
基于贝叶斯算法的上证指数择时研究
2021-01-25 16:11王慎敏
湖北经济学院学报·人文社科版 2021年1期
王慎敏

摘 要:本文根据贝叶斯算法构建了一套多因子择时模型,以上证综指为标的,使用了20多个技术因子和基本面因子,选取2008到2016年的数据,每天开盘前根据前两年的数据建模,预测当日标的指数的涨跌,并对比了朴素贝叶斯算法和基于爬山算法的贝叶斯网算法。回测结果显示,贝叶斯网算法可以提供更稳定的收益和更高的正确率。本文同时根据模型输出信号设计了一种仓位优化算法提升模型效果,在后续的模拟组合跟踪中,模型也持续有效。
关键词:朴素贝叶斯;贝叶斯网;指数择时
一、引言
股票市场的价格在表面上看杂乱无章,但众多学者的研究表明,众多因素都可以影响股票价格,股价并非完全随机的。量化择时的目的就是通过各种指标来预测市场趋势,并在低位买入,高位卖出来获得超过市场的收益。对量化择时的研究,在目前主要分为技术派和基本面派,前者主要通过研究各类技术指标和形态等,结合历史数据来对后市进行判断,后者主要通过基本面以及资金面等来研判后市。而本文尝试使用贝叶斯算法,将技术面和基本面信息结合在一起,构建因子间的贝叶斯网络,对下一交易日的指数涨跌进行预测。
二、贝叶斯模型简介
(一)朴素贝叶斯
朴素贝叶斯分类(Nave Bayes Classifier)是以贝叶斯定理为基础并且假设特征条件之间相互独立的方法,先通过已给定的训练集,以特征值之间独立作为前提假设,学習从输入到输出的联合概率分布,再基于学习到的模型,求出使得后验概率最大的输出。
(二)基于爬山算法的贝叶斯网
朴素贝叶斯分类只能处理离散数据,需要将连续数据离散化。对于连续数据,这里也使用了基于爬山算法的贝叶斯网。
爬山算法是一种搜索算法,该算法每次从当前解的临近解空间中选择一个最优解作为当前解,直到达到一个局部最优解。在一个贝叶斯网中,存在许多不同的父子级。而每个子级都有其自己的区域联合概率密度函数。在找到后验概率分布后,会对其和数据的拟合程度进行打分,然后使用爬山算法找到分值最大的后验概率分布。通过爬山算法寻找合适的参数,来使贝叶斯网的分数最大化。
三、因子选取和数据处理
(一)因子选取:
数据主要包括以下20余种:
自变量:上证综指
因变量:黄金现货,原油现货,天然气现货,白银现货,美元指数,LIBOR,SP500,人民币对美元汇率,上海期货交易所金铜铝,恒生指数, SHIBOR,中国债券指数,月度CPI,月度制造业指数,美国1年期债券,交易量等时间区间为2010年1月至2016年8月共6年数据。
(二)数据准备与参数选取
将自变量和因变量按大小排序,分2类或者分5类,并分别标记为0至1或0至4。
主要参数选取:经过参数优化,选取时间窗口长度为24个月。
模型训练方式:以时间窗口内数据为样本进行训练贝叶斯模型,每天开盘前将最新的因子数据输入模型,预测当天的指数涨跌。
