
基于预分区策略的装备数据分布式存储方法
2021-01-15 07:27许利杰汪保龙杨富学黄骁飞
计算机与生活 2021年1期
高 健,魏 峻,许利杰,汪保龙,杨富学,黄骁飞
1.中国科学院软件研究所软件工程技术研发中心,北京100190
2.中国科学院大学,北京100049
3.北京电子工程总体研究所,北京100039
随着计算机技术、传感器技术、物联网技术的发展,工业领域正前所未有地创造着大量数据,对于工业领域而言,大数据带来了潜在价值的同时,也同时带来了巨大的挑战[1]。大数据的挑战之一在于如何能在数据快速产生的同时实现数据快速存储管理,这对于数据的价值挖掘有重要作用,对于提升装备制造能力也具有重要意义。
研究装备大数据管理首先应研究装备数据特点,装备具有“多样性、大规模、高频性、时序性、高价值性”的数据特点[2-3],这里以航空航天装备数据为例说明。(1)多样性:装备在研制生产的过程中经历多个过程,包括设计、研发、试验、生产、使用和维护等,每一个过程又有多个种类的子过程,如飞机的试验包括发动机上电和点火试验、燃油系统的适坠性试验、轮胎爆破试验、疲劳试验、地面滑行试验等[4-5]。(2)大规模:装备结构复杂,特别是高端装备内部有数十个分系统、上百个子系统、成千上万个装备部件,一颗卫星、一架飞机可采集的参数往往有上万个,一个型号一次试验就能采集几十GB 的数据,因此数据量巨大。(3)高频性:随着传感器技术和传输网络的发展,数据的采集和传输频率特别高,如飞机总线协议ARINC664 采用全双工通信模式,带宽可达100 Mbit/s,终端数量理论无上限,采用这种协议采集的数据频率可达纳秒级[6-7]。(4)时序性:装备数据是强时序的,这也是与互联网数据的区别所在,互联网数据一般是庞杂且是离散的,装备数据一般是规则的且时序的,对于装备数据的使用往往也具备较强的时序性特征。(5)高价值性:装备在研制生产过程中产生的庞大数据量整体是高价值的,在工业生产的各个环节,数据直接反映装备质量,通过数据可以发现并排除装备研制生产过程中存在的隐患。
为解决装备大数据的存储管理问题,各界学者及工业部门开展了大量的研究与实践。但是,一个不容忽视的现实是,装备数据作为企业的重要核心资产,往往掌握在某些公司甚至某些部门手里,几乎不能与外人分享,因此对于大数据存储管理研究的大量成果,难以实现真正的验证与应用,对于某些在工业制造中出现的实际问题也没有解决办法。
迄今为止,我国装备数据存储管理方式主要有两种:一是将数据以原始文件的形式存储在硬盘上,数据“现用现解析”[8];二是数据解析后存储在关系型数据库中,形成数据资产库和数据仓库。两种存储都是传统的数据管理模式,在应对大数据方面都有一定的不足之处。使用文件的方式存储,难以针对大量数据进行更进一步的复杂分析,无法有效洞悉数据的内在价值。使用关系型数据库存储,由于数据库本身的限制,从技术上不得不将数据存储表切割,进行大规模的分表和分库,以缓解海量数据带来的存储压力。但是分表分库会带来非常高的成本,特别是数据检索效率很低,在众多类型的装备数据不断累积的背景下,这种方式显然已经无法满足当前的需求。
针对装备数据的特点,需要这样一种数据存储管理方式,首先要解决装备数据多样性和大规模特点,能够从生产过程、装备组成等多个维度存储海量数据;其次要能有效存储高频数据,对不同频率的数据进行分类存储;最后要能较好地支持数据的时序性特征。
