
基于CTPN神经网络对营业执照文字检测模型
2021-01-19 02:24邵慧敏张太红
计算机技术与发展 2021年1期
邵慧敏,张太红
(新疆农业大学 计算机与信息工程学院,新疆 乌鲁木齐 830001)
0 引 言
营业执照是工商行政管理部门发给工商企业和个体经营者能够从事某些生产经营活动的证明,是证明某个企业具有一定资格的重要依据[1-2]。文本图像信息是人们获取外部信息的主要来源。在现代科学研究、军事技术、医学、工农业生产等领域,越来越多的人使用图像信息来识别和判断事物并解决实际问题。虽然从图像中获得文字信息非常重要,但更重要的是对文字图像进行处理,从图像中获取所需要的信息,因此在当今科学技术高速发展的时代,对文字图像的处理技术就有了更高的要求,能够更加快速准确地检测人们所需的图像文本信息[3-6]。
目前,文字检测方法主要包括基于文本框回归的分类、基于分割的回归以及分割和回归结合的方法[7-8]。虽然近些年基于深度学习的文字检测方法已经取得巨大进步,但是文字作为一种具有其独有特色的目标,其字体、颜色、方向、大小等呈现多样化形态,相比一般目标检测更加困难[9-12]。一个模型在某个开源的数据集上得到了很好的效果,用这个方法直接换到另外的数据集上也许效果就不是很好,甚至是比较差的。因为很多模型是针对某项数据集来调整参数进行不断优化的,所以它极大依赖于数据,深度学习它有没有学到本质的东西,这个问题还值得深度探讨[13-17]。神经网络模型在文字检测方面已经有了研究,例如区域文本框网络(RPN),只是RPN进行的文字检测很难准确地进行水平检测。RPN是通过直接训练来定位图像中的文本行,但是通过文本行来预测图像中的文本出现错误的可能性很大,因为文本是一个没有明确的封闭边界的序列。令人欣喜的是,Ren提出了anchor回归机制允许RPN可以使用单尺度窗口检测多尺度的对象,这个想法的核心是通过使用一些灵活的anchors在大尺度和纵横比的范围内对物体进行预测[18-22]。其研究结果表明,根据CTPN方法,建立营业执照文字检测神经网络模型,能够准确地对营业执照的文字进行水平检测。
1 CTPN神经网络简介
CTPN神经网络模型主要包括三个部分:卷积层、双向LSTM、全连接层。底层使用VGG16来提取特征,由一个W*H*C的conv5的feature map,使用大小为3*3的空间窗口,在最后一层卷积(VGG16的conv5)的feature map上滑动窗口。每行中的顺序窗口通过BLSTM(bi-directional long short-term memory)循环连接,其中每个窗口的卷积特征(3×3×C)作为BLSTM的输入,再实现双向BLSTM,增强关联序列的信息学习,再将VGG最后一层卷积层输出的feature map转化为向量形式,用于接下来的BLSTM训练。然后将BLSTM的输出再输入至FC中,最终模型输出:2k个anchor的文本/非文本分数、2k个y坐标、k个side_refinement(侧向细化偏移量)。该模型设计的CTPN神经网络模型如图1所示。

