
基于U-Net神经网络眼底图像的视盘分割研究
2021-01-15 02:11:04郭学东黄铭斌许祥丛杨旭伦陈允照
仪器仪表用户 2021年1期
曾 锟,郭学东,黄铭斌,许祥丛,杨旭伦,张 浩,陈允照,陈 勇
(1.佛山科学技术学院 机电工程与自动化学院,广东 佛山 528200;2.佛山科学技术学院 物理与光电工程学院,广东 佛山 528200)

图1 视盘视杯结构图Fig.1 Optic disc cup structure chart
0 引言
眼底图像中的视盘在青光眼筛查和诊断中起着重要作用,青光眼的早期发现有助于显著降低不可逆性视力丧失的风险[1]。青光眼通常会导致视盘形状、颜色和视网膜厚度发生变化,主要表现为视盘的中心亮区域(视杯)扩增,临床上最常使用的诊断指标是视盘视杯垂直比(CDR),简称杯盘比,越大的杯盘比预示着更大的青光眼患病风险;在实际临床判断中,眼底图像的杯盘比CDR大于0.65这一阈值常被判定为青光眼[2]。计算的杯盘比越准确,对青光眼眼部疾病的诊断筛查就越有利,而准确的杯盘比,依赖于眼底图像视盘的精确分割,因此,眼底图像视盘的精确分割极为重要。眼底图像视盘视杯结构图如图1所示。
在过去的传统方法中,Aquino等人[3]采用形态学边缘检测方法分割视盘边界,赵圆圆等人[4]使用基于水平集的CV模型约束边界梯度对视盘进行分割,赵晓芳等人[5]使用Sobel算子对视盘进行边缘提取,随后使用霍夫变换检测圆来获取视盘轮廓。这些方法实现简单,但由于每张眼底图像的亮度不一样,加上临床研究表明视盘是垂直高度比水平高度大约长7%~10%的近似椭圆[6],所以利用形态学、圆形霍夫变换等技术并不能精确地分割视盘,而且霍夫变换的计算量大,导致分割慢、效率低。
近几年,深度学习以其在计算机视觉和图像识别领域的卓越性能吸引了许多研究者的注意,越来越多的人将深度学习算法,特别是卷积神经网络(Convolutional Neural Networks, CNN),应用于医学图像的分析中[7]。Chen等人[8]使用以视盘为中心的图像块训练端到端的CNN网络用于青光眼的疾病诊断;Li等人[9]在青光眼诊断中,通过深度卷积网络提取图像全局与局部的特征,将全局与局部信息的诊断结果加权融合得出最终的诊断结果。不同于传统的图像分析算法,深度学习不需要人工选取图像的特征,深度模型可以自动从图像中学习解决问题的最优特征表达,深度网络有许多层,随着层数的增加,网络对输入图像不断提取高层特征并生成最后的输出结果,通过多次迭代降低输出的损失函数从而不断优化深度网络结构参数。由于将特征提取与网络的最终输出结果相关联,可以提取对疾病诊断有效的图像特征以达到更好的图像分析性能。因此,深度学习具有较强的基于数据的自主学习能力[10],并且随着越来越多深度网络的结构和优化算法被提出,深度学习的泛化性能也不断提升,最近在医学图像领域不断取得优异的成果[11]。在眼科图像分析领域,最近深度学习才被逐渐应用,大多数的工作集中在使用简单的 CNN网络进行彩色眼底图像的分析,主要应用在眼底结构的分割、视网膜损伤的分割和检测、眼疾病的诊断和图像质量评价。
本文提出了一种基于U-Net神经网络的层级式视盘自动定位方法,该方法结合机器学习,通过U-Net神经网络有效学习视盘区域的特征结构,并将显著图与卷积网络有机结合,而且通过多层卷积能够减少图像亮度的差异,在快速定位视盘的同时也兼顾了定位结果的准确率。相对于传统的视盘分割方法,提高了分割的精确度,而且分割耗时更短。
1 方法
本文的视网膜视盘分割的方法流程大致如下:
1)数据集的获取。
2)对原始眼底图像进行人工分割标记视盘,然后对人工标记视盘的眼底图像和原图进行各种预处理操作,以便于后面的机器学习操作。
3)使用深度卷积神经网络对人工分割标记好的眼底图像进行训练、测试,以获取输入眼底图像的视盘特征结构。
4)结合经过训练、测试获取的视盘特征对眼底图像进行视盘位置的预测,最后得出相应的视盘分割结果图。
视网膜视盘分割方法流程图如图2所示:

图2 视网膜视盘分割方法流程图Fig. 2 Retinal optic disc segmentation's flow chart
1.1 眼底图像预处理
由于采集后的眼底图像比较容易受到光照强度、噪声等多种外界因素的干扰,从而增加了视盘定位和分割的难度[12]。为了让视盘的特征结构更加突显,所以在眼底图像进行训练之前,很有必要对视网膜眼底图像(标签图和原图)进行一系列的预处理操作。对眼底图像进行归一化和增强主要是想达到两方面的目的:第一解决光照强度不均匀带来的影响,第二是凸显视网膜视盘的特征结构。而对眼底图像进行滤波则有助于去除任何易受影响的噪音,同时保持边缘和使图像的对比度及亮度值进行了修改,以增强梯度变化和视网膜视盘边界特征。
1.1.1 图像归一化增强
为了解决眼底图像的光照不均匀问题和增强图像对比度,所以需要对眼底图像进行归一化增强处理。归一化处理公式为
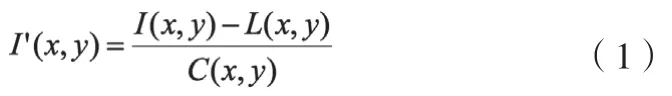
其中,I(x,y)为输入的视网膜眼底图像;L(x,y)和C(x,y)分别为像素点(x,y)的光照强度漂移因子和对比度漂移因子;I'(x,y)为进行归一化处理后的眼底图像。
1.1.2 滤波
各种滤波方式对不同性质的噪声有着不同的滤波特性[13]。实际滤波时,由于图像往往会受到两种不同性质噪声的同时干扰,因而单独采用高斯滤波或中值滤波都不会达到最好的去噪效果。为了能同时对两种不同性质的噪声进行滤除,现提出了一种新的混合滤波算法,该算法首先对受高斯噪声污染的像素采用高斯滤波算法进行滤除去噪,而对受椒盐噪声污染的像素则采用中值滤波算法进行去噪。经过实验结果证明,该方法更具有实用性和有效性。
均值为零的二维高斯函数如式(2)表示:
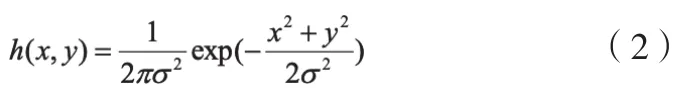
式(2)中,σ表示高斯函数的标准差。
1.2 U-Net神经网络
本研究采用U-Net网络作为本论文的网络体系,使用深度卷积神经网络对人工分割标记好并且经过预处理的眼底图像进行一定迭代次数的训练、测试,通过深度卷积神经网络有效学习视盘区域的特征结构,以获取输入眼底图像的显著图。
U-Net的网络体系如图3所示,U-Net通俗来讲是全卷积神经网络的一种变形,主要其结构经论文作者画出来形似字母U,因而得名U-Net。U-Net与其他常见的分割网络有一点非常不同的地方:U-Net采用了完全不同的特征融合方式——拼接,U-net采用将特征在channel维度拼接在一起,形成更厚的特征。而FCN融合时使用的对应点相加,并不形成更厚的特征。