为解决以上描述问题,本文提出了基于预分区策略的分布式存储方法,该方法使用分布式列式存储管理海量装备数据,可以实现数据存储的负载均衡,并提高数据存储效率;在数据模型方面,提出了基于列式存储结构的装备数据的分布式存储模型,定义了数据的键值对存储结构,有效解决单次TB 级装备数据的存储问题;在存储过程方面,提出了一种基于列式数据预分区策略,进而解决海量装备数据的高速存储问题,实现TB 级装备数据在15 min 内完成存储。
1 分布式列式数据库存储
1.1 HBase数据库简介
分布式数据存储技术是大数据的典型技术之一[9],其核心是将数据分散地存储在多台服务器设备上,这样一方面可以减少因数据量过大而造成的对单一服务的高负载,另一方面也可以提高数据整体的安全性、可靠性和存储效率,同时也可以提高数据存储的可扩展能力[10-11]。
以Hadoop 为代表的开源大数据技术的问世,快速推动了分布式存储技术的发展,HBase作为Hadoop架构下的分布式列式数据库,其内在的分布式元数据管理架构可以将数据分散地存储在多个节点上,进而解决了数据集中存储带来的瓶颈问题[12-13]。本文也是基于HBase 的分布式存储模式展开装备数据快速存储策略的讨论,在该模式中,装备海量工程值数据可以<key,value>的数据格式快速地存储在每个存储节点上,每个节点的每个HRegion 分散地承担数据存储任务。
1.2 HBase分区机制
在HBase 的设计中,每一个Region 作为一个单独的存储单元,用于数据的分区存储管理。每一个数据管理节点都分配一个Region server,用于管理若干个Region,Region server 和Region 是一对多的关系[14]。而Region 下面可以创建若干个store,每一个store 对应存储每一个Hfile,Region 和store 是一对多的关系。HBase 自身设计了一套自动分区机制,包含多种自动分区策略,能够在海量数据存入HBase 时,将数据平均存储在多个Region 中,进而实现数据在多台机器上的负载均衡。
HBase 分区策略的核心思想是通过判断hfile 是否超出了一定的阈值(Region 的存储能力),当达到阈值时Region 会进行裂变,HBase 的机制是选取Region 中间key 值,然后保留startkey 和endkey,将区间一分为二,新生成的Region 会重新挂载在Region server中,最后汇报给HBase中的master。
2 关键机制
2.1 数据表征
装备数据具有大规模、高频性、时序性等特征,但在装备不同的生命周期有所差异,如试验阶段需要大量数据进行装备功能和性能分析,因此特征最为明显。装备数据往往是以二进制方式进行传输处理的,图1 给出了某型号飞机和某型号飞行产生的数据示例,表1 对装备数据特征进行了说明,从数据来源阶段、数据量、数据频率、数据格式、数据组成、参数数量、数据相关性、数据标签等方面进行了特征说明。
2.2 装备数据快速存储框架
本文研究基于HBase 预分区策略的装备数据快速存储的框架,该框架的主要目标是实现装备数据在HBase 中进行快速而均衡的数据存储,该框架以快速存储中间件为核心,内置HBase 自动化预分区模块,针对经过预处理后的格式化装备数据,实现数据快速存储。

