
基于CUDA架构的LBM共享内存计算优化
2021-01-22 07:51李华兵赫轶男张乾毅韦华建韦国柱
桂林电子科技大学学报 2020年4期
李华兵, 赫轶男, 张乾毅, 韦华建, 韦国柱
(桂林电子科技大学 材料科学与工程学院,广西 桂林 541004)
近年来,在物理学领域中晶格玻尔兹曼法作为一种流体力学常用方法,越来越受到国内外学者的青睐。传统基于CPU上的线性运算的运算速度问题也逐渐暴露出来,作为发明GPU的领头公司NVIDIA亦认识到这一问题,其在2007年便推出了基于GPU上的并行计算架构(CUDA),于是便开启了CUDA渲染时代。
在物理学中,晶格玻尔兹曼方法在计算流体动力学方面的模拟是一个非常好的工具。迄今为止,LBM已成功地应用于多种复杂流体系统,如多孔介质流[1]、多相流[2]、反应扩散流[3]、血液流[4]等。将计算流体动力学与GPU数值模拟相结合亦取得了众多成果,如Tolke等[5]利用CUDA的并行优势实现了LBM中的D3Q15模型,张云等[6]实现了多松弛模型的计算加速。这2种方法虽都将CUDA应用在LBM上,但由于LBM规则格子模型处理难度较大,无法充分展示CUDA架构的加速效果。鉴于此,以D2Q9模型为例,通过改善内存访问以及数据传输的方法,进一步提高LBM的计算速度。
1 GPU与CUDA
1.1 GPU与CPU的区别
GPU与CPU二者之间虽不同,但也存在联系。2种器件的相同点是它们都是处理单元;不同点是CPU是“核心的”,而GPU主要用于“图像”处理。二者具有不同的架构,GPU采用了数量众多的计算单元和超长的流水线,但只有非常简单的控制逻辑,并省去了储存单元,而CPU不仅被储存单元占据了大量空间,且还有复杂的控制逻辑和诸多优化电路。虽然在逻辑控制与线性运算方面较好,但相比之下,GPU更擅长大规模的并行计算。
在最初的设计上,由于CPU仅具备单个DRAM内存块,其线程之间切换极为麻烦,仅能做到线性切换,而GPU具有多个存储器控制单元,进而多个线程之间可实现相互的快速转换。因此,相比于任务并发型优化的CPU,GPU更擅长数据的并发型优化。本计算采用Inter(R) Xeon(R) CPU E5-2620 v4,该CPU作为专业的服务器核心,含有8个内核数,16个线程,主频为2.1 GHz。它可通过多种散热管理功能保护处理器包和系统,以免出现过热故障。带有扩展页表(EPT)的VT-x,也称为二级地址转换(SLAT),可为需要大量内存的虚拟化应用提供加速。