
一种操作系统函数级安全监控方案
2021-01-15 08:23:02孙书彤王祥武蔡立志
计算机应用与软件 2021年1期
孙书彤 王祥武 蔡立志
1(中国银联股份有限公司 上海 201201) 2(中国海洋石油集团有限公司 北京 100010) 3(上海计算机软件技术开发中心上海市计算机软件评测重点实验室 上海 201112)
0 引 言
近年来,随着软件的规模和复杂度的日益增大,软件漏洞挖掘技术正逐渐向自动化和智能化演变。传统漏洞挖掘技术包括模型检测、二进制比对、模糊测试、符号执行以及漏洞可利用性分析等。机器学习和深度学习技术在漏洞挖掘领域也有应用,包括二进制函数识别、函数相似性检测、测试输入生成、路径约束求解等,但存在机器学习算法不够健壮、样本数据不足、算法和特征选择过度依赖经验和专家知识等问题。
此外,也有利用如Digtool之类的工具进行系统层面漏洞挖掘的方法。Digtool运行后自动记录内存访问等行为,进行路径探测,并尽量引导执行更多的路径;Digtool 会进一步分析,一旦发现符合主要的一些漏洞行为特征规则,就意味着找到一个漏洞。
这些方法都是针对某种局部特征或局部环境进行分析比对的。更重要的是,这些方法都是运行在一种模拟环境中,而非实际运行环境[1]。
本文提出一种新的研究思路和实现方案,专门针对操作系统内核中的漏洞进行识别、挖掘和自动封堵,在已知源码的前提下,能够自动识别和自动封堵操作系统内核中的几乎所有控制转移型漏洞[2-3]。
从运行轨迹角度上看,操作系统内核级漏洞可以分为控制转移型漏洞和非控制转移型漏洞两种。前者是指能够导致系统运行控制发生转移,从而完全脱离原始设计的运行轨迹,去执行入侵的代码或其他超越权限的代码的漏洞;后者是指不会导致系统的运行轨迹发生转移,仅仅能欺骗系统,使之放行的漏洞,如:验证口令、加解密等函数或流程方面的漏洞[4]。
非控制转移型漏洞范围集中,代码量小,易于研究和消灭。现实中这类漏洞也较少发生,故本文中不再考虑这类漏洞。本文中研究的漏洞是指控制转移型漏洞。这些漏洞范围广泛,能够导致系统运行失去控制,去执行入侵的代码或其他超越权限的代码,是目前漏洞威胁的主体。
