
密集连接扩张卷积神经网络的单幅图像去雾
2021-01-15 07:27刘广洲李金宝任东东舒明雷
计算机与生活 2021年1期
刘广洲,李金宝+,任东东,舒明雷
1.齐鲁工业大学(山东省科学院)山东省人工智能研究院,济南250014
2.黑龙江大学计算机科学技术学院,哈尔滨150080
雾是一种常见的大气现象,它是由空气中的水汽凝结物、灰尘、烟雾等微小的悬浮颗粒产生。由于光线在传播过程中与大量悬浮颗粒发生交互作用,光能被重新分布,使得雾天图像通常呈现模糊泛白、色彩饱和度下降、观测目标严重退化的现象,导致许多基于视觉的系统和任务性能急剧下降。
图像去雾是一种不适定逆问题,其目的是从退化图像中恢复高质量的无雾图像。尽管经过几十年的研究,但由于雾传播的位置变化和未知深度,使得图像去雾仍然是一个非常具有挑战性的任务。许多单图像去雾方法是基于经典的大气散射模型[1]。

其中,I(x)为退化的有雾图像;J(x)为无雾图像;A为全局大气光;t(x)为透射图;x为像素位置。
由式(1)可以看出,无雾图像的求解取决于透射图和大气光的估计。人们提出了许多方法来解决透射图和大气光的估计问题,主要分为基于手工先验的方法和基于学习先验的方法。基于手工先验的方法通过利用不同的先验知识来估计透射图,如暗通道先验、对比度先验和模糊先验等。基于学习先验的方法则是以数据驱动的方式对透射图和大气光进行估计。但这些方法都需要依赖于大气散射模型,透射图和大气光的估计精度对去雾图像的质量影响很大。
最近,一些基于卷积神经网络(convolutional neural networks,CNN)的端到端去雾方法被提出,这种方式直接通过CNN 恢复出干净的无雾图像,摆脱了大气散射模型的约束,从而获得更好的性能和鲁棒性。然而,目前的端到端去雾网络在以下几个方面还存在一定的局限性。
(1)空间上下文信息聚合:在图像去雾任务中,更大的感受野可以聚合更多的上下文信息,从而收集和分析更多的邻近像素间关系,有利于网络对图像内容的预测。增加感受野的经典方法是对图像或特征图进行下采样,进而获得多尺度信息。然而,下采样可能会丢失一些有用的细节信息,而上采样方法无法完全恢复这些细节。使用更大的卷积核或更多的卷积层也可以增加感受野,但会大大增加参数量和计算成本。扩张卷积同样也是一种常用的增加感受野的方法,可以在不需要增加计算成本的情况下聚合更多的上下文信息,并且不会损失空间分辨率。但当扩张率较大时,由于卷积核相邻两个单元的信息差异较大,会使去雾结果产生网格伪影,降低了扩张卷积的性能。因此,目前的去雾方法受自身方法的局限性,有效聚合多尺度特征信息的能力依然较弱。
(2)多阶段图像修复:由于自然场景下的环境复杂多变,导致雾的不均匀性和深度未知性,尤其当雾对图像的损坏程度严重时,去雾将变得更加困难,很难一次将雾去除干净,需要进一步将图像去雾分解为多个阶段。然而,现有的图像去雾方法多以并行或串行的方式堆叠多个卷积操作,层与层之间的特征传递是微弱的,忽略了各个特征图之间的特征联系,降低了复杂有雾场景下的去雾效果。
本文采用端到端的卷积神经网络直接恢复无雾图像,摆脱了大气散射模型的约束,从而获得更好的性能和鲁棒性。并针对目前卷积神经网络方法在图像去雾任务上的局限性,提出了一个密集连接扩张卷积网络(densely connected dilated convolutional neural network,DCDN)模型。首先,DCDN 通过密集连接不同扩张率的扩张卷积来聚合多尺度空间上下文信息,使网络在不增加参数量且不损失空间分辨率的情况下,增加网络的感受野,并且避免了扩张卷积带来的网格伪影。其次,由于雾分布的不均匀性,在一个阶段不容易完全去除雾,因此进一步将去雾网络分解为多个阶段,并在每个阶段都设计了一个可调节的损失约束,从而获得更精确的特征信息。图1 是本文方法对图像去雾的一个例子。
