
基于改进对数梅尔谱特征的街道环境声事件检测方法
2021-01-22 02:29张留军罗丽燕
桂林电子科技大学学报 2020年5期
张留军, 王 玫,2, 罗丽燕
(1.桂林电子科技大学 认知无线电与信息处理教育部重点实验室,广西 桂林 541004;2.桂林理工大学 信息科学与工程学院,广西 桂林 541006)
随着城市的发展,城市中机动车的保有量日益增加,由此引起的城市交通堵塞和汽车鸣笛声污染等问题给人们的工作和生活造成了极大困扰。目前,我国已初步建成以视频处理为主要技术手段的交通监控系统,可为交通状况预警和车辆调度提供有力支持,但无法对车辆鸣笛等声污染进行有效监控。因此,街道环境声事件检测作为声污染监控的重要组成部分,对城市噪声污染的管控具有极其重要的现实意义。
环境声事件识别是指对采集的环境声数据进行分析进而识别出所包含的声学事件,目前常采用机器学习方法解决环境声事件识别问题。在该领域中,数据、特征和分类算法决定了机器学习的性能,因此,这三部分也是影响环境声事件识别性能的关键因素。在早期的环境声事件识别的研究中,由于识别任务较为简单,加之计算机算力的不足,常采用传统的机器学习算法作为分类器,例如K近邻(K-nearest neighbor,简称KNN)算法[1]、支持向量机(support vector machines,简称SVMs)[2-3]和随机森林(random forest,简称RF)算法[4]等,但近年来随着环境声事件识别投入实际场景应用的需求增加,环境声事件识别所面临的背景噪声更加复杂多变,上述分类器由于对复杂信号的建模能力有限,因而无法满足环境声事件识别的要求。为解决这些问题,基于深度学习的环境声事件识别方法受到广泛关注,例如目前主流的环境声事件识别方法常使用卷积神经网络(convolutional neural networks,简称CNN)作为分类器,对数梅尔谱(log-Mel spectrogram,简称log-Mel)作为声学特征[5-8],但仅通过不同的卷积策略和不同的激活函数提升了分类算法的性能,并未解决对数梅尔谱抗噪性能差的问题,不适用于实际场景应用。其次,目前针对街道环境声事件识别研究的数据集较为稀缺,只有3个常用的公开环境声数据集:MIVIA[9]、Urbansound8K[10]和Google Audioset[11]。MIVIA数据集包含枪声、玻璃破碎声和尖叫声3种声音类型,主要用来研究异常声事件的识别;Urbansound8K数据集主要包含城镇环境声,共8 000余条声音样本包含10种声音类别,但是该数据集中有关街道环境声的数据量较少;Google Audioset数据集是谷歌开放的大规模数据集,其中632个声音类别均来源于Youtube视频,但是存在声音来源不确定和弱标签数据的问题,并不适合于街道环境声的研究。因而,建立一套真实的街道环境声数据集十分必要。针对上述问题,提出了一种改进的对数梅尔谱特征结合卷积神经网络的环境声事件识别方法,提高了环境声事件识别方法的抗噪性能。