本文提出的方案是:通过改造源代码,将操作系统代码中的函数进行函数名标签化,对每个函数增加记录该函数运行时的调用序列和上下文关系的一段极小通用代码,监测任何控制转移型漏洞的发生,进一步追踪、定位、分析漏洞,也可以阻塞漏洞代码的运行[5]。
1 基本思路和实现方案
在已知源代码的前提下,以函数为基本单位看待操作系统,整个系统的运行过程可以看作一个由这些函数互相调用构成的运行序列。这个运行序列是完全由源代码决定的,在运行过程中,除非发生漏洞入侵或bug,否则不可能出现函数脱离既定序列运行的情况。反之,通过漏洞入侵本系统的代码,不可能不改变原来的运行序列,也不可能不调用操作系统的固有函数。据此,通过将代码中的所有函数进行改造,增加调用者信息和调用序列检查功能,可以实时发现函数脱离原来既定序列运行的情况。这种情况一旦发生,即可自动阻塞执行,并报告发生脱序运行的“拐点”函数名称,所在源代码的文件名、行号等精确信息,为操作系统的运行安全增加了一种可靠的保护机制[6-10]。
1.1 源代码自动变造技术
对代码进行词法分析,包括隐函数和虚函数的提取、识别和变造。
操作系统源代码均为C语言实现的。根据C语言的规范,所有代码都是由函数构成的,每个函数都具有统一的语法特征和词法特征。因此通过对源代码的语法分析,可以提取所有函数,并自动改造每个函数,插入函数级监控和分析代码。
1.2 函数调用关系序列的分析和描述
从源代码中,可以确定函数之间的调用关系和调用上下文。虽然一个函数可以被多个函数调用,一个函数也可以调用多个函数,包括递归调用,但是每个调用必然是在源代码中明确定义的。从代码中可以很容易地确定任何函数的调用者列表和被调用者列表,以及调用序列表。这样可以建立一个以函数名为索引的调用关系表。
一个操作系统中所有函数个数大致在十万数量级以上,每个函数的平均调用者个数和被调用者个数在100以内,所以整个调用关系库的大小应该在4 MB左右,而且恒定不变,完全可以永久性地放在内存中供函数调用时实时比对和验证分析,不会影响系统内存占用。
