020年12期)2021-01-14
创新作文(1-2年级)(2019年3期)2019-09-03
电子测试(2018年1期)2018-04-18
中成药(2017年3期)2017-05-17
电子制作(2017年9期)2017-04-17
办公自动化(2016年18期)2016-08-20
办公自动化(2016年18期)2016-08-20
上海理工大学学报(社会科学版)(2015年3期)2015-11-30