1 街道环境声事件检测系统
系统旨在通过识别滑动检测窗口中的声音事件,从而达到检测整个声音片段所包含的声学事件的目的。街道环境声事件检测系统如图1所示。系统包括4个部分:滑动检测窗口切分,声学特征提取,分类算法识别,检测结果输出。根据声音片段的时长,该系统不仅可用于不同时长声音片段的环境声事件检索,还可用于实时的环境声事件检测。

图1 街道环境声事件检测系统
1.1 滑动检测窗口
由于街道环境声的复杂和多变性,导致常规的端点检测技术效果极差。系统直接将声音片段切分为一系列重叠的滑动检测窗口。滑动窗口检测方法不仅可检测不同时间点发生的声音事件,而且避免了端点检测失效造成的声学事件漏检问题。图1中,最上面深灰色长条表示一段声音片段,声音片段下面的一系列的短条表示有重叠的检测窗口,设置检测窗口的长度为0.67 s,滑动步长为0.25 s。
1.2 声学特征提取
声学特征提取是声学事件检测中至关重要的步骤,提取有辨识度和抗噪声性能强的声学特征,可极大提高声学事件检测的性能。为了分析街道环境声信号的特性,选择更有辨识度的声学特征。选择的4种典型的街道环境声信号的时频谱图如图2所示。图2(a)为街道背景噪声的时频谱图,街道背景噪声包括行人行走的声音、车辆过往的声音以及其他背景噪声。从图2(a)可看出,该类声音类似于白噪声,能量均匀分布于低频部分。图2(b)为汽车鸣笛声的时频谱,这种声音的能量分布以一定频率间隔出现,在时频谱图上表现为一系列直条纹,该类声音的频谱特点明显、辨识度较高。图2(c)为尖锐的汽车刹车声的时频谱,尖锐的刹车声使得一些频率的能量较高,在时频谱图中成条纹状。图2(d)为讲话声的时频谱,频谱分布于8 kHz之下的低频部分,谐波信息较为丰富。通过分析4种典型的街道环境声时频谱图可以发现,这4种环境声信号在时频谱图上具有明显的区别,其中汽车鸣笛声的频谱图具有较高的辨识度。因此,采用时频域特征-对数梅尔谱作为声学特征,对数梅尔谱特征是线性时频谱经过梅尔滤波器过滤后得到的特征,符合人耳的听觉特性,被广泛用于声学事件识别方法[9,12-13]。但该特征对噪声的鲁棒性差,通过对该特征从时间维度提取一阶差分系数和二阶差分系数作为动态补充特征,并与原特征组成类似图像的三维特征,这为该特征增加了2种动态维度的信息,大大提高了该特征的抗噪性能。log-Mel特征图提取流程如图3所示。
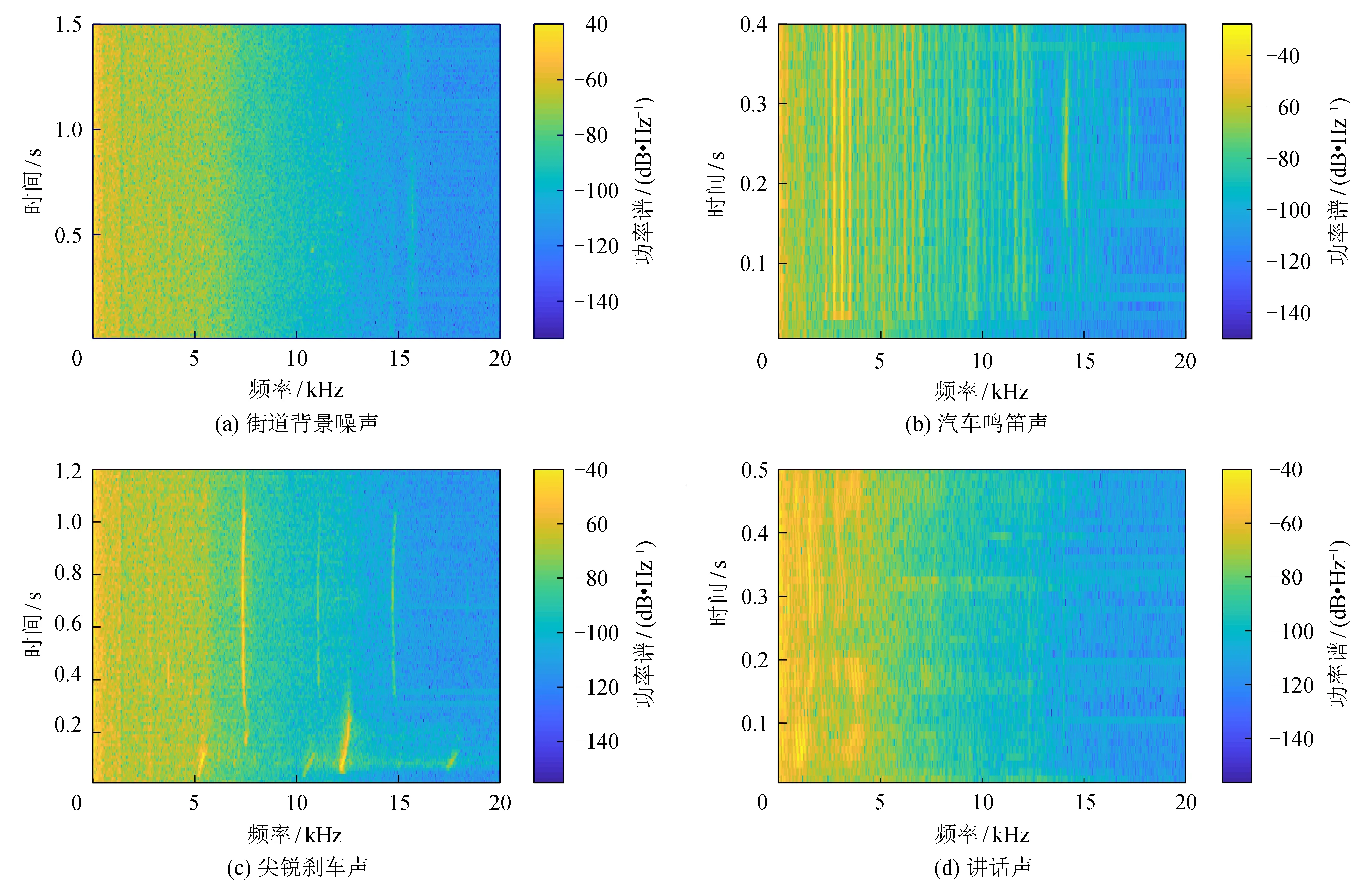
图2 4种街道环境声信号的时频谱图

图3 log-Mel特征图提取流程
改进的对数梅尔谱特征提取流程如下:
1)分帧加窗。对声音片段分帧,帧长为1 024个采样点,帧移为512个采样点,并对每帧声音信号加汉明窗,以防止频谱泄漏和边界信息丢失。窗函数为
(1)
