
基于YOLOv3的军事目标检测算法改进
2021-01-15 09:22张奔贾婧王伟
网络安全技术与应用 2021年1期
◆张奔 贾婧 王伟
基于YOLOv3的军事目标检测算法改进
◆张奔 贾婧 王伟
(北方自动控制技术研究所 山西 030006)
YOLOv3目标检测模型预设的anchor boxes是在VOC数据集上采用K-means聚类算法得到,并不适用于本文研究的巡飞弹对地目标侦察的使用场景。同时,K-means聚类算法在训练数据集上无法得到稳定的最优解。本文通过改进聚类算法,并对军事目标数据集重聚类后,更新anchor boxes数据。训练模型后的avg-IOU和loss曲线表明,改进算法使模型更快速地收敛,同时能够获得更高质量的目标检测结果。
YOLOv3;k-means;军事目标;重聚类
巡飞弹在执行作战任务的过程中,对地目标侦察是非常重要的一个环节[1],而YOLO系列目标检测模型在实时目标检测领域具有优秀的性能[2]。基于特征描述子的方法设计局部纹理特征,然后进行全局特征目标检测[3]。后续基于深度神经网络的方法有R- CNN,在此基础上又发展出了Fast R-CNN、Faster R-CNN等[4]。本文通过对均值聚类算法的研究,改进K-means算法,从而提高聚类结果稳定性,改善模型训练过程和目标检测效果。
1 YOLOv3目标检测算法
YOLOv3算法首先通过特征提取网络Darknet53对输入图像提取特征[5],得到图像对应的特征图,大小比如13×13,然后输入图像可以被认为分成了13×13个grid cells,接着如果真实图像中某个目标的中心坐标落在哪个grid cell中,那么就由该grid cell来预测该目标。每个grid cell都会预测3个边界框,并给出相应的objectness score。最后通过非极大值抑制算法排除冗余的预测候选框,完成对图像中目标的检测。如图1所示,网络在每个Cell上会预测3个边界框,其中每个边界框会用5个预测值表示,分别是:,tx,ty,th,tw,to,其中前四个是边界框坐标的offset值,最后一个是置信度。如果预测边框的中心点距离对应Cell左上角的边距为(cx,cy),而采用k均值算法得到的边界框先验维度(Bounding Box Prior)的高与宽分别为(ph,pw),则预测边框的实际值见下图1:
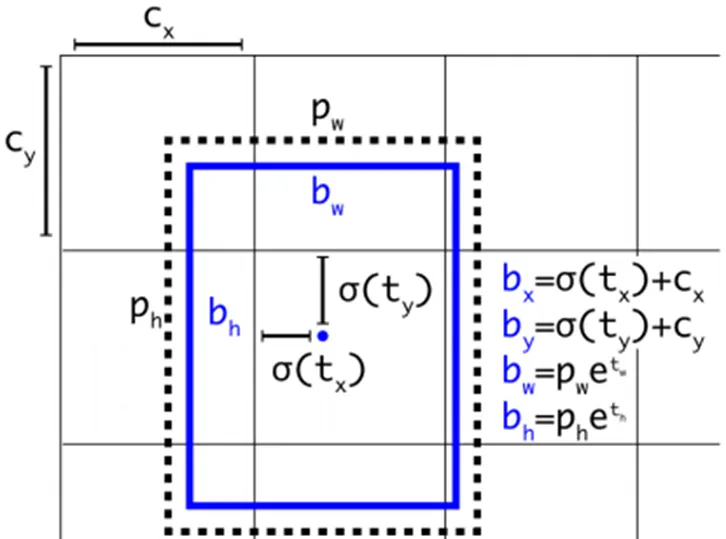
图1 YOLOv3预测框计算
YOLOv3的损失函数为:

损失函数分别表示定位损失、置信度损失和分类损失,从函数的定位损失部分可以看出:在训练的过程中,实际求得的是网络预测值与聚类得到的anchor boxes值之间的偏移值。因此,改善聚类算法,使之得到稳定的最优解并且针对特定训练数据集做重聚类,能够改善模型的收敛状况,获得更佳的识别效果。
2 K-means聚类算法
YOLOv3目标检测模型使用K均值聚类算法对voc数据集进行维度聚类,得到9个不同长宽比的anchor boxes ,以此代替配置文件中采用的原Faster R CNN中人为设定的anchor值[6]。
K-means聚类分析是利用数据的相似性,对聚类数据集进行划分[7]。其数据类别相似性指标一般采用欧式距离。对数据集划分成k个预先设定的类别,使每个类别所包含的数据点最为相似且不同类别之间的数据差异尽可能最大化。假设数据集X包含n个m维的数据点,相似性指标采用欧式距离分成K个类别,则各类包含数据点的聚类平方和最小时,达到聚类目标:

K-means通过多次迭代得到最终的k个聚类中心,算法流程如下:
(1)随机产生k个分别代表一个聚类中心的初始质心;
(2)对每个数据点对象都计算与各个初始质心的欧式距离,以最小距离为标准进行归类;
(3)对每个类别中所有属于该类的数据点位置统计计算,得到新的质心;
(4)重复2、3步骤,直到各个类别的质心不再改变,从而得到最终的聚类结果。
K-means这种采用贪心算法的聚类思路,前提是需要人为指定k值。从相关的仿真实验中可以看出,采用K-means算法对数据集多次聚类,聚类结果有较大差异性,很难得到稳定的最优解。
3 K-means聚类算法改进
针对上述问题,对K-means聚类算法的改进集中在选择相互衡量指标尽可能大的点作为初始质心,改进算法的流程如下:
(1)随机选择数据集中的一个数据点作为第一个聚类中心;
(2)计算每个数据点与其最近的聚类中心之间的距离d(x),统计得到距离累加结果sum(d(x));
(3)随机采用一个阈值,若累加后的种子点距离高于阈值,则设为下一个种子点,然后尝试更新选择作为聚类中心的数据点,选择包含数据较多的点,被选中作为新的聚类中心的概率应较大;
(4)重复2、3步骤,直至选出k个初始质心;
(5)执行K-means算法,得到最终聚类结果。
目标检测的图像数据集,采用矩形框来人工标注图像中的目标。大小不同的矩形框做聚类时,若采用欧式距离,会产生较多的损失误差。聚类的目的是要获得相对于所有矩形框而言更高的交并比得分,而这个分数实际上是与矩形框的大小没有关系,所以改进算法所采用的聚类标准为IoU距离公式:

4 实验
4.1 实验数据集
实验图像数据采用模拟器生成,以巡飞弹对地侦察目标为应用背景,采集空中俯视角度下的自行火炮、军用卡车、军用吉普车3种军事目标图像资料。模拟图像的尺寸为1920×1080,其中目标所占像素点分布在50×50到300×300之间。整个军事目标数据集包含2191张图片,其中包含目标:自行火炮6436辆,军用卡车1998辆,军用吉普车3009辆。数据集按照4:1的比例分为训练集和验证集。使用标图软件对上述3种类别的目标全部进行标记,生成2191个xml文件。
4.2 实验环境
实验环境:操作系统为ubuntu16.04;中央处理器为;GPU为GTX2080TI;GPU加速库:CUDA10.1、CUDNNv7.5.6、OPENCV-3.4.4;编程语言为Python2.7、C++语言。深度神经网络的配置参数如表1所示。

表1 训练配置文件主要参数设置
4.3 实验方法
按照K-means算法和改进聚类算法的流程,分别编写两个python脚本文件,将聚类K值设定为9,在ubuntu系统的终端下分别运行,得到聚类结果。由于YOLOv3的特征提取网络对输入图像进行32倍下采样,故聚类得到的9对高宽比需要乘32后写入到训练配置文件中才能正确应用。
K-means算法和改进聚类算法分别对军事目标数据集聚类得到anchor boxes,保持模型的其他参数一致的情况下,分别采用两种聚类方法得到的anchor boxes对模型进行训练,对比实验结果。
4.4 实验结果
如图2所示,黑色矩形图标表示VOC数据集下聚类得到的anchor boxes,红色图标表示采用K-means算法对军事目标数据集进行10次聚类后的结果,可以看到,聚类的结果并不稳定。
采用改进聚类算法对军事目标数据集进行10次聚类,结果稳定,最后的聚类结果为:0.43、1.11、0.71、0.79、2.07、1.10、1.18、1.33、3.23、1.75、1.78、1.94、5.24、2.75、2.76、3.79、4.57;平均IoU为0.733485。随机选取K-means算法的一组聚类结果:0.49、0.87、0.67、1.75、0.94、0.92、1.11、2.59、1.57、4.15、1.61、1.63、2.35、5.63、2.62、2.59、3.83、4.18;平均IoU为0.729859,分别乘32后写入配置文件进行训练,实验结果如图3、4、5所示。