至强E5-2620 v4 2.1 GHz 处理器集多种功能于一身,可满足几乎所有数据处理量大的基础架构应用程序的需求。而采用的专业级显卡型号为Nvidia Quadro GP100,该显卡具有较高的性价比,拥有16 GiB的显存内存及3 584个CUDA核心。一个专业级显卡所具备的CUDA核心直接反映了计算速度的快慢。由于要应用于LBM计算上,需达到双精度浮点计算,该型号专业级显卡用作LBM运算为较优选择。
GPU的作用已经不仅局限于图形处理与图像识别。经实验证明,在高精度的浮点运算与并行计算领域上,相比于CPU,GPU甚至可以提供数十倍乃至于上百倍速度比。
1.2 CUDA并行计算架构
在GPU数值计算领域,通用计算软件体系主要有OpenMP、CUDA、MPI。本研究采用的是CUDA,其是由NVIDIA公司所推出的并行运算开发平台,且随着时间的推演CUDA从起初仅可使用C语言进行程序编译,发展到现在的CUDA 3.0可支持C++以及FORTRAN,展示了其所具有的高兼容性。关于GPU并行运算加速LBM的计算在国内外有很多例子,如Li等[7]将LBM 演化过程映射为对2D纹理单元的光栅化和帧缓存的处理,并采用Nvidia GeForce4 Ti4600显卡,首次实现了在GPU上加速LBM计算,较传统的CPU获得了15.3的加速比。随后Fan等[8]采用相似编程方法将LBM运行在32个GPU节点的GPU集群,与CPU集群相比,获得了21.4的加速比。
并行计算是指同时使用多种计算资源解决计算问题的过程,是提高计算机系统计算速度和处理能力的一种有效手段。并行计算具有分明的并行层次,首先是作为底层的单核指令级并行,即在单个处理器能让多条指令命令同时并行执行;在这之上的是多核并行,由单个芯片构成,其允许多个处理器核心上的多线程之间相互并行;其次是多处理器并行,多个处理器之间通过集成安装的方式,使线程与进程之间到达并行;最顶为集群或分布式并行,作为一个独立的并行计算平台,亦可称为节点,各个节点之间为达到数据之间的共享,借助网络传输的方式最终达到集群或分布式的并行。
2 晶格玻尔兹曼法
用单粒子分布函数fi代替布尔变量,则LBM演化方程为
fi(x+ei,t+1)-fi(x,t)=Ω(fi),
(1)
其中:fi(x,t)是在x位置t时刻具有ei速度的粒子的分布函数;Ω(fi)为碰撞因子,表示碰撞对于fi的影响。
之后引入单弛豫时间近似代替碰撞因子项[9],碰撞项被简化为
(2)
其中τ为弛豫时间。因此单驰豫LBM方程可写为
(3)
