
基于聚类分析和主成分分析的城市空气质量评价
——以山西省11个地级市为例
2021-01-25 01:36:02陈颖张仲伍
山西师范大学学报(自然科学版) 2020年4期
陈颖,张仲伍
山西师范大学地理科学学院,山西 临汾 041000
0 引言
山西作为能源丰富的大省,自改革开放以来,其经济逐渐进入高速增长阶段,城镇化不断推进.1978年~2017年,山西国内生产总值由108.8亿元增长至12 966.2亿元,城市化率由16.24%上升至56.21%.伴随着工业化与城市化的快速发展,人民生活水平大幅提高,使得大量人口逐渐向城市聚集,城市便成为了环境污染的聚集地.山西省在2013年空气污染极其严重,同时“雾霾”也成为了大众口中的热词,引起多方关注.2014年,习近平主席尤其重视这个问题,提出控制PM2.5是我们的当务之急.2016年冬天,雾霾天气持久性最强,多个城市已被严重污染,对其环境、人民的身体健康均产生了不好的影响,严重限制了人们的出行,造成极其多的不便.数据来源于2017年的《山西统计年鉴》[1],基于SPSS 22软件对查找及整理的数据进行分析:首先采用聚类分析,需对样品进行量化分类,其次借助K均值法对样品进行快速聚类,距离的远近即代表亲疏;主成分分析法主要是对数据进行简化,解释变量相互间的关系,进行统计并得出结论.它可将指标简单化、综合化,是一种常用的统计方法,在日常的应用中对一些数据进行分析与降维.众所周知,当判断一个区域的空气质量时,我们需考虑相当复杂的因素,运用主成分分析找出其影响最大的因素.本文将两种方法做出的实验结果进行对比,可使得结果更加科学与准确.
1 原理
1.1 K均值聚类分析
K均值聚类分析的基本原理[2~3],是将数据中每个城市当成一个样品,样品需要各个要素,本文将各城市的空气质量指标作为样品要素,按照以下步骤[4]进行操作:
(1)由于采用K均值聚类分析,因此将样品分成K类,K所表示的是聚类的品类,这些都是可指定的,本文中的聚类种子可用每类的重心来表示,初始类中心不需要更改,均为自动设置;
(2)在组成全新类之前,需将样品与各类中心的距离进行计算;
(3)需要新的类中心,因此进行相应计算,即它们的均值;
(4)为了使各类中的样品不发生变化,我们需要重复步骤(2)、(3).
1.2 主成分分析
1.2.1 基本原理
主成分分析[5]是一种寻找较少主成分且能充分反映信息的真实性的方法.每种数据及每个原始变量间都是相互影响,只是影响程度不一,同时每个原始变量中所包含的意义也不尽相同,折射出不同的信息,所以在一个整体中的重要性也不同.通过“降维”将有影响力的主成分快速找到.
1.2.2 分析步骤
(1)首先在进行分析前,需要对数据进行标准化,其次建立R矩阵.由于原始数据的标准不一且单位不同,将会直接或间接的影响分析结果,需按照如下公式对原始变量数据进行标准化处理

其中,p表示p个变量数;Xi表示第i个变量.
(2)计算R的特征根λi以及相应的特征向量Ti;
(3)累计方差贡献率决定的是主成分的个数问题,其至关重要,方差贡献率公式如下

当累计方差贡献率的百分数较高时,我们才能准确的确认本次分析中有k个主成分,通过确定主成分,选择常用及准确的主成分表达公式,选取重要的影响因素.通常讲,当确定了特征值都是大于1的个数即确认了主成分的个数[6],本文将用这种方法进行相关计算.
(4)主成分表达式是解释主成分的含义,加权综合主成分表达式按照每个主成分对实际问题的各个样品进行排序及评价.