图1 CTPN神经网络模型
CTPN神经网络是一个完整的卷积网络,可以允许输入任意大小的图像。CTPN通过在CNN的feature map上密集地移动窗口来检测文本行,输出的是一系列的适当尺寸(固定宽度16像素,长度是可以根据情况调整的)的文本proposal。给每个proposal设计了k个垂直anchor用来预测每个点的y坐标。这k个anchor具有固定16个像素的水平位置,但垂直位置在k个不同的高度上变化。此次使用10个anchors,高度在11~273个像素变化,垂直坐标是通过一个proposal边界框的高度和y轴的中心计算得到的。有关预测anchor边界框的相对垂直坐标的计算公式如下:
(1)
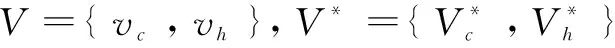
CTPN的三个输出都被一起连接到全连接层上。这三个输出同时预测文本/非文本分数,垂直坐标和side-refinement的偏移量。采用k个anchor对它们三个分别预测,依次在输出层产生2k、2k和k个参数(CTPN固定了水平位置,只预测垂直位置)。利用多任务学习来联合优化模型参数,目标函数如下:
(2)
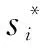
偏移量计算公式如下:
(3)
其中,O表示在X方向的归一化的偏移量,cx表示anchor的中心,xside表示预测的中心,w表示anchor的宽度。针对文本/非文本的分类,二进制的标签被分给每一个正anchor(文本)和负anchor(非文本),正负anchor是由IoU与GT边界重叠计算得到的。正的anchor被定义为:IoU与GTbox的重叠大于0.7的或者最高(集是一个很小的文本pattern也会被分为一个正的anchor)的anchor,负的anchor是IoU小于0.5产生。
2 估测模型训练过程
2.1 实验数据集
实验数据是笔者用手机拍摄及扫描的,总共收集大约2 000张营业执照数据集,采集日期是2018年12月初-至今。由于营业执照含有持有者的个人信息,所以收集起来比较困难。
2.2 数据预处理
2.2.1 图像采集
手机拍照或者扫描得到营业执照的图片。
2.2.2 图像预处理
营业执照的图像背景噪声大,所以首先利用Opencv对图像进行灰度化、矫正处理,再用labelimg对2 000张数据进行标注,得到xml格式的数据集,然后再转成VOCdevkit数据集,用于训练CTPN模型。
2.3 训练过程
该模型使用随机梯度下降(SGD)对现有的CTPN进行训练。因为牵扯到大量数据的计算训练,所以选用的服务器是适合于大规模运算的Google Cloud Platform的GPU服务器,所用数据集为VOCdevkit,并进行10 000次迭代训练。与RPN神经网络相同的是训练样本为anchors,每一个anchor是一个训练样本。对每个预测来说,水平位置和k个anchors的位置是固定的,这个是由输入图像在conv5的feature map上窗口的位置预先计算得到的,生成的文本proposals是由文本分数值大于0.7(通过使用NMS)的anchor生成的。通过使用垂直anchor和fine-scale策略,detector可以处理各种比例和纵横比的文本行,进一步节省了计算量和时间。在迭代训练过程中,生成的total_loss、model_loss如图2、图3所示。

图2 total_loss
目前,Mean Average Precision特别适用于预测目标位置及类别的算法,因此它对评估定位模型、目标检测模型和分割模型非常有用。在计算mAP之前先要了解Precision和Recall也就是精确率和召回率,精确率主要用于衡量模型做出预测的精准度,召回率主要用于衡量模型对Positives的检测程度。
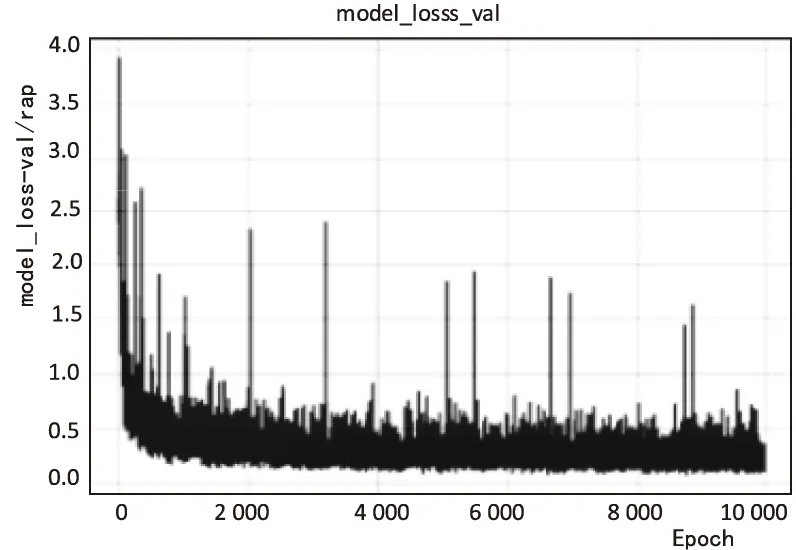
图3 model_loss
(4)

