
一种基于RDMA多播机制的分布式持久性内存文件系统
2021-02-07 02:51陈茂棠郑圣安游理通王晶钰屠要峰韩银俊黄林鹏
计算机研究与发展 2021年2期
陈茂棠 郑圣安 游理通 王晶钰 闫 田 屠要峰 韩银俊 黄林鹏
1(上海交通大学计算机科学与工程系 上海 200240)2(清华大学计算机科学与技术系 北京 100084)3(中兴通讯股份有限公司 南京 210012)(chenmaotang@sjtu.edu.cn)
新型的非易失性内存(non-volatile memory, NVM)[1-5]技术的出现为传统的计算机存储结构带来变革,其中通过内存总线连接CPU的NVM形态也被称为持久性内存(persistent memory, PM).与DRAM相比,持久性内存拥有相接近的传输带宽与访问延迟,但兼具了DRAM不具备的持久性.随着持久性内存的逐渐应用,许多研究针对持久性内存设计特异性的文件系统,其中大多数文件系统基于单台机器设计[6-10].但是目前大容量的持久性内存价格昂贵,单机存储容量难以提高.同时,持久性内存运行带来较高的CPU负载,单机大规模部署持久性内存会使CPU成为存储性能的瓶颈.这些原因使得单机持久性内存文件系统难以满足日益增长的大规模数据存储需求,必须开发基于持久性内存的分布式文件系统.
多播技术同样在分布式系统中发挥着重要的作用.多播技术的应用范围很广,从多媒体数据的直播分发,到数据中心的分布式文件系统,均需要多播技术的支持.尤其是在数据中心中,数据传输通常是从源节点到2个甚至多个目标节点,文件数据需要被复制到多个存储服务器[15].这个过程造成的延迟往往占数据中心负载的主要部分,并最终决定了系统的总体IO性能[16].
尽管多播技术在系统中起到重要的作用,但是在现有的基于RDMA的分布式文件系统中,往往没有提供多播传输的支持[13-14].在需要1对多传输的场景下,这些系统通常使用每次传输到1个节点的方法,将数据依次推送到所有的目标节点[17].为了解决该问题,康奈尔大学的RDMC基于RDMA的1对1传输开发了多播通信框架[18].但是,由于这种框架的底层依然是基于1对1的连接进行通信,当多播操作的目标节点较多时,需要占用大量的网卡资源,导致系统难以基于框架进行有效的扩展.另外,基于框架的编程较为复杂,不利于分布式系统的应用与维护.其他解决方案在获得可扩展性的同时,往往为传输过程引入了额外的复制与延迟,同样没有办法很好地解决分布式系统中的多拷贝文件数据传输问题[19].
本文提出了一种基于RDMA多播传输机制的分布式持久性内存文件系统(RDMA multicast trans-mission based distributed persistent memory file system, MTFS).通过使用RDMA多播通信语句,实现元数据节点与数据节点之间的1对多通信,提升数据传输效率.具体地,MTFS实现了低延迟多播通信机制,基于RDMA多播通信语句搭建内核态RDMA通信模块,将文件系统中1对多的传输请求使用多播通信机制发送,并添加无通知机制与拥塞控制来优化RDMA传输,从而避免了传统1对1传输机制带来的冗余传输开销.为提升传输的灵活性,对分布式文件系统各项功能提供支持,MTFS基于多播通信机制设计多模式远程过程调用(remote procedure call, RPC)框架,发送端将请求相关信息写入RPC头部,接收端通过接收处理程序解析相关信息,从而定位要执行的操作地址与操作类型,保证相应文件系统功能得到执行.为保证多播传输机制的一致性,MTFS引入轻量级一致性保障机制,利用持久性内存字节寻址的特性实现错位的快速纠正,并支持在数据无法恢复时请求重传.节点发生故障时,MTFS为元数据节点与数据节点均提供了故障恢复机制,保证文件数据的一致性与可靠性.
本文的主要贡献有3个方面:
1) 提出基于RDMA多播机制的分布式持久性内存文件系统MTFS,实现了内核态RDMA通信模块,通过将文件系统中1对多请求使用RDMA多播语句发送,避免了额外的开销.
2) 提出基于多播传输机制的多模式RPC设计,提升数据传输的灵活性,为分布式文件系统各项功能提供支持.
3) 引入轻量级一致性保障机制,使用冗余校验机制保证数据传输过程的可靠性,利用持久性内存字节寻址的特性实现错位的快速纠正,并为系统中的各个节点提供故障恢复功能,从而保证数据的可靠性与一致性.
1 背景介绍
本节主要介绍了持久性内存技术与远程内存直接访问技术的基本特征,同时简要介绍与MTFS相关的NOVA文件系统实现细节.
1.1 持久性内存
持久性内存是一种新兴的硬件技术,主要包括相变存储器(phase-change memory, PCM)、忆阻器、自旋矩存储器(spin-torque transfer ram, STT-RAM)和3D XPoint等技术[1-4],其中基于3D XPoint的英特尔傲腾持久内存目前已经投入市场使用[5].
持久性内存的出现打破了内外存之间的界限,颠覆了传统的存储体系结构.一方面,持久性内存作为一种内存,拥有内存的种种特性.持久性内存可直接连接于高带宽的内存总线上,传输带宽和访问延迟均与DRAM相接近,并支持字节寻址访问.同时,与DRAM相比,持久性内存具有更高的存储密度和更低的能耗,这为搭建大规模内存文件系统提供了基础.另一方面,持久性内存作为一种持久性存储介质,与传统的硬盘和SSD相比,具有更高的带宽和更低的访问延迟.同时,由于CPU可以直接对持久性内存上的数据进行访问,数据可以绕过DRAM,无需在内存和存储之间进行迁移,数据访问的整体性能得到了大幅的提升.
持久性内存为文件系统的设计提出了新的要求.基于持久性内存的文件系统可以直接通过loadstore指令读写持久性内存.一些文件系统专为持久性内存进行特异性设计[6-9,20],另一些文件系统则基于现有文件系统进行改动[10,21],通过添加直接访问能力,允许应用程序绕过页缓存直接访问持久性内存,从而实现了文件系统对持久性内存的适配.
1.2 远程直接内存访问
近年来,RDMA技术在业界受到越来越广泛的关注[11,22-24].RDMA技术允许应用程序在不告知远端CPU情况下,绕过内核直接访问远端内存,实现零拷贝的数据传输,从而实现高带宽且低延迟的远端内存访问[25].目前,RDMA传输性能已远优于现有的固态硬盘和机械硬盘的读写性能,如果仍使用固态硬盘或者机械硬盘搭配RDMA网络实现分布式文件系统,存储介质的高延迟将使系统无法充分发挥RDMA网络的性能优势,同时文件系统也无法绕过DRAM直接写入存储介质.而持久性内存低延迟内存访问的特性,使其能有效适配RDMA技术,实现高效的远程存储访问.
