
具有仿射变换锚点的文字检测方法
2021-02-03 09:35:06仝明磊姚宏扬
上海电力大学学报 2021年1期
仝明磊, 姚宏扬
(上海电力大学 电子与信息工程学院, 上海 200090)
文字检测是计算机视觉中的一个重要部分,也是文字识别的必要过程。自然场景下的文字检测目前依然面临很大的挑战,主要是因为自然场景图像中的文字在亮度、模糊、形状、方向等方面有很高的随机性,导致文字检测的难度较大。
近年来,研究者提出了很多的文字检测方法[1-5]。尽管这些方法提高了检测结果,但大多还是基于水平的检测方式,无法有效解决自然场景图像中文字复杂多变的情况。在实际应用中,大部分图片中的文字区域都不是水平的,通过以前的水平候选区方法来大量训练并不能得到很高的检测精度,还会增加大量的计算时间。最近带有几何方向性的文字检测方法被提出[6-7]。该方法主要是通过自底向上的卷积神经网络(Convolutional Neural Network,CNN)[8-9]进行特征提取来生成文字预测特征图,再通过计算有倾斜性质和特殊形状的锚点框与特征图上网格之间的置信度,使用回归方法或者其他精细调整方法得到最终的检测结果。区域提议网络(Region Proposal Network,RPN)与Faster-RCNN[10]框架的结合,进一步加快了锚点的提议进程。本文将角度信息和仿射变换信息加入多方向文本检测的模型中,以期进一步优化适应文字区域的检测。
1 仿射变换锚点
1.1 水平锚点
RPN可以进一步加速区域提议的生成过程,采用残差网络(Residual Network,ResNet)[11]的一部分作为共享网络层,通过在最后一层卷积得到特征图上滑动窗口来生成水平区域提议。每个滑动窗口得到的特征提取后,被送入回归层(regression)和分类层(classification)中;回归层输出的每个提议框上有4个参数(宽、高、中心位置x坐标和y坐标),另外每个滑动位置的锚点还有2个分数从分类层输出。
RPN使用尺度和宽高比两个参数控制锚点的大小和形状,以便更好地适应不同尺寸的文字。尺度决定锚点的大小,宽高比决定锚点的形状比例。在文字检测中,尤其是自然场景下的图像,文本通常都以非常规形状表现,如果只使用RPN产生的水平锚点,对于场景文字检测来说鲁棒性较差。为了提高网络检测的鲁棒性和准确率,有必要建立一个适应文本形状的检测框架。
1.2 网络结构
本文所提网络的整体框架使用ResNet-101的卷积层进行特征提取,增加仿射变换参数的RPN对最后一层卷积的特征图进行区域提议。图1为仿射变换区域提议网络结构。
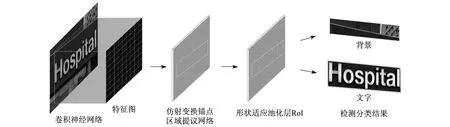
图1 仿射变换区域提议网络结构