本文主要贡献如下:
(1)提出了一个端到端的图像去雾卷积神经网络,通过使用密集连接的扩张卷积,有效克服了目前方法在空间上下文信息聚合上存在的局限性,增强了网络对大尺度特征信息的聚合能力。

Fig.1 Example of image dehazing图1 图像去雾的一个样例
(2)将图像去雾过程分解为多个阶段,并在每个阶段使用侧输出来近距离约束损失,克服了雾从本质上带来的不均匀、深度未知的噪声对图像的影响。
(3)与已有方法相比,本文提出的密集连接扩张卷积神经网络,在合成数据集和真实数据集上都取得了良好的去雾效果。
1 相关工作
1.1 基于物理模型去雾
现有依赖于物理模型的去雾方法,主要分为基于手工先验和基于学习先验两类。这两类方法之间最显著的区别是,前一种类型的图像先验需手工制作,后一种类型的图像先验可以自动学习。
基于手工先验的方法:Tan[2]观察到无雾图像比有雾图像的对比度更高,从而设计了一个模型来最大化图像的对比度,用于图像去雾。He 等人[3]提出了一种用于估计透射图的暗信道先验方法,该先验认为无雾图像暗通道的局部最小值接近于零。Tang 等人[4]在一个回归框架中系统地研究了各种与雾相关的先验,以寻找用于图像去雾的最佳先验组合。Berman 等人[5]发现一个无雾图像的颜色可以很好地近似几百种不同的颜色,然后提出了一个基于此先验的去雾算法。虽然基于手工先验的去雾方法取得了良好的效果,但手工先验对室外无约束环境的鲁棒性较差,往往会向去雾图像中引入大面积伪影。
基于学习先验的方法:与基于手工先验的方法不同,基于学习先验的方法直接估计透射图或大气光,而不是依赖先验知识。Cai等人[6]提出了一种基于卷积神经网络(CNN)的端到端去雾模型DehazeNet,用于透射图的估计。Ren 等人[7]提出了一种多尺度深度模型来估计透射图。Zhang 等人[8]提出了一个单一的去雾网络DCPDN(densely connected pyramid dehazing network),共同学习传输图、大气光和无雾图像,捕捉它们之间的关系。然而,由于对透射图估计的不准确,这些方法往往会导致低质量的去雾结果。
1.2 基于端到端的去雾
近年来,端到端CNN 被用来直接从输入雾图像中学习无雾图像进行除雾。Yang 等人[9]将雾成像模型约束和图像先验学习集成到一个单独的除雾网络中进行无雾图像预测。Li 等人[10]将VGG(visual geometry group)特征和l1 正则化梯度引入条件生成对抗网络(conditional generative adversarial nets,CGAN)中进行无雾图像重建。Ren 等人[11]设计了一个编码-解码器网络GFN(gated fusion network for single image dehazing),从三个由不同物理模型生成的雾图像中学习置信度图,并将它们融合到最终的去雾结果中来增强去雾效果。Liu 等人[12]将语义分割任务中的GridNet 网络引入到图像任务上,提出了一个Grid-DehazeNet 用于端到端图像去雾。Qu 等人[13]提出了一个增强型Pix2Pix 去雾网络,通过分阶段的去雾模块来增强去雾效果。Deng 等人[14]提出了一种深度多模型融合网络,通过将多个物理模型得到的结果融合到不同的层中,提高图像去雾的性能。