2)快速傅里叶变换。对每帧声音信号进行快速傅里叶变换(fast Fourier transform,简称FFT),并对复数谱取模后平方求得功率谱。离散傅里叶变换(discrete Fourier transform,简称DFT)的计算式为
(2)
3)梅尔滤波器。使用与人耳听觉特性相适应的梅尔滤波器对求得的功率谱进行滤波,得到梅尔频谱。设置梅尔滤波器数量为40,梅尔滤波器组为
H(k)=
(3)
(4)
功率谱经过梅尔滤波器变换为
(5)
4)取对数。每帧的梅尔频谱取对数得到对数梅尔谱,计算式为
Xlog-Mel=lns(m), 0≤m≤M。
(6)
5)提取一阶差分和二阶差分。对数梅尔谱提取一阶差分系数和二阶差分系数,提取的一阶差分系数和二阶差分系数与原特征组成三维特征。差分系数计算式为
(7)
1.3 卷积神经网络
卷积神经网络具有强大的学习表征能力,能够从输入数据中提取更高阶特征,而且其局部连接和权值共享特性,使得该网络适合处理图像等高维数据,因此,该网络广泛应用于图像识别、语音识别和环境声事件识别等相关领域。针对实际街道环境中噪声复杂多变的问题,采用添加正则化和批标准化等提升模型泛化能力的技术,设计了抗噪性能好的卷积神经网络。
1.3.1 卷积神经网络结构特点
借鉴经典的卷积神经网络结构[14-15],设计了如图4所示的卷积神经网络结构。该网络将改进log-Mel特征作为输入,即Xlog-Mel∈R40×80×3,2个卷积层和2个最大池化层用于深层特征提取,全连接层用于深层特征整合和函数建模,输出层得到分类结果。

图4 卷积神经网络结构图
给定一组输入Xlog-Mel,卷积神经网络训练得到一组参数θ,并得到一组输出,
Z=F(Xlog-Mel|θ)=fL(…f2(f1(X|θ1)|θ2)|θL),
(8)
其中fL(·|θL),1≤L≤6为每层网络的输出映射,设计的卷积神经网络共6层,即L=6,其中卷积层的操作为
Zl=fl(Xl|θl)=h(W*Xl+b),
θl=[W,b],
(9)
其中:Xl为输入的三维张量;W为三维卷积核;h(·)为激活函数;b为偏置矢量。在每层卷积层后接一个最大池化层,以减小特征映射维度,提高特征鲁棒性和提升训练速度;随后一层为全连接层,这层网络不做卷积,而进行矩阵相乘;最后将该层输出,以全连接的方式连接到输出层得到分类结果。
1.3.2 模型参数设置
设计的卷积神经网络的参数设置如下:
1)卷积层1和卷积层2。2层卷积层均使用40个3×3的卷积核,卷积核的滑动步长为2,用于提取log-Mel特征图的局部深层特征。2层卷积层的输出数据分别为(20,40,120)和(5,10,4 800),激活函数采用修正线性单元(rectified linear unit,简称ReLU)[16],其函数表达式为
f(x)=max(0,x)。
(10)
此外,为了提高卷积神经网络训练的速度和稳定性,在每个卷积核和激活函数之间引入批标准化技术[17],进而提高了网络的泛化能力。
