
基于多模态输入卷积神经网络的蜻蜓识别算法
2021-02-07 08:56重庆师范大学彭明杰
电子世界 2021年2期
重庆师范大学 彭明杰
昆虫的有效识别是农林业病虫害防治的必要环节,也是研究和维护生态环境的重要前提。蜻蜓是一种理想型环境指示昆虫,蜻蜓的识别研究在环境检测和保护方面有着重要的现实意义。本文使用收集的处于生态环境中的蜻蜓数据集,采用多模态深度学习网络模型设计思路,构建了以SqueezeNet为主干分类网络的蜻蜓识别系统,识别准确率高于传统手工设计特征的算法,并且避免了传统算法只能识别标本图片的局限性。
昆虫的有效识别是农林业病虫害防治的必要环节,也是研究和维护生态环境的重要基础。蜻蜓是一种水陆两息的昆虫,因此是一种理想的环境指示昆虫,在环境检测和保护领域有着极其重要的研究价值。国内外均有蜻蜓识别相关的研究,但利用机器学习技术进行蜻蜓的自动识别研究还有欠缺。传统的蜻蜓识别方法是在生物学专家采集蜻蜓样本,通过观察蜻蜓的颜色形状和形态结构等特征后,进行人为设计的蜻蜓特征提取,然后与已有的模式照样本进行对照鉴定,从而判断出蜻蜓的种类。此类方法费时费力且依赖于蜻蜓识别知识的掌握,极大的限制了蜻蜓识别的普适性。同时其识别准确率也很低,并且只能识别标本图片,对处于生态环境下的蜻蜓没有识别能力。随着计算机视觉和机器学习技术的发展,利用神经网络来进行图像识别的方式在许多图像分类问题上已取得了很好的效果。但是由于蜻蜓对象与自然环境紧密结合,生存环境复杂多变,导致蜻蜓的图像背景对识别任务造成巨大的干扰,并且蜻蜓各种类之间差异小,一些种类尤其相似,这些原因不仅使得蜻蜓数据采集困难,也让识别蜻蜓具有细粒度分类的特点。面对以上情况,本文采用多模态特征融合的方式对数据集进行处理和特征提取,利用改进的SqueezeNet达到了更好的识别准确率和较快的识别速率。
对同一物种的不同种类进行识别属于典型的细粒度识别任务,现今人们已经将细粒度识别作为一个计算机视觉领域的基础性问题来讨论。在分类学的逻辑约束下,人为进行分类的某一群子类往往因同属于一个大类而具有较高的相似度,这时区分各个子类的凭借只能是它们之间存在的一些细小的差异,这样的特点使得细粒度识别任务更具挑战性。如图1所示,以小团扇春蜓和巨圆臀大蜓为例,两者之间可用于区分的特征主要在于背侧纹的不同,而这种差异是很细微的。
细粒度图像分类随着深度学习的发展,如今在各个领域都有着广泛的研究和应用需求。在生活中,真正能满足实际需求的不是区分“大象和冰箱”之类的粗分类,而是区分“250ml豆瓣酱和250ml甜面酱”这样的细分类。在学术上,人们主要构建了公共的鸟、狗、花、车、飞机等公开图像数据集来进行细粒度识别算法的研究。而尤其在生物学中,有效地识别不同的物种,是进行其他研究的重要前提,由此甚至诞生了生物分类学这一学科。因此,借助机器学习算法实现低成本的细粒度图像识别,对我们的研究和生活都有重要的意义。

图1 小团扇春蜓和巨圆臀大蜓
1 数据集采集
实验采用平时比较常见的蜻蜓种类作为研究对象,以野外拍摄、网络搜索和向他人索要等方式共采集到12类蜻蜓的图片,共计1768张图片,以此作为数据集。数据集样本如图2所示。
2 数据预处理

