
基于卷积神经网络的语义分割技术及其在脑神经影像应用中的研究进展
2021-01-18 06:05:22吴玉超王婧璇吴水才
北京工业大学学报 2021年1期
林 岚,吴玉超,王婧璇,吴水才
(北京工业大学生命科学与生物工程学院智能化生理测量与临床转化北京市国际科研合作基地, 北京 100124)
在过去的几十年中,结构和功能神经影像成像技术的巨大发展,使其在神经系统疾病的诊断中扮演着越来越重要的角色[1].通过非侵入式的神经影像技术,医疗工作者们在不断提高空间分辨率和时间分辨率的条件下,获取了大量患者的影像数据.这为了解大脑的解剖结构及其工作机制,特别是高级认知活动的内在机制奠定了坚实基础.现在,神经影像技术已被广泛用于研究癫痫、脑卒中、脑肿瘤、多发性硬化症、神经退行性疾病(如阿尔茨海默症)等疾病[2-7].当前,基于神经影像的正常与病理脑组织分割和临床解释一般依赖于神经放射科专家们的主观定性解释,利用计算机算法自动分析更多是一种辅助手段.由于神经影像数据量大,完全依赖于手工分割既烦琐耗时,结果又比较主观,不能适应现代神经影像学的发展要求.随着计算机技术的普及,准确、自动化的神经影像分割方法已成为放射科医生的一项重要需求.神经影像分割方法旨在大脑中定义不同类别的感兴趣区域:如大脑、脑组织结构类型或更局部的脑解剖区域.在分割过程中,所面临的挑战包括低信噪比、影像灰度不均匀、部分容积效应、形状复杂性等方面.传统的神经影像分割方法主要包括基于阈值的方法、基于区域的方法及像素分类方法等[8-9].当前,一些新方法进一步将传统分割方法与脑模板/图谱的先验知识相结合[10-11],将脑图谱的先验知识融入分割过程.该类方法基于模型描述分割任务,设定解空间,最后通过数学计算优化最大化目标函数(或等效地最小化能量函数)来实现分割模型[12].然而,这类方法对先验知识有较大依赖,对原始输入数据或模型特征敏感度高,当分割数据与先验知识不能很好匹配时往往分割性能不佳.与这些分割方法不同,图像语义分割是更高层次的图像分割方法.它既包含图像分割,又包含对每个像素所属分类的密集预测.给定一份神经影像,语义分割模型不仅能对图像进行自动分割,而且能识别出图像中的内容.深度学习方法不再需要明确地指定影像特征,而是基于层次型的神经网络结构,自动从大型神经影像数据库中隐式地学习数据中的高级抽象.2014年,加州大学伯克利分校的Long等[13]提出了基于卷积神经网络(convolutional neural networks,CNN)进行图像语义分割的代表作——全卷积网络(fully convolutional network,FCN).该网络的核心思想是在已训练好的CNN中,用卷积层来替换全连接层,从而可以保存分割的位置信息,并进行密集的像素预测.输入图像的每一个像素在输出图像中都有对应的类别标注,实现了像素级一对一的类别标注映射.
在大量的图像分割问题中,基于CNN的语义分割技术表现出较前文所述传统方法更优的性能.因此,它也开始被应用到神经影像的研究领域.本文针对神经影像研究中的具体分割应用,以基于CNN的语义分割技术为主线,评述了该应用领域的现状和挑战.首先,简述了CNN的结构和特点,从语义分割网络的基础结构出发,介绍语义分割的最新进展.随后,介绍了基于CNN的语义模型在神经影像领域的应用成果.最后,指出该领域中存在的问题及未来的研究方向.
1 语义分割网络及其发展
1.1 CNN
基于CNN的语义分割并不是一个独立发展的领域,其发展过程在一定程度上与CNN发展同步.CNN的设计思想来源于猫的大脑视觉皮层对于信息的分层处理机制.最前面的层提取的是最简单的信息,并逐渐得到高层次的抽象信息[14].CNN解决了以往机器学习中需要人工设计特征的难题,能够学习输入数据的分层特征表示;网络的不同层能对特征进行不同级别的抽象[15-17].通常,CNN由3个主要的层组成,分别是卷积层、池化层和全连接层.训练分为前向和后向阶段.前向阶段用每一层的权重和偏差来表示输入图像.然后利用预测输出和真值标签的差异来计算损失误差.在后向阶段,基于损失误差用链式法则来计算每个参数的梯度,并根据梯度对所有参数进行更新.经过充分的前向和后向迭代,网络可以获得较好学习效果.AlexNet模型[18]在2012年计算机视觉大赛以绝对优势迎来了CNN的应用热潮.随着CNN架构的不断发展,一些著名的CNN模型应运而生,它们通常被作为语义分割系统的基础网络.常用的CNN模型及它们的主要贡献如表1所示.

