
基于深度学习的生成式自动摘要技术
2021-01-22 13:40陈天池洪沛杨国锋
数字技术与应用 2020年12期
陈天池 洪沛 杨国锋
(中国电信安徽分公司,安徽合肥 230001)
0 引言
互联网技术的高速发展带来信息快速增长的问题,人们在处理和阅读文本信息中花费大量时间和精力,精简浓缩文本信息的技术显得尤为迫切。自动摘要技术是一种能够从文档中获取重要信息的方法,它能缓解信息爆炸时代给人们带来的时间精力问题。
自动摘要技术按照组成摘要的句子进行区分,可以分为抽取式自动摘要和生成式自动摘要。抽取式摘要通过考虑原文中句子的位置、词频、关键词[1]等评估句子重要度,从原文中提取重要度高的句子组成摘要。此外,陆续有研究将外部知识引入自动摘要任务中,如TF-IDF、Text Rank[2]等,这些算法可以挖掘语料中隐含的知识将其融入句子重要度评估函数中,提高自动摘要效果。抽取式方法虽然能输出语义完整的句子,但由于语言的复杂性和灵活性缺乏对语义的分析,其核心问题在于如何选取更合适的句子来表达文章的中心思想。深度学习技术的出现推动了生成式自动摘要技术的发展,生成式方法使用了一系列自然语言处理技术对原文内容进行总结,生成更加符合人类摘要思维的句子。当前主流的生成式摘要技术是基于Seq2Seq框架进行的[3-4],通过对输入的原文档加以理解将输入序列表示成向量形式,然后经解码器解码得到生成的目标文本,即摘要。与抽取式摘要相比,生成式的方法能够从语义层面对文本进行分析,生成更加简洁、灵活、多样的摘要。
根据任务需求,本文将从语义分析角度出发,基于Seq2Seq框架进行文本语义信息解析,联合注意力机制将文本中的关键信息与语义信息结合起来实现对摘要的引导生成。
1 生成式摘要算法模型
1.1 Seq2Seq框架
Seq2Seq框架[5]是Google在2014年一篇机器翻译的文章上提出来的,将深度学习模型用于语言生成,推动了自然语言生成领域的发展。Seq2Seq是一个Encoder-Decoder结构的网络,其输入是一个序列,输出也是一个序列。其中Encoder的任务是将输入序列编码表示成一个带有语义信息的中间向量,Decoder则将Encoder产生的中间语义向量作为输入解码为目标输出序列。
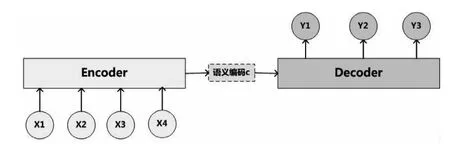
图1 Seq2Seq框架
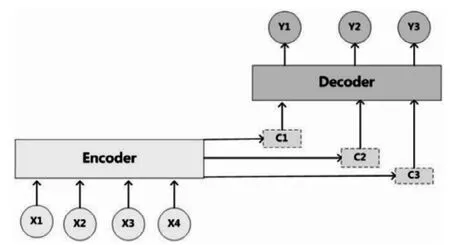
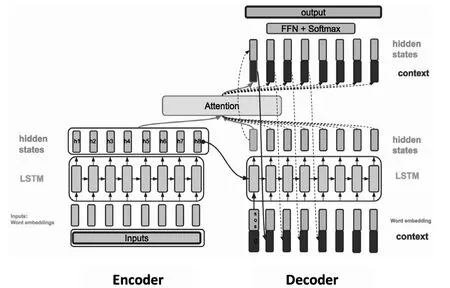
其内部工作流程如图1所示,X代表给定的原始文本输入,Y代表生成的摘要,分别由各自的单词序列组成:X= Seq2Seq的Encoder-Decoder结构虽然非常经典,但具有一定的局限性。其最大的局限性就在于编码器要将整个序列的信息压缩进一个固定长度的向量C中去。当输入序列过长时,一个向量C可能会丢失早期携带的信息,无法完全表示整个序列的信息。这就使得在解码的时候无法获得输入序列足够的信息,那么解码的准确率就会下降。 图2 Attention机制 Attention机制[6]就是为了解决上述问题而提出的。相较于Encoder-Decoder框架,Attention最大的区别就在于它不要求编码器将所有输入信息都压缩到一个固定的向量序列C,而是根据当前要输出的y进行动态调整,给不同部分赋予不同的权重,从而有针对性的对输入的全部信息进行有效利用,如图2所示。 基于上节介绍的相关技术,本文采用的Seq2Seq+Attention生成式自动摘要算法的结构如图3具体操作流程如下: 1.3.1 词典构建 考虑到分词工具容易对文本分词产生错分(尤其是未登录词),本文选择直接采用字作为基本输入进行摘要抽取。对语料中所有字进行频率统计,过滤掉频率过低的字,结果作为词典保存。 