2)池化层1和池化层2。2层池化层均采用2×2的最大池化滤波器下采样上层输出,滑动步长为2,以达到减小特征映射维度、提高特征鲁棒性和提升训练速度的目的。2层池化层输出数据分别为(10,20,120)和(3,5,4 800)。
3)全连接层。全连接层包含256个神经元,激活函数同样使用ReLU。
为了减小模型过拟合程度和提高模型的泛化能力,对卷积层和全连接层的参数使用L2范数惩罚[18],即通过向目标函数添加一个正则项,
(11)
其中:w为所有范数惩罚影响的权重;θ为所有参数(包括W和无需正则化的参数)。在训练过程中使用Adam[19]进行反向传播,Adam是一种学习率自适应的优化算法,它采用偏置修正,修正原点初始化的一阶矩(动量项)和二阶矩(非中心)的估计,使得其对超参数的选择更鲁棒[20]。
2 实验与分析
实验由2个部分组成。1)使用公开和自建的环境声数据集评估本方法,并与常规方法进行对比;2)基于不同识别方法的环境声事件检测系统在实际场景下对汽车鸣笛声的检测实验。实验均在Windows平台下完成,硬件设备使用酷睿I7 6800 K处理器,GTX1080TI显卡,特征提取、分类算法的建模借助Python语言的librosa、sklearn和TensorFlow等模块完成。
2.1 基于环境声数据集的对比实验
2.1.1 环境声数据集
本实验使用2个环境声数据集。数据集1为公开的环境声数据集Google AudioSet[3],从中选取枪声、尖叫声和汽车鸣笛声3种声学事件,每种类别的样本数量为900余条,按7∶3划分为训练集和测试集,均采用44.1 kHz采样频率和16 bit的PCM编码格式。数据集2为自行采集的街道环境声数据集,同样按7∶3将其划分为训练集和测试集。
2.1.2 评价指标
采用如下评估指标[20]来评估分类算法的性能:
查全率
(12)
查准率
(13)
置信度
(14)
其中:nTP为样本正确判断为正类(少数类)的样本数;nTN为样本正确判断为负类(多数类)的样本数;nFP为样本错误判断为负类的实际正类样本数;nFN样本错误判断为正类的实际负类样本数。
2.1.3 实验结果与分析
使用Google AudioSet数据集和自建的街道环境声数据集,不同分类算法的评估结果如表1、2所示。从表1、2可看出:使用相同的声学特征log-Mel,本方法相比KNN、SVMs、RF和文献[13]的CNN方法在查全率、查准率和置信度3个指标上均有不同程度的提升,验证了本方法设计的卷积神经网络具有更优的分类性能。
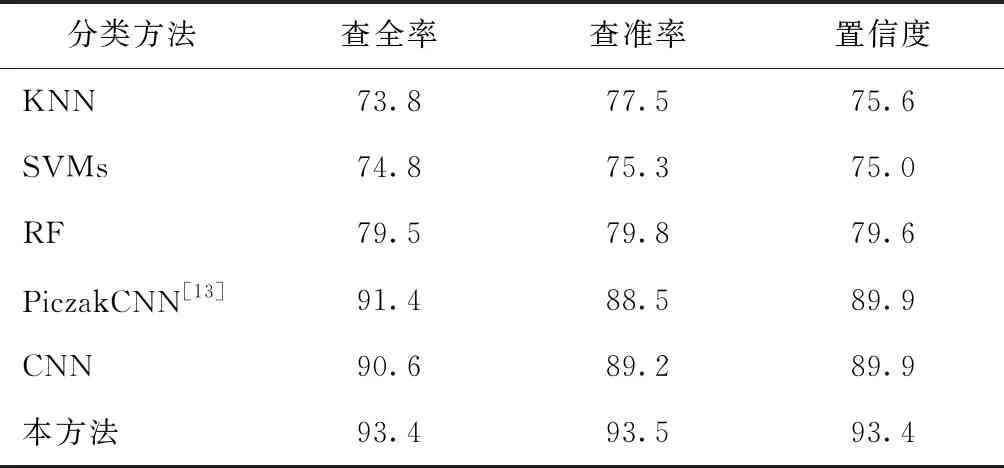
表1 Google Audioset数据集不同算法的评估结果 %
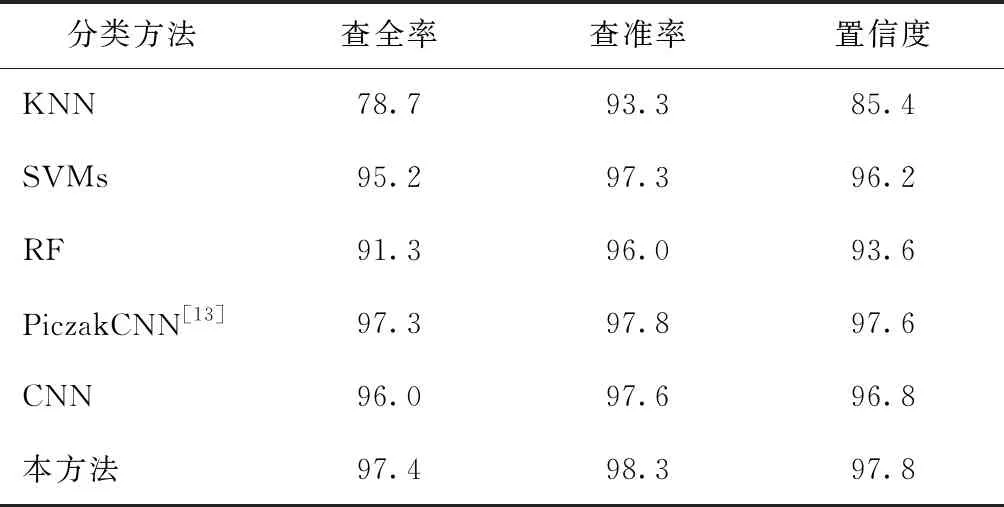
表2 街道环境声数据集不同算法的评估结果 %
2.2 实际场景下汽车鸣笛声检测实验