表1 经典CNN模型及其特点
1.2 语义分割与FCN
图像语义分割是一种密集预测的任务,其目标在于标记图像中每一个像素,实现像素级别的分类.CNN的多层结构可以自动进行特征提取和学习,并对提取到的特征进行图像分类.但是,CNN中的全连接层会对多次卷积后获取的高度抽象化特征进行整合与归一化,将卷积层产生的二维特征图压缩成一个固定长度的一维特征向量,从而丢失了关键的空间信息.FCN是对CNN的延伸,主要使用了卷积化、上采样和跳跃结构3种技术,其具体结构如图1所示,在结构图中还标出了每层所得特征图的通道数.卷积化技术把传统CNN最后的全连接换成了卷积层,输入图像的大小不再受限,将分类网络输出变化成二维的目标物热力图.同时,针对池化层下采样后的特征图与原图像大小不一致这一问题,采用转置卷积上采样,可将热力图上采样到与输入图像相同尺度.跳跃连接将低层网络的细节信息和高层网络的位置信息进行结合,将不同分辨率的特征图整合到同一尺度并进行融合.FCN是语义分割问题中的关键里程碑,为图像语义分割指明了方向.当然,它也存在结果图像过于模糊或平滑,不够精细,不能分割出目标图像的细节这样一些缺陷.
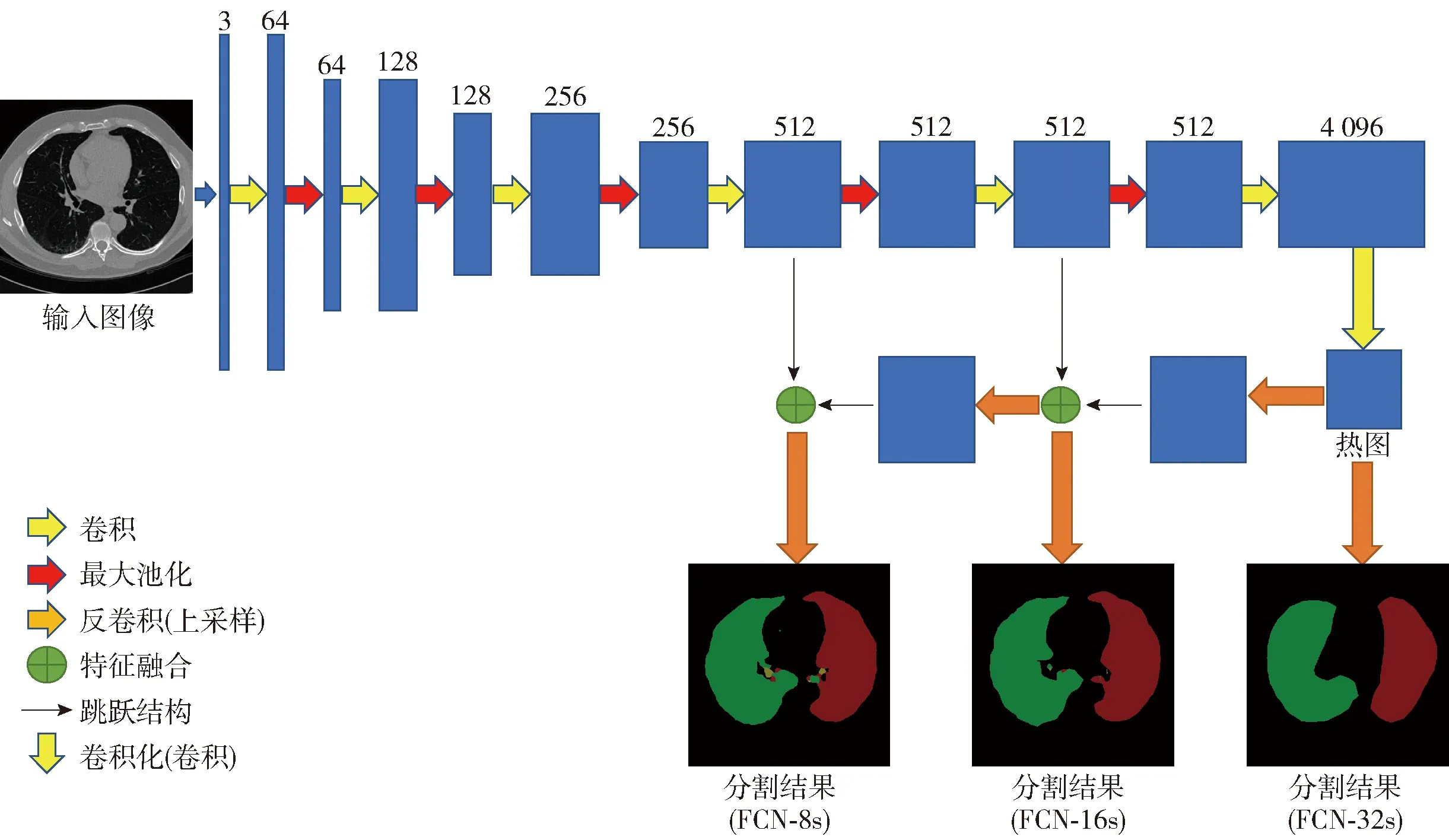
图1 FCN网络结构Fig.1 FCN model illustration
1.3 编码器- 解码器结构与语义网络优化