图3 U-Net网络体系Fig.3 U-Net network structure
网络架构中有两条路径:收缩路径(左侧)和扩展路径(右侧)。收缩路径主要是用来捕捉图片中的上下文信息,而与之相对称的扩展路径则是为了对图片中所需要分割出来的部分进行精准定位。每条路径由4个块组成。在每个块中有两个卷积层,其核大小为3×3,并且在每次卷积运算后都有一个校正的线性单元(RELU)。然后,将步幅为2的2×2最大池化层添加到收缩路径,并将2×2上卷积层添加到扩展路径。快捷方式连接被添加到具有相同分辨率的层,从收缩路径到扩展路径,以提供高分辨率特征。在扩展路径之后,使用1×1卷积层将特征映射到对应于背景、视盘的2通道概率图。对于每个像素,选择概率最高的通道作为分割结果。而为了能使网络结构能更高效的运行,结构中是没有全连接层,这样可以很大程度上减少需要训练的参数,并得益于特殊的U形结构可以很好地保留图片中的所有信息[14]。
本网络选择比较常用的ReLu作为激活函数,ReLu解决了梯度消失的问题,而且计算速度和收敛速度快,另外减少了参数的相互依存关系[15]。ReLu函数公式为
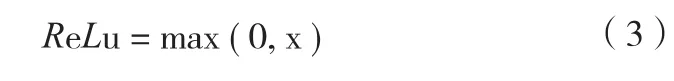
为了避免过拟合[16],在1×1卷积层之前插入了退出层。在训练阶段,只有一半的单元被随机保留以将特征馈送到下一层,而在测试阶段,所有单元都被利用来生成分割。通过避免在每个样本上训练所有单元,通过防止训练数据上的共同适应,降低了过拟合的机会。
1.3 眼底图像预测
经过卷积神经网络对眼底图像进行一定迭代次数的训练、测试后,结合训练、测试获取的视盘特征对眼底图像进行视盘位置的预测,最后得出相应的视盘分割结果图。
2 实验结果
2.1 数据集
在本研究中的数据集是百度研究院从实际使用案例中收集的,并且具有行业规模和质量的免费提供于研究和个人使用的数据集。数据集是由两个不同的眼底照相机获取的,其中用于训练的是由蔡司Visucam 500(2124×2056像素)获取,用于验证和测试的是由佳能CR-2(1634×1634像素)获取,所有数据集加起来一共有1200张彩色眼底图片,正常与病变的眼底图像比例为1:1,并且将数据集按1:1:1比例分为3个子集,分别用于训练、验证和测试。
2.2 评价标准
接受者操作特性曲线(Receiver Operating Characteristic Curve,ROC):为了更直观地看出视盘的分割性能,在分类结果上计算对应的敏感度和特异度并绘制相应的ROC曲线,ROC曲线的横坐标为假阳性率(FPR,1-Specificity),纵坐标为真阳性率(TPR,也称为Sensitivity),其中敏感度(Sensitivity,SEN)又被称作真阳性率,是指被正确判定为视盘区域像素占实际视盘区域像素的百分比;特异度(Specificity,SPE)又被称为真阴性率,是指被正确判定为背景区域像素占实际背景区域像素的百分比。最后,根据ROC曲线计算曲线下面积(Area Under Curve,AUC)作为评估视盘分割性能的重要指标,越大的AUC代表更优的分割性能。敏感度和特异度的计算公式为
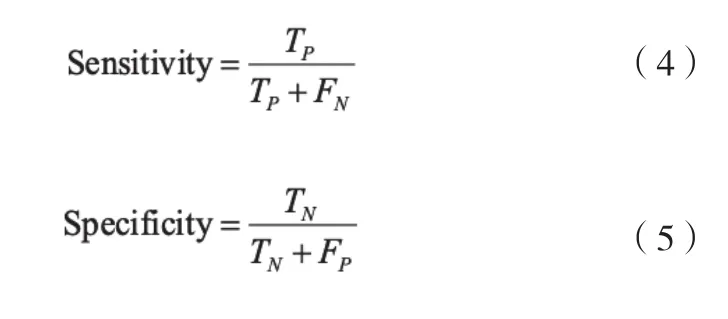
其中,TP为真阳性,指分割正确的视盘像素个数;TN为真阴性,指分割正确的背景像素个数;FP为假阳性,指分割错误的视盘像素个数;FN为假阴性,指分割错误的背景像素个数。
2.3 正常视网膜实验结果
正常视网膜分割实验结果如图4所示。
正常眼底图像的杯盘比CDR为0.230。
由图4(a)可以看出,原图首先经过预处理后,能较好得到图片的边缘信息,对可能是视网膜视盘的区域进行分割;由图4(b)可以看出本论文的方法成功实现了对正常视网膜视盘的分割;由图4(c)和杯盘比可以看出,视盘分割的准确率比较高。
2.4 病变视网膜实验结果
病变视网膜实验结果如图5所示。
病变眼底图像的杯盘比CDR为0.707。