RDMA主要提供单边语句和双边语句2种传输语句支持.表1展示了每种传输语句对应的类型.单边语句主要包括READ和WRITE语句,这些语句可以绕过远端节点的CPU,直接对远端内存进行读写操作.此外,RDMA单边语句还包括compare_and_swap 和fetch_and_add等原子性语句,使RDMA能够对远端内存进行原子性访问.双边语句主要包括SEND和RECV语句,采用类似于socket编程的方式,发送端和接收端均需要CPU参与.在发送端进行SEND操作之前,接收端需要提前准备1个RECV请求并放入网卡,该请求中包含待接收数据的地址.

Table 1 Verbs Type of Each Transport Verb表1 每种传输语句对应的语句类型
RDMA通过队列对(queue pair, QP)进行传输操作.每个队列对包括1个发送队列(send queue, SQ)和1个接收队列(receive queue, RQ).当进行传输时,使用RDMA的程序首先根据其传输的内容填充1个工作请求(work request, WR),并将其发布到发送队列上.RDMA网卡会依次处理队列上的WR,执行对应的传输操作.当传输完成时,网卡会在完成队列(completed queue, CQ)上发布1个工作完成(work completion, WC)信息,通知CPU进行相应处理.如果是双边操作,接收端在传输进行之前还需要提交1个RECV WR并放入其接收队列.
RDMA包括有连接和无连接2种形式.有连接的传输提供2个QP之间的1对1通信,若需要与多个节点进行通信,则需要创建多个QP分别与多个节点进行1对1通信.而无连接的传输基于数据报实现,通信节点之间不需要创建连接,每个QP可以和多个QP进行通信.用户可以选择可靠或不可靠的RDMA传输类型.可靠的传输可以按照顺序交付信息,并在传输失败时返回错误信息.不可靠的传输则无法提供可靠性保证,但是其通过避免发送确认信息获取更高的性能.使用不可靠传输,RDMA通过数据链路层提供的一致性保障机制仍可以在很大程度上保证数据传输的可靠性[22].
基于传输是否有连接与是否可靠,RDMA提供了3种主要的传输方式:可靠连接(reliable connec-tion, RC),不可靠连接(unreliable connection, UC)和不可靠数据报(unreliable datagram, UD).表2展示了每种传输方式可以支持的传输语句.可以看到,不同的传输方式所支持的传输语句不同,RDMA单边操作只在有连接的传输方式下支持,而RDMA多播传输只在UD模式下支持,因此用户需要根据传输需求选择对应的传输方式.

Table 2 Verbs Supported by Each Transport Type表2 每种传输方式支持的传输语句
RDMA提供了多播语句支持[26].多播语句是UD模式下双边语句的一种特殊形式.用户使用多播语句进行RDMA通信时,首先将所有需要通信的节点加入同一个多播组.发送信息时,目标地址设定为多播组的地址,发送端仅需要1次发送操作,发送成功后,所发送的信息通过交换机被分发到多播组中的各个节点.多播语句为1对多的传输场景提供了合适的解决方案,降低了多节点数据传输的开销,为解决基于RDMA的分布式系统中的多拷贝文件数据传输问题提供了有效的支持.
1.3 NOVA文件系统
MTFS是基于NOVA实现的.NOVA是加州大学圣地亚哥分校开发的一种持久性内存文件系统[6].为更好地利用持久性内存的诸多优秀特性,NOVA做了许多特异性的设计,使其在保证一致性的基础上提升文件系统的性能.本节讨论与MTFS相关的一些NOVA设计.
NOVA为每个索引节点维护1个单独的日志链表,每块日志中存储1次写入的基本信息与指向写入数据页的指针,同时在DRAM中维护基数树索引以加速对文件数据的查找.写入操作使用写时复制机制实现,每次写入时会申请新的日志块与数据页,在日志中记录操作相关信息与指向新写入数据的指针.当数据成功写入持久性存储介质后,NOVA更新文件日志的尾指针以及其对应的基数树索引.当读取数据时,NOVA通过基数树索引找到对应的日志块,从日志中读取数据地址,并通过地址找到数据页并读取数据.
NOVA使用可利用空间表管理持久性内存空间.NOVA将可用的数据空间均分给每个CPU进行管理以提升并发文件访问的性能,每个CPU使用红黑树结构管理数据空间中的空闲块,以提升连续数据块查找的性能.通过这种方式,NOVA提升了持久性内存空间分配操作的并行性,减少了空间分配的争用.
NOVA提供了故障恢复机制.当系统从故障中恢复时,首先,NOVA需要检查崩溃前写入的日志,通过日志将未提交的事务回滚.然后,NOVA并行扫描每个索引节点,通过日志链表恢复数据组织结构.通过日志设计,NOVA保证系统可以从故障中恢复数据.
2 MTFS设计
本节将详细介绍MTFS的系统设计.首先整体描述MTFS的系统架构,然后分别对MTFS中的低延迟多播通信机制、多模式多播RPC机制和轻量级一致性保障机制进行介绍.
2.1 系统架构
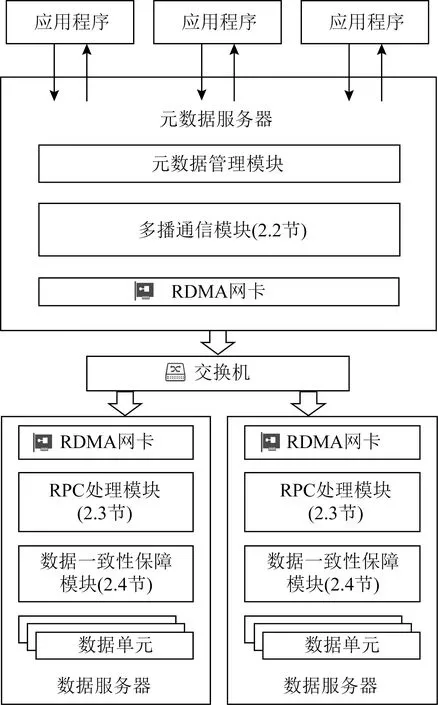
Fig. 1 Overall architecture of MTFS图1 MTFS系统整体架构
图1展示了MTFS的系统整体架构.系统由1个元数据节点和多个数据节点组成.其中元数据节点存储系统的元数据信息,包括文件的元数据信息和系统的基本配置与空间管理信息,数据节点中仅存储文件的数据.元数据节点与数据节点之间通过RDMA网络互连.MTFS采用主从式架构,将数据存储在多个数据节点上,提升了数据访问的并行性.