一个通用的语义分割模型可以被认为是一个基于前端的编码器和一个基于后端的解码器网络组成的综合体[22].前端编码器通常是一个预训练的CNN分类网络,其中的卷积层和池化层会逐渐缩减输入数据的空间维度,降低特征维度.当后端解码器接收到前端编码器的特征表达后,会通过反卷积层等逐步恢复目标的细节和空间维度,将编码器学习到的较低分辨率的可判别特征从语义上映射到较高分辨率的像素空间,以获得密集分类.FCN是最为典型的编码- 解码器结构,当前这种结构已成为图像语义分割的基本框架.语义网络的发展主要来源于对编码器结构、解码器结构的优化,以及设置独立的后处理模块来优化分割结果.几种最为典型的语义分割网络架构如表2所示.
2 基于CNN的语义分割网络在脑神经影像上的应用
对脑神经影像进行定量分析是许多神经疾病的常规检查步骤,而感兴趣区分割是定量分析的关键步骤.研究者们在运用分割方法对正常脑组织结构(例如,白质和灰质)和病变脑组织(例如,脑肿瘤)分割方面已经进行了大量的努力,但此类方法还面临着一些挑战.基于CNN的语义分割网络由于可以避免传统算法的局限性,自动学习神经影像中有价值的成像特征,实现像素级别分类预测,因此越来越受到学术界和工程界的重视.
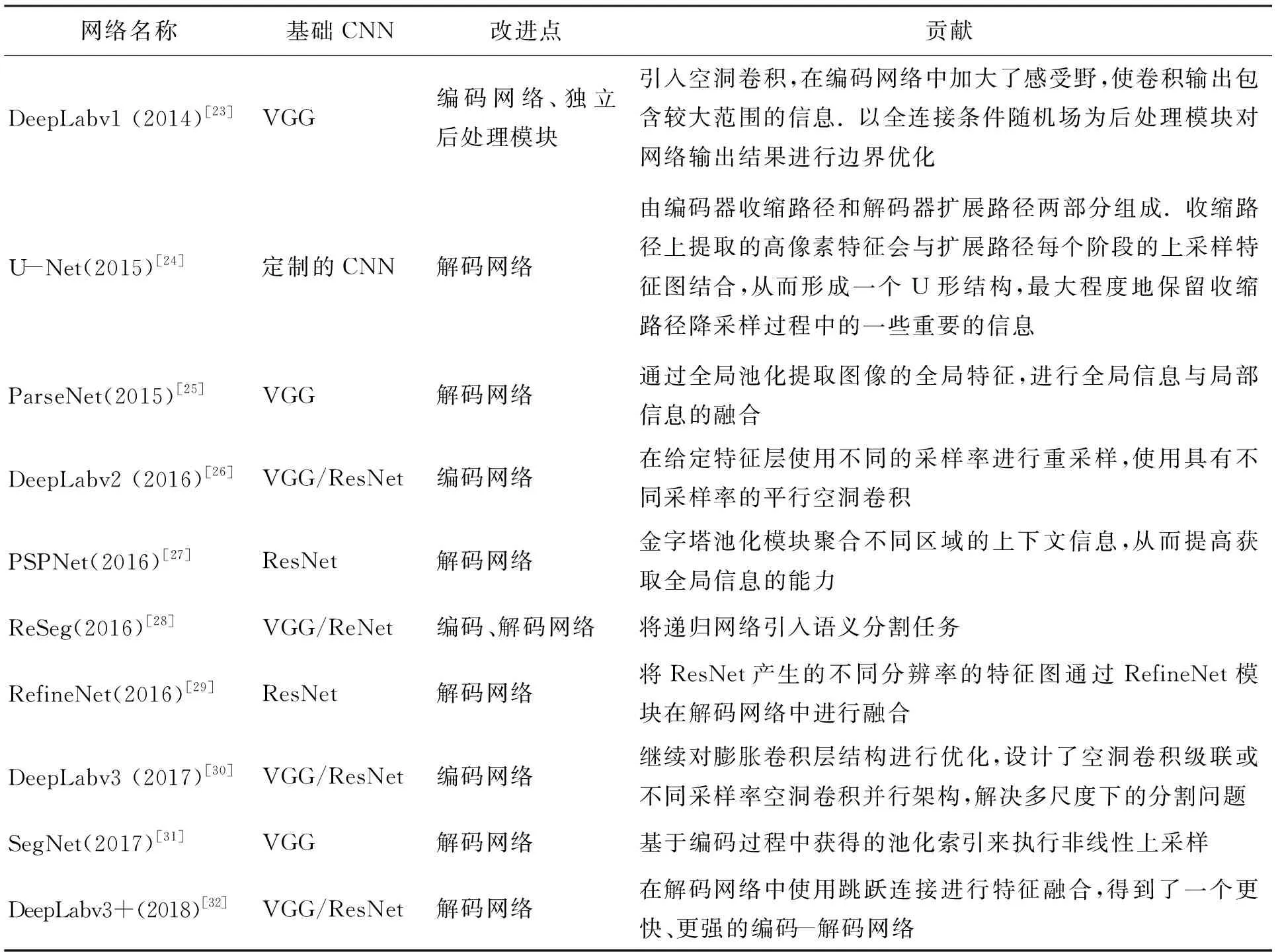
表2 典型语义分割网络比较
2.1 非脑组织去除