平衡分布函数是将LBM应用在不同问题中的关键要素,只要提供一个合适的平衡分布函数,不同的物理问题都可用LBM来解决。平衡分布函数的一般形式为
(4)
其中:u为宏观流动速度矢量;A、B、C、D为常数,需要通过守恒定理加以确定;φ为标量,如密度(ρ)、温度或组分浓度等,其等于所有分布函数的总和。
二维九速(D2Q9) 晶格玻尔兹曼模型如图 1 所示,其边界不存在六角形格子中的阶梯状边界问题,因而得到了广泛使用。利用Chapman-Enskog多尺度展开[10],以及质量与动量守恒,得到局域平衡分布函数:
质量守恒时,
(5)
动量守恒时,
(6)
(7)
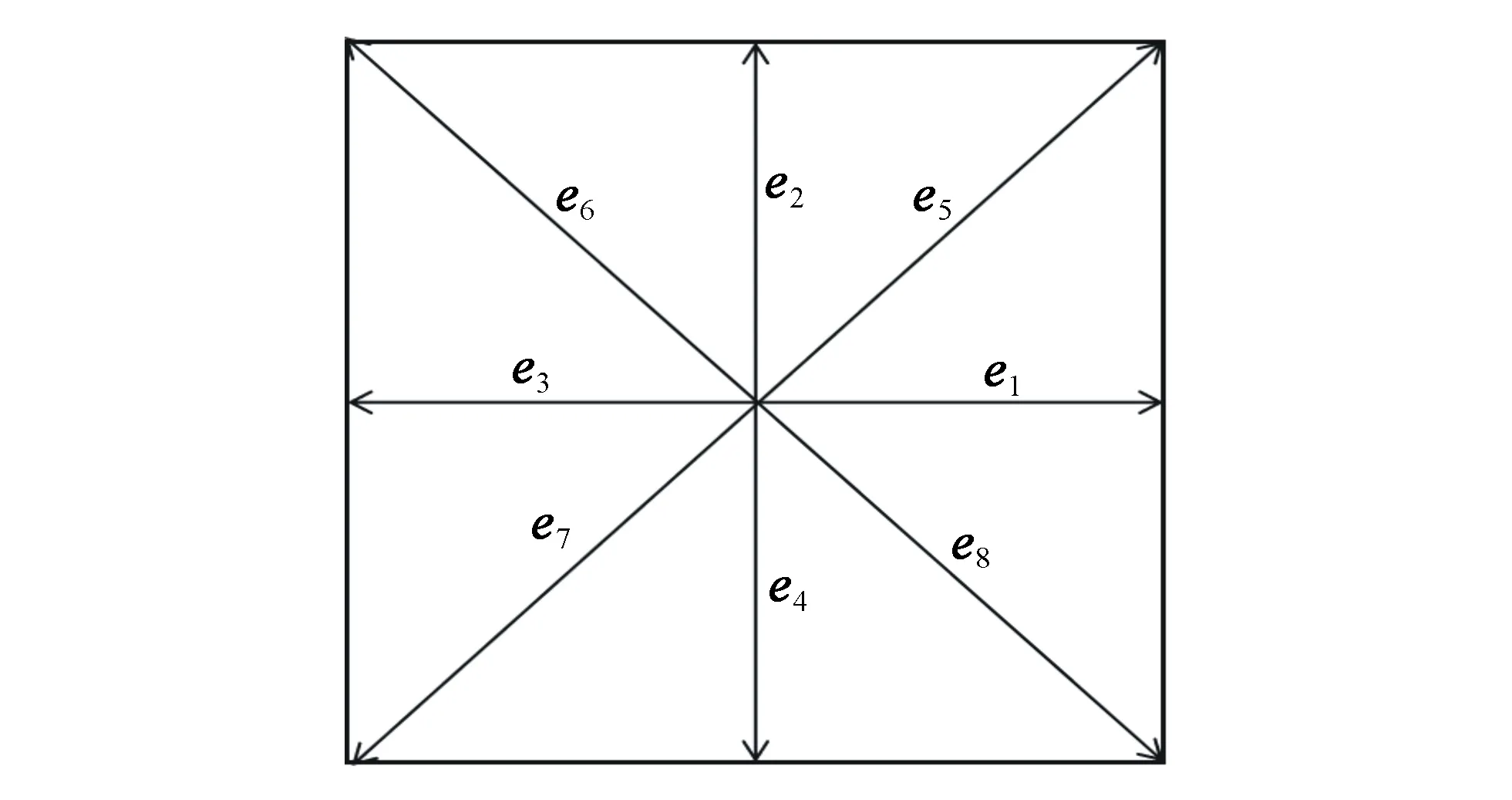
图1 D2Q9晶格玻尔兹曼模型
3 基于CUDA的程序算法优化加速
该程序的的执行步骤为:
1) GPU开辟内存空间,调用CUDA函数中的cudaMalloc()函数。
2) 调用CUDA架构中的cudaMemcpy()函数,将数据传递到GPU上,且此函数中的最后一个参数应为cudaMemcpyHostToDevice。
3) 在GPU并行执行,设计了KernelCollide、KernelStream、KernelCalculate三个核函数,分别代表每个格子进行碰撞、迁移流动、计算每个格子点的宏观量。本计算采用CUDA中的共享内存,对KernelStream、KernelCalculate两个核函数进行优化。
4) 结束迭代循环,调用CUDA架构中的的cudaMemcpy()函数,将GPU的数据传回CPU,此函数中的最后一个参数应为cudaMemcpyDeviceToHost。
基于CUDA上的LBM其最大的问题在于内存的访问以及数据的传输,覃章荣等[11]已证明通过使用CUDA架构中的全局内存、共享内存、纹理内存能够对LBM进行加速,且共享内存优化效果最佳。本研究即针对共享内存的使用再进行优化。
3.1 共享内存
CPU与GPU均采用动态随机存取储存器DRAM。与CPU上不可编译的一级缓存与二级缓存不同的是,GPU上的内存设备有很多种:寄存器、共享内存、全局内存、本地内存、常量内存以及纹理内存,如图2所示。每个线程都对应一个私有的本地内存;每个块中都有一个共享内存,且该共享内存对整个块中的线程可见,同时不同块的线程无法访问另一个块中的共享内存;每个线程均可以访问网格中的全局内存、常量内存以及纹理内存。
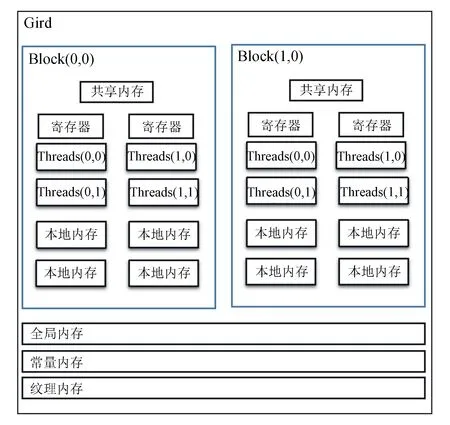
图2 CUDA内存模型