应用程序通过可移植操作系统接口(portable operating system interface of UNIX, POSIX)对文件系统进行访问.以数据写入为例,当应用程序发起数据写入请求时,MTFS通过访问元数据节点在各目标数据节点分配持久性内存空间,然后将数据写入到各数据节点中.待写入的数据通过多播通信模块(2.2节)以RDMA数据报的形式由网卡发出.网络交换机收到多播数据报时,会进行分发操作,将数据报发送到多播组中的每个数据节点.数据节点通过RPC处理模块(2.3节)识别数据报请求体,并通过数据一致性保障模块(2.4节)将数据持久化到持久性内存.与此同时,元数据节点会提交该次数据写入操作并返回用户.文件系统的元数据访问则仅通过元数据节点进行,无需对数据节点进行远程访问.
2.2 低延迟多播通信机制
在分布式文件系统中,节点间的网络传输的开销非常高昂.数据节点间等待传输完成与确认需要耗费大量的时间,从而产生较高的延迟.而在1对多的分发场景下,传统的文件系统会发起多次网络传输请求,将相同的数据逐一发送到各个节点,增加了网卡的负载(图2(a)).多播通信机制旨在将多个传输相同数据的请求合并为多播请求,避免网卡数据重复发送的冗余开销,从而大幅提升发送数据的效率.
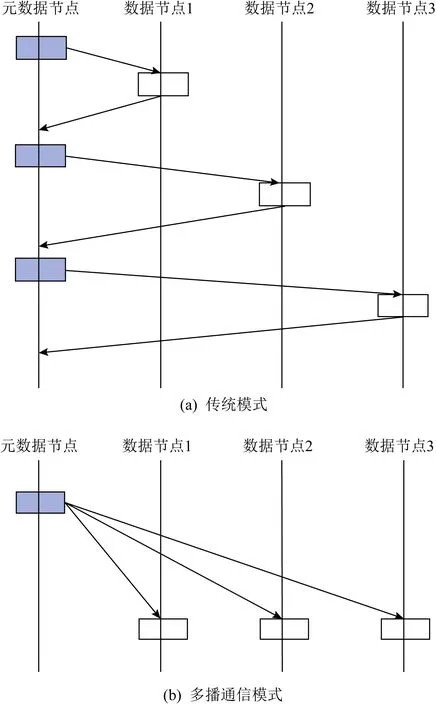
Fig. 2 Comparison of traditional and multicast schemes图2 传统模式与多播通信机制对比
当MTFS的元数据节点发起写请求时,数据将被同时写入所有的目标数据节点:首先多播传输模块会申请1块发送结构体,并根据写请求对应的数据地址、数据大小等元数据信息填写结构体的头部字段,同时将数据放入发送结构体的数据字段.然后多播传输模块会将RDMA传输信息添加到填写完毕的发送结构体中,并将其打包成工作请求放入发送队列进行传输;网卡依次对工作请求进行处理,将数据以RDMA数据报的形式发送到各个目标数据节点,由数据节点中的接收处理程序进行处理并写入持久内存.当发送操作完成之后,元数据节点会触发中断通知发送完成处理程序,将工作完成从完成队列中移出,从中获取已完成的发送结构体地址并将对应空间释放回收.执行过程如图3所示.

Fig. 3 Multicast transmission execution图3 多播通信运行过程
为提升系统可扩展性,MTFS将数据节点划分为存储单元进行管理.MTFS将数据节点每2~3个一组划分为存储单元,单元内的数据节点存储相同的数据,并和MTFS的元数据节点加入同一个多播组.多播信息仅在组内传递,由于不同存储单元间存储的数据互不相同,存储单元之间不需要进行多播通信.当元数据节点发起写入请求时,MTFS会选择剩余空间最多的存储单元,并将单元内的数据节点作为存储的目标数据节点;当元数据节点发起读取请求时,MTFS会根据对应存储单元内各数据节点正在请求的线程数量,从中选择负载最低的数据节点读取数据.通过存储单元管理,MTFS避免了数据冗余存储,提升了系统的可扩展性.
为减少元数据节点CPU的开销,MTFS通过RDMA无通知机制优化多播发送流程.由于RDMA的多播能力由UD模式提供,而UD模式基于无连接数据报实现,不需要处理接收端的确认信息.因此,当多播请求发送完毕后,多播传输模块不会立即通知CPU进行处理,而是将工作完成暂存在完成队列上.当完成一定数量的工作请求之后,为了防止工作完成的堆积,下一次发送的工作请求会被设置为完成后通知.当该工作请求发送完成后,网卡会触发CPU中断并转入发送完成处理程序,对先前放入的工作完成进行批量处理.通过无通知发送的优化,MTFS减少了CPU中断处理的次数,极大地降低了CPU的负担.
为了避免网络堵塞引起的发送队列拥挤,MTFS实现了拥塞控制系统.RDMA的发送队列长度固定,当网卡处理速率小于工作请求的增加速率时,发送队列会被填满,导致之后的工作请求无法放入发送队列.MTFS多播传输模块会对发送队列中待发送的多播请求数目进行实时统计,并据此控制RDMA多播请求的发送速率.当网络拥塞时,发送队列中待发送的请求数目超过了预先设定的阈值.此时发送队列将暂缓接受工作请求直到待发送的请求数量低于阈值,从而避免了发送队列溢出造成的传输问题.
通过上述多播通信机制,MTFS减少了文件操作过程中RDMA的通信次数,并充分利用UD模式数据报通信的优势降低了数据的传输延迟(图2(b)).尽管RDMA的UD模式具有一定的可靠性[22],MTFS依然通过发送端的拥塞控制机制与接收端的一致性保障机制(2.4节),在不显著增加延迟的情况下尽可能地保证数据的可靠性与一致性.
2.3 多模式多播RPC机制
MTFS使用RPC实现元数据节点与数据节点间通信.如图4所示,RPC采用服务端主动的方式,元数据节点通过多播通信机制将RPC请求分发到数据节点的网卡上,并由网卡放入接收队列等待处理.接收端处理程序按到达顺序依次处理接收队列中的RPC请求,对参数进行解析并执行相应的操作.