从神经影像中去除非脑组织是大量神经影像分析工作的第一步流程,其准确性会严重影响后续的处理步骤[33].当前,多种方法已被用于健康成人的脑磁共振成像(magnetic resonance imaging, MRI)的研究,并取得了较好的效果.但当面对其他模态的影像数据、婴幼儿大脑[34]、存在病理改变的大脑以及动物模型脑图像[6]时,结果往往不尽人意.如在计算机断层扫描图像(computed tomography,CT)中,眼睛和颈部等组织的CT衰减系数与大脑组织相似,因此为MRI而设计的方法在这些区域一般表现较差.Akkus等[35]对比了二维U- Net、2种改进的二维U- Net、三维U- Net和SegNet 5种类型的语义网络对CT图像中的非脑组织去除效果.其中,对二维U- Net的第1个改进版本是通过提升编码器的卷积步幅来改善降采样效果.同时用leakyReLU替代ReLU作为激活函数.对二维U- Net的第2个改进版本是对收缩路径和扩展路径中对应卷积块之间加入批处理规范化和残差连接.三维U- Net网络由于计算量的原因,对训练数据进行了4倍的降采样,同时对分割结果进行4倍升采样.结果显示,未优化改进的二维U- Net具有最好的分割性能,同时该方法比传统方法具有更好的泛化能力.Zhao等[36]将深度贝叶斯CNN与全连通三维条件随机场相结合,对100只灵长类动物的MRI的T1像进行了非脑组织去除.贝叶斯SegNet不仅能够获得高分辨率像素级的分割结果,而且能够在测试阶段通过蒙特卡罗采样来测量模型的不确定性.全连通三维条件随机场进一步对概率分割结果进行优化,在动物模型中展示了优异的性能.