Fig.1 Initial data format of aircraft图1 飞行器初采数据格式

Table 1 Data characteristics表1 数据特征
图2 展示了装备数据快速存储的框架。在数据处理层中,数据经过准备、预处理和数据解析之后,数据进入到中间件层。中间件层的作用是在数据处理层和数据存储层之间搭建一个服务层,能够将解析之后的数据按照需求进行快速处理和存储。中间件层包含四个模块,分别是数据标准化模块、关键信息采集模块、HBase 预分区处理模块、HBase 服务接口模块。其中,数据标准化模块的作用是将不同类型的装备数据进行标准化格式处理,形成可以存储在HBase 数据库中的数据格式;HBase 预分区模块实现基于装备模型的HBase 的预分区规则,执行规则算法;关键信息采集模块可以将预分区所需要的数据从原始数据文件、数据配置文件、集群环境中进行采集;HBase 服务访问接口提供标准的HBase 数据库访问服务。通过中间件层的数据存储优化过程执行后,HBase 会根据命令执行相应的预分区操作,并接收中间件层下发的数据存储命令。本文主要完成了中间件层以下的相关工作,通过研究自动化预分区算法实现数据的快速存储。

Fig.2 Fast storage framework for equipment data图2 装备数据快速存储框架
2.3 装备数据分布式存储方法设计
由于装备在短时间内可产生大量数据,如某型号飞机在一次飞行任务里可产生10 亿~100 亿条数据,传统关系型数据库一张表的存储上限为千万级,数据量过亿后查询效率大大降低。而使用大规模的分表分库会提升管理成本,同时也会降低跨时间域、参数域的数据检索效率。因此采用分布式列式数据库,可以同时解决海量装备数据的高速存储问题和快速查询问题。
在分布式存储设计中,首先建立基于HBase 的数据存储模型,这影响着数据分区规则的制定。HBase的数据存储是key/value 形式的,每一条信息使用rowkey作为索引,而HBase的分区机制是使用rowkey的前置字符作为分区边界[15]。因此,如何基于装备数据存储模型实现自适应的预分区机制,将是整个研究的基础。当然,装备数据存储模型的建立依托于分布式数据库HBase和传统的关系型数据库。
以飞行器为例,一般的飞行器信息如飞行器表、飞行器型号表、飞行器分系统表、飞行器参数表仍然使用关系型数据库管理,而产生大量数据的飞行器参数值表需要使用分布式数据库进行管理,也就是需要对其建立分布式数据存储结构。在分布式数据库HBase 中建立飞行器参数工程值表,实现飞行器数据存储方式的重构,完成数据模型的建立。对于rowkey 中索引的唯一标识,需要飞行器飞行任务、参数数据时间戳、参数名进行组合实现唯一标识索引,而value 中需要存储每一个参数每一条数据的数值,将数据碎片化存储。值得注意的是,这里不使用HBase 的列族,原因是会降低表的检索效率[16]。这样,就完成了装备数据存储模型的最初形态。参数值如表2 所示。

Table 2 Aircraft parameter value表2 飞行器参数值表
2.4 自动化预分区策略影响因子研究
HBase 是以key/value 的结构进行数据存储的[17],其分区机制是通过数据表的rowkey 值进行分割的,HBase本身的分区机制存在以下不足。