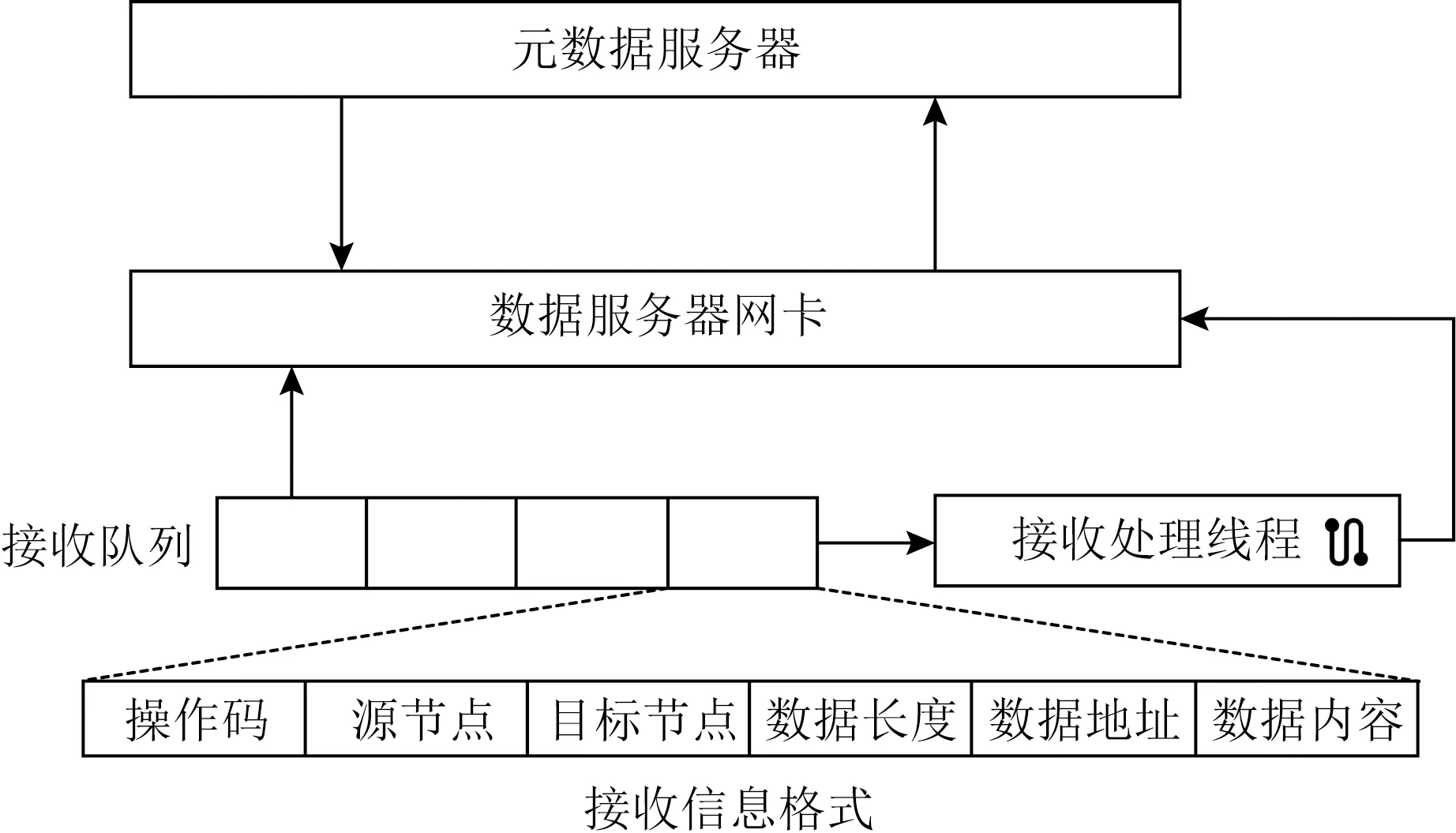
Fig. 4 RPC module design图4 RPC模块设计
RPC通过源节点字段和目标节点字段进行请求识别,从而判断该节点是否需要进行处理.由于RPC采用多播通信机制实现,多播组中的所有数据节点均可以接收到元数据节点的请求.为增强RPC的灵活性,请求头部标识了源节点与目标节点,数据节点收到请求后首先判断该节点是否需要执行操作,从而避免冗余的请求对数据节点资源的占用.
RPC通过优化返回机制降低执行延迟.接收端根据其接收到的操作码对请求进行分类:对于不需要返回信息的请求如数据写,数据节点会直接执行相应操作,不发送返回信息;对于时效性要求较高的请求如数据读,数据节点会立即进行处理并返回完成信息;对于时效性要求较低的请求如数据迁移,元数据节点采用异步处理机制,发送RPC请求之后继续执行其他操作,不阻塞等待结果,当收到返回信息后再进行结果处理操作.而数据节点收到请求之后,会在优先处理其他请求之后进行处理并返回完成信息.通过RPC多模式分类,MTFS减少了部分操作的传输次数,并将部分传输操作从关键路径移除,有效提升了文件操作的整体效率.
考虑到RPC基于多播通信机制,MTFS的写请求使用RPC实现,保证写请求通过多播语句1对多地发送到所有的数据节点.但鉴于读请求针对单一客户端的特性,MTFS在实现了基于RPC的读方法的同时,采用基于RC模式的RDMA读操作实现了对文件数据的读取操作,避免了集群规模过大时使用多播通信机制读数据造成的额外开销.用户挂载文件系统时,可以根据集群配置选择合适的读方法.
2.4 轻量级一致性保障机制
MTFS开发了故障恢复机制以有效应对各节点上可能发生的系统崩溃.MTFS检测到数据节点崩溃后,会将该数据节点标记成为故障节点,读请求将被分流到其他数据节点执行,不会影响系统正常运行.该数据节点中的数据可以通过元数据节点与其他数据节点进行恢复.当元数据节点崩溃时,系统停止提供服务,等待元数据节点重启,并通过文件的元数据与数据日志,将系统恢复到崩溃前的状态.通过故障恢复机制,MTFS保障了数据的高可靠性.
MTFS使用冗余校验机制保证了数据传输的容错性(图5).发送端打包传输数据时,会将数据分为2部分并分别计算循环冗余校验(cyclic redun-dancy check 32, CRC32),校验结果存入发送请求的固定区域.同时,MTFS对2部分数据计算奇偶校验结果并放入发送结构体.接收处理程序收到数据后会首先计算2部分数据的CRC32校验和,与收到数据中存储的校验和进行比对.若2份数据校验和与存储的校验和均相同,则说明本次数据传输没有发生错误;若仅有1份数据校验和与存储的校验和相同,说明另1份数据发生了传输错误.接收处理程序会通过奇偶校验结果查找错误发生的位置,计算出正确的结果并写入;若2份数据校验和与存储的校验和均不相同,则该次传输可能出现了大面积无法恢复的错误,接收处理程序会激活重传机制,发送1个重传请求到发送端,请求重新发送该数据.通过冗余校验机制,MTFS在不显著影响性能的情况下保证了数据传输的正确性.
