
基于深度卷积神经网络的堆芯换料方案性能评价研究
2021-02-03 08:39雷铠灰曹良志万承辉
原子能科学技术 2021年2期
雷铠灰,曹良志,*,万承辉,曹 泓
(1.西安交通大学 核科学与技术学院,陕西 西安 710049;2.上海核工程研究设计院有限公司,上海 200233)

图1 换料限制条件原理示意图Fig.1 Diagram of refueling principle
在核电厂堆芯换料方案设计优化过程中,由于换料方案的样本空间极大,而传统的换料方案评价需借助燃料管理软件完成堆芯三维核-热-燃耗的耦合计算[1],无法在短时间内筛选出满足经济性和安全性要求的堆芯换料方案。因此,为减轻换料方案优化过程中的人力时间投入,快速精确地评估方案的性能具有重要的研究价值。
自20世纪90年代以来,研究者尝试将人工神经网络用于堆芯换料参数的快速预测并证明了其具有较好的适用性。但以往的研究[2-4]普遍基于传统的全连接神经网络,存在以下问题:学习参数多、组件编码的大小和形式显著影响神经网络的训练以及预测精度,尤其在组件类型较多时编码形式的考虑将变得异常麻烦等。同时,全连接神经网络还存在参数冗余、忽略位置信息等缺陷。
卷积神经网络可处理类网格结构数据[5],它有效地解决了全连接神经网络的缺点,被广泛应用于图像识别、文档分析、语言检测等领域。Jang等[6]对比了卷积神经网络和全连接神经网络的预测性能,并采用VGGNet[7]卷积网络成功预测了堆芯换料方案的循环长度和功率峰因子,证实了卷积神经网络用于堆芯方案评估的优越性。但Jang等采用的VGGNet结构卷积核尺寸单一且在同等网络深度下存在学习参数过多、网络训练慢的缺点。因此,本文拟采用Inception-ResNet网络结构[8],在加深网络深度的同时减少学习参数、抑制梯度弥散等现象,以实现对换料关键参数的快速精确预测。作为数值实验,本文以某二代改进型机组为研究对象,基于工程换料经验随机生成堆芯换料方案用于神经网络训练,评估本文提出的预测方法的计算效率和精度。
1 换料方案随机生成
在实际换料过程中,组件所处的位置可分为1/8区域、正1/4线(水平垂直1/4线)和斜1/4线(对角1/4线),从右下1/4堆芯开始,按照逆时针方向依次分别为1/8区域和1/4线进行类型编号0~7。在该堆芯中,1/8区域对称的有8个组件,1/4线对称的有4个组件。本文采用压水堆机组堆芯换料方案设计中的换料规则,生成神经网络训练所需的堆芯换料方案的样本,原理示意图如图1所示(组件字母后的数字为区域编号)。其中,关键的换料规则如下:1) 处于上一循环1/8区域的乏燃料组件在本循环可放到1/8区域上(如组件C),或拆成两组分别放到不同1/4线上(如组件B)或同一类(正或斜)1/4线上(如组件A),在拆分和放置时保持上一循环中各组件旋转对称和逆时针相对位置不变;2) 位于上一循环1/4线上的乏燃料组件在本循环放置在1/4线上(如组件D);3) 如果中心位置使用1/8区域的乏燃料组件(如组件E),则与被使用组件90°旋转对称的另外3个组件不在本循环放置,另外4个组件可在本循环1/4线上放置,放置时仍保持旋转对称和逆时针相对位置不变,如果采用上一循环1/4线组件,则其余3个组件不在本循环使用;4) 后备反应性较高的燃料组件周围应尽量展平功率分布;5) 将后备反应性低的燃料组件卸出堆芯,卸出数目为新燃料组件装载数目。基于上述5条限制条件,以此生成不重复的换料方案。
2 卷积神经网络
2.1 卷积神经网络算法概述
卷积神经网络仿照生物响应眼前精确位置图像的局部感知、扫视等过程,通过设计卷积和池化操作,实现对图像的特征提取。这种卷积和池化操作使卷积神经网络具有稀疏连接、参数共享、平移等变和局部平移不变的特点,从而在减少学习参数、降低训练难度的同时有效地提取了图像的特征,因此被广泛用于图像识别、物体检测等领域。卷积神经网络一般由输入层、隐藏层、输出层组成,结构如图2所示。
隐藏层通过卷积核或池化窗口进行计算、平移操作对输入图像进行局部特征感知与提取,然后输出新的特征图,其中特征图的通道数为卷积运算使用的卷积核数目。

i,j=1,2,…,n;c=1,2,…,d
(1)

i,j=1,2,…,n;k=1,2,…,d
(2)