(1)HBase 分区策略会导致数据存储上的分配不均衡,对于数据如何分配才最合理需要有经验的工程师进行干预。假设有10 GB的装备试验数据,如图3所示场景,如果工程师将HBase Region 的分裂阈值设置成10 GB,数据就会在单个Region server 中集中存储,导致其他资源闲置,集群资源极大浪费;如图4所示场景,如果工程师设置的Region 阈值过小,导致Region 阈值与数据容量比值过小,数据分配给1 000个Region 进行分布式存储,过多的分区会开启过多的并发任务,占用过多的计算资源,会影响数据的写入速度。
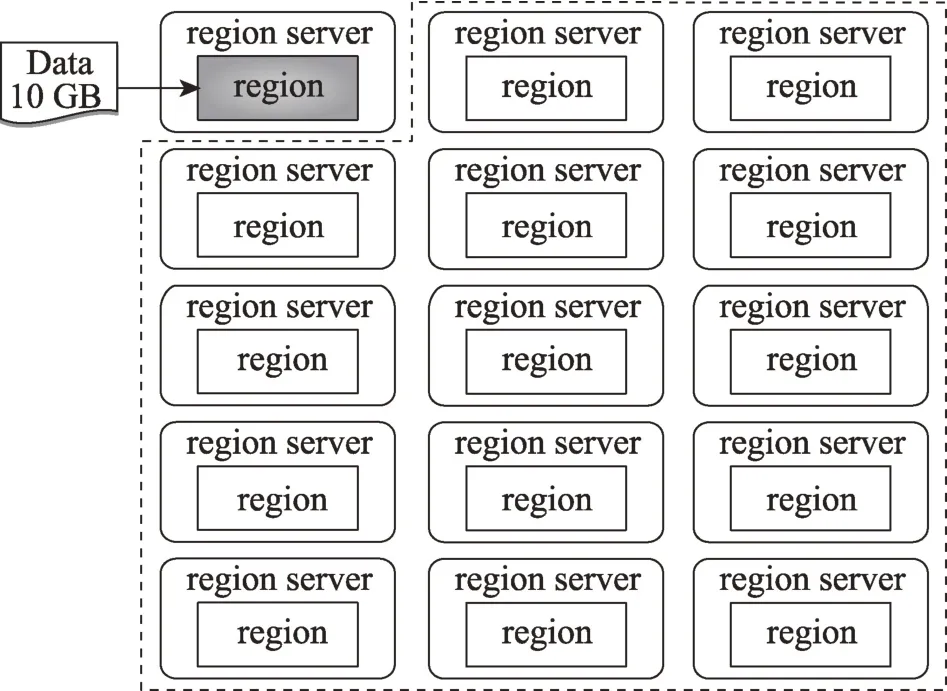
Fig.3 Uneven data distribution leading to idle and wasted server resources图3 数据分配不均导致服务器资源闲置浪费

Fig.4 Too many data partitions affecting storage performance图4 过多的数据分区影响存储性能
(2)HBase 的分区机制是Region 不停地进行split裂变操作,进行裂变的Region 需要不断地进行下线、创建、写入、重新挂载、汇报master 等过程,造成大量的资源负载,增加系统开销,数据量过大时还会导致系统崩溃。
这里设计自动化预分区的机制,在设计的装备参数值表中可以判断,需要将唯一标识“任务编号+参数名+时间戳”进行多段分割,以达到数据分布式存储的目的。而针对数据设计模型,可以选择按参数名进行分区或者按时间戳进行分区,具体选择哪种分区方法,需要研究数据的本身,如不同采样周期的参数数量和数据样本量,找出相关的影响因子,从而做出正确的选择。
这里以某型号飞行器为例,图4 统计了某型号飞行器一次飞行试验任务数据,分别统计了不同采样率和采样周期下的参数数量。在这个样本数据中,共有3 万多个采集参数点,参数点的采样周期从最小的0.1 ms 到最大的4 000 ms 不等,由图5(b)可以发现,2 000 ms 的采样周期上共有2 万多个采集参数点,也就是说大多数的参数点只有0.5 Hz 的采集频率。而由图5(a)所示,有少数样本参数的采集频率达到了8 000 Hz,单位时间内可产生大量数据,因此对于工业装备而言,由于传感器设置的差异,会导致即使在相同的时间内,参数样本数量差异很大,大样本参数0.5 Hz 与小样本参数8 000 Hz 差了16 000 倍的数据量,因此说数据极不平衡,在数据处理和存储过程中需要考虑数据倾斜问题。
更进一步地,需要在数据预处理的过程中计算出每个样本参数点在存储过程中产生的数据量,用于分区策略的判定标准。图6(a)展示了样本数据在25 个采样周期下最大的数据量值,也就是在每一个点统计了最大数据存储量值的参数。图6(a)记录了一帧数据的大小,根据存储模型可知,一帧记录数据量大小sr=f(rowkey,column,cell)=(任务单编号+参数名+时间戳+参数名+时间戳+参数值)。图6(b)展示了在1.5 h 的飞行任务下每个采集参数点产生的样本量,其中横坐标表示样本参数序号,横坐标轴下方是对应了每个序号参数的采样周期。通过图可以看到,采样周期为0.2 ms 和0.1 ms 的参数样本量很大,0.1 ms 周期的参数产生了3 GB 的数据量。由于HBase 的Region 需要设有一定的阈值,数据量超过阈值后要进行分区存储,因此需要将参数数据量纳入影响因子进行研究。