首先,从场景图像上的预测文本实例中生成适应方向和变换的提议,然后对提议进一步回归边界框来适应真实文本区域。由回归层和分类层输出的回归提议信息和分类分数计算回归和分类损失,最终汇总为多任务损失。兴趣区域(Region-of-Interest,RoI)池化层将带有仿射变换的提议映射到特征图上。最后,通过两个全连接层组成的分类网络将RoI特征区域分为前景文字区域和背景。
1.3 训练集处理
训练时,图像上文本实例的位置形状坐标由标注真值框4个角的坐标(x1,y1,x2,y2,x3,y3,x4,y4)获得,输入网络时通过计算转换为6个参数(x,y,h,w,θ,trans_x)。坐标(x,y)表示文本边界框的几何中心坐标;高度(h)为边界框的短边长度;宽度(w)为边界框的长边长度;角度(θ)为边界框长边与坐标轴x之间的夹角;变换值(trans_x)为长边方向的仿射变换偏移量。文本框的中心坐标、长宽和角度由文本边界框真值坐标求出的最小外接矩形得到,仿射变换值由最小外接矩形与边界框真值的x坐标差值得到。
1.4 仿射变换锚点
传统的水平锚点不能进行很好的文字检测,因此本文设计了具有仿射变换的旋转锚点,并且进行了相应的调整和改进。
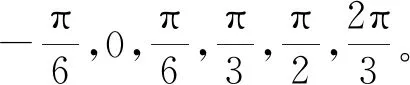
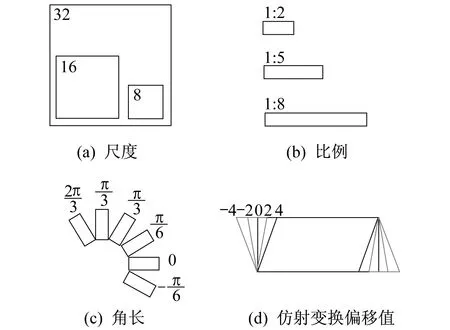
图2 网络中锚点的固定参数
训练数据经过预处理步骤后,一个提议锚点中有6个参数(x,y,h,w,θ,trans_x)。对于特征图上的每个点,生成3×3×6×5共270个锚点。在每个滑动窗口经过的位置上分别生成6×270共1 620个输出,分类层生成2×270共540个输出。根据仿射变换锚点网络在宽度为W、高度为H的特征图上滑动,总共生成H×W×270个锚点。训练数据所给的坐标真值数量较少,如果直接选择为训练结果,容易产生过拟合现象。由于RPN中锚点数量多、形状变化大,因此将锚点作为RPN的候选框进行正负样本分类时,网络会学习这些具有仿射变换属性的锚点。通过计算文本坐标真值框与仿射变换锚点的面积交并比(Intersection-over-Union,IoU)来判断检测效果的好坏。正样本定义为:最高的交并比或交并比大于0.7,锚点的方向角度与文本坐标真值的旋转角度小于π/12[12],并且仿射变换的变换值小于2。负样本定义为:交并比小于0.3,交并比大于0.7,但旋转角度超过π/12。其余为不参与训练的多余样本。
1.5 损失函数
RPN在候选框生成完成后,还需要使用Faster-RCNN的全连接层对这些候选框进行准确检测。检测过程分为回归网络和分类网络两个部分,损失函数分为分类损失和回归损失:分类损失是指候选框在前景背景分类时的误差;回归损失是指候选框与标注真值框的几何参数的误差。
对于仿射变换锚点,网络采用了多任务损失函数,定义为
L(p,l,v*,v)=Lcls(p,l)+λlLreg(v*,v)
(1)
式中:p——softmax函数计算的类的概率,p=(p0,p1);