共享内存具有低延迟、高带宽的特点。共享内存作为GPU上的一个关键部分,其使同一个线程块中的线程可以相互协同,最终实现内存利用最大化,进而降低全局内存读取的延迟。在核函数中使用_shared_关键字修饰变量,定义一维、二维甚至三维数组作为共享内存缓冲区。由于共享内存有大小的限制,不可设置太大的数组。在使用共享内存时还需用到线程同步函数_syncthreads(),该函数的调用将确保线程块中的每个线程都执行完_syncthreads()前的语句,才会执行下一条语句,最终保证其他线程都能执行完。在VS编译器可能会出现_syncthreads()未定义标识符的警告提醒,这是由于VS编译器的原因所致,编译无法识别该函数,但是nvcc可以识别。
3.2 程序设计
在整个程序中预先定义了一个Lattice_Str结构体,用于存放9个分布函数、x与y方向上的速度以及格子点的密度等数据。再定义一个parameter结构体,为之后格子点迁徙流动做铺垫。
struct Lattice_Str
{
double m_df[9]; // 9个分布函数
Cuda_Vector m_v; //包含x与y方向上的速度
double m_dDen; // 密度
…
};
struct parameter
{
int iPrjx[9]; //代表 {0,1,-1,0,0,1,-1,1,-1};
int iPrjy[9];//代表 {0,0, 0,1,-1,-1, 1,1,-1};
…
}
针对3个内核函数分别进行讨论。
1) KernelCollide格子碰撞内核函数。由于在LBM中粒子碰撞过程主要涉及到有关计算,用式 (6) 计算平衡分布函数,放入_device_关键字修饰的成员函数,该函数仅可在GPU上运行。
_ device _ void feq(double *dR,int Order,double Den, double Velx,double Vely,parameter *p)
{
double dfeq;
double dDotMet;
dDotMet=p→iPrjx[Order]*Velx+ p→iPrjy[Order] * Vely;
dfeq=Den*p→dCoe[Order]*(1+3*dDotMet + 4.5*dDotMet*dDotMet-1.5*(Velx*Velx+Vely*Vely));
*dR=dfeq;
}
由于GPU具有优秀的计算能力,计算速度得到提升。
2) KernelStream格子迁徙流动内核函数。启动KernelStream<<