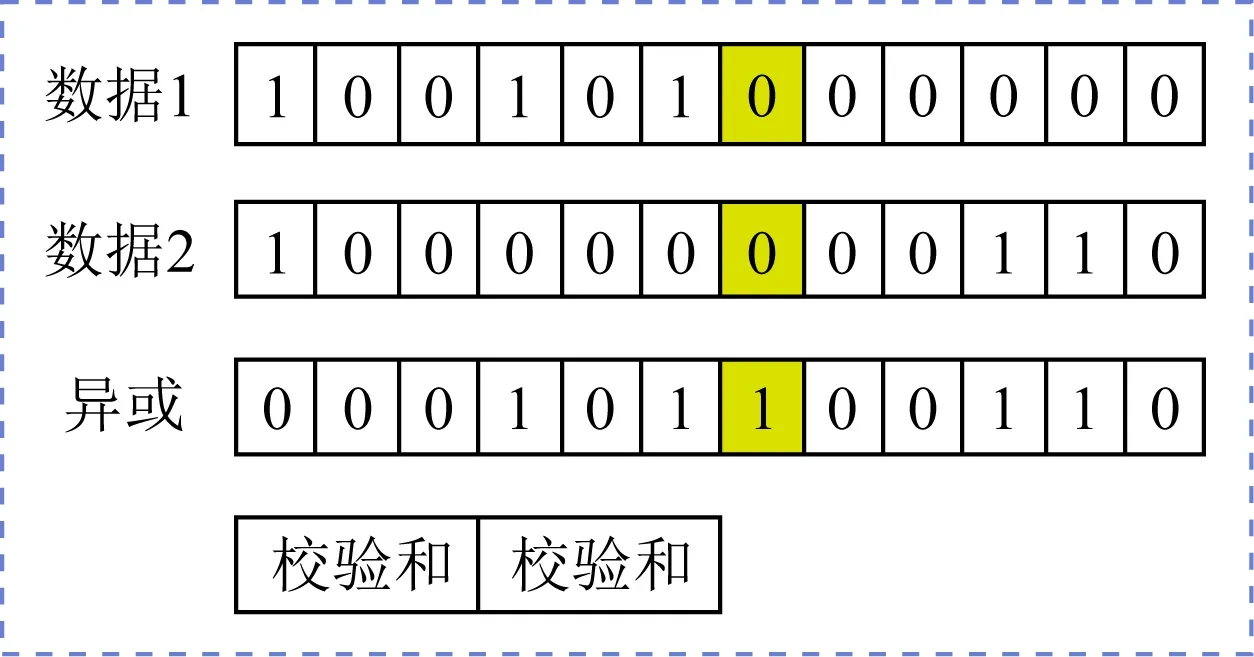
Fig. 5 Data verification mechanism图5 数据冗余校验机制
MTFS使用重传机制保证文件数据的持久性.发送端申请工作请求时会指定全局唯一的WR_ID,并附在RDMA发送的立即数字段一同发送.接收处理程序会记录来自同一个节点的最近1个请求的WR_ID,并在新的请求到达时读取立即数字段进行比较.若新接收的请求出现乱序,接收处理程序会发送重传请求到发送端,要求重传缺失的工作请求.对于传输数据出现大面积错误的情况,接收处理程序会通过最新记录的WR_ID计算出错误的WR_ID并发送重传请求到发送端.发送端收到重传请求时,会通过WR_ID查找相应的发送数据进行重新打包发送.
MTFS通过窗口确认机制保证了数据一致性.元数据节点记录了每个索引节点最后1次写入操作的WR_ID.各数据节点每隔一段时间会向元数据节点报告TAIL_WR_ID(即节点已成功接收在该WR_ID之前的所有请求).当元数据节点发起读请求时,会检查索引节点最后1次写入的WR_ID和目标节点报告的TAIL_WR_ID,确认目标节点是否已经收到该索引节点的所有写请求.若未收到,则说明还有写请求正处于传输的过程中,系统会对读请求进行阻塞,直到数据节点确认已收到所有的写请求;若已收到,则元数据节点可以执行读操作.通过窗口确认机制,MTFS避免了文件读写出现不一致,保证了数据一致性.
MTFS避免了RDMA网卡的数据一致性问题.当使用RDMA网卡对远端地址进行数据写入时,数据可能会暂时驻留在RDMA网卡的易失缓存中,由网卡决定写入内存地址的时机,这可能导致数据不一致的问题[27].MTFS采用多播发送语句,远端网卡接收到数据之后,会通知接收处理程序将数据写入持久性介质,避免数据在RDMA网卡缓存中驻留,保证数据的一致性.
3 系统实现
本节主要讲述了MTFS各项设计的实现方式与细节.虽然本文在NOVA的基础上实现MTFS的各项功能设计,但MTFS的设计可以基于现有的单机持久性内存文件系统实现,不局限于某个系统的设计.
3.1 文件系统相关实现
MTFS基于NOVA的元数据组织实现元数据节点组织,并沿用了NOVA的元数据相关设计.由于MTFS元数据节点与数据节点分离的架构,MTFS优化了数据日志的格式,将各目标数据节点中对应的数据地址存入日志之中.同时,MTFS对所有的数据节点进行统一编址,使用NOVA的可利用空间表数据结构进行管理.每个CPU在每个数据节点上对应1个可利用空间表,并通过可利用空间表管理1块持久性内存空间.当执行数据写入操作时,元数据节点会从每个目标数据节点对应的区域中各分配1段空间,并通过RPC将数据远程写入.当执行数据读取操作时,系统会按照日志块中记录的远端数据的地址从远端数据节点读出数据.
3.2 RDMA通信模块
MTFS实现了高效的内核态RDMA通信模块.为了提升通用性,更好地与主流的基于POSIX接口的内核态文件系统适配,MTFS在内核态实现了RDMA通信.同时MTFS将RDMA服务以模块的形式呈现,封装RDMA的相关操作,将复杂的RDMA操作抽象为通信建立、通信关闭和操作执行等若干类函数,对文件系统屏蔽了RDMA通信的相关细节,方便相关代码的移植与维护.
为了方便管理RDMA,MTFS使用RDMA_CM库管理通信.RDMA_CM可以在RDMA传输建立之前,使用基于RDMA网络的TCP传输在各节点间传递RDMA网络参数,并据此建立RDMA传输.RDMA_CM将RDMA通信建立流程封装成为类似于socket的接口,并在整个通信阶段对通信进行管理.建立多播通信时,需首先对约定好的多播地址进行解析,当确认解析无误后将解析到的设备绑定到CM_ID,然后各节点加入该多播组并注册到子网管理器,从而完成多播通信的建立.对于多播传输请求,所有加入该多播组的节点均可以接收.通过使用RDMA_CM库,MTFS简化了RDMA编程操作.