虽然上述端到端的去雾方法比基于物理模型具有更好的去雾效果和鲁棒性,然而,这些方法在聚合多尺度空间上下文信息上依然采用图像或特征图池化下采样的方式,导致图像的高频细节信息容易丢失。此外,这些网络模型多为线性拓扑结构,忽略了浅层与深层特征之间复杂的非线性关系。虽然文献[12]采用格子网络结构来提取雾图像的特征信息,但并未考虑重雾场景下的有效去雾,在缓解雾与信号之间纠缠方面的能力依然较弱。
2 本文方法
本文提出的密集连接扩张卷积神经网络(DCDN)主要分为3 个模块:预处理模块、密集扩张模块和侧输出模块。DCDN 以密集块为基础,可以保持特征的有效传递。在密集块中逐步加入不同扩张率的扩张卷积,有效聚合空间上下文信息,并避免了网格伪影的产生。为了充分利用各层的特征,通过引入侧输出模块,保证中间特征层的信息不丢失。图2 给出了该网络的整体框架。
2.1 网络结构
预处理模块首先使用一个卷积操作从有雾图像中提取相关特征。输入的特征通道数为3,使用3×3的卷积核,输出的特征通道16。预处理模块输出的特征作为密集扩张模块的输入。
密集扩张模块的目的是从网络的浅层开始有效利用各层的特征,经过多层的传递后依然能够保持学习过程中细节信息的完整性。该模块中共串联了16 个密集块,每4 个密集块后面做一个输出,其中前三个为侧输出,第四个为最终输出。这里每个密集块的输入特征通道数为16,卷积核大小为3×3,增长率为16,输出的特征通道数也为16。
侧输出模块是对密集扩张模块提取的特征进行融合,得到恢复后的无雾图像。在侧输出模块把密集扩张模块输出的16 个特征通道进行融合得到3 个特征通道,其中选取了3×3 的卷积核,采用ReLU[15]作为激活函数。
2.2 密集扩张模块
本文使用的密集块[16]如图3 所示。每个密集块包括5 层,前4 层中的每一层都是接收前面所有层的信息,输出作为下一层的输入。其中第一层卷积的扩张率为1,第二层卷积的扩张率为5,第三层卷积的扩张率为9,第四层卷积的扩张率为13。第五层把前4 层以通道拼接方式得到的特征图,通过1×1 的卷积操作,降低输出信息的冗余,把前4 层提取出来的特征通道降低到初始输入密集块的通道数。然后以当前密集块输出的信息作为下一个密集块的输入,依次类推,第d个密集块的输出为第d+1 个密集块的输入(d=(1,2,…,15))。
扩张卷积[17]可以增大接收域,降低层内空间信息的损失,如图4 所示。扩张卷积可以通过增加扩张率来聚合大尺度空间上下文信息,能够在保证网络中参数量不变且不损失细节信息的前提下,可以获得更大的感受野。
2.3 损失函数

Fig.2 Architecture model of densely connected dilated convolutional neural network图2 密集连接扩张卷积神经网络的整体框架
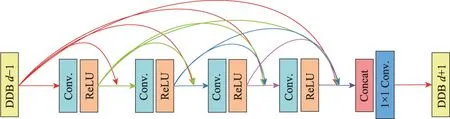
Fig.3 Framework flow of dense blocks图3 密集块的框架流程
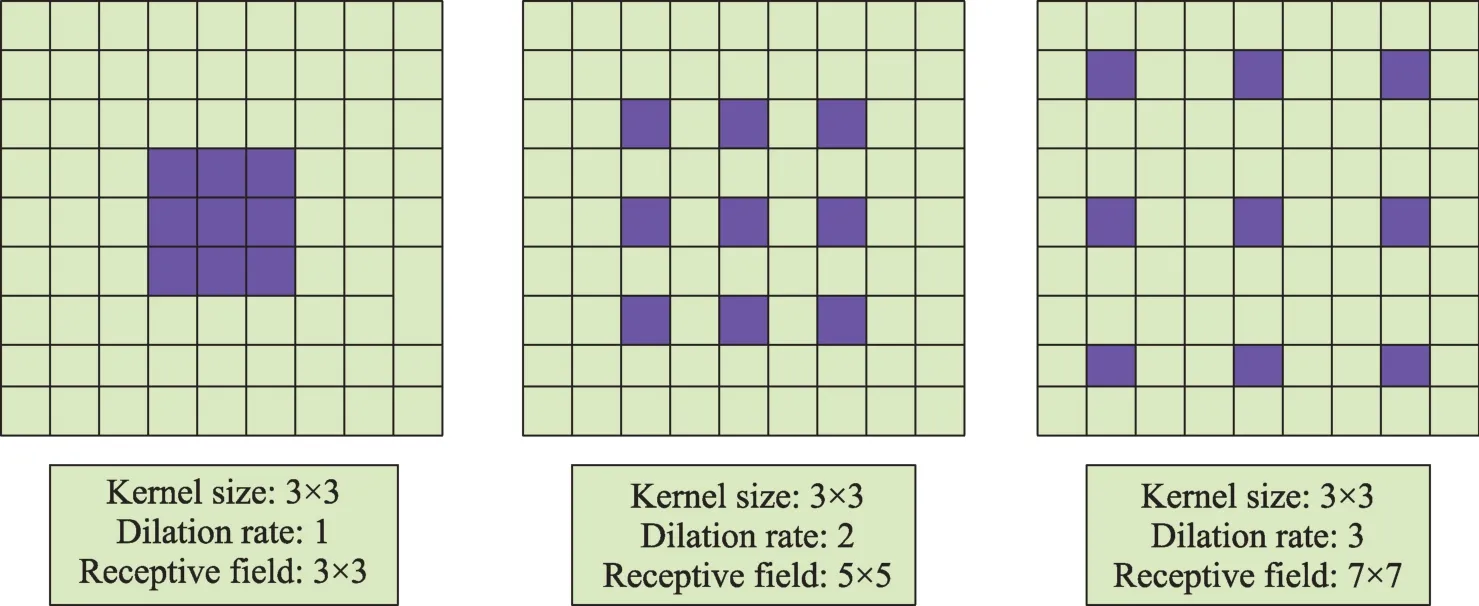