1.3 函数调用监控技术
通过改造每个函数,在函数头部插入一小段代码,比对该函数的调用者和调用上下文与调用关系库中是否一致,可以判断出对该函数的调用是否合法,进而确定是否有漏洞的存在。再通过全息日志,分析漏洞成因,同时可以阻塞函数的运行,确保它们不造成危害。
由于函数名已被标签化为整数,可以直接作为查找索引去查询调用关系库,因此是一个直接定位、无须加锁的全内存操作,相当于每个函数多运行几十条指令而已,故对系统运行效率影响极小。
2 核心技术
2.1 源代码函数调用关系图、关系表生成
以源代码文件为对象,从所有源代码中识别和提取出所有函数,包括隐函数、虚函数,形成函数描述表,描述每个函数的详细调用序列关系和调用上下文。
操作系统源代码一般由C语言编写,对源代码文本进行语法分析和词法分析,识别和提取其中所有的函数,详细步骤如下:
① 遍历源代码所有文件,包括头文件和.c文件,去掉其中所有注释信息,以便简化后继分析。注释信息中通常包含文字或代码等信息,容易带来语法分析和词法分析的困扰。
② 逐一遍历所有文件,根据C语言函数的语法分析,标定所有函数的函数名、函数参数、函数起止位置。
③ 对所有标定的函数名统一进行标签化,即对每个函数重新命名,命名为统一代号的标签化函数名,这样做一方面可以保证不会发生重名现象,比如函数名和变量名重名,另一方面是为后继查询提供了快速定位索引信息,流程如图1所示。
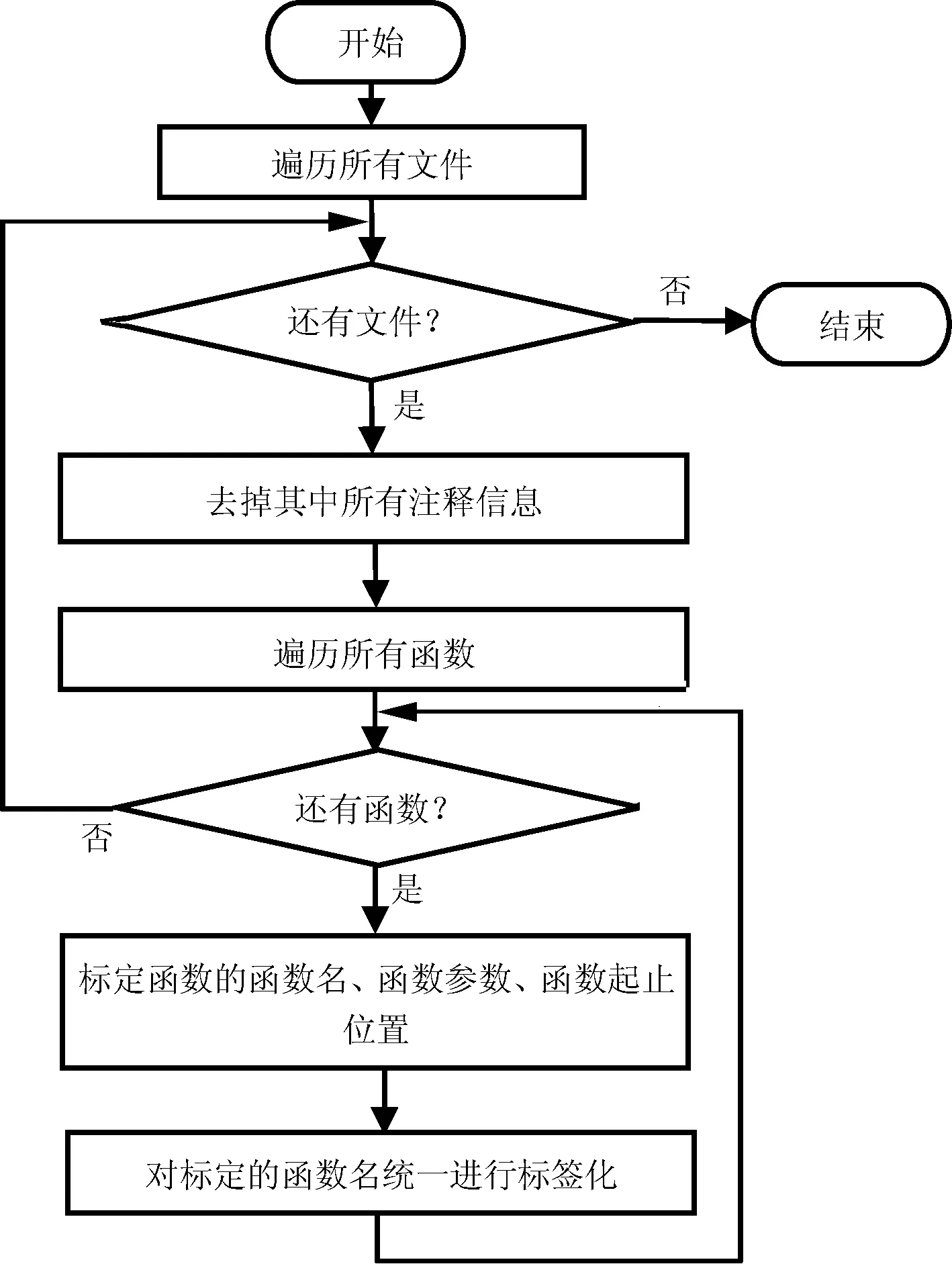
图1 函数标签化流程
④ 经过上述三步处理后的源代码文件,所有函数均已标签化、清晰定位、语法分析和词法分析阶段已经完成。接着,统计所有函数的调用关系,生成函数调用关系库。具体方法是遍历所有文件,根据每个标签函数名查找调用者和被调用者,将得到的所有信息索引化处理后,保存入库,流程如图2所示。