struct SharedMemory_data
{
double m_df[9];//9个分布函数
};
_ shared _ SharedMemory _ data
La_SharedM[10][10];
计算二维网格点上的索引i=threadIdx.x+blockIdx.x*blockDim.x;j=threadIdx.y+blockIdx.y*blockDim.y。建立一个循环,将原矩阵格子上8个方向的分布函数传给_shared_修饰的共享内存缓冲区La_SharedM[tthreadIdx.y][threadIdx.y],按threadIdx.x维划分,即threadIdx.y固定而threadIdx.x连续变化,这样在一个线程块即可进行一行一行的访问,从而避免了存储体冲突。在传给共享内存缓冲区时,同时做到传播到相邻的格子点,即(0,0)(1,0)(-1,0)(0,1)(0,-1)(1,1)(-1,1)(-1,-1)(1,-1)这几个方向,需注意的是要添加线程同步函数_syncthreads()。
_ global _ void KernelStream(…,parameter* p)
{
…
_ shared _ parameter st_p;
st_p=*p;
for (k=1;k < 9;k++)
{
La_SharedM[threadIdx.y][threadIdx.x].m_df[k]=Lattice_Str[i- st_p.iPrjx[k]][j-st_p.iPrjy[k]].m_df[k];
}
_ syncthreads();
}
最终将数据从共享内存中传回到原矩阵中。
for (k=1;k < 9;k++)
{
Lattice_Str[i][j].m_df[k]=La_SharedM[threadIdx.y][threadIdx.x].m_df[k];
}
3)KernelCalculate计算格子点宏观量核函数。启动KernelCalculate<<
struct SharedMemory_data
{
double m_df[9]; //9个分布函数
double m_dDen; //格子点密度
double m_vx; //x方向速度
double m_vy; //y方向速度
…
};
_ shared _ SharedMemory_data
Lattice_Str[[10][10];
Lattice_Str[threadIdx.y][threadIdx.x].m_vx=0;