(5)
其中,TP=True Positive,TN=True Negative,FP=False Positive,FN=False Negative。随着Recall从0到1之间的提升,AP(average precision)可以由计算11个不同Recall阶层最大Precision的评价值而得到。该文使用如下方式计算AP:

(6)

模型训练完成后进行测试,得到的AP如图4所示。
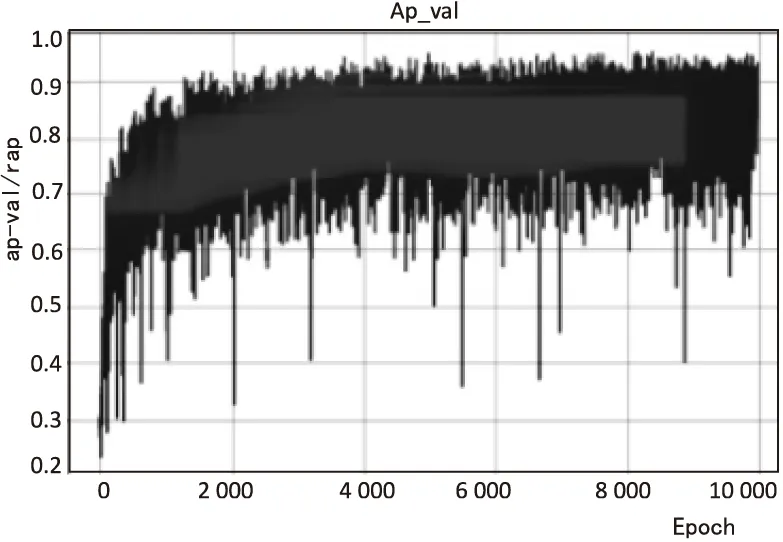
图4 AP
3 实验结果及其对比
本次实验首先进行数据采集,其次对采集数据进行预处理,并分析所研究的营业执照文字中所需要检测的位置,然后运用python语言结合Tensorflow框架、Opencv等第三方工具包构建CTPN神经网络,再根据评价指标对模型进行参数优化,最后确定模型并与现有的方式进行对比分析。经过多次实验后,选取了其中的一个样本进行对比分析,此次是将RPN和未训练的CTPN及训练后的CTPN对营业执照图像的文字检测结果进行对比,检测结果如图5所示。

(a)RPN (b)未训练的CTPN (c)已训练的CTPN
由于营业执照复杂的背景,噪声干扰,字体大小不一致,颜色多样,且需检测的文字都是水平检测,所以基于RPN的方法对营业执照图像中文字的检测不具有良好的鲁棒性,经测试有很多的文字都未被检测到。像营业执照中的经营场所和经营范围出现多行文字的情况时,每一行文字没有被分开检测,这对后续的文字识别率有很大的影响,因为OCR识别只能识别单行的文字。没有用营业执照数据集训练的CTPN的检测率也不理想,部分文字未被检测到,同样在出现多行文字时没有将每一行进行分开检测,但检测效果比RPN要好。而经过训练后的CTPN,检测的准确率大大提高,也解决了出现多行文字时每一行文字被分开检测,准确率达到项目使用的要求。
4 结束语
CTPN利用文字序列的特点降低了检测难度,使其能够对背景复杂的营业执照图像进行高精度检测。而系统的不足之处是对拍摄角度、曝光度及像素较低的图像的检测率较低,将会在后期的研究中对其进行改进。目前数据集较少,还需要再不断收集数据,并且在用labelimg标注数据时,要避免勾图的框过大,保证文字被完整框住即可,使用这样标注的数据集进行训练,会更有利于提高CTPN模型的文字检测率。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
煤气与热力(2022年2期)2022-03-09
中国品牌(2021年6期)2021-08-06
软件(2017年6期)2017-09-23
妇女生活(2017年8期)2017-09-06
金点子生意(2014年4期)2014-04-10
中学生英语高效课堂探究(2008年9期)2008-11-17