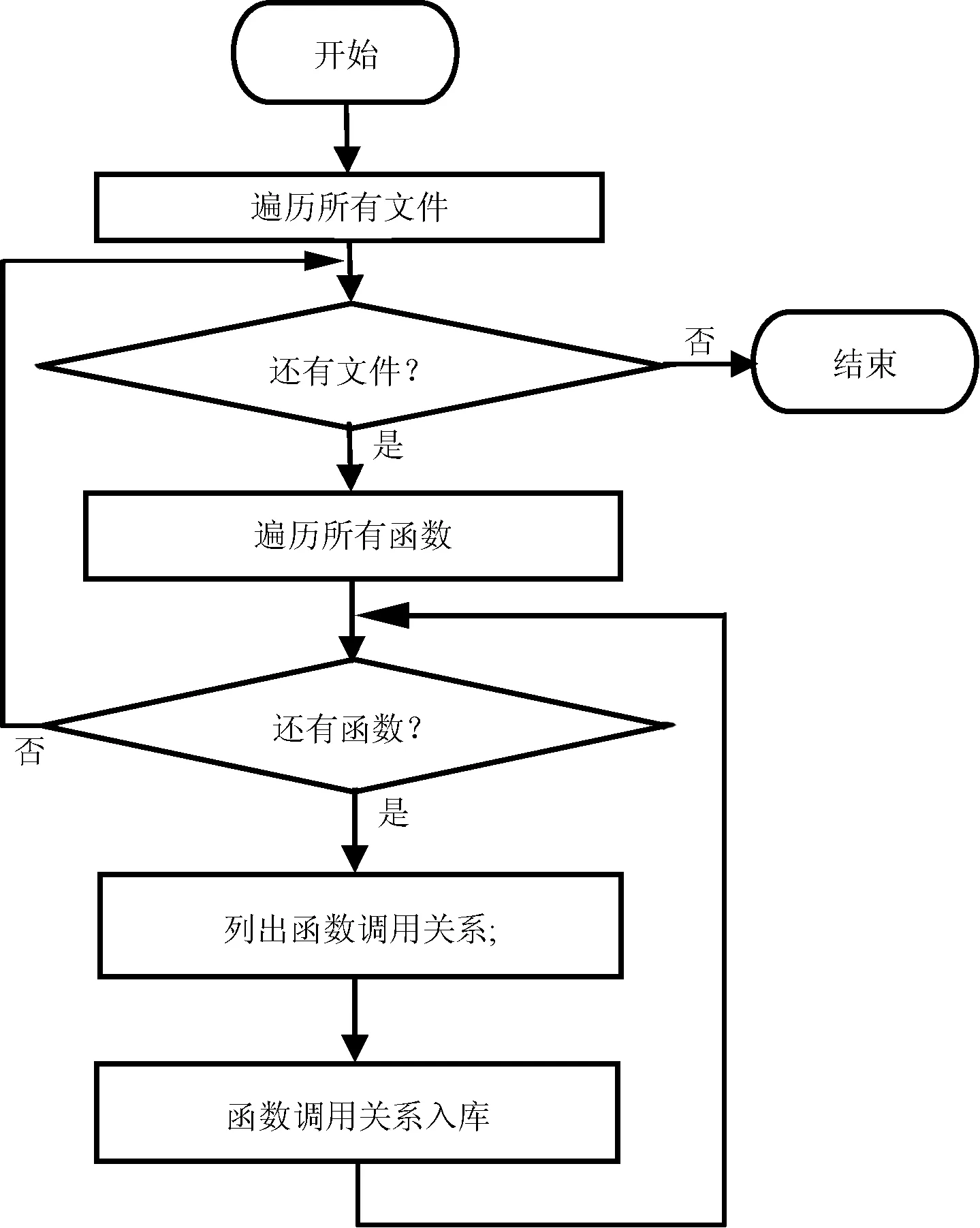
图2 函数调用关系入库流程
2.2 源代码函数变造
将每个函数进行源码变造,在保证不改变原始逻辑的前提下,增加三个参数和一条语句,用以描述函数运行时的调用上下文关系、调用序列关系验证等。
(1) 函数增加调用参数。除了main函数和其他标准函数,所有自行定义的函数均增加三个参数,分别用来表示调用者、调用者的上级调用者、调用发生的代码行。变造后的源码所有文件都有唯一的编号,这样,后继任何函数在执行中出现异常时,都可以轻松定位到源代码及调用上下文,便于区分漏洞和异常。
(2) 函数增加验证和日志语句。在代码中每个自定义的函数头部增加相同的处理语句,即把新增加的三个参数传递给公共的验证函数,验证函数将根据这三个参数进行验证,如发现脱序调用,即可阻止该函数的运行,并报告出错的函数及调用上下文。据此可以追踪出整个调用序列中的所有调用上下文,分析漏洞或异常的原因。
如图3所示,一个已标签化函数8344在被调用时传递三个参数:调用者函数序号,本函数所在文件号,行号。在执行时首先调用脱序检查函数RuntimeCheck,并返回脱序检查结果。

图3 源代码变造实例
2.3 运行时测试和函数追踪
(1) 函数级上下文日志。根据2.2节中描述的数据结构和算法,实现任意函数调用时,都会另外增加三个参数,用来指明本次调用的调用函数、上级调用函数、调用代码所在的代码行。每个函数被调用时,同时知道它的调用函数以及调用函数的调用函数,这就为函数调用序列的跟踪和验证提供了保证。
(2) 函数级调用存储。如前所述,任何函数发生调用时,根据调用参数信息可以进行调用序列验证和追踪分析。所有函数的调用序列关系是由源代码完全决定的。通过2.1节中描述的方法,得到如表1所示的函数调用序列验证数据库。
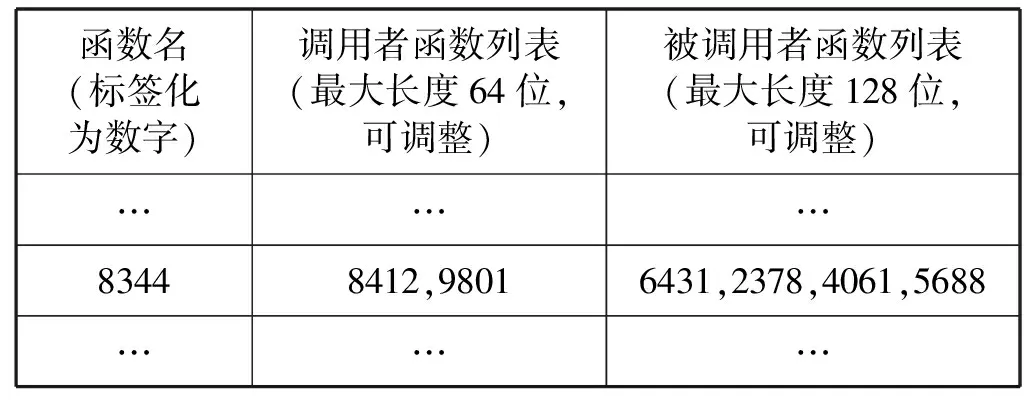
表1 函数调用关系数据库