四、朴素贝叶斯模型回测
(一)使用分2类的自变量,以及分5类的因变量。
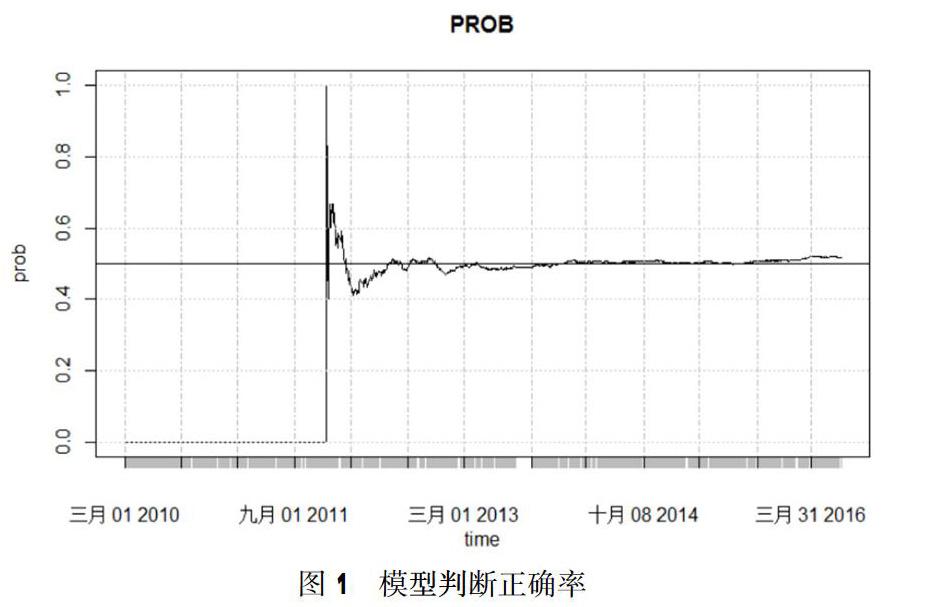
将判断正确记录为1,错误记录为0,每天将其累加/总判断次数,得到模型判断正确率。如图1所示,正确率在50%附近,表明模型有效性较低。
(二)使用分2类的自变量以及因变量。
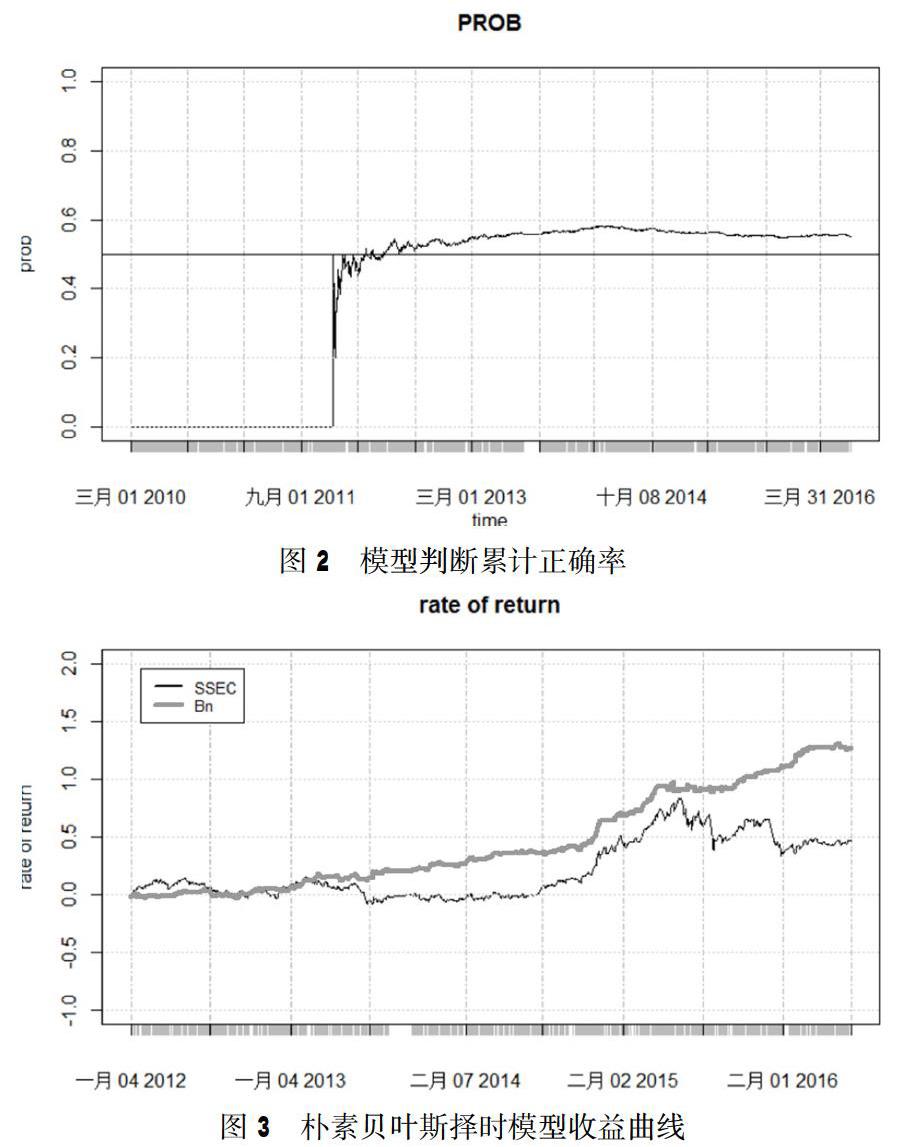
如图2,正确率在55%至60%之间,正确率随时间推移达到峰值后有所降低。
根据每天的模型输出结果,预计涨则买入,其余时间维持空仓。收益曲线见图3。
累计收益率:127%
年化收益率:27.25%
最大回撤:-8.7%
五、贝叶斯网模型回测
(一)使用连续数据的自变量和因变量带入模型进行回测:
部分变量的关系
如图5所示,正确率在0.59附近持平,说明模型的预测能力较强,正确率高于朴素贝叶斯模型。
设计两种策略:
Bn0:预计涨则买入1单位指数,其余时间维持空仓。
Bn1:预计涨则买入2单位指数,其余时间维持1单位指数。
Bn0:
最大回撤:-17.6%
累计收益率:142%
年化收益率:30.43%
由以上数据可知,贝叶斯网模型的回测结果的年化收益率高于朴素贝叶斯模型,但是最大回撤较高,下面将设计一种仓位优化方式来对回测指标进行优化。
六、仓位优化
在上述贝叶斯网的回测当中,模型输出的预测值是一个连续数值,但是仓位只分为0,1倍或者2倍指数,精细度较低,并不能完全反应模型的输出结果的所有信息。下面本文将设计一种仓位计算方法来充分利用输出的结果。
将模型输出结果在固定区间内排序,得到输出结果在这个固定区间内对应的分位数。将该分位数与下一日的指数收益率进行对应。纵坐标为指数收益率均值。横坐标为50 例如x=90,表示大于90%分位数的预测值所对应的所有指数收益率的均值。 通过观察图7的图形规律设计函数:(a*(2p-1))^b,p为分位数。 在样本区间内取最近两年的数据,通过遍历不同的a和b值计算每日仓位,将每日仓位乘以每日指数涨跌幅计算择时后收益和最大回撤。不同的a和b值可以得到不同的收益/最大回撤比值,进而得到以下热力图(图8)。 由图8知,收益/最大回撤最大时,a=1.15,b=2.2, 因此仓位方程为:(1.15*(p*2-1))^2.2 考虑到上述的回测都是以昨收盘价进行买入,而实际中是无法成交的。这次回测以开盘价买入,若当日仓位大于50%,则在尾盘将仓位降低到50%。并增加每日回撤和仓位进行比较。 从2014年1月到2016年8月,累计收益83%,年化收益31.20%,最大回撤10.3%。最大回撤发生在2015年6月29日。收益曲线见图9。年化收益以及最大回测相对于仓位优化前的都有所提升。 因为这都是基于历史数据的回测,在真实的金融市场是否有效还有待进一步验证,因此,本文下一步对仓位优化后的贝叶斯网模型进行模拟建仓跟踪。 