
通道与空间注意力图像超分辨率网络
2021-01-22 06:00宋海川黄建设马利庄
计算机工程与应用 2021年2期
刘 璟,宋海川,黄建设,马利庄
华东师范大学 计算机科学与技术学院,上海200062
高分辨率图像具有高密集度的像素分布,图像的空间分辨率越高,能容纳的高频细节成分越多,越有利于后续的图像与视觉分析等任务。受限于实际硬件成像水平、网络传输流量、硬盘存储空间与压缩技术,无法获得或无法存储非常高分辨率的图像,因此必须通过超分辨率技术提高图像分辨率。这种提升可以是对原图的高分辨率重建,也可以是没有原图的单纯图像放大过程。超分辨率技术已被广泛应用于医学图像处理、卫星遥感影像、高清数字电视、视频监控等高新技术领域,与计算机视觉一些交叉领域,例如,语义分割领域DUC[1]模块,通过使用超分辨率领域的Sub-Pixel 方法[2],使其相比baseline方法提高了2%mIoU。
单图超分辨率算法的研究分为两个方向,其一目标为重建出更高感知质量的高分辨率图像,这类往往运用GAN(Generative Adversarial Networks)的技术,把已有超分辨率网络作为生成器的基础上,增加一个判别器,同时使用MSE 或L1 损失函数和VGG 等特征损失函数来重建逼真的超分辨率图像,后者具有比前者更真实的高频细节,但是与原图的一致性上不如前者。因此,在与原图更为接近、更为相似的研究方向上,复原高频细节成为了一大热点。
针对重建与原图更为接近的高分辨率图像的研究,起源于SRCNN[3](Super Resolution Convolutional Nerual Network),早期的超分辨率网络普遍采用bicubic 上采样算法将输入与输出的特征图的尺度size放大为一致,认为这有利于进行非线性映射,随之出现的VDSR[4](Very Deep convolutional network for single image Super Resolution)、DRRN[5](Deep Recursive Residual Network)与DRCN[6](Deeply Recursive Convolutional Network)网络便是该种架构。这种方式很快被证明徒增计算量,并且会产生新的噪音,并丢失原图信息。随之出现的FSRCNN[7](Fast Super Resolution Convolutional Nerual Network)与ESPCN[2](Efficient Sub-Pixel Convolutional Network)分别在网络末尾生成输出图片的特征图的卷积层前加上反卷积层与Sub-Pixel卷积进行上采样,在学界普遍证实了Sub-Pixel 卷积能避免反卷积层带来的棋盘格效应带来的指标下降后,之后出现的超分辨率网络大多采用Sub-Pixel卷积[2]进行上采样。