使用自建的街道环境声数据集,并利用本检测系统对一段未训练的时长为10 min的街道环境声数据进行汽车鸣笛声检测。
2.2.1 街道环境声数据采集
在桂林电子科技大学金鸡岭校区正门前放置环境声采集设备,采集真实的街道环境声数据,环境声采集设备及采集场景如图5所示。该环境声采集设备由安卓开发板、拾音器和防水盒3个部分组成。安卓开发板采用全志A33处理器,1 GiB运行内存;拾音器为无源拾音器,其拾音的频率为20~20 kHz;防水盒为普通网络设备防水盒。使用上述设备产生44.1 kHz、16 bit的PCM信号来记录街道环境声数据,然后人工标注并剪辑音频中的汽车鸣笛声。共采集了3 114条汽车鸣笛声样本,每条汽车鸣笛声样本时长为0.5~1.5 s。
2.2.2 实验结果与分析
本实验使用街道环境声数据集来训练所设计的卷积神经网络。图6为卷积神经网络在训练过程中损失值和分类准确率的变化曲线。从图7可看出,随着训练批次的增加,训练集和测试集的损失值不断下降,测试集和训练集的准确率曲线都在上升且二者非常接近,说明本方法泛化能力较好,准确率达到了97%以上。因此,卷积神经网络在训练过程中得到很好的收敛,且不会产生过拟合。

图5 声音采集设备及采集场景
本方法测试卷积神经网络得到ROC(receiver oprating characteristic)曲线如图7所示。从7图可看出,本方法的AUC(area under curve)面积接近1,因此,本方法的分类性能优异。
使用不同的识别方法的环境声事件检测系统对一段时长为10 min的街道环境声数据检测结果如表3所示。从表3可看出,本方法的检测性能优于其他方法,具有较强的抗噪能力。综上实验结果,本方法在训练数据集有限的情况下仍具有较好的检测表现(查全率为94%,查准率为87%,置信度为90.5%)。

图6 损失值和准确率变化曲线

图7 本方法汽车鸣笛声识别的ROC曲线

表3 汽车鸣笛声检测结果
3 结束语
针对现有的环境声事件识别方法噪声鲁棒性差及街道环境声数据少的问题,提出一种基于改进的对数梅尔谱特征的环境声事件识别方法,并使用自主设计的环境声采集设备收集了大量的街道环境声数据用于对街道环境声的检测。街道环境声事件识别系统在实际场景中取得了良好的检测性能,从而验证了该系统在实际场景下应用的可行性。
猜你喜欢
空间科学学报(2021年6期)2021-03-09
智慧少年·故事叮当(2021年1期)2021-01-16
源流(2020年4期)2020-07-14
小学生必读(低年级版)(2017年4期)2017-09-04
人民音乐(2016年3期)2016-11-07
琴童(2016年7期)2016-05-14
空间控制技术与应用(2015年2期)2015-06-05
小猕猴学习画刊(2015年4期)2015-05-05
中国设备工程(2014年2期)2014-02-28
作家(2008年7期)2008-10-27