Fig.4 Schematic diagram of reception domain with convolution kernel of 3×3 and expansion rate of 1,2 and 3图4 3×3 卷积核扩张率为1、2、3 的接收域示意图
平滑的L1 损失克服了L1 损失的缺点,消除了局部的不稳定点,使其梯度更加光滑。本文通过引入平滑的L1 损失,有助于降低不稳定点的影响,并有利于优化网络的性能。感知损失函数[18]利用前馈卷积神经网络并结合预训练好的网络提取高级特征信息,相对单一的前馈卷积神经网络能更高质量地恢复图像。本文网络的3 个侧输出做平滑L1 损失,最终输出同时做平滑L1 损失和感知损失。通过联合侧输出和主干网的输出,同时利用浅层和深层的特征优化整个网络。平滑L1 损失表示为:

其中,N表示像素的总数;ˆ是有雾图像;J是无雾图像;i表示图像的通道号;x表示图像中的像素;(x)(Ji(x))表示像素x在有雾图像(无雾图像)中第i个通道的强度值。
为了获得更加丰富的细节信息,使用感知损失联合优化整个网络。感知损失表示为:
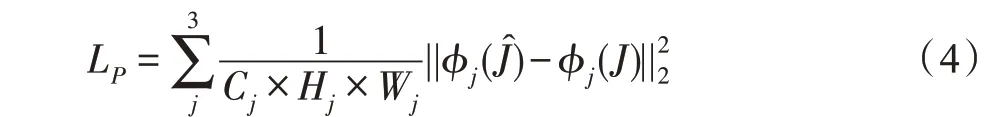
其中,φ是VGG16[19]基于ImageNet[20]训练损失网络,是有雾图像,J是无雾图像。是处理有雾图像Jˆ时,网络φ的第j层的特征图;φj(J)是处理无雾(标签)图像J时,网络φ的第j层的特征图;Cj×Hj×Wj是的三维特征图,其中j=1,2,3。

总损失由三个侧输出损失和最终输出损失组成,总损失表示为:其中,L表示总损失,LO为最终输出损失,L1、L2、L3为前三个侧输出损失,λ1、λ2为加权常数,λ1为0.7,λ2为0.1,加权常数由控制变量实验产生的最优结果确定。
多阶段侧输出损失的设计是为了防止图像在深层网络中的特征丢失和梯度消散,从而起到对网络中各阶段进行中继监督的作用。这种方式不仅适用于图像去雾,对其他使用深层神经网络的图像处理任务也同样适用。此外,针对各阶段损失函数比例常数的设计思路,由于图像去雾结果为网络最终输出的结果,侧输出只是对算法的优化调整,因此本文遵循最终输出比例大、侧输出比例小的原则。
3 实验
本章首先介绍实验的相关配置,然后在合成数据集和真实数据集上与已有方法进行对比分析。在合成数据集上进行了主观和客观评估,在真实数据集上,由于没有无雾参照图像,故只进行主观评估。选取峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性(structural similarity index,SSIM)[21]作为合成数据集的客观评价指标。
3.1 数据集
正常情况下很难采集到大量成对的有雾-无雾图像的数据集,通常使用合成数据集,即在真实数据集上基于大气散射模型合成有雾的图像。RESIDE[22]是一个大规模的合成数据集,由5 个子数据集组成:室内训练集(ITS)、室外训练集(OTS)、综合客观测试集(SOTS)、真实测试集(RTTS)和混合主观测试集(HSTS)。其中ITS、OTS、SOTS 为合成数据集,ITS和OTS 分别用于室内和室外环境的训练,SOTS 用于室内及室外两种场景的测试;RTTS 为真实数据集,RTTS 用于真实有雾图像上的测试。ITS 包含1 399张无雾图像和13 990 张有雾图像,其中1 张无雾图像生成10张不同轻重等级的有雾图像。OTS包含8 477张无雾图像和296 695 张有雾图像,其中1 张无雾图像生成35 张不同轻重等级的有雾图像。SOTS 包含室内有雾图像500 张和室外有雾图像500 张。RTTS包含4 322 张真实的有雾图像。