NTIRE2017[8](New Trends in Image Restoration and Enhancement)比赛在2017 年提出了一个新的训练集DIV2K[9],NTIRE2017 的 冠 军 模 型EDSR[10](Enhanced Deep Super Resolution)Lim等人表示,批量归一化层操作不利于超分辨率网络的训练,是占用更多显存并且减慢网络收敛的无效操作,该模型简单地在SRResNet[11]的基础上移除BN层后,获得了NTIRE2017的冠军。Guo等人在DWSR[12](Deep Wavelet Super Resolution)网络中设计了一个深度卷积神经网络模型来预测低分辨率图像与原图的4个小波域的残差细节,取得了较好的成绩。CVPR2018 中,Tai 等人在DBPN[13](Deep Back-Projection Network)中提出了一种迭代升降采样方式,使得网络可以同时学习在低分辨率与高分辨率下的特征映射方式。
针对高频细节不易复原的问题,提出了一个基于注意力机制的基本块,它由通道注意力和空间注意力两部分组成,分别对通道间的高低频信息与同一通道内不同空间位置的高低频信息分配不同的权重,从而使得高频与低频信息都能更好地被学习。进一步的,基于该注意力基本块,设计了基于注意力机制的单幅图像超分辨率网络,若干基本块结合短期特征体质模块组成一特征提取组,若干特征提取组与长期特征调制模块形成整个特征映射子网。低分辨率图像在经过前期特征提取、特征映射子网与上采样模块后,高分辨率图像得以重建,其中特征调制模块能够解决来自前期层的长期信息在后期层被减弱或丢失导致训练过程难以进行甚至不收敛的问题。实验结果表明,与SRCNN、FSRCNN、EDSR、DBPN、DWSR 等网络相比,本文方法具有更好的重建效果。
1 基于注意力机制的基本块设计
基本块作为单张图像超分辨率网络的主要非特征映射模块,是影响重建结果的重要因素。本章以EDSR[10]中的基本块作为基线进行多方面的改进。
基于注意力机制的基本块由两个3×3的卷积层,一个具有空间注意力机制的激活层和在层尾的通道注意力层组成。其中,两个3×3卷积层和一个激活层组成了常用的超分辨率任务基本块,这种基本块在EDSR中被证明为非常高效的特征映射块,并被后面的超分辨率网络广泛使用,结构如图1(a)所示。相对这种结构,做出如下优化:第一,将常用结构中的ReLU 激活层替换为本文设计的携带空间信息的注意力激活层。第二,对两个3×3卷积层中间的激活层使用宽激活配置,卷积层中间的通道数为输入与输出的4倍,改进后的激活层配置中广泛的宽度使得基本块的映射能力得到进一步的提升。第三,在基本块做残差前加入通道注意力层,使得不同通道间的权重分配更加均衡。