l——分类标签的指示符,l=1为文本,l=0为背景,对于背景不进行回归;

v——文本标签预测出的参数组,v=(vx,vy,vw,vh,vθ,vtrans_x);
Lcls,Lreg——分类损失和回归损失;
λ——平衡控制参数。
分类损失与回归损失之间由λ权衡。其中将分类损失定义为
Lcls(p,l)=-logpl
(2)
对于边界框回归,背景RoI被忽略。文字RoI采用了smooth-L1损失函数,即
(3)
(4)
候选框形状参数元组v和v*的计算方式为
vθ=θ-θa+kπ,
vtransx=transx-transxa
(5)
vθ*=θ*-θa+kπ,
(6)
式中:x,xa,x*——预测框、锚点和标注真值框;

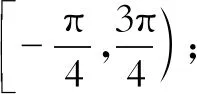
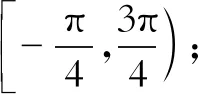
w*,h*——标注框的宽和高;
wa,ha——锚点的宽和高;
k——任意整数。
仿身变换区域提议网络可以提供大量不同形状的锚点,针对任何仿射变换形状的文本实例都可以在合适范围内拟合形状。
1.6 优化计算
由于引入了仿射变换形状的锚点,在计算IoU时相交面积不再是矩形,因此可能会造成IoU计算不准确,影响网络训练学习。针对新的锚点形状,设计了一种求解任意形状四边形相交面积的IoU算法。输入锚点和标注框的6个坐标形状参数(x,y,h,w,θ,trans_x)转化为4个角的点坐标,通过4个角的点坐标求出凸包形状,即仿射变换锚点和标注框的形状,通过这两个图形分别求出各自的面积和重叠面积,最终可以得到两个仿射变换形状的IoU。
2 实 验
本文在文字检测公共竞赛数据集ICDAR2015[13]和ICDAR2017MLT[14]上进行了实验。这两个数据集的图像和标注坐标都具有仿射变换形状,可以训练和测试文字检测网络的几何文本检测能力。ICDAR2015是用于文本检测的常用数据集,共包含1 500张图片,其中1 000张用于训练,其余用于测试。文本区域由四边形的4个顶点注释。ICDAR2017MLT是大规模的多语言文本数据集,包括7 200个训练图像、1 800个验证图像和9 000个测试图像。数据集由来自9种语言的完整场景图像组成。与ICDAR2015类似,ICDAR2017MLT中的文本区域也由四边形的4个顶点注释。
实验使用一块TITAN X显卡,显存为12 GB,CPU为Intel Core i5-2320 @3.00GHz×4,内存为15.6 GB。实验中,网络在前200 000次迭代中的学习率为10-3,后100 000次迭代中的学习率为10-4,权重衰减为5×10-4,动量为0.9。