3.2 实验细节
本文的网络采用端到端的训练策略,截取大小为240×240 的图像块作为网络的输入。该网络基于PyTorch 框架实现,使用ADAM[23]优化整个网络。在室内和室外情况下,网络的初始学习率都为0.001。在室内的情况下,每20 轮学习率变为原来的一半,共训练100 轮(epoch)。室外的情况下,每两轮学习率减半,共训练15 轮(epoch)。实验使用Nvidia GeForce RTX 2080 Ti 训练整个网络,并配置NVIDIA 的深度学习库提升GPU 运算速度。所有的训练和测试均在python3.7 上进行,训练的批次大小(batchsize)为8。室内的训练时长约24 h,室外的训练耗时约65 h。
3.3 对比分析
在合成数据集和真实数据集上的对比的方法有
DCP(dark channel prior)[3]、DehazeNet[6]、DCPDN[8]、AODNet(all-in-one dehazing network)[24]、GFN[11]、EPDN(enhanced Pix2pix dehazing network)[13]。其中DCP[3]是利用暗通道先验知识对图像去雾,其他方法是目前在去雾任务上经典且效果较好的深度学习方法。
3.3.1 合成数据集
表1 为不同去雾方法在SOTS 数据集上的定量评估。可以看出DCP[3]恢复结果的定量评价指标较低,而DehazeNet[6]、DCPDN[8]、AOD-Net[24]这些深度学习方法的评价指标一定程度上有所改善,GFN[11]的评价指标在室外环境中相对较高,EPDN[13]的评价指标在室内环境中相对较高。在室外的情况下,本文方法比GFN[11]在PSNR 和SSIM 上分别高出1.66 dB 和0.013 2。在室内情况下,本文方法比EPDN[13]的PSNR 和SSIM 分别高出2.26 dB 和0.029 9。综上所述,本文提出的方法在PSNR 和SSIM 两个指标上均高于对比方法,说明了本文提出方法对图像去雾后恢复的图像质量更接近真实的无雾图像。
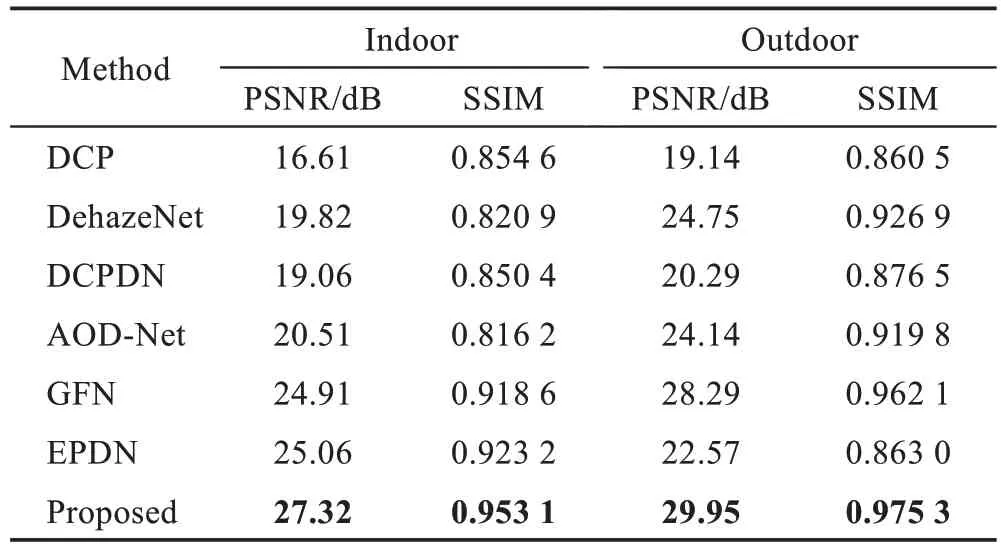
Table 1 Quantitative evaluation of different dehazing methods on SOTS data set表1 不同去雾方法在SOTS 数据集上的定量评估
图5为本文方法与已有方法在合成数据集(SOTS)上的效果,其中上面四行显示室内图像的去雾结果,下面四行显示室外图像的去雾结果,第一行和第五行分别为室内和室外的重雾去除结果。DCP[3]恢复后的图像色彩偏暗(如图5(b)的第1、5、7 幅),且有雾图像中高亮度区域去雾之后会出现色彩失真现象(如图5(b)的第6、7、8 幅天空区域)。DehazeNet[6]网络对图像去雾后个别图像存在明显的雾(如图5(c)的第2、7 幅),且色彩失真现象较严重(如图5(c)的第3、5、8幅)。AOD-Net[24]网络对图像去雾后依然存在较多的雾(如图5(d)的第2、3、5 幅)。EPDN[13]方法去雾的效果较好,但去雾后依然存在一些雾(如图5(e)的第1、3、5幅),且第4幅中墙体的颜色和第8幅中楼体颜色恢复的颜色偏差较大(如图5(e)的第8 幅)。当EPDN[13]方法和本文方法同时和真实无雾图像比对时,可以明显看出本文提出的方法在去除雾的同时色彩方面恢复得更自然(如图5(f)的第7 幅柳树及湖面区域)。从定量的指标到主观的评价,可以看出本文恢复的效果较好,相对其他方法更加接近真实的无雾图像。