图1 (a)EDSR中基本块中的特征提取配置

图1 (b)本文改进基本块中的特征提取配置
1.1 宽激活层
传统的单图超分辨率深度学习网络中的基本块结构具有两个3×3 卷积层与一个ReLU 激活层,数据流的通道数配置为{x,x,x}(x 为基本块通道数,下同)。为了促使更多的低层次信息可以通过以达到尽可能将低层信息传递到后面的层,在Relu激活之前对通道数进行r 倍扩张,在广泛地对各通道信息进行激活后进行倍压缩,改变后的通道数配置为。这样配置后基本块的计算量与参数量保持不变。参照WDSR[14]的结论,实验中将r 设置为4 以得到最佳的配置,最终的通道数配置为,即基本块的输入通道数与输出通道数调整为原结构的一半,而中间激活通道数为原结构的两倍。
1.2 空间注意力激活层
不同的通道具有不同的重要性,例如,在具有复杂边缘和纹理特征的特征映射中,高频滤波器更重要。但是,同一通道中的不同区域,亦具有不同的重要性。例如,如果能够集中在高频区域的细节区域,同时抑制低频区域的权重,这将有助于高频滤波器学习更多的高频特征,最终图像的高频细节被更好地重建,反之亦然。受这些启发,提出了一种新的空间注意力激活层(Spatial Attention Activation Layer,SAAL)作为具有空间注意信息的激活层。输入信息先经过一个1×1 卷积层来融合跨通道的信息,接着通过ReLU 激活层与DepthWise卷积层,每个通道分别学习它们的空间权重,最后Sigmoid层将空间权重的动态范围映射到[0,1],逐像素点乘输入信息,进而得到携带空间信息的激活特征图。
空间注意力激活层分离了高频与低频信息至不同滤波器,使得它们分别具备不同的功能,同时专注学习高频与低频信息,使它们相比于原有激活层的学习,对高频与低频的预测都更好。会在实验部分具体分析这一点。空间注意力激活层可表示为:

其中,W 分别代表DepthWise 卷积层与1×1 卷积层,δ代表ReLU激活层,HSAAL代表空间注意力激活层。注意该激活层几乎不会带来更多的参数量与计算量,因为DepthWise 卷积层的计算是单通道对单通道的计算,而1×1卷积层的卷积核计算量仅为相同配置下的3×3卷积层的九分之一。
1.3 通道注意力层