训练时,锚点形状参数中的倾斜角度(θ)和仿射变换变换值(trans_x)由输入训练图片的标注坐标真值求出。在输入文本框水平时,当左上点坐标的x坐标值大于文本框最小外接矩形左上点x坐标值,则仿射变换偏移值取正;当右下点坐标的x坐标值小于文本框最小外接矩形右下点x坐标值,则仿射变换偏移值也取正,如图3所示。图3中,X是指某一段的偏移量。训练时生成的仿射变换变换值(trans_x)就由左上点坐标的偏移值与右下点坐标的偏移值取平均值得到。
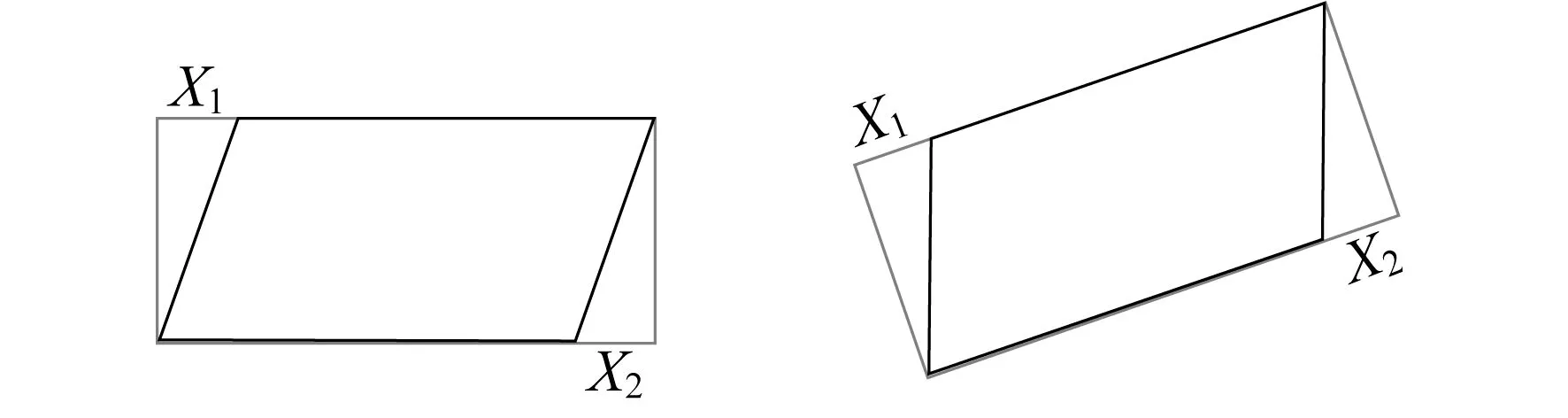
图3 仿射变换偏移值
使用ICDAR2015的训练数据集进行训练,该数据集包含1 000张图像和10 886个文本实例。检测的结果如下:召回率为0.62;准确率为0.81;F1值为0.71。即使给定了270种形状的锚点,但是一些训练的文本区域仍然太小,导致召回率的提升不是很高。
与同类方法在标准数据集上进行了对比,结果如表1所示。
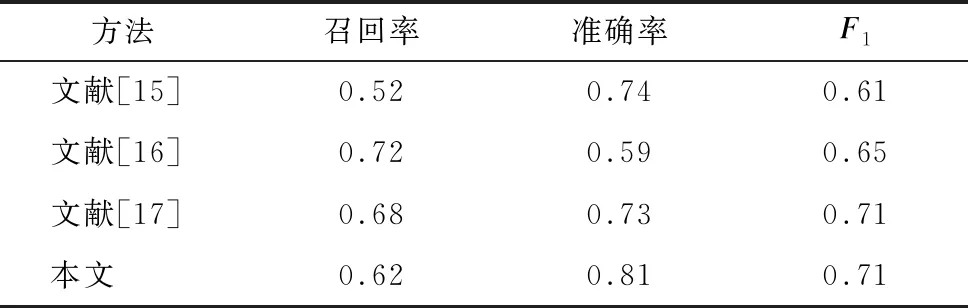
表1 不同文字检测方法在ICDAR2015上的常用评价指标对比
由表1可以看出,由于本文方法带有仿射变换属性,可以更好地检测到真实场景图片中的文字目标区域,检测出的文字框形状与文字真实形状更加贴合。
图4为检测过程模拟及检测结果。由图4可知,相比水平检测方法和带角度的矩形检测方法,具有仿射变换形状的检测方法对于图片上的文字区域能够更好地框选出来,不会像普通检测算法一样框选出很多不需要的背景区域,从而提高了检测精准度。另外,检测出来的文字框具有仿射变换参数,可以轻松地将文字区域反求转换成矩形正面字体,方便后续识别等操作。

图4 检测过程模拟及检测结果
3 结 语
针对现实场景图片中的文字大部分具有仿射变换和多方向的形状,以及传统水平锚点检测无法很好检测场景图片中文字的问题,本文设计了一个带有仿射变换锚点的文本检测网络。利用网络中较高卷积层的文本位置信息,结合具有仿射变换形状的锚点,生成了具有任意方向和仿射变换形状文本的检测网络。在ICDAR2015和ICDAR2017数据集上进行了实验比较,结果表明,本文所提出的仿射变换文字检测网络在场景文字检测任务中具有较高的准确率。
猜你喜欢
中学生天地(A版)(2022年11期)2022-11-25 07:43:16
通信电源技术(2021年2期)2021-05-21 02:33:46
电子技术与软件工程(2020年22期)2021-01-30 05:29:42
数字技术与应用(2020年12期)2021-01-22 13:40:40
移动通信(2020年5期)2020-06-08 15:39:51
新世纪智能(英语备考)(2018年11期)2018-12-29 10:56:52
电子制作(2017年1期)2017-05-17 03:54:35
小学生学习指导(低年级)(2016年10期)2016-12-01 06:10:42
智能系统学报(2015年5期)2015-12-03 05:18:20
浙江大学学报(工学版)(2015年2期)2015-05-30 07:05:04
