
自适应加权低秩约束的多视图子空间聚类算法①
2021-01-21 06:50刘金花岳根霞贺潇磊
计算机系统应用 2020年12期
刘金花,岳根霞,王 洋,贺潇磊
1(山西医科大学汾阳学院,汾阳 032200)
2(北方自动控制技术研究所,太原 030006)
1 引言
在实际应用中将来自多个源或者通过不同的采集器采集到的数据,称为是多视图数据[1].例如,我们可以通过人脸、指纹、签名或虹膜来进行人物识别;通过颜色、纹理或图注特征来表示一张图像.多视图聚类就是利用隐藏在多个视图数据中的互补信息和一致信息来提高聚类性能[2,3].最直接的方式就是将多视图数据的特征进行简单拼接,然后执行单视图聚类算法.然而,在实际应用中,特别是多媒体领域,每个视图的数据都是一个高维的特征空间,将各视图特征拼接显然会带来“维度诅咒”.另外,对于高维数据,特征分布通常更稀疏,传统欧式距离来进行相似性度量的方法根本不适用[4].为了解决这个问题,本文使用了低秩约束的方法从高维数据中学习低维的子空间,这样既缩减了计算的复杂度,也提高了对噪声数据的鲁棒性.
另外,目前的多视图聚类方法主要分为基于潜在一致信息、基于多样互补信息和综合潜在一致和互补信息三大类.这些方法都有一个共同的缺点,它们平等的对待各视图.由于各视图表征数据的能力有强弱之分,故赋予各视图不同的权重更具合理性[5].洪敏等[6]考虑到不同样本存在的“全局”信息的差异,提出了样本加权的K-means 多视图聚类算法;Xu 等[7]提出了在各视图间和视图内特征都进行加权的K-means 多视图聚类算法;聂飞平等致力于研究自动加权的多图学习模型,主要有AMGL[8]和SwMC[9]模型,还有Huang和Wang 等[10,11]提出无需引入任何权值和惩罚参数自动为各视图分配权重的多视图聚类算法,但这些方法主要是针对基于K-means 或基于图的多视图聚类.本文针对基于子空间的多视图聚类方法提出的自适应权重学习方法,在目标函数中设置了权重参数,且在函数优化的过程中以自动学习的方式同时优化各权值.
2 本文方法
2.1 自表示的子空间聚类
自表示的子空间聚类可以有效处理高维数据,它是基于这样的假设:空间中的任何数据点都可以通过其他样本点的线性组合得到.设X(v)=Rdv×n为第v个视图的数据矩阵,其中每一列为一个样本,dv为特征空间的维度.自表示方式的子空间聚类方程如下所示:

其中,L (·,·) 表示数据重构的误差损失函数,Ω (·)表示正则项,并且λ用于平衡公式中的两项.Z(v)为潜在的自表示系数矩阵,当求得Z(v)后,就可以通过式(2)来得到用于谱聚类输入的亲邻矩阵S.

2.2 低秩约束
正如前面讨论的,对于高维数据,构造一个低秩的矩阵可以很好地捕获数据的特征.Liu 等[12]提出了用于单视图数据的低秩表示方法,即将数据样本表示为基的线性组合,然后从这些候选对象中寻找最低的秩表示.本文将它扩展到多个视图,也就是每个视图数据都进行最低秩表示,如式(3)所示.
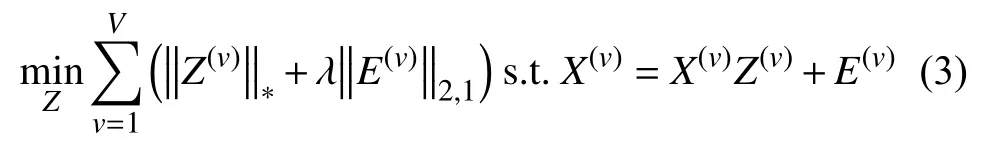
2.3 加权融合
由于多视图数据描述的是同一事物,所以这些视图数据有潜在相同的数据结构[13],那么多视图聚类的目的就是要从不同视图数据中挖掘出潜在一致的数据结构.类似的,本文假设潜在一致数据结构Z是由各视图低秩表示Z(v)线性组合得到的.另外,考虑到数据的噪声、缺失等因素,还有不同视图数据表征能力的差异性,表征能力强的数据可以很好助力聚类,而表征能力差的数据含有大量噪声和冗余特征阻碍了聚类性能.因此,我们利用了加权的方法来融合得到潜在一致矩阵Z,如式(4)为本文提出的目标函数.

3 优化
式(4)是典型的低秩优化问题,本文利用了增广拉格朗日乘子法来进行优化.为了变量可分,引入了辅助变量R(v)代替Z(v)得到式(5).


3.1 更新R(v)
固定除R之外的其他所有变量,得到关于R的子问题如式(7):

上式可以通过奇异值阈值法[14]来求解如式(8),获得闭形式的解.其中Sτ[·]是收缩阈值操作符.
3.2 更新Z(v)
固定除Z(v)之外的其他所有变量,得到关于Z(v)的子问题如式(9):

对式(9)求关于Z(v)的导数,并令其为0,得到了下面的优化解.

3.3 更新E(v)
固定除E之外的所有变量,得到关于E的子问题如式(11):

参照文献[12]中引理3.3 得到下面的优化解.

3.4 更新Z
固定除Z外的其他变量,得到了关于Z的子问题:

对式(13)求关于Z的导数,并令其为零,得到了下面的优化公式:

3.5 更新Π
固定Π 之外的其他变量,得到了关于Π 的子问题.