通道注意力机制在单图超分辨率任务中有两点优势。一方面,基本块卷积层中的每个滤波器都使用本地的感受野,因此卷积后的输出不能利用本地区域之外的上下文信息,而通道注意的全局池化层包含了通道的全局的空间信息。另一方面,特征映射中的不同通道在提取低频或高频分量上起着不同的作用,引入信道注意层可以自适应地调节信道的权重从而有效地提高重建指标。在难以重建高频细节的超分辨率任务中,往往表现为有利于对提取高频成分的通道分配更高的权重,对冗余的低频成分提取通道分配更低的权重。
如图2 所示,借鉴SENet 中的扩张-挤压结构,将该结构作为本文的通道注意力层中的权重线性映射部分,并将整个通道注意力层放置在基本块的末尾。使用X=[X1,X2,…,Xc,…,XC] ∈RH×W×C来表示通道注意力层的输入,它由C 张大小为H×W 的特征图组成,后接一个全局池化层与全局方差层,其输出是通道的均值与方差统计信息:

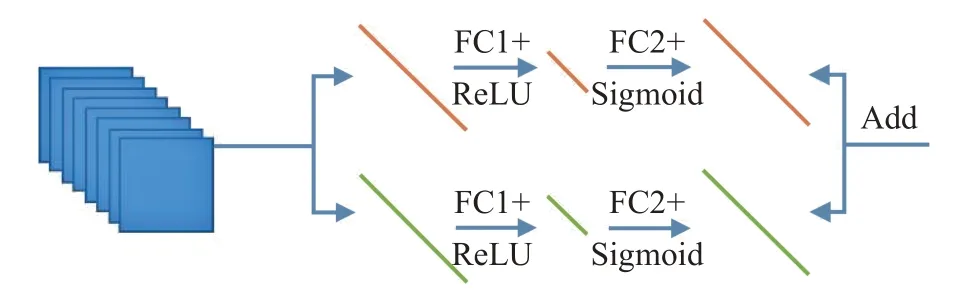
图2 通道注意力层网络流程图
将输入层的各通道的统计系数(这里选取均值mean 与标准差std)作为单像素、多通道的输入,分别经过挤压、激活与扩张结构,形成两组通道注意力系数:

其中,δ 代表ReLU 激活层,σ 代表Sigmoid 激活层,将注意力系数映射到[0,1]区间内。两支路的通道注意力加权求和(在这里,选取系数均为1)得到最终的通道注意力系数s。将通道注意力系数分别与输入进行点乘求和,形成带通道注意力机制的输出:

其中,HCA代表通道注意力层,s 和x 代表通道注意力系数与分配权重前的特征图输入。
如图3所示为整个基本块,它可以表示为:

其中,Fb、Fb-1分别为第b 个基本块的输入与输出,Bb代表第b 个基本块,HCA为该基本块的通道注意力层,δ 为该基本块的空间注意力激活层,Wb为第b 个基本块的卷积层。
2 网络架构设计
2.1 网络的总体结构
网络的总体结构如图4所示,它由如下几个模块组成:初始特征提取层、特征映射子网(Feature Mapping Sub-Net,FMS)、上采样模块,其中特征映射子网由堆叠的基本块连接组(Base Block Concat Group,BBCG)组成。
设ILR与ISR为输入的低分辨率(Low Resolution,LR)图像与对应的经过本文设计的CSAN(Channel and Spatial Attention Network)网络重建后的超分辨率图像。首先使用一个3×3 卷积层对输入图像进行浅层特征提取:

其中,f0(⋅)代表网络的头部卷积层。FSF接着被用作特征映射子网的输入,FSF先经过G 个基本块连接组与一个卷积层得到深层的特征残差图,然后与FSF进行全局的残差连接,得到网络的深层特征(Deep Feature,DF)FDF:
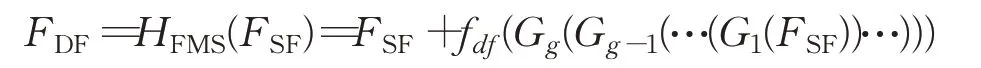
其中,Gg(⋅)代表第g 个基本块连接组,fdf(⋅)代表特征映射子网的尾卷积层,HFMS代表特征映射子网,它经过了2 阶段的基本块堆叠,拥有庞大的深度与感受野。第一个阶段由基本块连接组形成堆叠结构,第二个阶段为简单的全局残差连接。然后,网络的深层特征FDF被送进上采样模块得到最终的超分辨率重建图像ISR:

其中,HUP代表上采样层,HCSAN代表本文设计的网络的总体结构。
2.2 基本块连接组
形成较高的超分辨率网络图像重建性能,往往需要非常深的网络层数,但是简单地堆叠基本块或卷积层不能达到预期的效果。因此,设计了一种两阶段的基本块堆叠方式,基本块连接组方式代表了第一阶段的深度折叠,第二层的折叠为全局残差结构。经过两阶段的深度折叠,网络深度大幅缩减,不易收敛的深层基本块堆叠网络转化为容易收敛的浅层基本块连接组堆叠网络。
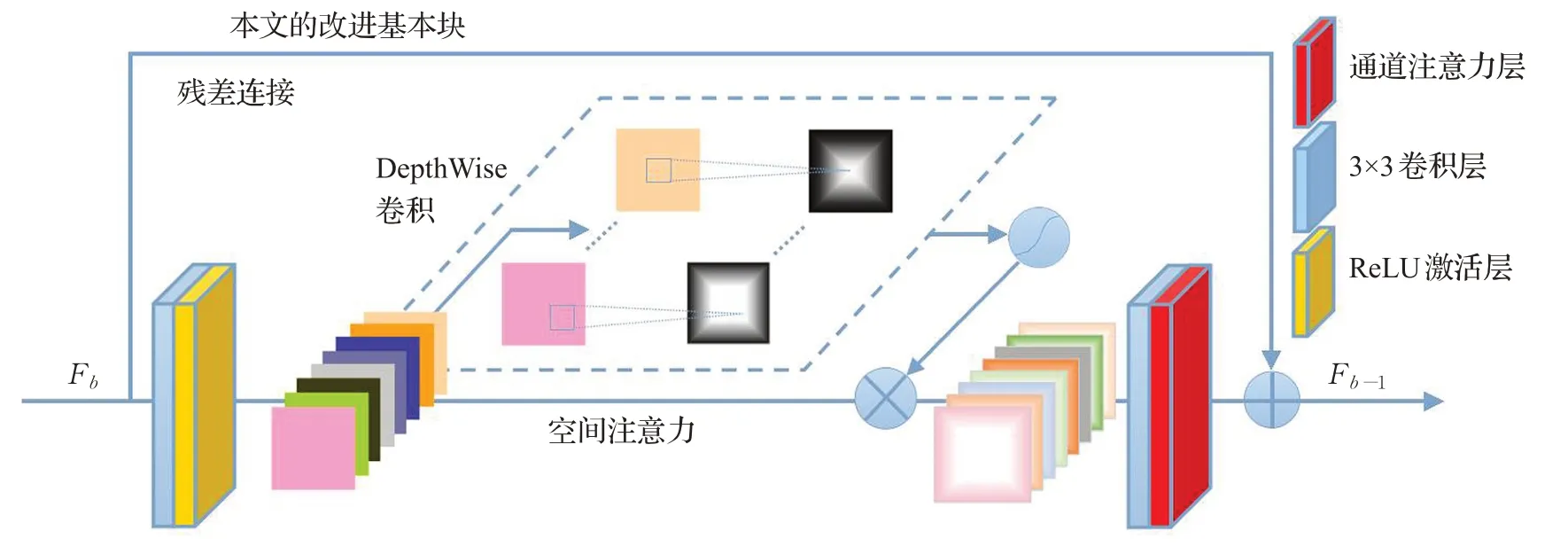
图3 本文的改进基本块网络流程图
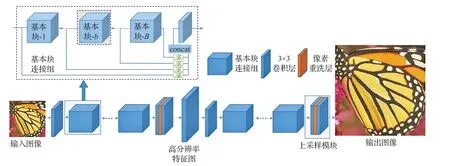
图4 基本块连接组,阶段式上采样与网络总体结构
如图4 左上角所示为基本块连接组的示意图。每个基本块的输出都被连接(concat),经过一个基本块连接组末尾的卷积层对各基本块的输出进行压缩得到有用的基本块连接组的输出。这样的设置使得所有基本块的输出都得以充分利用,从而缓解浅层信息被遗漏导致的深层网络难以收敛的问题。基本块连接组可以表示为:
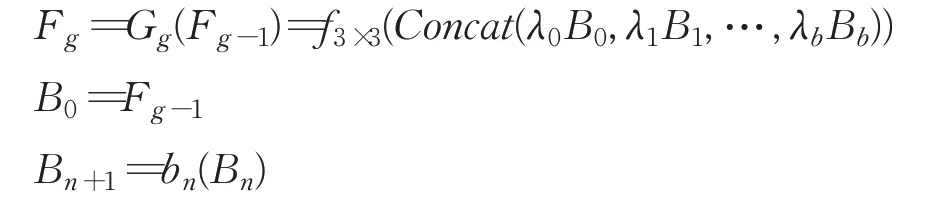
其中,Gg代表第g 个基本块连接组,Fg和Fg-1分别为基本块连接组的输入和输出,λb为第b 个基本块输出的权重,Bb为第b 个基本块的输出。
2.3 上采样模块
采用阶段式上采样(每次进行2 倍分辨率的上采样)代替一次性的上采样,这样的设置使得网络能在多尺度(不同2J尺度)上进行学习,而不仅仅是在最低尺度上进行学习。图4 中的网络为4×超分辨率(J=2)的示例,含有2 个上采样模块(右下角虚线框),其中上采样模块由2个3×3卷积核一个像素重洗(Pixel Shuffle)层组成,其中像素重洗层起到把空间维度压缩,扩张分辨率维度的作用。例如,在2 倍分辨率中,先用过第一个3×3卷积将通道扩充为原来的4倍,经过像素重洗层后,通道数还原,而分辨率为原来的2倍。
2.4 优化器与损失函数
使用Adam 作为优化器算法,分别在第150,第200与第250epoch 将学习率减半,初始学习率为1E-4 。将L1损失函数作为Adam优化器的优化目标:

3 实验与分析
3.1 实验配置
3.1.1 数据集
与EDSR[10]、SRMD[15]、RDN[16]等 网 络 一 致,使 用DIV2K[9]作为本文的训练与验证集。DIV2K包含800张训练图像,100张验证图像,100张测试图像(均为2K分辨率)与它们4个尺度(2倍、3倍、4倍、8倍)下对应的低分辨率图像。在此基础上,添加了选图范围更加丰富、张数更多的Flikr2k 数据集作为训练集组成DF2K 训练集作为本文的训练集进行训练。网络输入图像为48×48的分块,经过顺时针旋转0°、90°、180°、270°,左右翻转与上下翻转得到8倍于原数据的增强数据集,该增强策略同时也应用于测试阶段对结果进行融合从而进一步提升重建的准确度。
3.1.2 测试指标
经过融合输出的高分辨率重建结果与标签高分辨率图像在YCbCr 空间计算Y 通道的峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)和结构相似性(Structural Similarity,SSIM)作为衡量单图超分辨率算法的客观性能指标,从而更准确地表明本文算法相较其他算法的优越性。PSNR 反映两幅图像对应像素点间的误差,其值越高表明输出图像失真越少,图像重建质量越好。SSIM是表示两幅图像相似度的评价指标,其值越接近于1代表输出图像越接近于原始高分辨率图像,即重建效果越好。在本文的对照实验中,使用DIV2K 验证集的前十张在训练阶段每个epoch后进行测试。使用5个单图超分辨率通用benchmark 在2×尺度与4×尺度进行测试:Set5[17]、Set14[18]、B100、Urban100[19]和Manga109[20]。
3.1.3 模型细节
网络的基本通道数设置为64(对应的,在基本块内,为{32,128,32}配置,基本块外的卷积层通道数为32,而基本块中的DepthWise 卷积层通道数为128)。在对照实验中(2 倍尺度),使用每个基本块连接组10 个基本块,10 个基本块连接组,通道数64,也即10B-10G-64C的配置;在性能测试中,使用更大的网络配置,20G-10G-64C。
3.2 对照实验与模型分析
3.2.1 通道注意力机制的有效性
如表1所示,研究了本文的基本块的几种通道注意力变体,其中基线网络仅包含两个卷积层和普通的激活层ReLU,而没有融合通道注意力机制。作为对照,分别去除均值与标准差的分支进行实验。