由于原始数据的量纲不同,在进行综合评价函数时不能直接使用,一般采用(4)式,或有的信息重叠,我们需要继续利用公式(5),通过主成分分析将不同量纲进行统一化,且用没有多大关系的综合变量代替最原始的指标.
2 实验分析
2.1 数据来源
数据来源于 2017《山西统计年鉴》[1],6 个影响空气质量的因素 (X1、X2、X3、X4、X5、X6):PM2.5 年平均浓度(μg/m3)、SO2年平均浓度(μg/m3)、NO2年平均浓度(μg/m3)、PM10年平均浓度(μg/m3) 、CO 日均值第95百分位浓度(μg/m3)、O3日最大8小时第90百分位浓度(μg/m3),全国进行空气质量评价时,也是选取这6个因素[7].表1中还有“空气质量达到好于二级的天数(天)”这一数据,实验过程将它作为综合因素(X7).
2.2 K均值聚类分析
本文需要对收集整理好的有关城市空气质量的数据进行聚类,运用K均值法可以将所有样品划分为5类:优、次优、良好、较差、最差.由于样品数量多且部分数据聚集,部分数据相差较大,会造成细分类不均衡的现象,实验结果显示,可先分成3大类:优、良、差,为了进行更细致的划分,需再观察各类别.
2.2.1 数据标准化
本文所查找的数据,除了本身误差外,在实验过程中,考虑到这些影响因素在单位上进行了统一的换算,其相对一致,但实验中由于观测时间段的不同,如:年平均、日均值、最大8小时等,没有统一标准,且考虑到实验中要求影响因素的标准含量也不尽相同,同样会造成或多或少的偏差.进行完聚类分析,得出的样品离类中心的距离不能直接与各因素类中心进行对比,且不能得出哪一类是较好的,因此,需要按照各个影响因素的不同要求,将原始数据标准化成比值进行比对.数据以国家颁布的二级标准(表1)[8]为参考值,我们处理后的数据不需要实验后与标准值进行对比,可直观观察.
本文需对数据进行标准化处理[3],如以下公式

其中,C'ik表示第i个城市第k个因素(标准化后);Cik表示第i个城市第k个因素(原始数据);C0k表示第k个因素的二级标准值.
从公式(6)可看出C'ik大于1时,该污染物超标.在进行标准化的过程中,对空气质量达到好于二级的天数这一影响因素也进行标准化,通常讲,以365天为一年,计算过程中,原始数据需除以一年的天数,计算出的结果越接近于1,则表明一年中该城市空气质量大部分均处于良好状态.限于篇幅,标准化后的数据略.

表1 各指标二级标准值Tab.1 Secondary standard values of each indicator
2.2.2 实验说明
以山西省11个地级市的空气质量数据为实验数据,采用K均值法进行聚类,根据实验结果将其分为优,良,差3类.
符号说明:
X1—细颗粒物(PM2.5)对比值
X2—二氧化硫(SO2)对比值
X3—二氧化氮(NO2)对比值
X4—可吸入颗粒物(PM10)对比值
X5—一氧化碳(CO)对比值
X6—臭氧(O3)对比值
X7—空气质量天数达到好于二级的对比值
2.2.3 实验结果
如图1所示,可以看出,各城市细颗粒物(PM2.5)、可吸入颗粒物(PM10)、二氧化硫(SO2)浓度远高于二级标准值,说明各城市这些污染物占据主要地位,发挥着不可忽视的作用.

图1 各指标与二级标准值对比Fig.1 Comparison of indicators and secondary standard values
详细分析数据见表2、表3、表4.

表2 11个地级市各类别及距类中心表Tab.2 11 prefecture-level cities and categories

表3 最终类中心表Tab.3 Final class center table
通过分析,整理数据得表3、表4,从中清晰看出,城市所属类别1中有晋城、晋中、运城、临汾4个城市,类别2中有大同、忻州、吕梁3个城市,类别3中有太原、阳泉、长治、朔州4个城市.从表3中看出,类别1中影响因素2和影响因素5偏高,类别2中影响因素全部较低,类别3中影响因素3和影响因素6较高.由这11个城市可看出山西绝大部分的城市空气污染物二氧化硫(SO2)、一氧化碳(CO)、二氧化氮(NO2)、臭氧(O3)偏高.
表3中显示,影响因素7是看一年中空气质量好的天数的比例,从而确定为什么,表中清晰显示优良差分别为类别2、类别1、类别3.

表4 聚类结果的案例个数Tab.4 Number of cases of clustering results
由于在实验中,对数据进行了标准化,因此显示出的即比值关系,可用来直接观察,看这些数据是否具有偏高的特点.同时在判断类别好坏时,将各因素值求和得平均值作为综合对比值来判断.综合值对比见表5.