2.2 脑组织结构分割
脑组织结构分割方法一般集中在将神经影像分割为3种不同脑组织结构,即白质、灰质和脑脊液.这类方法对于脑组织结构和颅内体积的大规模定量评估非常重要,实践中一般需要进一步结合脑图谱或脑模板中的先验信息.近年来,基于CNN的语义网络开始被用于该领域,往往可以提供比阈值分割等传统方法更好的性能,特别在先验知识不足的领域.Chen等[37]提出了一种改进的U- Net模型,在编码器收缩路径中使用不同大小的卷积核提取图像特征并进行拼接,结果显示在灰质、白质和脑脊液这3个基本脑组织结构上较U- Net具有更好的性能.Chen等[38]提出了一种体素级残差网络(voxelwise residual network, VoxResNet)用于白质、灰质和脑脊液的分割.深度残差学习的改变表现在训练时,不是简单地堆叠层,而是通过将输出表述为输入和输出的一个非线性变换的线性叠加来缓解网络随层数变深出现的网络退化问题,这样可以充分利用更深的网络来获得性能提升.在该研究中,VoxResNet由25层网络层组成,比一般的语义分割网络在深度上有所提升.同时,VoxResNet将残差结构从二维扩展到三维,以满足三维MRI脑组织结构分割的任务.T1像、水抑制像等多种模态的互补信息以及多尺度的上下文信息被整合到VoxResNet中,将低级的图像外观特征,隐式的形状信息和高级的上下文信息无缝集成在一起,进一步提高分割性能.该方法在医学图像计算与计算机辅助干预学会举办的脑MRI分割大挑战竞赛中[39]获得了第1名的成绩.该竞赛的第2名是一种名为多模态聚合网络的方法[40].该方法的主要创新在于利用不同膨胀率的空洞卷积,获得不同尺寸的感受野,同时使用Inception结构来融合多尺度的特征.同时,也使用了3个子网络来学习3种不同模态.最后的特征为多模态的互补信息和多尺度的上下文信息的融合.
月龄为6~8个月的婴儿,白质和灰质在MRI的T1像和T2 像中会表现出相近的信号强度水平,因此组织对比度差,分割困难.Nie等[41]针对6~8个月健康婴儿的T1像、T2像和弥散加权像3种影像模态,对于每个模态采用一个单独的FCN网络进行训练,然后将高层特征融合在一起,以进行最终分割.结果表明,该模型在准确性方面明显优于使用普通FCN的方法.后续的研究中,Nie等[42]进一步将语义网络从二维FCN扩展到三维FCN,并通过使用整合上下文语意信息、融合不同尺度特征等方法进行网络优化,取得了更优的结果.
2.3 脑区分割
脑区分割中的一部分研究旨在将整个大脑分割成多个脑区.而另一部分研究则集中在分割一个或多个特定的脑区结构.以在人类记忆中起着重要作用的海马区为例,其萎缩已被证明是一种预测轻度认知障碍、阿尔茨海默病及记忆相关的神经系统疾病的生物标志物.由于海马区结构尺寸小、形态复杂,从神经影像中准确地分割海马子区是一项颇具挑战性的任务.Shi等[43]提出了一种使用生成对抗网络在脑MRI中进行海马子区分割的方法.生成对抗网络不需要大量有标注数据就可以学习深度表征[44-45].该模型由2个主要部分组成.一部分是通过对U- Net进行改进获得生成网络,其被训练用于对二维的MRI切片进行语义分割.另一部分是基于CNN的对抗网络,被用来区分专家注释和生成网络生成的分割图像.生成网络和判别网络的互相博弈学习来产生符合需求的输出.该模型在海马和较大海马子区的分割中均获得了很高的准确性.现有的海马子区分割方法一般是基于成人受试者设计的.Zhu等[46]提出了一种U- Net扩张密集网络来进行婴儿海马子区域分割.嵌入式扩散密集网络可以在保持高空间分辨率的同时生成多尺度特征,这有助于将收缩路径中的低级特征与扩展路径中的高级特征融合.为了进一步提高性能,他们在每对卷积层与U- Net扩张密集网络间加入一个残差连接,获得了残差U- Net扩张密集网络.与三维U- Net相比,该网络性能上有一定提高.纹状体是大脑基底神经节之一,其主要机能为调节肌肉张力、协调各种精细复杂的运动.如纹状体受到损害,则其功能发生障碍.Shakeri等[47]采用 FCN网络对纹状体皮层下结构(丘脑、尾状核和苍白球等)进行了分割,并在输出端设计了马尔可夫随机场对分割结果进行优化改进.实验结果显示该模型优于Freesurfer等最先进的自动脑区分割工具.
