
一种改进的鸡尾酒排序算法
2021-01-26 03:13:40苗潇文张细凯
西南民族大学学报(自然科学版) 2021年1期
张 凡,殷 锋,苗潇文,张细凯
(西南民族大学计算机科学与技术学院,计算机系统国家民委重点实验室, 四川成都 610041)
鸡尾酒排序算法是一种基于双向遍历的冒泡排序改进算法,具有冒泡排序算法的稳定性[1]. 该算法通过对序列进行双向遍历排序,有效地缩小了数据比较区间,在一定程度上提高了冒泡算法的排序效率,但算法仍存在大量重复的数据比较、对初始输入序列的数据随机度过敏感以及比较区间收缩不彻底等问题[2-3].对于该算法的改进思想主要是缩小数据比较区间以及减少重复的数据比较,改进方法主要有通过标记是否发生数据交换来降低数据的重复比较,跳过有序数据单元来缩小数据比较区间[4-6].通过上述方法改进的鸡尾酒排序算法的排序效率虽有所提高,但仍存在大量冗余重复的数据比较,数据比较区间也存在进一步收缩的可能性.
本文提出的T -CCS 算法利用标记数据交换位进行分段式逆向遍历排序,在正向遍历比较过程中以发生数据交换为条件,标记发生数据交换位置的同时开始分段逆向遍历排序,直到不发生数据交换条件时跳回标记位继续正向遍历,直到再次发生数据交换时更新标记位并重复上述过程直到所有排序完成,有效的缩小了正向遍历和逆向遍历的数据比较区间,同时由于将逆向遍历比较进行了分段处理,保证了在标记位前的数据为有序序列,进一步减少了重复的数据比较.

图1 两种算法排序效率比较Fig.1 Comparison of the sorting efficiency of the two algorithms
鸡尾酒排序算法作为一种改进的冒泡排序算法,在某些条件下,可以大量的减少待排序列数据间的比较次数,有效的提高冒泡算法的排序效率[10],但是其仍存在以下缺陷:
首先,根据鸡尾酒排序算法排序的流程图可知,它每次进行正向或者逆向排序时均带着一个特定的“目标”,即完成该次排序后应该将某个数据放置某个特定的位置.例如第一次正向遍历排序的目标便是找出最大值放到数组的最后一位,第一次逆向遍历排序的目标则是找到最小值放到数组的第一位,这种带着“目标”进行排序的方式,忽略了排序过程出现的多次重复的数据比较,降低了排序效率;其次,输入待排序列中可能存在一些存储在连续单元里的有序数据,该
1 鸡尾酒排序算法
鸡尾酒排序算法又称来回涟漪排序算法,它是为减少待排序列数据之间的比较轮次而衍生出来的一种改进型的冒泡算法[7],相较于传统的冒泡排序算法[8-9]的排序效率有一定的提升(如图1 所示).其主要思想是假设待排的n个数据存储于一维数组N中,在第一次正向遍历中依次进行冒泡排序操作,找出最大值置于数组的最后一位N[last],缩小比较区间为N[0]到N[n-1]并从N[last-1]处开始逆向遍历依次进行冒泡排序操作并找出最小值置于数组的第一位N[begin],此时缩减比较区间N[1]到N[n-1],再次进行正向遍历排序.重复上述过程直到不再发生数据交换时,排序结束.其排序流程如图2 所示.算法仍会对这些数据进行多次重复比较[11],使得数据比较区间收缩不够彻底,仍有优化的空间[12],尤其是当输入待排序列的数据规模较大时,每次全序列遍历比较都会消耗大量的时间[13-14];最后,该算法的排序效率受到初始输入待排序列的数据随机度影响[15],在某些情况下其排序效率会迅速降低.