MTFS实现了RDMA发送与接收请求的统一管理,从而支持了RDMA多播传输的各项优化.为了方便对网络请求进行统一管理,MTFS在各节点上分别为RDMA发送与接收请求维护全局的工作请求链表.正常情况下,当有新的请求需要发送时,MTFS申请1个新的工作请求,相关信息填写完毕后,会将工作请求放入链表,并生成全局唯一的WR_ID,WR_ID在发送时被放入数据报一起发送.当发送完成时,发送完成处理程序通过工作完成找到WR_ID,进而找到该次工作请求并回收相关数据结构.接收请求的情况与之类似.当无通知优化功能被启用时,MTFS会记录发送请求的数量,工作请求通知标志的默认值为0,当一定数量的数据发送完成后,下一个工作请求的通知标志会被置为signaled,发送完成之后通知处理程序对所有早先产生的工作完成统一进行处理.启用拥塞控制时,MTFS使用原子变量记录发送队列上的待发送工作请求数量,通过该原子变量判断是否暂缓接受发送请求.通过对RDMA请求的统一管理,MTFS实现了请求的添加、存储、删除与查找,为RDMA多播传输的各项优化提供了有效的支持.
3.3 RPC与一致性保障实现
MTFS为RPC传输设计了发送结构体.结构体中包含了该次操作的详细信息,包括操作码、源节点与目标节点、数据长度、数据地址和数据内容等,整个结构体经过冗余和校验处理之后,会统一作为RDMA传输的数据进行发送.而工作请求的控制信息会根据请求类型和待发送数据进行填写,其中立即数字段填写全局唯一的WR_ID,填写完毕之后放入发送队列进行发送.接收端收到RPC请求之后,会读取数据并对各字段进行解析,执行相应操作.
4 实 验
本节将MTFS与其他文件系统对比,对各项性能进行评估.首先介绍实验环境配置,然后从微观测试、Filebench测试、Redis测试3个方面对比MTFS与现有的分布式和单机持久性内存文件系统,详细比较并分析相关性能差异.
4.1 实验配置
实验所使用的实验平台环境配置信息如表3所示.各节点均部署4块Intel Optane DC 128 GB持久性内存,并采用APP-Direct模式.各节点通过一块Mellanox ConnectX-5 RDMA网卡与其他节点通信,网卡配置为Infiniband模式运行,并连接到Infiniband交换机.

Table 3 Platform Configuration表3 实验平台配置
MTFS使用NOVA的代码作为基础,在Linux 4.13内核上实现.MTFS基于Mellanox OFED实现了内核态RDMA通信模块,并整合入文件系统.MTFS最大可支持同一广播域内的所有节点组成的集群,本实验中MTFS默认在3个节点组成的集群上部署,包括1个元数据节点与2个数据节点,其中2个数据节点属于同一个存储单元.各节点采用128 GB持久性内存作为存储介质.
本实验主要将MTFS与同样运行在持久性内存与RDMA上的分布式文件系统GlusterFS进行比较[28],对各项性能进行评估.鉴于MTFS基于单机文件系统NOVA实现,本实验同样将与NOVA进行性能比较.由于NOVA部署在单台机器上,公平起见,MTFS在实验中数据吞吐量均表示集群中单个节点的吞吐量.
4.2 微观测试
实验使用Fio进行微观测试,展示MTFS在1对多的场景下进行写操作的吞吐量[29].在测试过程中采用随机读写,分别通过IO大小变化和文件大小变化,测试Fio的总体吞吐量.
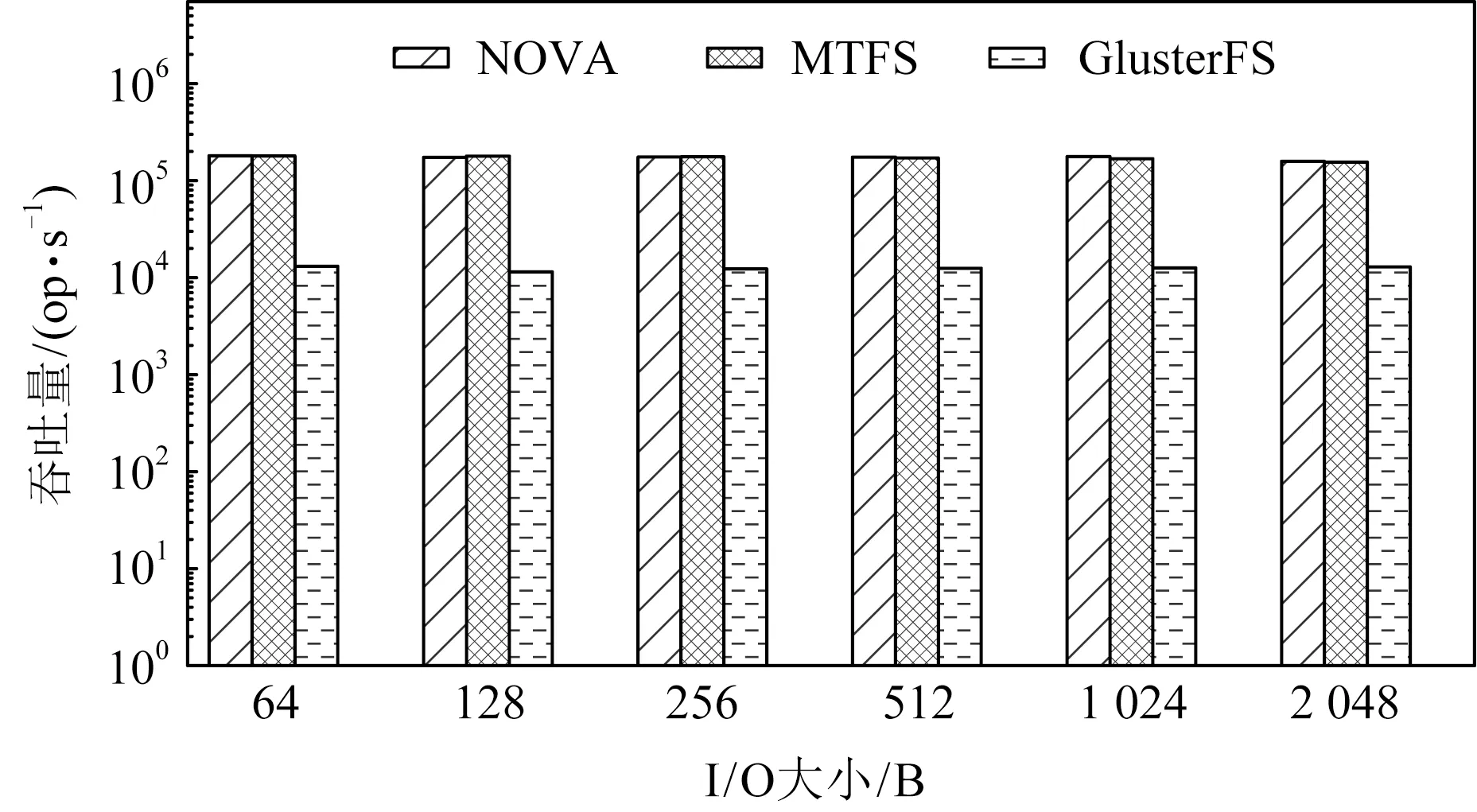
Fig. 6 Throughput of write syscall with varying I/O sizes图6 写系统调用在不同I/O大小下的吞吐量
图7展示了MTFS与其他对比系统在不同的文件大小下的写系统调用吞吐量,其中IO大小为2 KB.从图7中可以看到,与GlusterFS相比,在文件大小为2 KB时,MTFS性能相比GlusterFS提升了145倍,而在文件大小为2 GB时,MTFS对比GlusterFS仍然有10.2倍的提升.同时,随着文件大小增长,MTFS和NOVA性能均未出现明显下降.这是因为MTFS与NOVA虽然采用日志结构,但相应的在DRAM中维护了作为数据索引的基数树,当文件大小增长时,文件数据访问延迟并不会出现明显增大.