1.3.2 Embedding 以字为基本单位,对输入信息进行padding后做Embedding处理,将每个字转换为固定长度m的向量,输入文本即可表示为m×n的矩阵。此处encoder和decoder共享Embedding层的参数,降低模型参数量。 1.3.3 Encoder 把Embedding后的向量输入encoder将其编码为中间语义向量,其中Encoder采用双层双向LSTM,它可以更好的捕捉双向的语义依赖。 1.3.4 Attention + Decoder 由于decoder在执行每一步时无法提前使用后面步的输入,因此Decoder采用双层单向LSTM结构。Attention机制应用在encoder的hidden states上得到context,context一方面作为输入与目标字串联作为Decoder端LSTM的输入,循环得到hidden states;另一方面可以和Decoder的hidden states连接进行softmax计算输出概率。 图3 Seq2Seq + Attention 表1 实验结果 表2 摘要示例 自动文本摘要发展缓慢的原因之一是业界缺乏大规模且高质量的数据集,数据集的好坏直接决定了最后摘要生成的质量的好坏,本文使用的数据集为清华大学开源的THUCNews[7],该数据集包含74万篇新闻文档,共14个类,每条包含新闻标题和对应的新闻内容,本文将新闻标题作为摘要输入模型进行训练。 摘要结果评价采用了Rouge评价体系[8],它是目前公认的摘要评价标准。Rouge评价的思路是分析比较候选摘要集与专家摘要集的相似程度来评价摘要质量。本文采用Rouge-1,Rouge-2和Rouge-L三种方式分别从字相似度、词相似度和句子流畅度三个方面对模型生成的摘要质量进行测试评价。 本文进行了两组实验,实验1采用抽取式方法Text Teaser,实验2采用生成式方法Seq2Seq+Attention,实验结果如表1所示。 表2给出了测试结果的示例,每个例子包含原文本、与之对应的专家摘要、Text Teaser抽取的摘要和Seq2Seq+Attention生成的摘要。通过实验结果对比可以看出,Text Teaser抽取出的摘要偏长,且没有突出文章主题“《我是唱作人》”,而本文设计的生成摘要模型能够准确识别出主题关键词“《我是唱作人》”,同时引申联想到了原文中没有的“云集”一词对文中列举的明星进行概括表达。对比实验结果可知,抽取式摘要虽然能够获得一个完整通顺的句子,但往往难以全面概括文章主题,生成式摘要则能够将文中原句进行缩写、转述等,生成更凝练的摘要,更加符合人的理解。 从上述实验分析结果来看,本文采用的Seq2Seq+Attention方法能够在一定程度具有表征、理解、生成文本摘要的能力,满足提取关键信息的要求。但从实验结果来看该方法也存在许多不足,模型在对人/地名等命名实体、未登录词、重复词进行处理时,无法准确识别这些信息,最终导致摘要生成结果表述不准确。因此,在后续的研究中我们将针对这一问题作进一步研究,为准确提供用户AI话术提供更有力的支撑。1.2 注意力机制(Attention)
1.3 算法流程


2 实验结果及分析
2.1 数据集
2.2 实验结果与讨论
3 结语
猜你喜欢
中国石油石化(2022年12期)2022-07-16
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
开放教育研究(2020年2期)2020-03-31
中国外汇(2019年19期)2019-11-26
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
现代语文(2016年21期)2016-05-25
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