从表1中前四列或后四列中均可看出,同时使用均值与标准差两个分支的统计信息作为通道注意力(3组、7组)的重建指标最高,而不含通道注意力机制的基线模型(Baseline)重建指标最差,在Set14的×2尺度超分辨率测试中落后于最优配置0.12 dB,在Urban100的×2尺度测试中落后0.08 dB,证明了本文的通道注意力机制的有效性。注意通道注意力机制并不会过多地引入额外参数。

表1 通道注意力层与基本块连接组对照实验数据
3.2.2 空间注意力机制的有效性
本文的空间注意力激活层允许投入很少的额外参数以获得性能上的提升。在性能越弱的网络中,这种提升越明显,但投入参数的占比越高。空间注意力激活层中DepthWise卷积层的卷积核大小设置不同,会影响投入参数的占比与网络最后的性能,是一个性能与参数的折中。使用基本配置的CSAN模型,通过不同大小卷积核的配置进行对照实验,实验结果如表2。表2 是有关是否使用空间注意力激活层(SAAL)与其中DepthWise卷积核大小对于结果的影响的对照实验配置表与实验数据。MAdds 与显存占用为3×16×16 作为输入时的测试数据,PSNR 为DIV2K801~810 验证集重建结果的平均值,网络为基线配置。实验结果表明,SA 层的引入,从卷积核大小为5×5开始具有提升,并且卷积核大小越大提升越大,引入SA层会带来约1.66倍的显存占用。

表2 空间注意力激活层对照实验数据
进一步观察了通道注意力激活层对特征图带来的变化来分析通道注意力激活层的本质。如图5 所示为Set5-2x中的一组示例高频滤波器特征图。其中左图为原图,中图为空间注意力激活层前的特征图,右图为经过空间注意力激活层激活后的特征图。可视化图将特征图的值sigmoid激活后线性放缩至-175至175范围,进行蓝绿色调的colormap映射。

图5 空间注意力激活层特征图可视化
可以清楚地从图5 右图中观察到本文的空间注意力激活层能杀死高频滤波器中的低频部分(绿色部分代表该区域被分配接近0 的权重),从而更好地提取高频特征,从而证明了本文的空间注意力激活层的有效性。
3.2.3 基本块连接组的有效性
基本块连接组能够折叠网络的基本块深度,从而使得网络不会随着深度的增加而难以收敛,网络更好地收敛为网络带来更高的重建精度。由于宽激活层的配置,基本块外的卷积不会带来太多额外的参数量。在基线配置下使用DIV2K 验证集801~810 对PSNR 指标进行测试,对是否使用基本块连接组、是否对各输入的weight进行放缩进行验证。如图6 所示,最终图4 中的配置取得了最好的成绩。图1 中相同通道注意力配置下是否使用基本块连接组的对照实验也证明了基本块连接组的有效性。
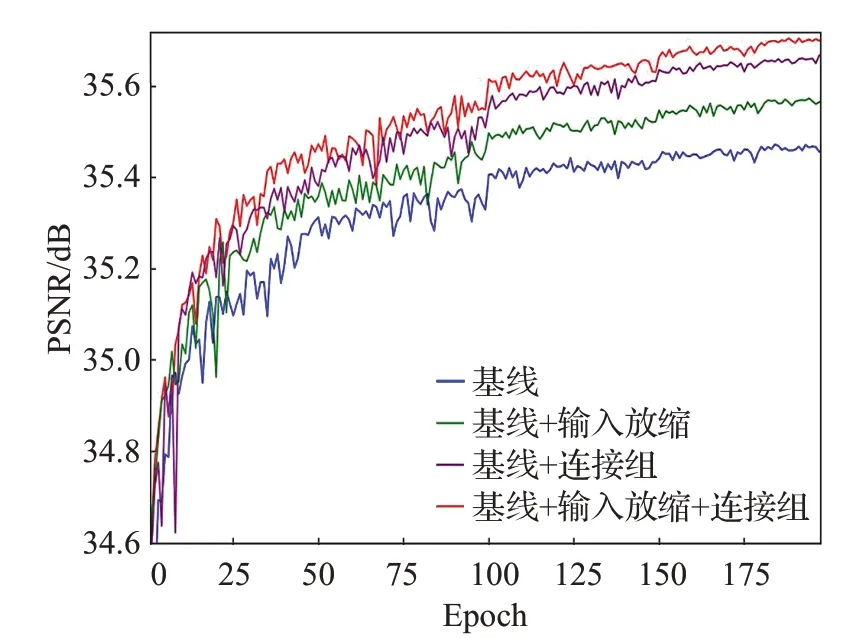
图6 基本块连接组对照实验的PSNR-Epoch曲线图