值得注意的是,本文方法在室外数据集上的去雾效果要略优于室内数据集上的去雾效果。主要原因是合成数据集的生成是以大气散射模型为基础,如式(1),然而室内受干扰光线的影响,全局大气光的估计并不准确,因此造成室内合成的雾图像没有室外合成的雾图像真实,影响了算法的性能。此外,由于室内图像内容的相对距离较小,导致透射图具有更高的灵敏度,使得合成的雾图像空间受损差异更小,这也是导致室内去雾效果相对较差的一个原因。

Fig.5 Comparison of different image dehazing methods on synthetic data sets图5 不同图像去雾方法在合成数据集上的比较
3.3.2 真实数据集
相对于合成数据集,真实数据集是在有雾天气情况下进行采集的,更具真实性和实用性。然而,同一场景下有雾与无雾的采集需要十分昂贵的成本。因此,目前的端到端图像去雾方法都是在合成数据集上进行训练和算法验证,在真实数据集上进行主观评估。
图6 为本文方法与已有方法在真实数据集(RTTS)上的测试效果。DCP[3]恢复的图像整体偏暗(如图6(b)的第2、4 幅),且个别图像出现色彩失真现象(如图6(b)的第2、3 幅)。DehazeNet[6]网络对图像去雾后依然存在较多的雾(如图6(c)的第2、5、6 幅),且出现了色彩失真现象(如图6(c)第1、4 幅)。AODNet[24]网络对图像去雾后的效果相对较好,但色彩上相对偏暗(如图6(d)的第1、2、4 幅),且个别图像恢复后的色彩偏差较大(如图6(d)的第3、5 幅)。EPDN[13]方法去雾的效果较好,但去雾后图像的色彩偏差依然较明显(如图6(e)的第2、4、5 幅)。与上述方法相比,本文方法在有效降低雾气,同时恢复后的图像在色彩上更自然。综上所述,本文提出的方法无论是在合成数据集上还是在真实数据集上,都取得了较好的去雾效果。

Fig.6 Comparison of different image dehazing methods on real data sets图6 不同图像去雾方法在真实数据集上的对比
真实环境下拍摄的有雾图像具有更大的复杂性和不确定性,这给图像任务带来了更大的挑战。本文提出的多阶段去雾方法通过分解问题空间,分阶段逐步去除图像中的雾,因此相对于其他方法在真实环境下具有更优的去雾效果。
4 消融实验
4.1 网络参数量
为了进一步证实DCDN 高效的特征利用率,比较了不同方法的参数量和定量去雾结果。如图7 所示,相比于目前的图像去雾算法,本文提出的DCDN网络不仅参数量小,而且去雾图像的峰值信噪比(PSNR)达到了最优效果。与最近提出的EPDN[13]网络相比,DCDN 的参数量仅为其3%左右,但PSNR 却高出了2.26 dB。
4.2 密集网络扩张率设置
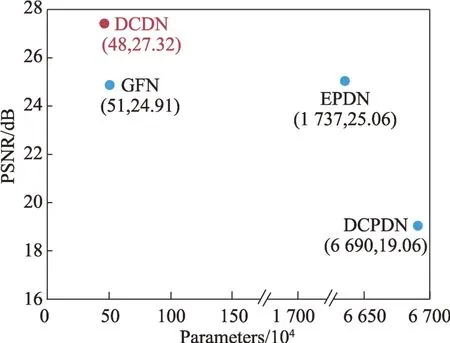
Fig.7 Comparison of parameters and peak signal-to-noise ratio of different methods图7 不同方法的参数量和峰值信噪比对比