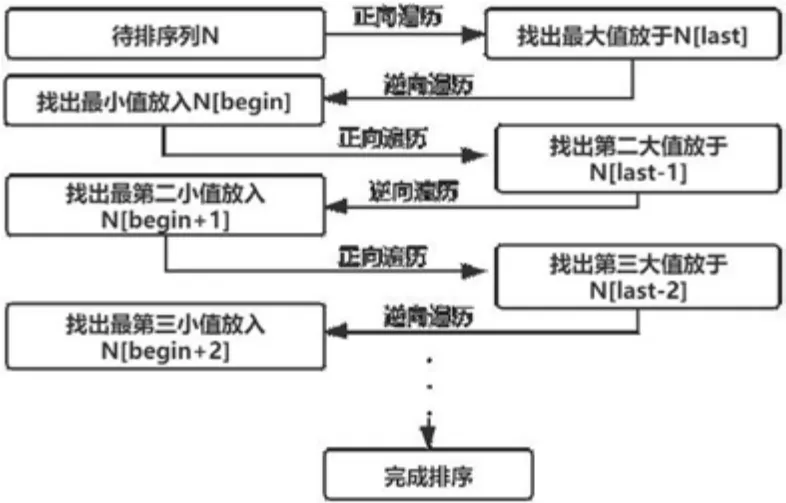
图2 鸡尾酒算法排序流程图Fig.2 Cocktail algorithm sorting flow map
2 改进的鸡尾酒排序算法
针对上述中鸡尾酒排序算法存在的缺陷,本文提出了一种分段式逆向遍历排序的鸡尾酒排序算法.该算法的主要思想是在排序的正向遍历排序过程中,如果在x处数据间发生了位置交换,则立即从x处开始进行逆向遍历排序,同时标记位置x,直到不出现数据交换而结束逆向遍历排序,返回标记位置x继续未完成的正向遍历排序并重复执行上述操作直到不再出现数据交换.这样就保证了在标记位x之前的序列均为有序序列,从而有效地缩小了后续遍历时的数据比较区间.由于进入逆向遍历排序的条件是当排序过程出现了数据交换,因此只要满足该条件,便会一直进行逆向遍历排序,直到不再发生数据交换,即逆向遍历排序条件不成立时结束逆向遍历排序返回标记点继续正向遍历排序.这种排序方式将进行多次局部的逆向排序操作,而理论上只需要进行一次完整的正向遍历便可完成整个序列的排序. 本文的算法描述如下:

为了更直观的描述T -CCS 的排序过程,现给出一个按索引值排序的随机序列a,其使用T -CCS 排序的过程图如图3 所示.
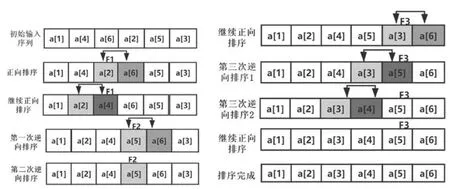
图3 T-CCS 对序列a 进行排序的过程Fig.3 T-CCS sorting map diagram for sequence a
第一步:在对序列a 进行正向遍历排序时,a[6]与a[2]发生了位置交换,触发第一次逆向遍历排序,同时在a[2]处设置标记位F1.
第二步:第一次逆向排序中,a[2]与a[4]满足数据位置交换条件,发生了数据位置交换,满足继续逆向遍历排序的条件,因此比较a[2]与a[1],由于a[2]>a[1],未发生数据位置交换,不满足继续逆向排序的条件,随即停止第一次逆向排序,从F1处继续未完成的正向遍历排序.
第三步:a[6]与a[5]发生交换,触发第二次逆向遍历排序,同时在a[5]处更新标记位为F2.
第四步:由于a[5]>a[4],未发生位置交换,不满足继续逆向遍历排序的条件,因此停止第二次逆向遍历排序,从F2处继续未完成的正向遍历排序.
第五步:a[6]与a[3]发生位置交换,触发第三次逆向遍历排序,同时在a[3]处更新标记位为F3.
第六步:a[3]与a[5]发生位置交换,满足逆向遍历排序的条件,继续第三次逆向遍历排序.