图2 蜻蜓数据集
为了更加清晰地将目标与背景分离开来,得到目标完整的轮廓信息,本文使用富边缘检测的方法来对图片进行预处理。具体步骤为:①首先对输入的彩色图像进行灰度处理,使用公式(1)来计算灰度值,把RGB图像转换为灰度图。其中R,G,B分别表示色彩通道中的红、绿、蓝三个通道的数值;

②对训练样本添加随机的椒盐噪声以模拟图像在传输、处理等过程中受到的干扰信息,从而增强算法的鲁棒性;③再使用中值滤波器对上一个步骤输出的灰度图进行降噪处理,得到输出图像X1;④再使用Sobel算子对图像X1进行边缘检测,得到图像X2;⑤再使用Canny算子对图像X2进行边缘检测,得到图像X3;⑥将上两个步骤得到的图像X2与X3进行叠加,从而最终获得富边缘检测图像。处理结果如图3所示。

图3 图像预处理过程结果图
3 网络模型
深度学习模型比常规的算法有着更庞大的计算量,意味着需要更优良的设备,如GPU,TPU等等,随着智能移动端的发展,将深度学习模型嵌入至移动端设备成为了现如今的业界的需求,国内外研究者们提出了一系列降低卷积神经网络计算量的方法,如Andrew Howard等研究者提出的MobileNet(G.Howard,M.Zhu,B.Chen,D.Kalenichenko,W.Wang,T.Weyand,M.Andreetto,H.Adam.Mobilenets:Efficient convolutional neural Networks for mobile vision applications)系列和另一种轻量级的卷积神经网络SqueezeNet。它利用FireModule模块降低卷积神经网络的参数量,使得其准确率在与AlexNet的同时参数量却仅为后者的五十分之一。另外,单一特征的输入不利于以复杂自然环境为背景的蜻蜓图片的识别,因此本文提出了一种基于SqueezeNet的多模态特征输入的蜻蜓识别网络。
3.1 模型设计
本文采用两种图像特征作为输入。一种是蜻蜓的RGB原图,由可见光摄像头采集的三通道图像,第二种是经富边缘检测处理后的单通道灰度图像,RGB图能够描述物体的表观,颜色以及部分纹理的信息,而富边缘检测后的单通道灰度图能够描述物体的形状,尺度以及空间几何的信息,因此两种特征的图像具备互补性,两种图像采用特征融合的方式,输入图像是RGB图像和富边缘检测后的单通道灰度图像,在经过2个FireModule之后生成的特征图在三维空间中沿着第一个维度进行拼接,将拼接完的特征图再经过7个FireModule进入全连接层。网络模型结构图如图4所示。
3.2 损失函数
由于数据集的每一类的样本数量处于非均衡状态,例如第一类的数据有179张,而第二类仅有43张,如表1所示。大范围的数据比例失衡会破坏交叉熵损失,若是以传统的损失函数去构造目标函数,会导致部分类别发生欠拟合的情况。
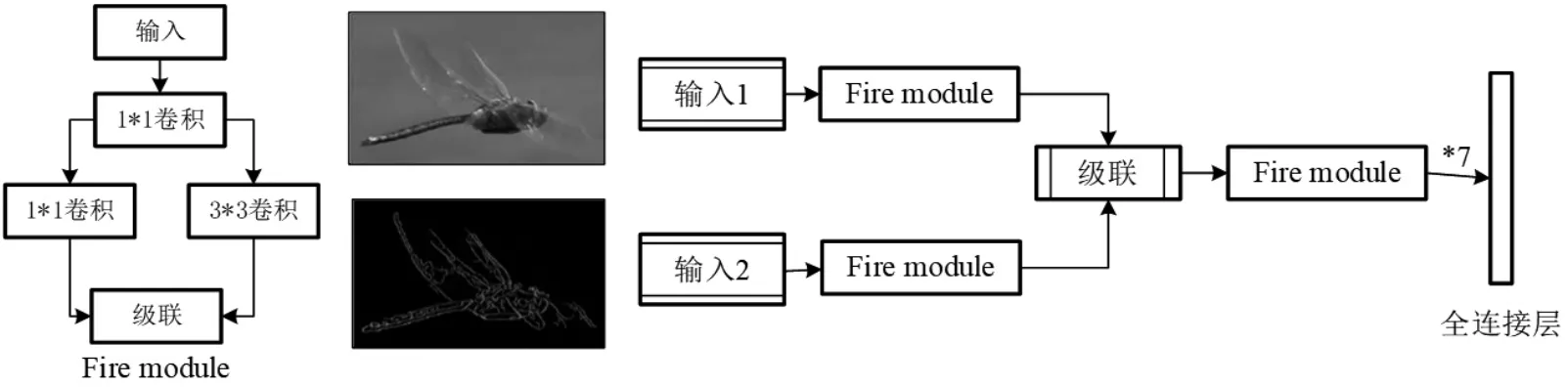
图4 模型结构图
而一般而言,常用的多分类交叉熵损失定义为:

其中pgroundtruth为数据集的标签,ppredict为预测的类别概率。针对数据集类别分布不均匀的问题,本文采用Tsung-Yi Lin(Lin T Y,Goyal P,Girshick R,et al.Focal Loss for Dense Object Detection)等研究者提出的Focal Loss损失函数的方法构造蜻蜓识别的目标函数。多分类Focal Loss公式为:


表1 各类蜻蜓样本数量表
α和γ是平衡参数,分别用来平衡正样本与负样本数量比例不均(即类别不均衡)的问题和简单样本与复杂样本的权重平衡问题。只设置α可以平衡正样本和负样本的在训练过程中的权重问题,但是无法解决简单样本与复杂样本的权重问题,因此引入γ参数来调节简单样本权重,使之保持一个动态降低的速率,当γ为0时即为交叉熵损失函数,后续实验结果也证明使用FocalLoss后整体准确率有明显的提升。
4 实验结果与分析
4.1 实验条件
本实验采用Python3.6、TensorFlow-gpu 1.8.0以及Keras2.2.4框架搭建模型。并且采用Cuda8.0、Cudnn为Titan XP GPU提供深度学习的驱动支持。超参数设置包括BathchSize为128,学习效率为1e-3,权重衰减率为5e-6,优化器采用Adam优化器,优化器参数Beta1、Beta2分别设置为0.9、0.999,迭代次数为200次。
4.2 实验结果
我们在收集的数据集上对不同算法进行了对比实验以验证本文方法的有效性。将本文提出的方法分别与包括支持向量机(Support vector machine,SVM)、贝叶斯神经网络方法(Bayesian neural network,BNN)和残差网络ResNet18(Convolutional neural network)在内的三种算法在蜻蜓识别准确率上进行了对比。除本文方法外,其他算法均采用单一特征输入的方式进行实验,即只使用蜻蜓RGB图像的颜色直方图来表征训练样本的特征图,SVM算法的核函数选择高斯核函数。不同算法的准确率结果如表2所示。可以看出,在使用支持向量机时,算法对蜻蜓的识别准确率较低;传统的卷积神经网络在小数据集上则容易发生过拟合现象,因此在该方法下的蜻蜓识别准确率也不高;贝叶斯神经网络方法与本文方法相似,但因其只使用单一输入特征,其准确率也低于本文方法使用多特征融合的多模态输入神经网络。总的来看,本文方法与上述3种算法相比,平均识别准确率提高了11到35.6个百分点,平均提高了23.8个百分点。
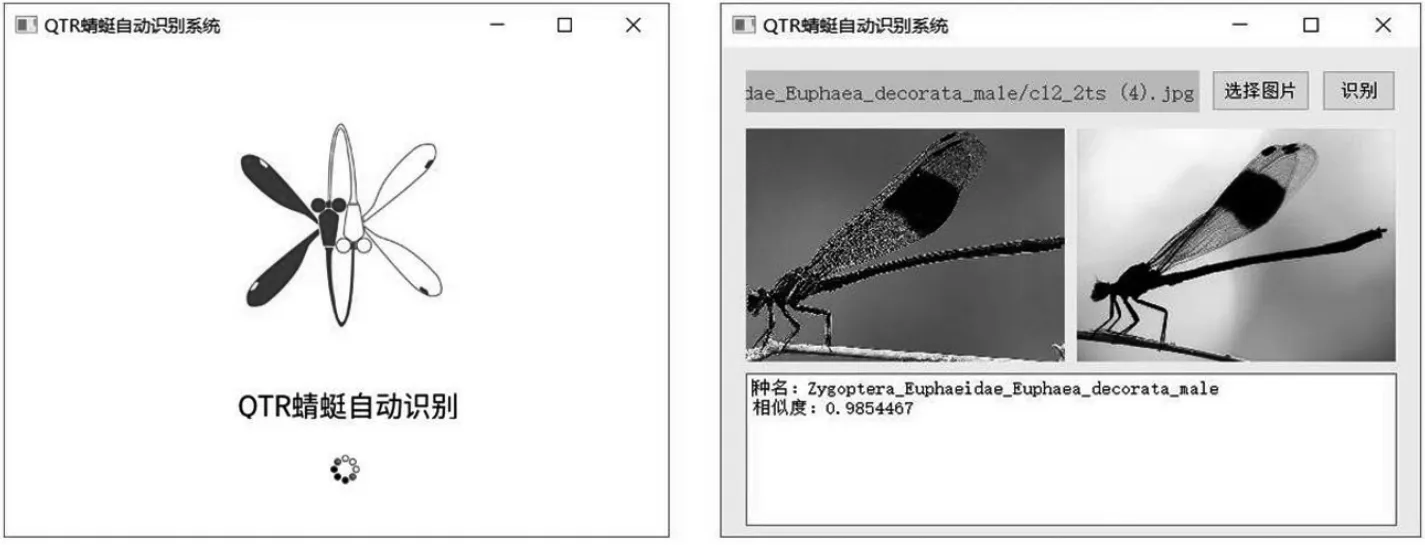
图4 蜻蜓自动识别系统