经过卷积或池化操作后,特征图的长宽尺寸要小于原始图像的,此时可通过填充0以保持操作前后尺寸不变。新的特征图又会被后续的多个隐藏层逐步提取特征以形成高度抽象化的特征,最后通过整合这些高度抽象化的特征并进行线性运算以获得输出层结果。整个网络的更新由梯度下降算法进行,其算法公式如下:
(3)
式中:n为神经网络训练步数;θ为神经网络学习参数;ε为学习率;m为进行小批量学习时每批数据量;x(i)、y(i)分别为每批数据中第i个样本的输入值和目标的真实值;L(x,y,θ)为预测值与真实值之间的损失函数。
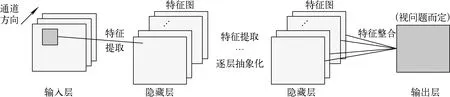
图2 卷积神经网络结构Fig.2 Structure of convolutional network
2.2 卷积神经网络构建
在各种卷积网络结构中,GoogLeNet[9]和ResNet[10]深度卷积网络凭借优异的性能被广泛用于图像识别等领域。其中,GoogLeNet网络模型具有多尺度特征融合、学习参数少等优点。而ResNet模型通过残差学习,有效地解决了深度神经网络难以训练的问题,为高精度、深层次神经网络的构建提供了可能。后续研究者将GoogLeNet的Inception结构与ResNet的残差结构相结合,获得了训练速度更快、精确度更高的Inception-ResNet卷积网络。因此,本文基于Inception-ResNet结构的思想实现对堆芯换料方案关键参数的预测。网络结构如图3所示。
图3构建的卷积神经网络主要分成3大部分:信息初步处理、Inception-ResNet结构和特征整合输出。其中,信息初步处理部分由Inception-ResNet结构前的卷积层和平均池化层构成,用于处理和提取输入图像特征形成新的特征图;Inception-ResNet结构部分由3个Inception-ResNet结构构成,每个Inception-ResNet结构由子网络结构-A、网络结构-B和网络结构-C组成,这3个子结构均采用了不同尺寸和不同数量的卷积核,以便提取和汇聚不同的非线性特征,网络结构-B还用了ResNet的“短接”思想,即输入与输出直连,以解决网络深度增加时产生的训练困难和网络退化现象;特征整合输出部分则由全局平均池化层和4层全连接层构成,用于对Inception-ResNet结构部分输出的特征图进行特征整合、变换并输出评估指标。
信息初步处理部分对输入的1/4堆芯组件布置特征图像进行各通道方向上的特征整合和特征初步提取形成新的特征图,然后Inception-ResNet结构部分对新的特征图进行逐层特征提取、抽象化以及融合形成高度抽象化的方案特征图。最后,特征整合输出部分对抽象化后的特征图在各通道维度上进行特征整合并经过全连接层的特征变化输出堆芯换料方案的评估预测指标。此外,为防止数据特征在前向传播过程中出现偏移,导致训练收敛速度变慢,激活函数采用梯度下降效率高的ReLU(线性整流单元)函数,并在卷积层和激活函数之间进行批标准化操作[11]用于加速神经网络训练、降低对参数初始值的依赖程度。
3 实验程序设计与仿真实现
3.1 数据预处理
在堆芯换料过程中,组件的关键特征参数包括富集度、燃耗深度、历史可燃毒物棒数和经历的循环数。因此,本文选取这4个特征参数作为神经网络的输入物理量,并基于我国某二代改进型压水堆第2循环,利用前述换料限制条件随机生成60 000个不重复的换料方案。以其中1个换料方案为例,其神经网络输入可视化效果如图4所示,其中不同颜色深度代表不同取值大小。
如图4所示,每个堆芯换料方案对应于1个8×8×4的方案张量x,该方案对应的评估参数y由压水堆燃料管理程序SPARK[12]计算获得,并将其作为参考结果用于参数预测的检验。
使用SPARK程序完成对生成的60 000个方案的数值计算,由此获得数据集D={(x1,y1),…,(x60 000,y60 000)}。将数据集中的数据随机打乱,然后按照12∶1∶2的比例将数据集依次切分成训练集、验证集和测试集。其中训练集数据用于神经网络的训练,验证集数据用于超参数的调优,测试集数据不参与训练和验证,仅用于最后评估模型泛化能力。数据集在使用前,为消除数据量纲影响,以加速神经网络训练并且提高精度,需对数据集中所有数据做归一化处理。本文采用Min-Max归一化方法对各物理量进行处理后,数据输入格式仍如图4所示,其公式如下:
(4)
式中:xnorm为归一化处理后的数据;xdata为原始数据;xmin为数据中的最小值;xmax为数据中的最大值。
3.2 模型训练
Adam算法[13]结合了RMSProp算法和AdaGrad算法[14]的优点,对超参数的选择具有一定的鲁棒性,可实现参数空间的高效搜索,故参数的更新算法采用Adam优化算法,算法中用于矩估计的指数衰减速率参数β1和参数β2分别设置为0.9和 0.999,学习率设置为0.001。实验采用小批量训练方法,每次从训练集中随机抽取一小批量数据进行训练,当训练集中所有数据被使用1次后称为1轮训练。