第七步:a[3]与a[4]发生位置交换,仍满足逆向遍历排序的条件,继续第三次逆向遍历排序.
第八步:a[3]<a[2],不满足继续逆向遍历排序的条件,返回F3处继续未完成的正向遍历排序.
第九步:a[5]与a[6]未发生位置交换,且正向遍历排序结束,完成排序.
3 实验与分析
在了解T-CCS 算法的原理后,将通过实验进一步对T-CCS 的排序效率进行分析. 无论是T -CCS还是鸡尾酒排序算法,都没有跳出二层嵌套循环这一双向排序算法所必要的条件,因此算法的时间复杂度并未发生改变.但T -CCS 通过减少重复的数据比较和逐次缩短比较区间,降低了算法的空间复杂度,有效的提高鸡尾酒算法的排序效率.
为了比较本文算法与鸡尾酒排序算法以及常见改进算法的排序效率,引入不同规模相同随机度的随机序列,通过对已有实验数据的拟合预测,得到大规模输入数据下各算法的耗时情况.四种算法关于输入序列数据规模的耗时表现分别为表1 和图4 所示.
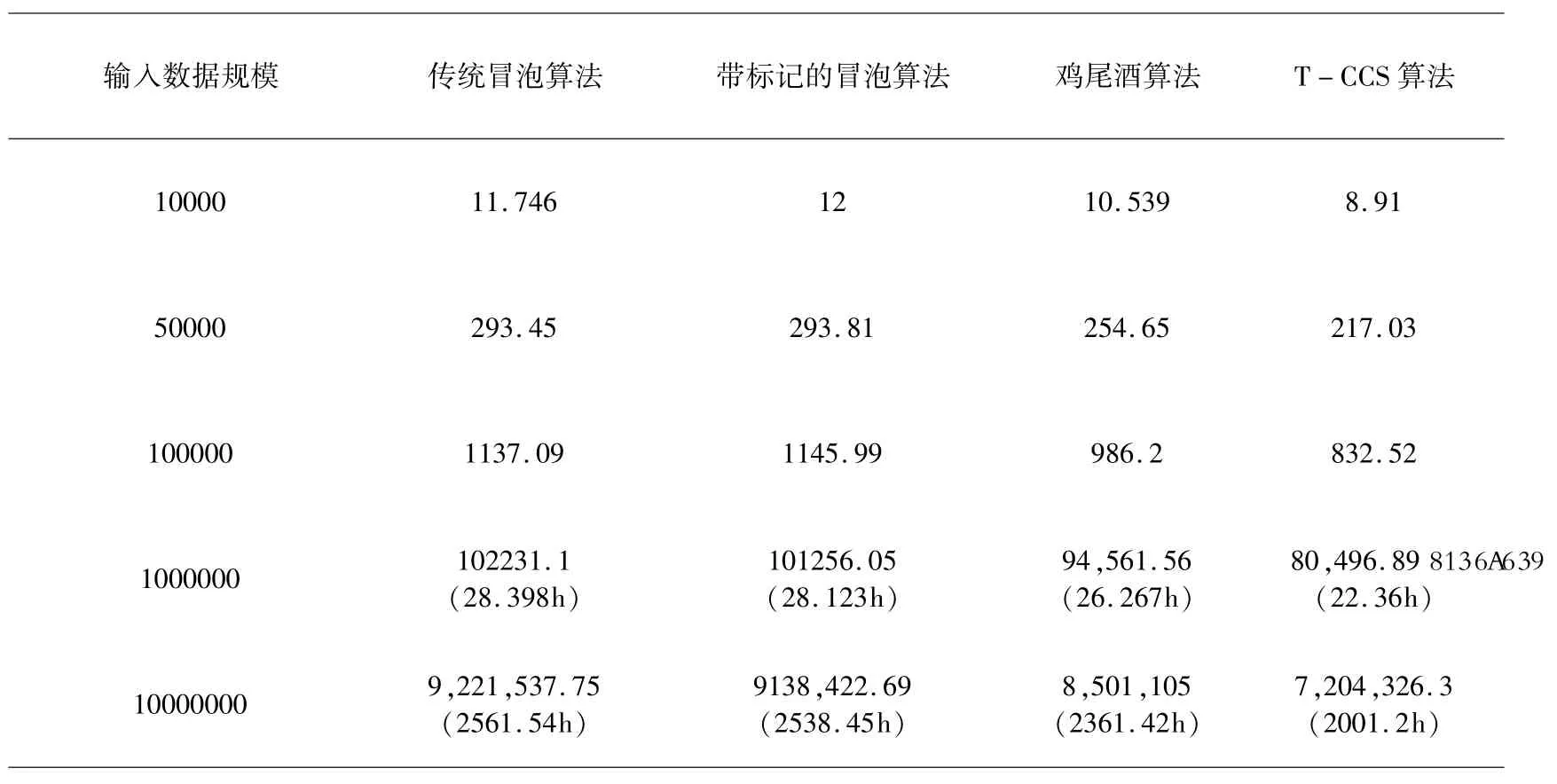
表1 四种排序算法关于输入规模的耗时(单位:秒)Table 1 Time-consuming (in seconds) for four sorting algorithms on input scale
由表1 和图4 可知,随着输入序列的数据规模不断增大,传统的冒泡算法和带标记的冒泡算法在排序耗时上趋于相同,与鸡尾酒排序算法的执行效率差距逐渐增大,而T -CCS 算法在对大规模数据序列的排序耗时远远低于其他三种算法,且当数据规模增大时T-CCS 的效率优势越发明显.总体来说,T -CCS 算法比传统的冒泡排序算法的排序效率提高26% 左右,比鸡尾酒排序算法的排序效率提高20%左右,且这种提升不会因为输入序列的数据规模增大而产生震荡,是一种稳定的效率提升.