在所有函数的最前面插入验证语句Runtime-Check(),在调用原函数逻辑功能前,都会调用一个公共的验证函数。验证函数在初始化时即装于验证数据库。该数据库的内容是描述代码中定义的所有函数的调用序列关系,因此是静态不变的。这就意味着可以公共访问,无须加锁。因此这个访问验证函数不会消耗太多的系统CPU,可以始终在线运行。
(3) 拐点函数的识别。当公共验证函数检测到任何函数脱序调用时,即可断定这里发生了漏洞或BUG,这时可以通过追踪调用序列,查找调用序列中发生拐点的函数,以进行漏洞分析,同时也可以直接阻止该函数的运行,确保漏洞不能被利用。
如图4所示,五列数据分别为函数号,调用者,所在文件号,行号,检查结果。一个已标签化函数8344返回了脱序检查结果,即函数被调用执行时,执行轨迹没有脱序。

图4 内核检查调用序列输出实例
3 方案实验效果
本方案改造的操作系统是Linux内核,数据库不到5 MB,运行可以监测到由外部输入触发的控制转移型的漏洞[11]。
4 结 语
经过本方案改造的操作系统内核,能够在函数粒度上进行全息跟踪和运行验证。本文方案能够自动发现和阻止利用本系统漏洞攻击成功的恶意代码,通过实现整个系统运行全过程的详细日志,为各类系统运行的安全提供可验证和追溯的轨迹数据。
猜你喜欢
计算机仿真(2023年8期)2023-09-20 11:23:42
电脑知识与技术(2021年33期)2021-12-17 00:50:31
现代信息科技(2021年21期)2021-05-07 21:44:50
商品与质量(2019年34期)2019-11-29 03:25:51
测控技术(2018年5期)2018-12-09 09:04:46
中国司法鉴定(2018年4期)2018-07-30 06:08:26
湘潭大学自然科学学报(2018年2期)2018-05-28 09:04:38
电脑知识与技术(2017年32期)2017-12-15 10:22:23
中国新通信(2017年1期)2017-03-08 03:12:21
信息安全研究(2016年4期)2016-12-01 06:07:05