其次,为了证实扩张卷积对网络性能的影响。分别评估了DCDN 网络中正常卷积和扩张卷积的去雾效果,以及不同的扩张率对网络性能的影响。如表2 所示,由于正常卷积(R1)仅在一个小区域内获取图像信息,其去雾效果较差。扩张卷积(R2,R3,R4,R5)则在不增加参数量,且不损失空间分辨率的情况下,充分聚合了上下文信息,因此其去雾效果要优于正常卷积。此外,为了确定密集扩张块中不同层的扩张系数,分别实验了不同的扩张率组合。如表2 所示,随着扩张率的增加,去雾结果的PSNR 和SSIM 也在提升,当扩张率超过R4=1,5,9,13 后,由于上下文信息关联性减弱,去雾结果也降低,因此本文将每个密集扩张块的扩张率设置为1,5,9,13。

Table 2 Impact of different dilated rates on network performance表2 不同扩张率对网络性能的影响
4.3 侧输出模块对网络性能的影响
为了验证每个阶段均引入侧输出模块的必要性,实验了侧输出模块对网络去雾性能的影响。如表3 所示,其中S1、S2、S3分别代表各阶段的侧输出模块,随着侧输出模块的增加,去雾结果的PSNR 和SSIM 也在提升。此外,由于侧输出模块只作为网络各阶段的中间特征监督,因此只在训练时产生少量参数;而在应用测试时不再使用侧输出模块,因此不会增加额外的计算成本。

Table 3 Impact of side output module on network dehazing performance表3 侧输出模块对网络去雾性能的影响
4.4 阶段数量设置
表4 为不同阶段数量的参数量、PSNR 和SSIM,如表所示,随着网络阶段的增加,参数量、PSNR 和SSIM 都在逐步增加。然而,当网络为5 个阶段时,PSNR 和SSIM 仅比4 个阶段提高了0.04 dB 和0.000 6,但参数量依然增加了11 万。因此,为了权衡参数量和去雾效果,本文将网络阶段数量设置为4 个。

Table 4 Parameters and quantitative dehazing results in different number of stages表4 不同阶段数量的参数量和定量去雾结果
5 结束语
本文提出了一种用于图像去雾的密集连接扩张卷积神经网络。该网络使用密集扩张模块来增强特征利用率,通过密集扩张卷积克服了目前神经网络在聚合上下文信息上遇到的瓶颈问题,通过多阶段的侧输出模块增强网络去雾的鲁棒性。实验表明,本文方法摆脱了大气散射模型参数的影响,对比合成数据集和真实数据集上去雾的效果可以发现,本文方法恢复的图像更加接近无雾图像,并且恢复后的图像色彩更自然。在客观指标上也证明了本文方法图像恢复的质量较优。在接下来的工作中,将进一步提高算法在真实场景上去雾能力。
猜你喜欢
社会科学战线(2022年1期)2022-02-16
计算机研究与发展(2022年1期)2022-01-19
客联(2021年9期)2021-11-07
英语文摘(2021年2期)2021-07-22
海外文摘·艺术(2020年22期)2020-11-18
汉语世界(The World of Chinese)(2018年6期)2018-01-22
岁月(2016年5期)2016-08-13
文苑(2015年9期)2015-09-10
BOSS臻品(2015年1期)2015-09-10
新课程学习·中(2013年3期)2013-06-14