表5 类比综合对比值Tab.5 Analogy comprehensive comparison value
由综合对比值判断:类别2为优,类别3为良,类别1为差.
2.3 主成分分析
主成分分析方法[9,10]是建立降维的一种方法,需保证信息量损失到最小的同时,找出问题的主要方面,达到对复杂的多变量数据进行最佳简化.主成分分析法主要对数据进行综合评价,将多个变量简化为综合性指标,从而对重点城市空气质量数据进行综合评价.
2.3.1 数据标准化
我们在处理数据的过程中,由于变量的无量纲化及变量不同其单位也不同,需对原始数据进行处理,如公式(1),在实验过程中,标准化后的协方差阵较为复杂,通常用原始数据的相关矩阵R来代替.由于城市空气质量数据的复杂性,不一致性等,造成各指标数据差别较大,本文中将原始数据的相关系数矩阵看作已经标准化的数据进行以下实验.
2.3.2 实验结果
利用SPSS软件,对相关数据进行主成分分析,结果见表6,结果选取2个主成分,累计方差贡献率为81.611%,表中处理过的数据保留了原本变量的信息.
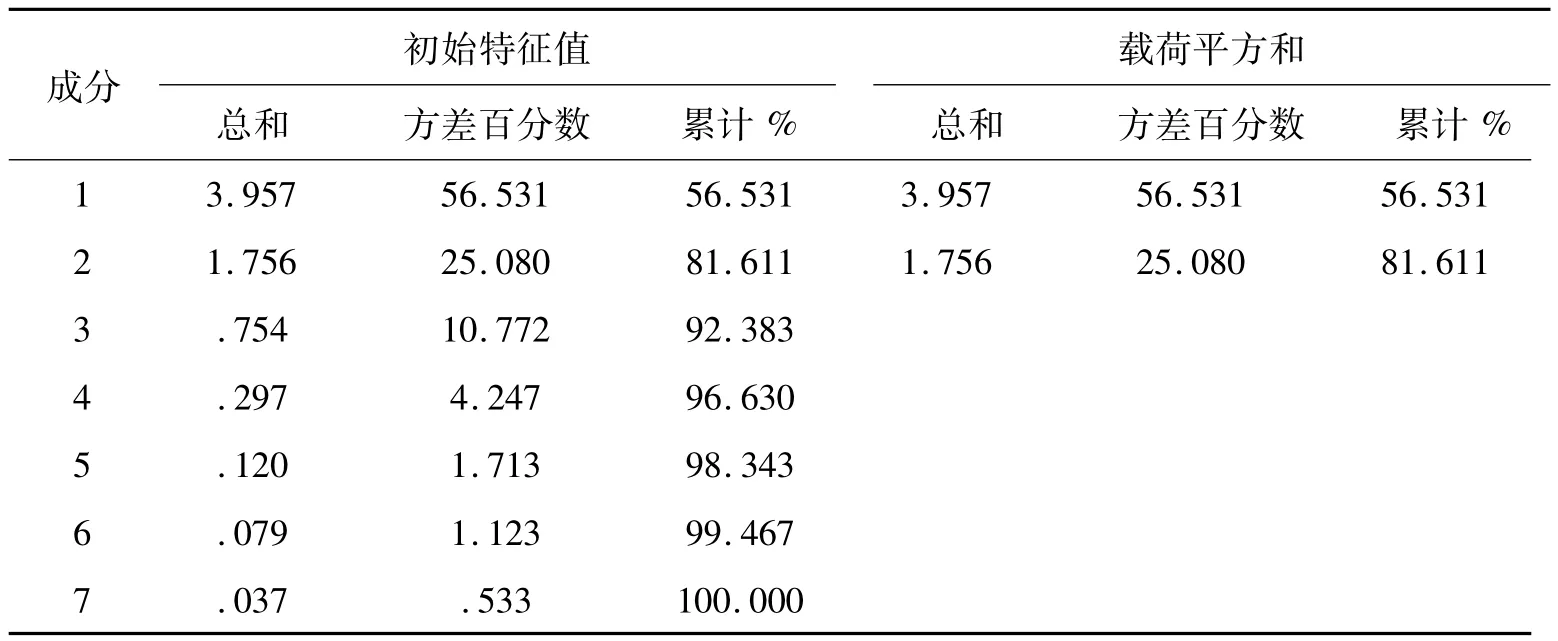
表6 方差初始特征值Tab.6 Initial variance eigenvalue
提取方法:主成分分析法.
根据表6中特征值,按照以下公式求第一、二特征向量[11]:

其中,zj表示第i特征向量;ai表示第i因子载荷阵;λi表示第i特征根.