图3 堆芯换料参数预测网络结构Fig.3 Network structure of predicting core refueling parameter
对于训练过程中的模型评价指标和损失函数,实验采用相对误差作为实时评价指标,选用均方误差(MSE)作为损失函数,损失函数公式如下所示:
(5)


图4 卷积神经网络输入量可视化Fig.4 Visualization of convolutional neural network input
神经网络的训练基于TensorFlow2.1.0工具包[15],整个实验在RTX 2060显卡上完成,实验设定批数据量为100,每次抽取前随机打乱。训练过程相关指标变化如图5所示,其中均方误差损失函数将转化成均方根误差(RMSE)以方便展示。
由图5可知,训练过程中未出现训练集和验证集的预测精度明显分离的过拟合现象,模型能快速收敛,这是因为批标准化方法的引入有效地缓解了深度神经网络各层输出结果偏向分布的情况,提高了深度神经网络的训练效率,同时它还向神经网络训练过程引入了噪声,起到了网络正则化效果,有效地抑制了过拟合现象。当训练到第65轮之后,模型的精度基本收敛,因此在第71轮停止模型训练并保存其相关参数。
3.3 预测结果
用测试集中的8 000个方案对训练好的神经网络进行泛化能力评估。测试结果表明,平均每个方案的预测用时为0.000 5 s。各误差范围内方案所占比例分布如图6所示。
从图6可知,在预测的8 000个方案中,99.22%的堆芯临界硼浓度误差绝对值在3.0 ppm以内,平均误差为0.86 ppm,最大误差为6.3 ppm;99.76%的功率峰因子的相对误差绝对值在3%以内,平均相对误差为0.54%,最大相对误差为3.9%;99.87%的核焓升因子的相对误差绝对值在3%以内,平均相对误差为0.38%,最大相对误差为4.7%。此外,对该机组实际采用的第2循环换料方案进行预测结果对比验证,其结果列于表1,误差均在工程要求范围内,这说明模型预测可靠性较高。
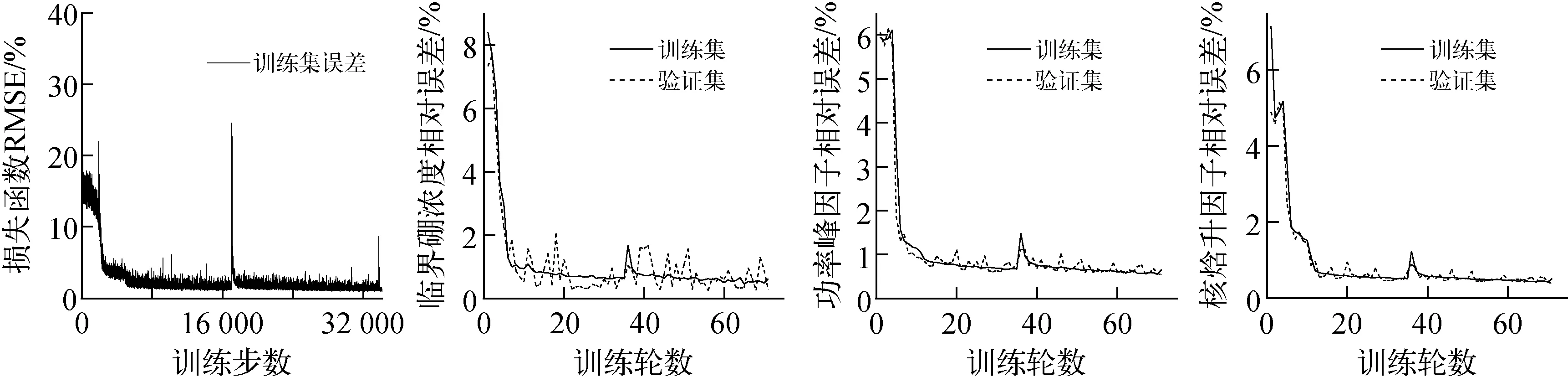
图5 神经网络相关训练指标变化Fig.5 Changes of network parameter during training process

图6 预测结果统计分布Fig.6 Statistical result of network prediction

表1 预测结果对比Table 1 Comparison of prediction results
4 结论
本文基于Inception-ResNet的卷积网络结构,提出了反应堆换料方案堆芯关键参数快速预测方法。通过在我国某二代改进型压水堆上的数值实验表明,本文提出的预测方法具有非常高的预测精度和效率,能减少换料方案优化过程中的人员时间投入,具有非常好的应用前景。作为下一步的研究计划,拟将结合换料方案优化方法,开展快速堆芯换料方案优化相关的研究。
猜你喜欢
能源工程(2022年2期)2022-05-23
今日农业(2021年21期)2022-01-12
现代畜牧科技(2021年3期)2021-07-21
河南畜牧兽医(2021年1期)2021-01-07
重型机械(2020年2期)2020-07-24
装备制造技术(2019年12期)2019-12-25
辐射防护通讯(2019年3期)2019-04-26
核技术(2016年4期)2016-08-22
核科学与工程(2015年3期)2015-09-26
核科学与工程(2015年2期)2015-09-26