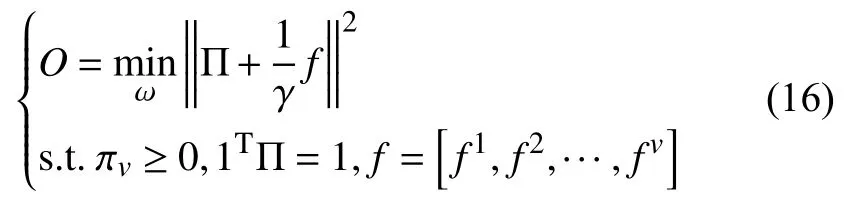
3.6 更新拉格朗日乘子


算法1.优化过程输入:多视图数据集X={X(1),…,X(V)},类簇数k,参数,最大迭代次数maxIter,,ρ=1.1.1:Repeat 2:For v∈V do R(v)λ,γµmax=106 3:利用求解式(8)更新4:利用求解式(10)更新Z(v)E(v)5:利用求解式(12)更新6:利用求解式(16)更新权重Π Y1(v) Y2(v)7:利用式(17)更新拉格朗日乘子,8:end 9:利用求解式(14)更新Zµ=min(ρµ,µmax)10:更新11:Until 收敛或达到最大迭代次数输出:Z.
4 实验
4.1 数据集及评价指标
为了验证所提多视图聚类算法的有效性,本文选取了5 个公开的数据集进行实验,各数据集描述如下:
(1)Digits 数据集包含2000 张手写的0-9 数字图像数据,每个数字包含200 条样本,共有6 个视图.本实验选择了Fourier 和pixel 两个视图.
(2)Caltech101-7 是一个广泛使用的图像数据集,包含7 个类别共441 张图像,由CENTRIST、CMT、GIST、HOG、LBP 和SIFT 6 个视图组成.
(3)3-source 数据集包含BBC、Reuters 和Guardian 3 个源的新闻数据,共169 条分为6 个类别.
(4)WebKB 数据集包含Texas、Cornell、Washington和Wisconsin 4 个大学的网页数据.每个网页由内容、链入信息、视角和城市4 个视图.由于4 个子数据集是相似的,本文采用了Texas 数据集进行实验,它包含187 条样本共5 个类别.
(5)MRSCV1 数据集包含240 张共8 个类别的图像,本实验选择常用的牛、树、建筑、飞机、人脸、汽车和自行车7 个物体,包含与Caltech101-7 数据集相同的6 个视图.
另外,本文采用了两个通用的聚类评价指标ACC和NMI 来对实验结果进行评价.
4.2 比较实验及讨论
将所提算法与现有相关算法进行比较,包括单视图的子空间聚类模型(LRR)、协同正则的多视图谱聚类模型(CoregSPC)[15]还有潜在的多视图子空间聚类模型(LMSC)[16].对于单视图的LRR 模型,我们进行了两次实验,在每个视图上执行LRR 算法,从得到的结果中取最好的记为LRR_best;另外,我们将各视图的特征进行直接拼接后,在其上执行LRR 算法,得到的结果记为LRR_catFea.对于比较算法,涉及到的参数都按照原论文中作者建议的值进行设置.另外,为了避免算法中随机初始化引起的误差,每个算法在各数据集上都重复进行10 次实验,然后取均值作为最后结果.表1就是各算法在相应数据集上的聚类准确率和NMI 值.

表1 各算法在5 个公开数据集上的ACC 和NMI 值
从表中可以看出本文所提算法在5 个公开的数据集均优于其他的模型,可见算法发挥出了它应有的效果,将表征能力强的视图赋予了大的权重,且摒弃了冗余的特征和噪声特征.
4.3 参数敏感性分析
在所提算法中存在λ和γ两个参数,我们采用网格搜索的策略来选择最优的参数组合,设置λ的取值范围均为[10-4,104],γ的取值范围为[1,105],图1分别展示了两个参数在设定范围内所提算法在3 个数据集上的准确率和NMI 值.从图中可以看出参数在给定的范围内对应的ACC 与NMI 值变化都不是特别大,说明该算法在给出的取值范围内对参数λ和γ不敏感;不过从MRSCV1 和3-sources 数据集的结果可以看出γ取值在[1,105],λ取[10-2,102]聚类结果相对较好,故在其他数据集上进行实验时,我们固定γ值为10,然后让λ取[10-2,102].
5 总结与展望
文章提出了一个低秩约束的自适应权重的多视图子空间聚类算法,由于高维数据的特征分布比较稀疏,所以利用低秩约束来进行各视图子空间的自表示矩阵,然后学习各视图共享的潜在一致数据结构,另外,在寻找各视图的一致结构时对各视图设置权值,在算法优化的过程中该权值会随着目标函数优化.在公开的数据集上进行实验证明了所提算法的优越性.

图1 在MRSCV1、WebKB 和3-sources 数据集上参数λ 和γ 取不同值时的聚类ACC 和NMI 值
猜你喜欢
模式识别与人工智能(2022年9期)2022-10-17
计算技术与自动化(2022年1期)2022-04-15
计算机研究与发展(2022年1期)2022-01-19
计算机技术与发展(2020年2期)2020-04-15
世界知识画报·艺术视界(2017年7期)2017-07-27
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
今日中国(2017年3期)2017-03-31
试题与研究·中考数学(2016年4期)2017-03-28
电脑知识与技术(2016年13期)2016-06-29