表7 主成分矩阵Tab.7 Principal component matrix
选取方法:主成分分析法.
选取2个主成分.由式(4)得到第一、二主成分的表达式:

从表6中可清晰看出,主成分一起了最大的作用,其方差贡献率达56.531% ,原信息中的占比较大.其次看表7中的第一主成分的特征向量,影响因素X2、X5、X4与Y1之间呈正相关关系且影响较大,结果表明X2、X5、X4即二氧化硫(SO2)、一氧化碳(CO)、可吸入颗粒物(PM10)在整个空气质量中有较重的地位.
表中主成分2反映了原信息的25.080% ,其影响力与第一主成分相比较低,Y2与因素X3、X6、X2、X1即二氧化氮(NO2) 、臭氧(O3)、二氧化硫(SO2)、细颗粒物(PM2.5) 有较强正相关,说明 NO2、O3、SO2、PM2.5与空气质量的好坏有一定的关系.从表中得出,影响因素X7与Y2之间呈负相关关系,影响因素X7代表空气质量好的天数,其越大,说明该城市空气质量越好,第二主成分越低,说明空气质量会越好.
因此,影响空气质量好坏最主要的因素依次是二氧化硫(SO2)、一氧化碳(CO)、可吸入颗粒物(PM10)、二氧化氮(NO2)、臭氧(O3)、细颗粒物(PM2.5),煤燃烧、工业排放的废气、粉尘等对环境空气质量污染起到不可忽视的影响,在生活中,生产工厂排放的烟尘、机动车尾气等也产生着极大的影响,所以政府及社会应加大检测和治理工作,还人们一片蓝天.
3 实验结论与讨论
从聚类结果的类中心表,可以看出类别中二氧化硫(SO2)、一氧化碳(CO)超标严重,尤其是二氧化硫(SO2).同样从主成分分析的成分一中,可以看出二氧化硫、一氧化碳对影响空气质量起到不可忽视的作用.由此可见:本文中的两种分析方法得出的实验结果,从整体看高度一致,说明了在对山西11个地级市城市空气质量进行评价时,所选模型具有可行性.本文结合两种分析方法进行了综合性分析,方法的不同分析出的结果具有不同的特征,但结果却高度一致,使得结论更具有说服力.
随着人们生活质量的提高,对生存环境的要求也随之提高,在空气质量越来越差的都市,进行城市空气质量的评价是进行大气环境保护的基础,在日常生活中同样也发挥着至关重要的作用.所有的实验分析结果均是为了对空气质量环境作出更加客观、科学、准确的分析,从而找出对空气质量的影响较大的关键因素,积极制定相应措施,才能更加有效地防治空气污染.主要影响空气质量的几大因素,使得空气质量恶化,这说明空气污染源主要是:工业排放的废气,车辆尾气,化石燃料、煤、垃圾的燃烧等.大家应从自身做起,政府积极采取防治措施,众志成城减少各空气污染物的浓度,确保生存环境的安全,对于空气质量较差的城市尤其应引起注意,不然将导致无法想象的后果.
4 结论
本文结合了两种分析方法,对城市空气质量问题进行全面分析,借助SPSS软件,将2017年的山西省11个城市的空气质量进行分析,既将问题简单化又使得结果更科学.得出空气质量污染主要来自于二氧化硫(SO2)、一氧化碳(CO)的结论,可以为控制大气污染提供支持.
本文是以山西省11个地级市的空气质量为研究对象进行的相关分析,对于城市多的区域可以选择对其重点区域进行分析,为了研究方便也可将区域进行划分,对多个样品进行监测做实验,这样实验结果会更精准、科学、有效[7].本文在查找数据上存在些许缺陷,只整理了一年的数据对山西各城市空气质量进行分析,如果想要进行几年的对比及预测,需要考虑查找更多数据,寻找较多指标,建立更加复杂的对比及预测模型,运用更加优化的算法计算结果.本人能力有限,在城市空气质量问题上只进行了较为浅的分析,其结果只供参考.主成分能使问题简单化,并找出有效的影响因素来表达原始信息,而聚类是对样品进行快速分类,本文将两者相结合运用其中处理数据,是本文的一大优点.且在现实生活中,运用SPSS软件经常处理样品多、指标多的大数据,其应用分布广泛.
猜你喜欢
中国宝玉石(2019年5期)2019-11-16 09:10:20
环境保护与循环经济(2017年3期)2017-03-03 20:08:30
汽车与安全(2016年5期)2016-12-01 05:22:14
汽车与安全(2016年5期)2016-12-01 05:22:13
中国环境监察(2016年11期)2016-10-24 05:25:12
冰雪运动(2016年4期)2016-04-16 05:54:56
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
食品科学(2013年8期)2013-03-11 18:21:31