图4 正常视网膜视盘分割结果图Fig. 4 Segmentation results of normal retinal optic disc

图5 病态视网膜视盘分割结果Fig.5 Segmentation results of pathological retinal optic disc
由图5(a)中可以看出,原图首先经过预处理后,能较好得到图片的边缘信息,对可能是视网膜视盘的区域进行分割;由图5(b)可以看出本论文的方法成功实现了对病变的视网膜视盘的分割;由图5(c)和杯盘比可以看出,视盘分割的准确率比较高。

图6 本文视盘分割ROC曲线图Fig.6 This paper presents ROC curve chart for optic disc segmentation
2.5 ROC曲线
本文提出的视盘分割方法的ROC曲线如图6所示。
由图6可以看出,本文提出的视盘分割方法具有良好的分割性能。
2.6 结果对比
本文提出的视盘分割方法与传统的视盘分割方法对比见表1。
从表1可以看出,本文方法分割平均准确率为98.9%,相对于传统的视盘分割方法,本文的U-Net神经网络能够有效学习有利于分割视盘的特征,从而提高分割的精确度,而且分割耗时更短。
3 讨论
本文提出的视盘分割方法适用于数据量比较大的视盘分割,使用U-Net神经网络对人工分割标记好的眼底图像进行迭代的训练、测试,通过深度网络能够有效学习有利于分割视盘的特征,以获取输入眼底图像的视盘特征结构,从而提高分割的精确度,而且分割耗时更短。而本文的方法不适用于数据量比较小的视盘分割,因为数据量比较小,视盘特征结构的信息量比较小,以至于神经网络对输入眼底图像的视盘特征结构的获取不够精确,导致分割的精确度降低。
4 结论
本论文根据视网膜视盘在青光眼筛查和诊断中起着重要作用的情况提出了一种基于U-Net神经网络的视盘分割的方法。为了验证所提分割方法的有效性,从原始图像中先对其进行人工分割标记视盘位置,并对进行人工分割好的眼底图像进行一系列的预处理操作;然后,利用U-Net神经网络对经过预处理的视网膜图像进行迭代的训练、测试,以获取有利于视网膜视盘分割的特征结构模型;最后,根据获取的特征结构模型,对正常和病变的眼底图像进行预测视盘的位置。该实验平台采用 spyder(python 3.7)进行仿真,由实验结果可知,该方法成功实现了对正常和病变的视网膜视盘的分割,而且分割的准确率比较高。本文研究的基于U-Net神经网络的视盘分割方法在青光眼筛查和诊断中起着重要作用,使青光眼得到早期发现,有助于显著降低不可逆性视力丧失的风险。不足的是U-Net神经网络训练的数据集较少,预测的时候会把背景的少数面积错误预测为视盘。

表1 视盘分割平均准确率与每张图片处理时长对比Table 1 The average segmentation accuracy of optic disc was compared with the processing time of each image
猜你喜欢
国际眼科杂志(2023年3期)2023-04-15 15:59:29
中老年保健(2022年3期)2022-08-24 02:57:52
现代仪器与医疗(2022年2期)2022-08-11 09:53:56
基层中医药(2021年6期)2021-11-02 05:46:04
中医眼耳鼻喉杂志(2021年1期)2021-07-22 07:38:28
中医眼耳鼻喉杂志(2021年2期)2021-07-21 08:53:34
眼科学报(2021年6期)2021-07-18 02:06:02
临床眼科杂志(2021年2期)2021-05-26 03:26:38
中医眼耳鼻喉杂志(2018年1期)2018-04-10 02:54:56
湖南中医药大学学报(2016年1期)2016-12-01 04:08:18