图4 四种排序算法关于输入规模的耗时趋势图Fig.4 Time-consuming trend map of four sorting algorithms on input scale
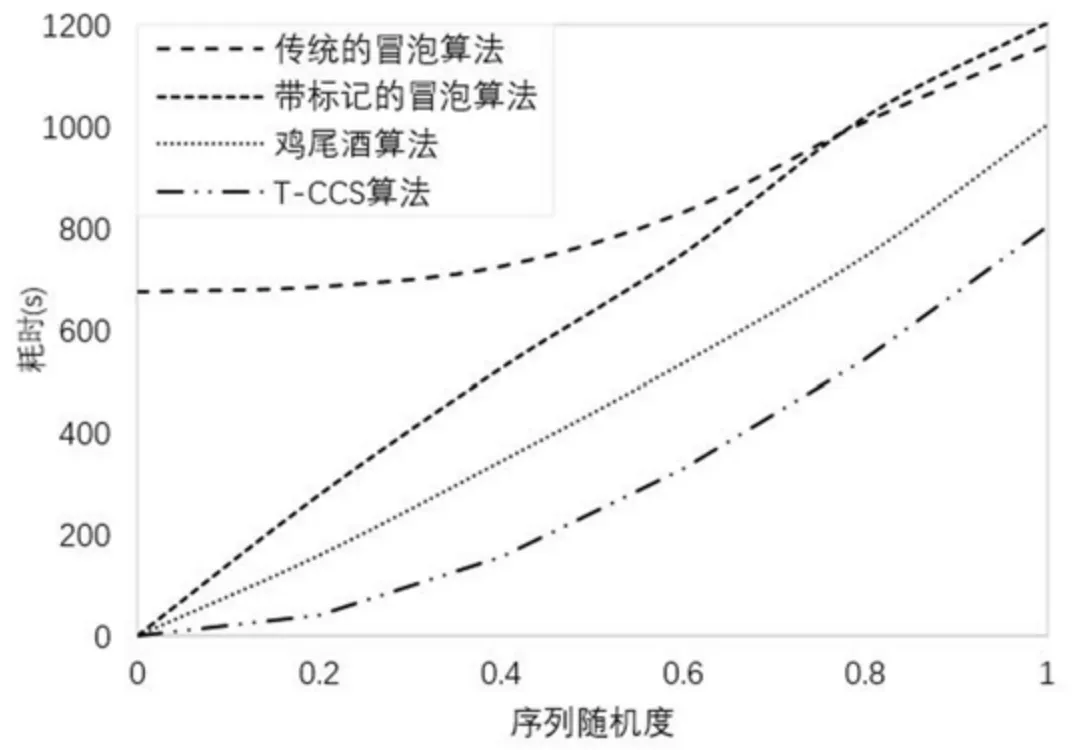
图5 四种排序算法关于序列随机度的耗时趋势图(数据规模:100 000)Fig.5 Time-consuming trend map of four sorting algorithms on sequence randomness (data size:100 000)
为了比较四种算法在对相同规模不同随机度输入序列的排序中的表现,引入随机度x来衡量输入序列的数据有序程度,x的值表示输入序列中无序序列所占的比例.当x为0 时,数据的随机度为0,表示输入序列为顺序序列;当x为1 时,数据的随机度为1,表示输入序列为倒序序列.当指定输入序列的数据规模为100 000 时得出四种算法关于输入序列随机度的表现如表2,图5 所示.

表2 四种冒泡排序算法关于数据随机度的耗时(单位:秒)Table 2 Time spent by four bubble sorting algorithms on data randomness (in seconds)
由表2 和图5 可知,在同等规模的输入数据下,传统的冒泡排序算法因其独特的排序原理,它的排序效率受序列随机度的影响较小;当序列随机度在[0,0.6]区间时,带标记的冒泡排序算法的排序效率要高于传统的冒泡排序算法,而当序列随机度在[0.8,1]区间时,其表现反而不如传统的冒泡排序算法,因此该算法更适合低随机度的序列的排序处理