七、模拟建仓跟踪 在2016年9月5日—2016年12月30日期间,每天开盘前根据模型计算当天仓位,收益率4.6%,累计最大回撤1.5%。验证阶段正确率达到65%。 模型理论最大收益4.4%,最大回撤1.7%,见图10。 如图11所示,模拟跟踪以来仓位对应平均收益,横坐标为仓位,0%到100%,纵坐标为指数收益。指数收益与仓位大小正相关。 考虑滑点,以开盘价成交,如图12所示,收益:2.8%,高于指数收益。 根据模拟持仓跟踪可以发现,贝叶斯网择时模型是有效的,可以较准确的预测指数涨跌并得到高于指数的收益。 八、总结 本文以上证指数为预测标的,选取了多种技术指标和基本面指标,在对数据进行了预处理和模型参数优化后,通过在每天开盘前预测当天指数的预期涨跌,并设计一套算法对仓位进行优化,构建了一套不同于传统择时模型的基于贝叶斯算法的日频指数择时策略,并在之后进行了每日的模拟建仓跟踪以验证其有效性。 通过贝叶斯择时模型的回测发现,朴素贝叶斯分类法的正确率不如贝叶斯网算法高,通过对模型的输出结果进行分析,从而对仓位进行优化后,回测的年化收益率和最大回撤指标有了进一步的提升。 在后续的模拟建仓跟踪中,可以观察到该模型近期效果良好,效果符合回测组合中的指标。因此该模型是有效的,贝叶斯网模型在量化择时策略中具有较高的应用价值。各种基本面指标和技术指标与上证指数之间存在一定的联系,而且其可以用贝叶斯模型进行有效描述,从而对上证指数进行预测。 在后续的优化中,如果将因子个数进一步提升,预计会有更高的正确率。在后续的模拟验证阶段发现,国内的政策性事件无法在模型中反映出来。将来可以在模型中加入事件驱动策略,对模型进一步提升。 参考文献: [1] Nagarajan R, Scutari M, Lebre S.“Bayesian Networks in R with Applications in Systems Biology”. Springer,2013. [2] Scutari M.“Learning Bayesian Networks with the bnlearn R Package”.Journal of Statistical Software,2010,35(3):1-22. [3] Scutari M. "Bayesian Network Constraint-Based Structure Learning Algorithms: Parallel and Optimized Implementations in the bnlearn R Package". Journal of Statistical Software,2017,77(2):1-20. [4] 孫旭.基于中国股票市场趋势预测的择时策略研宂[D].兰州:兰州大学,2018.