Fig. 7 Throughput of write syscall with varying file sizes图7 写系统调用在不同文件大小下的吞吐量
为了检验MTFS在集群中的可扩展性,实验测试了MTFS在不同规模集群中的性能表现,结果如图8所示.可以得知,随着集群中节点数量增加,在不同的IO大小下,MTFS吞吐量都能够基本保持不变,展现出良好的可扩展性.
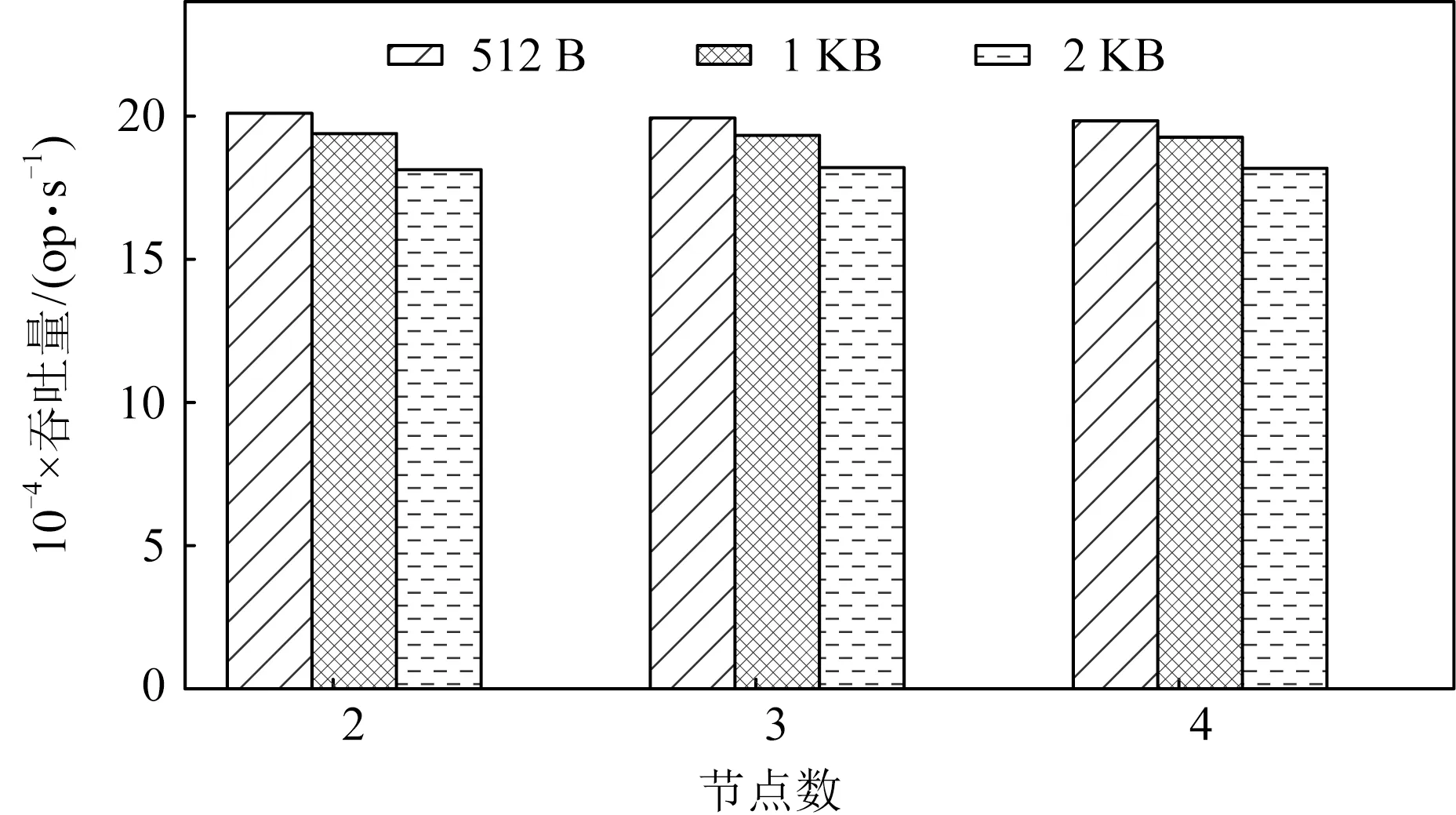
Fig. 8 Throughput of write syscall in clusters with varying sizes图8 写系统调用在不同规模集群中的吞吐量
4.3 Filebench
MTFS使用Filebench[30]测试评估真实负载下的表现.实验选择Filebench的工作负载Randomwrite来评估MTFS的性能.实验采用以下参数进行测试:负载平均文件大小2 KB,数据操作的平均IO大小从64 B~2 KB不等.
图9展示了各文件系统在Filebench的Random-write工作负载上的性能表现.可以得知,MTFS与NOVA性能相接近,在IO大小为2 KB时,MTFS相比NOVA性能有11%的提升.主要原因是当IO大小增大时,NOVA进行持久化相关操作的延迟随之增大,而MTFS将持久化相关操作放在远端数据节点进行处理,从关键路径移除,减小了数据操作的延迟.与GlusterFS相比,MTFS性能仍然有13.7~219倍的提升.