传统的鸡尾酒算法与T -CCS 算法的效率均受到数据随机度的影响,其中鸡尾酒排序算法受到的影响近乎为线性的影响,当序列随机度在[0 -0.2]区间时,T-CCS 算法对序列随机度的敏感度与传统的冒泡排序相差无几;当序列的随机度在[0,0.4]区间时,T-CCS 算法对序列随机度的敏感度低于传统的鸡尾酒算法,当序列的随机度在[0.4,1]区间时,两种算法对序列随机度的敏感度基本相同,但是在相同的序列随机度下T -CCS 算法相比于传统的鸡尾酒算法有着更高的执行效率.
4 总结
数据的排序是计算机科学中某些研究问题的前提和基础.与传统的冒泡排序相比,鸡尾酒排序算法的效率有一定程度的提高,但仍存在改进的可能,该算法在排序过程中存在的重复冗余数据比较和比较区间收缩不彻底等问题仍然是改进的方向,. 针对上述问题,本文根据双向排序的相关理论,对鸡尾酒排序算法做出了一定改进并进行实验分析.实验结果证明,本文提出的T -CCS 算法在大规模数据排序效率以及对输入序列数据随机度的敏感度等方面都取得了较好的效果.
猜你喜欢
音乐天地(音乐创作版)(2022年1期)2022-04-26 13:51:38
中学生数理化·七年级数学人教版(2022年11期)2022-02-14 07:14:12
中学生数理化·八年级物理人教版(2020年12期)2021-01-18 05:46:38
科普童话·学霸日记(2020年1期)2020-05-08 16:45:11
现代装饰(2020年3期)2020-04-13 12:53:54
现代装饰(2019年11期)2019-12-20 07:06:32
小天使·一年级语数英综合(2019年2期)2019-01-10 11:57:30
基层中医药(2018年3期)2018-05-31 08:52:09
儿童绘本(2018年5期)2018-04-12 16:45:32
中学课程辅导·高考版(2017年6期)2017-06-13 07:21:57