图2 聚类结果对比
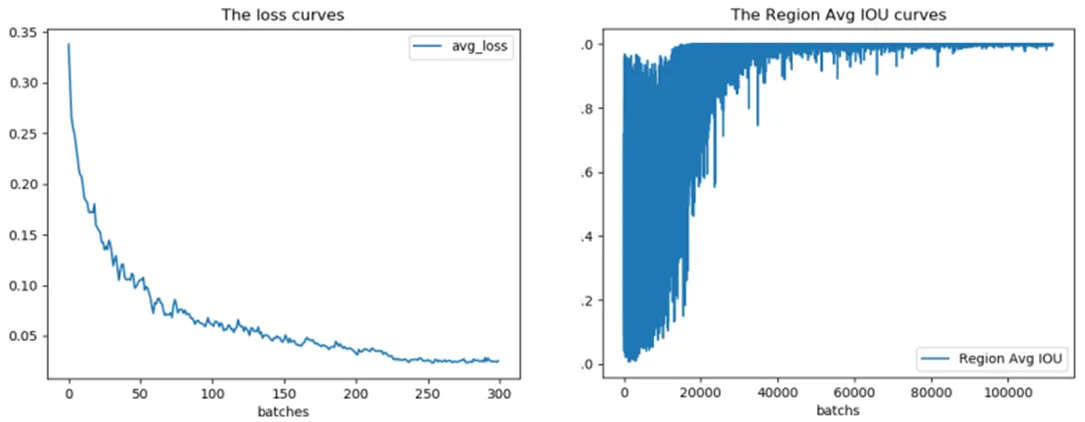
图3 K-means算法训练loss和Avg IOU曲线

图4 改进算法训练loss和Avg IOU曲线

图5 采用改进算法(右)聚类结果的识别效果对比
采用改进聚类算法结果的模型相比K-means算法,在反映模型训练过程的loss和Avg IOU曲线图中都有更好的表现,识别效果图中也可以看出对目标的标记更加精准。
5 结语
本文研究了YOLOv3算法中对训练数据集进行聚类分析的算法,针对聚类得到的anchor boxes对模型神经网络训练的影响作用,做了针对性的改进。对比实验结果表明改进算法能够得到稳定的聚类结果,并且对网络训练的收敛情况有明显的提升,同时最后模型的目标检测效果也有所改善。
[1]郭美芳,范宁军,袁志华.巡飞弹战场应用策略[J].兵工学报,2006,27(5):944-947.
[2]Redmon J,Divvala S, Girshick R, et al.You only look once: Unified, real-time object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition.2016:779-788.
[3]Dalal N,Triggs B. Histograms of oriented gradients for human detection[C]. Computer Vision and Pattern Recognition.2005:886-893.
[4]邢志祥,顾凰琳,钱辉,等.基于卷积神经网络的行人检测方法研究新进展[J].安全与环境工程,2018,25(6): 100-105.
[5]Redmon J,Farhadi A. Yolov3:An incremental improvement[J]. arXiv preprint arXiv:1804.02767,2018.
[6]苏飞.高维数据的聚类分析研究与应用[D].华北水利水电大学,2017.
[7]田潇潇.基于多分类的主动学习改进算法[D].河北大学,2017.
猜你喜欢
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
作文小学中年级(2020年6期)2020-07-24
铁道通信信号(2019年6期)2019-10-08
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
自然资源遥感(2014年3期)2014-02-27
意林(2011年10期)2011-05-14
中学英语之友·上(2008年2期)2008-04-01
中学英语之友·上(2008年2期)2008-04-01