表2 算法结果对比图
5 蜻蜓识别系统
将本文训练的网络模型搭载在基于python的图形界面开发包QT5编写的GUI上,搭建一个轻便的蜻蜓识别系统。该系统能够根据用户传入的蜻蜓图片给出准确的分类信息,主要分为两个模块:输入模块与输出模块,输入模块首先判断传入对象是否为蜻蜓,其次对图像进行预处理,处理完成后对图像放入网络进行预测。输出模块主要来自于给出预测的结果,判断蜻蜓所属类别及其概率,并且给出该类别的蜻蜓示例图。系统示例图如图4所示。
结论:本文将图像处理技术和深度学习技术相结合,采用多模态输入的方式搭建卷积神经网络,有效地实现了蜻蜓图像的自动识别。实验主要采用Sony IMX300摄像头以及通过Google搜索引擎进行数据的采集,分类上细分到每个类别中的雄雌性,使用RGB图与富边缘检测图像处理相结合的方法,在更加清晰地将目标与背景分离开来,得到目标完整的轮廓信息的同时,保证了图片的色彩信息。提出了一种基于SqueezeNet多模态特征融合的蜻蜓识别网络对数据进行训练,从而对蜻蜓的种类进行分类,克服了传统蜻蜓识别方法中需要通过手工设计和提取目标特征的缺点,为蜻蜓鉴别任务节省了时间成本。另外,由于图像的质量将直接影响到分类的效果,基于本文算法搭建的蜻蜓识别系统对于质量较好的蜻蜓图片识别率较高,对背景复杂和模糊的图像识别率较低,这是值得进一步研究的地方。
猜你喜欢
红外技术(2022年11期)2022-11-25
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
安阳工学院学报(2020年2期)2020-06-05
中国交通信息化(2018年5期)2018-08-21
电脑知识与技术(2017年26期)2017-11-20
小天使·一年级语数英综合(2017年9期)2017-10-20
小学生导刊(低年级)(2017年1期)2017-06-12
信息安全研究(2016年3期)2016-12-01