3.3 与已有算法的对比
为了证明本文方法的先进性与有效性,选取了单张图像超分辨率领域先进的8 种方法深度学习方法,
SRCNN[3]、VDSR[4]、DRCN[6]、LapSRN[21]、MemNet[22]、EDSR[10]、SRMDNF[15]、D-DBPN[13],与传统的Bicubic 算法,在2 倍与4 倍尺度分别进行对比,结果如表3。从表中可以看出,无论是在2 倍还是4 倍尺度下,在不同测试集下,本文算法对于重建图像的PSNR 与SSIM 指标均处于领先,其中PSNR在5个不同的测试集上平均领先D-DBPN约0.4 dB。
同样对不同先进算法的主观视觉效果进行了对比评价,图像来自测试集Urban100,结果如图7所示。图7(a)中,由于降采样使得高频信号缺失导致窗沿的平行线发生了严重的混淆现象,FSRCNN 没有解决混淆现象,其他的算法均预测了错误的方向,只有本文算法成功重建了原图的窗沿平行线方向。图7(b)中的混淆现象体现在栏杆上,同样只有本文算法由于最准确地还原了栏杆的方向而得到了精度最高的重建结果。因此,定量数据与定性视觉效果,均表明低分辨率图像通过本文算法得到的重建效果整体优于所对比的重建算法。
4 结论
本文提出了一种基于通道注意力机制与空间注意力机制的单幅图像超分辨率网络。网络使用阶段式上采样进行分辨率的提升,使得网络可以学习不同的2倍尺度上的非线性特征映射;使用基本块连接组对网络的深度进行折叠,使得非常深的超分辨率网络可以更快更好地收敛;使用包含通道注意力层与空间注意力激活层的改进基本块作为网络的基本特征映射单位,对照实验证明了提出的通道注意力机制和空间注意力机制的有效性;大量实验表明本文方法不论从客观定量指标,还是主观视觉上,均优于目前的先进方法。
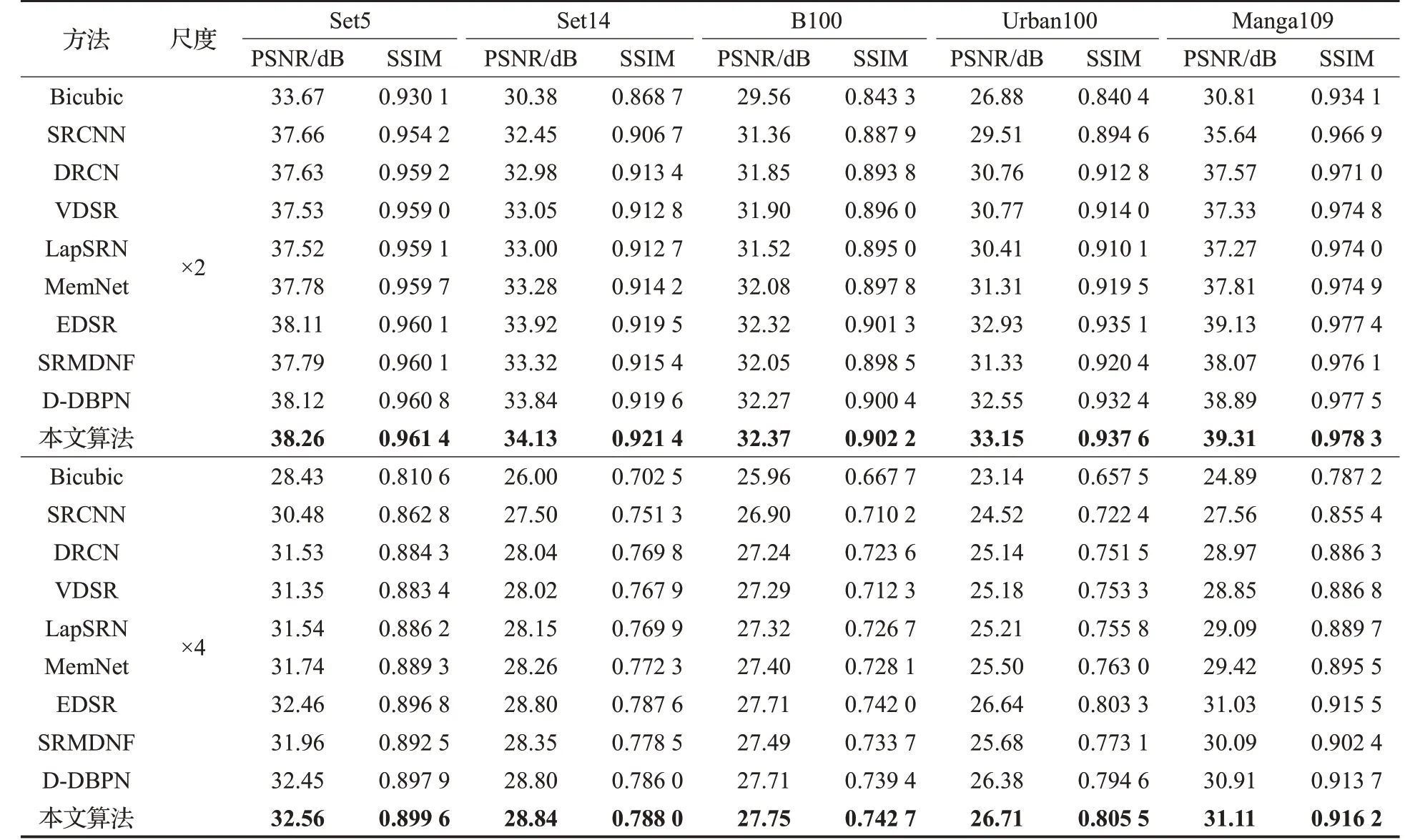
表3 与先进单张图像超分辨率领域已有算法的指标对比

图7 (b)“Img100”-2×与不同先进算法的视觉效果对比
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
数学物理学报(2019年3期)2019-07-23
电子制作(2019年11期)2019-07-04
家庭影院技术(2018年9期)2018-11-02
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
自动化学报(2017年5期)2017-05-14
成都信息工程大学学报(2017年6期)2017-03-16
第二课堂(课外活动版)(2016年2期)2016-10-21