Lattice_Str[threadIdx.y][threadIdx.x].m_vy=0;
Lattice_Str[threadIdx.y][threadIdx.x].m_dDen=0;
类似KernelStream格子迁徙流动内核函数,计算二维网格点上的索引,通过建立循环将原矩阵9个方向的分布函数以及x与y方向上的速度拷入共享内存缓冲区,再将数据从共享内存传回原矩阵,同时也要针对可能产生的错误进行if语句判断,不能一味地为了计算效率而忽略错误判断。
3.3 计算结果及讨论
本计算采用的是泊松流模型,在对程序进行优化加速的同时,也能保证程序结果的正确性。泊松流水平方向速度分布如图 3 所示。从图3可看出,泊松流的水平方向流速为抛物线。本模型进行了10 000步计算(流场还未达到稳定),采用不同共享内存网格大小,与不采用共享内存相比,计算加速比,得到不同的共享内存加速比如图 4 所示。从图 4 可看出,最高加速比可达 2.15,随着共享内存的增加,加速比有所下降,这是因为共享内存的分配是有限的。本计算采用的计时函数是CPU上的clock()函数,与传统上使用cudaEventRecord()函数单一测核函数计算时间不同,要测加速比也需要考虑创建内存时间以及释放内存的耗时,即整个项目的时间,不能只考虑核函数运行所节省的时间。
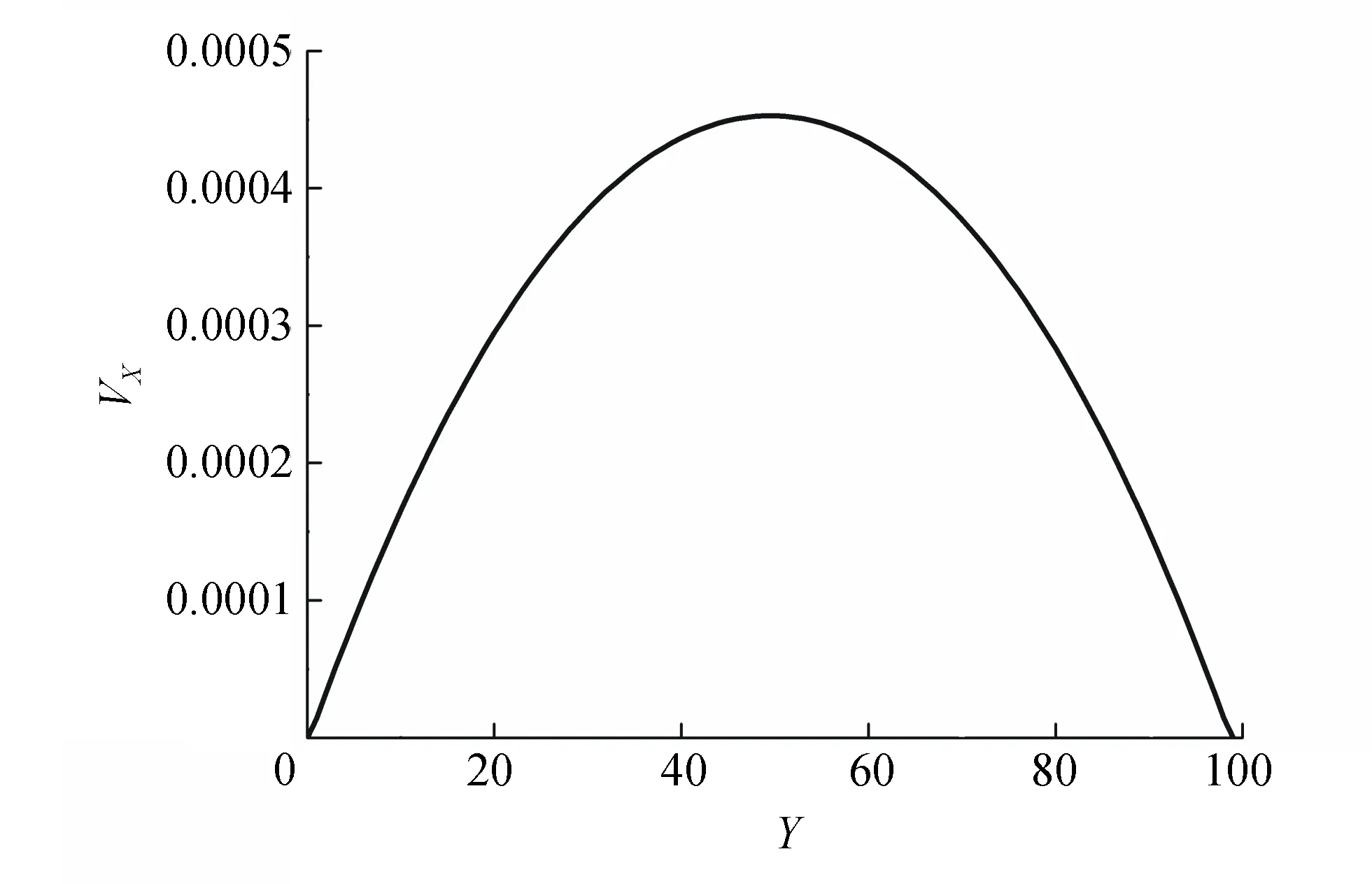
图3 泊松流水平方向速度分布
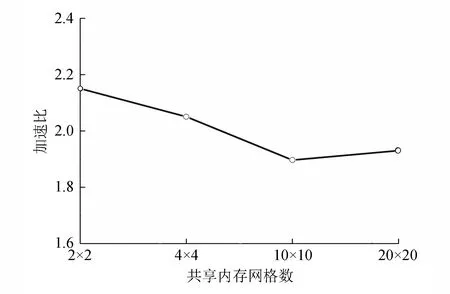
图4 不同共享内存的加速比
4 结束语
针对基于GPU上的CUDA架构,对LBM数值模拟程序加速进行讨论与分析,CUDA架构中的共享内存LBM计算,CUDA的并行计算与LBM天然的并行性能够很好结合。该程序中由于有针对可能出现的越界现象的判断,这会影响计算效率,需后续进行一步优化。
猜你喜欢
保健医苑(2022年9期)2022-10-01
山西电子技术(2021年3期)2021-06-28
网络安全技术与应用(2020年1期)2020-01-07
通信技术(2019年9期)2019-10-09
小学生导刊(2018年22期)2018-08-21
小学生学习指导(低年级)(2018年6期)2018-05-25
女友(2017年6期)2017-07-13
中国工程机械学报(2016年5期)2016-03-07
项目管理技术(2015年3期)2015-04-23
时代人物(2014年10期)2015-01-28