2.4 脑部病灶分割
脑损伤的定量分析包括测量脑损伤区域,以及量化脑疾病的病灶区大小.脑卒中是脑疾病患者长期残疾或死亡的主要原因之一,其中脑缺血导致了大约80%的脑卒中[48]的发生.扩散加权MRI对急性病变的检测和定量对缺血性脑卒中的诊断和治疗具有重要意义.Chen等[49]提出了一种由2个子网络构成的急性缺血性病变分割系统.第1个子网络的输入为图像块,由多个并行的DeconvNet结合[50]输出具有语义描述的分割概率图,并通过对概率图进行阈值分割来得到急性缺血性损伤病变区域和假阳性区域.第2个子网络使用概率图和原始图像为输入,对检测结果进行重新评估,排除假阳性误报.结果显示该网络可以比FCN、U- Net和Deeplab提供更优的分割结果.
神经胶质瘤是成人最常见的脑肿瘤,占所有原发性脑肿瘤的40%左右,肿瘤分割对脑癌的诊断和预后具有重要意义.神经胶质瘤通常具有很强的浸润性,存在边界模糊和对比度差的特点.Cui等[51]使用多模态(T1像、T2像、T1像增强和水抑制像)脑肿瘤分割数据集,设计了一种级联的网络结构来实现对脑胶质瘤的自动语义分割.第1个网络为肿瘤定位网络,为一种FCN结构.2个跳跃结构被用于减轻局部图像特征的损失和融合中间层获得的局部信息与深层的全局信息.第2个网络为肿瘤内分类网络,将定义的肿瘤区域标记为多个肿瘤亚区.Wang等[52]提出了一种宽残差网络和金字塔池化网络的方法来自动分割脑胶质瘤.该方法主要分为3个大的步骤.首先,宽残差网络被用于从多模态影像提取脑肿瘤的关键表达特征.随后,金字塔池化网络被用于提取不同尺度的全局先验表达,并与宽残差网络的输出特征进行融合.最后,尺度恢复模块输出与输入图像一样大小的像素级的语义分割结果,该方法在脑胶质瘤分割上具有很好的分割效果.
3 讨论与结论
随着CNN技术的发展成熟,基于CNN的语义分割网络在神经影像领域相继取得了不少令人兴奋的成果,但它们还具有一定的局限性.首先,基于语义的深度网络在性能改进上很大程度会依赖于大规模影像数据集,而神经影像领域数据集相对较小,这制约了该类方法性能的进一步提升.对于较小数据集,存在2种形式的改进策略.一种是进行数据增强,如随机变换(如翻转、旋转、平移和变形)的方法.另一种是使用迁移学习,即用在大型数据集上预训练的网络,在小数据集上进行微调训练.其次,训练语义分割网络需要标签数据.因此,语义网络面临更严峻的问题是缺乏足够的专家标注影像数据.生成对抗网络是一种无监督的学习方式,降低模型对标签的依赖,是未来该领域研究一个可能的重要发展方向.最后,神经影像数据通常是三维或更高维度,现有的语义分割网络更多集中在二维.相比二维模型,三维模型需要更多计算代价,随着现代图形处理器技术的发展,该问题将会得到缓解.
对网络结构的改进也需要深入探索.编码- 解码网络具有简洁高效的优点,但在复杂多变的神经影像分割任务中,需要针对不同的任务特点进行改进.语义网络的最优设计往往需要设计者通过大量优化实验来获取.基于CNN的语义网络一般以链式结构为主体,中间可能存在部分的多叉结构.而这些结构往往是基本子结构的重复,通过这些子结构重叠拼接来形成总体网络.因此,对语义分割网络的结构优化可以被看成这些子结构的优化拼接.对网络结构进行编码,用强化学习的方法获得最优语义网络,是该领域发展的又一方向.
目前,基于CNN的语义分割已成为神经影像研究领域的一项重要的工具,其广泛的应用领域和良好的实践效果已日益受到了国内外学者关注.但该领域目前还处于高速发展阶段,在方法改进方面还有不少余地.预计未来几年该方法在神经影像研究中将取得重大进展,具有更光明的前景.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
开放教育研究(2020年2期)2020-03-31 01:54:14
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
中国组织化学与细胞化学杂志(2017年1期)2017-06-15 20:27:42
中成药(2017年6期)2017-06-13 07:30:35
现代语文(2016年21期)2016-05-25 13:13:44
吉林大学学报(医学版)(2015年4期)2015-12-17 07:48:13
大连民族大学学报(2015年2期)2015-02-27 08:28:11
癌变·畸变·突变(2015年3期)2015-02-27 06:15:12