Fig. 9 Throughput of Randomwrite with varying I/O sizes图9 Randomwrite在不同I/O大小下的吞吐量
4.4 Redis
为进一步测试MTFS在真实负载环境下的表现,实验采用Redis[31]作为负载测试各文件系统的表现.Redis 是一个高性能的key-value数据库,在企业级应用中被广泛使用.实验采用Redis的AOF机制实现数据持久化,持久化策略使用每修改同步策略,数据大小从默认2 B~2 KB不等.实验比较Redis在不同文件系统下的每秒请求数.

Fig. 10 Performance of Redis with varying data sizes图10 Redis在不同数据大小下的性能
图10展示了各文件系统运行Redis时的性能表现.与上述微观测试和Filebench测试采用IO密集型负载不同,Redis包含大量的计算操作,这导致GlusterFS数据操作上的性能缺陷在一定程度上被掩盖,但MTFS与GlusterFS相比仍取得了25.5~42.1倍的性能提升.与NOVA相比,MTFS在Redis负载上取得了更优异的性能表现,主要原因是Redis操作中IO密集度下降减轻了网卡的负载,使得RDMA多播操作发送延迟下降,进而提升了数据传输效率.
实验在Redis负载上对各文件系统进行了线程扩展能力测试,结果如图11所示.可以看到,MTFS随线程数量增加,表现出良好的线程可扩展性.

Fig. 11 Performance of Redis with varying thread numbers图11 Redis在不同线程数下的性能
5 相关工作
新兴的持久性内存技术与RDMA技术分别为本地内存访问与远程网络通信访问提供了优化的可能,现有的一些工作基于这2种技术提出了针对性设计.
5.1 RDMA相关优化
文献[11]提出了一个基于RDMA的分布式共享内存系统FaRM.FaRM使用单边RDMA语句实现了无锁读取和RPC操作,避免了双边RDMA操作带来的通信延迟与CPU开销.与基于TCP的系统相比,它的设计使其在RDMA网络上获得了巨大的性能提升.但是,FaRM使用了RC模式的单边RDMA操作,对于每组连接都需要创建至少1对QP,而过多的QP会带来RDMA网卡缓存不足和处理器争用的问题,这限制了系统在大规模集群中的表现.MTFS基于多播语句实现,每对QP都可以发送信息到所有的节点,从而大幅减少了对RDMA网卡相关资源的需求.
文献[22]通过实验证明了在UD模式中,RDMA传输依然具有非常高的可靠性,并基于该结论提出了FaSST.FaSST使用UD模式的双边RDMA操作开发了RPC系统,利用UD模式数据报传输的优势,通过降低发送端延迟提高系统性能,并取得了良好的可扩展性.然而FaSST只能通过QP进行1对1数据发送,当需要将相同的数据传输到不同的目的地时,需要进行多次发送操作.尽管MTFS同样基于UD模式的双边RDMA操作,但是在上述情况下,MTFS使用多播语句可以将发送操作降低到1次,从而有效降低了发送端的延迟与资源占用.
文献[23]提出了一种基于混合RDMA语句的分布式事务系统DrTM+H.该系统使用了乐观并发控制实现事务,按照乐观并发控制中的特性比较不同RDMA语句的表现,并在事务执行的每个阶段选择最适合的语句进行操作,取得了良好的性能表现.MTFS也使用了混合RDMA语句,选择了多种RDMA语句分别进行读取和写入操作,但是与DrTM+H相比,MTFS将元数据操作放在本地执行,仅将数据放在远端存储,通过减少RDMA操作次数降低了事务执行延迟.
5.2 基于持久性内存的分布式文件系统
文献[17]提出一个分布式文件系统NVFS,在现有的HDFS基础上进行了改进,使系统可以更好地利用持久性内存技术和RDMA技术的特性.尽管HDFS表现良好,但HDFS设计的复杂性增大了改进的难度,导致NVFS无法充分利用硬件的性能.而其他类似的工作只是简单地用RDMA替换了现有系统中的网络,同样无法充分地利用新技术的特性[28].
文献[13]同样将持久性内存与RDMA功能进行了紧密结合,开发出分布式文件系统Octopus.Octopus基于RDMA的write_with_imm语句构建RPC,该语句可以在进行单边写操作的同时携带32 b立即数字段,通过在该字段中编码RPC相关信息,为接收端的相关处理提供了一定的灵活性与便利.但是在该语句中,当远端节点的网卡接收到立即数字段时,需要触发中断来通知CPU处理立即字段,从而失去了RDMA单边写操作无需CPU处理的优势,而仅32 b的字段大小也无法充分实现灵活性.为了满足灵活性的需求,MTFS采用了UD模式的双边操作语句,并设计了大小可调整的头部字段来实现RPC操作.
上述系统虽然均表现良好,但由于缺少对RDMA多播通信支持,导致难以解决分布式系统中的多拷贝数据传输问题,造成一定的性能损失.MTFS充分利用RDMA多播通信能力,通过多播传输解决了多拷贝数据传输问题,有效提升了系统数据传输效率.
6 总 结
持久性内存与RDMA技术的出现,为分布式系统的设计提供了新的思路.现有的基于RDMA的分布式系统未能充分利用RDMA的多播能力,难以解决多拷贝文件数据的传输问题.本文提出一种基于RDMA多播机制的分布式持久性内存文件系统MTFS,通过低延迟多播通信机制将数据高效传输到多个数据节点,从而避免了多拷贝传输操作.为提升传输操作的灵活性,MTFS设计了多模式多播RPC机制,并通过优化返回机制将部分操作移出关键路径,进一步降低传输延迟.同时MTFS提供了轻量级一致性保障机制,保证了数据的可靠性和一致性.实验结果表明,MTFS在各测试集上性能比GlusterFS高10.2~219倍,并在Redis负载上相比于NOVA取得了最高10.7%的性能提升.MTFS在大规模数据存储场景中有着广阔的应用前景.
猜你喜欢
电脑爱好者(2021年4期)2021-02-27
山东工业技术(2017年7期)2017-04-10
科技经济市场(2016年5期)2017-02-05
商(2016年20期)2016-07-04
电脑爱好者(2015年15期)2015-09-10
数学教学通讯·初中版(2014年6期)2014-08-11
小学生·多元智能大王(2014年6期)2014-07-09
小雪花·初中高分作文(2009年8期)2009-11-16
网络与信息(2009年7期)2009-07-11
网络与信息(2009年8期)2009-05-10