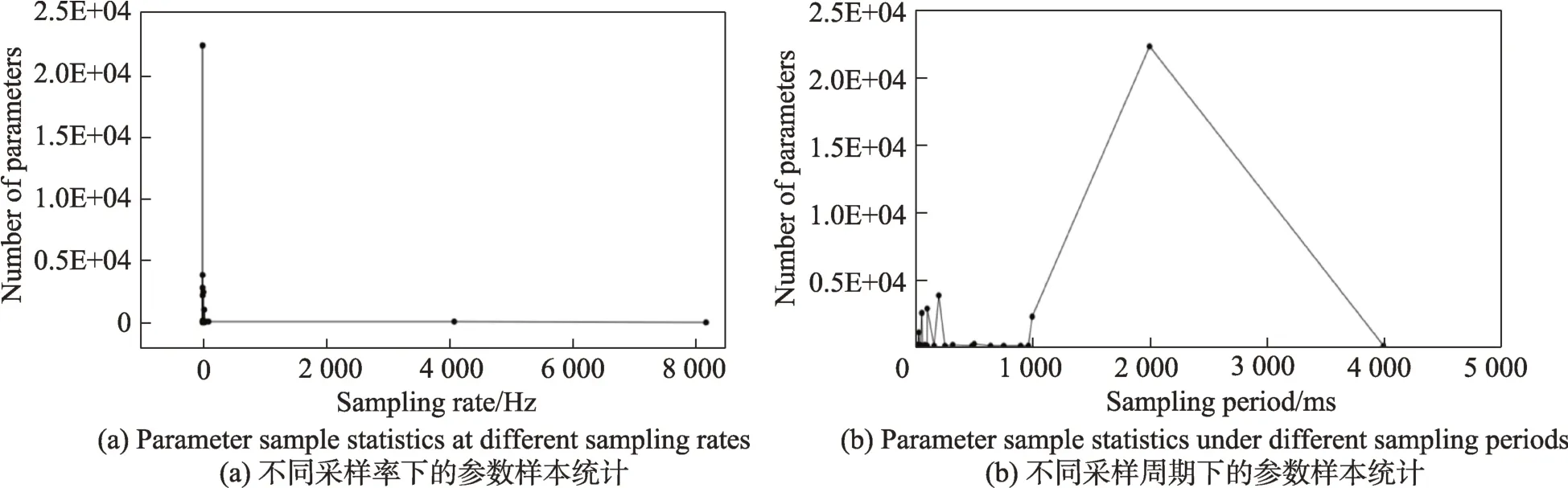
Fig.5 Sample data analysis of aircraft flight test图5 飞行器飞行试验样本数据分析

Fig.6 Flight data statistics of aircraft图6 飞行器飞行数据量统计
因此,针对飞行器数据模型的分布式存储,可以归纳出自动化预分区机制的影响因子,由表3 可知,影响因子包括装备参数数量、装备参数、装备各个参数采样率、任务总时间、单参数单条记录数据量、HBase 中Region 的裂变边界值。同样表3 中也给出了影响因子的表达符号、影响行为说明和相应的数据来源。
2.5 列式存储自动化预分区算法
列式存储自动化预分区算法的目的是让装备数据快速而又均衡地存储在每一个节点上[18],解决HBase 自动分区产生存储效率低下或是资源闲置问题。此工作若人工进行,工作量较大、难度较高[19]。因此自动化预分区的目的就是通过计算机的计算能力实现海量装备数据负载均衡的、快速的存储,如图6 所示。
表2 给出了装备参数数据的分布式存储模型,其唯一标识rowkey 组成为“任务编号+参数名+时间戳”。HBase 的分区规则是给不同的区间Region 设置起止索引,即“startkey”和“endkey”,这些key 值都是由字符串组成,也就是说,每一条数据存储在哪一个分区中,是由每一条数据的rowkey 决定的,取决于rowkey 的前置字节落在哪一个的startkey 和endkey区间之内。
一般来讲,由于装备制造过程复杂、数据类型多样、数据量庞大,HBase 的一张表中无法存储大量数据,需要将数据进行分区存储,分区方法可以分为按参数名分区和按时间戳分区两种。按参数名分区,不同的参数将会分到不同的Region 中,同一个参数所有的时间段数据相邻存储;按时间戳进行分区,不同时间段的数据分到不同的Region 中,同一个时间戳下所有参数数据相邻存储。如何进行选择,需要通过数学模型进行计算,通过参数量值的计算决定使用哪种分区方法。图7 在图6(b)的基础上增加Region size 阈值线,可以看到,由于某些参数采样率非常高,一次任务数据量可达数个GB,如果HBase 的Region size 小于某一参数的数据量,就不宜按参数进行分区,应该按时间戳分区,因为一个分区设置无法存储一个参数的数据,如果HBase 的Region size 大于全部参数的数据量,可以按参数进行分区。

Table 3 Influence factor of automated pre-partition of industry equipment data表3 装备数据自动化预分区影响因子
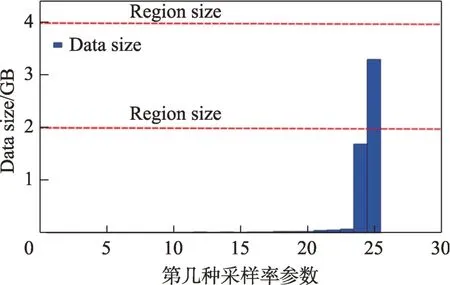
Fig.7 Comparison diagram of Region size and Data size图7 Region size和Data size的对比图
预分区算法流程如图8 所示。开始阶段需要读取样本数据文件中的参数采样率、采样时间、计算最大参数存储量,同时要获取存储环境中的HRegion 阈值。接下来需要考虑两种情况:
第一种情况:按参数名进行分区,将不同的参数数据按参数名均匀地划分存储在HBase 所有的Region中。判断条件是所有参数中采样率最高的参数数据量小于一个Region 设置的最大值,换言之,需要保证一个Region 至少能存下一个参数的完整数据。
第二种情况:按时间戳进行分区,判断条件是存在某一个或多个参数数据量大于一个Region 设置的最大值,换言之,无法保证一个Region 至少能存下一个参数点的完整数据,某些数据会溢出Region 的空间。
预分区算法伪代码如下:


Fig.8 Flowchart of pre-partitioning algorithm图8 预分区算法流程图


经过执行自动化预分区算法,飞行器的数据可以快速并均匀地存储在HBase 的分布式表中,能够适配每次试验任务的变化,能够解决数据的变化带来的数据存储效率问题和服务器负载不均衡问题。
3 试验
3.1 试验环境和设置
试验环境如表4 所示,集群采用Hadoop 大数据架构进行构建,使用的是华为公司的FusionInsight 1.0 管理系统版本,集群系统包括22 个服务器节点(其中2 个调度节点、19 个计算和存储节点、1 台应用服务器)。调度服务器节点的配置为(2×Intel Xeon 4C Processor Model E5-2609v2 2.5 GHz,RAM 512 GB),计算服务器节点的配置为(2×Intel Xeon 4C Processor Model E5-2609v2 2.5 GHz,RAM 128 GB),集群环境还包括一个核心交换机和一个千兆交换机,网络带宽为1 000 Mbit/s。在集群环境中,两台调度节点配置为一主一备的热备份方式,防止单点故障,19 台计算和存储节点不进行虚拟化操作,每台机器包括2 颗CPU,每台计算和存储节点的CPU 可以在非虚拟化环境下做超线程。在19 台计算节点上部署HBase 数据库用于数据的分布式存储,每台节点部署Region Server 和Region 环境,在试验过程中,所有的节点同时进行数据写入操作,存储过程也不存在单点故障。中间件部署在应用服务器上,和集群环境进行集成,用于实现装备数据的快速存储优化。
3.2 数据存储性能评价
本节的目标是评价自动预分区模型的存储性能,将提出的基于HBase 的自动化预分区策略数据快速存储模型与HBase 已有的自动分区机制进行对比。数据方面选取了某型号飞行器8 次飞行试验任务数据,并对其中部分数据进行了裁剪,使数据(原始数据)覆盖度从159 MB 至90 GB。
表5 列出了8 次数据存储试验的结果。如表所示,每次试验选取不同的数据量、不同的参数数量,并给出了每次试验的数据膨胀之后的数据大小,如159 MB 数据解析之后膨胀到2.5 GB,90 GB 数据解析之后膨胀到1.5 TB。在存储效率上计算数据从Hfile 进入到HBase 的时间,并将模型与HBase 自动分区机制进行对比。如表可以发现,当原始数据量超过20 GB 以后,HBase 分区机制无法对数据进行存储,而自动预分区模型可以完成所有试验数据的存储。并且当数据量不大的时候,相比较HBase 自带的分区机制,预分区策略明显有更加优秀的性能。

Table 4 Experimental environment表4 试验环境
从表5 中可以看出,与HBase 分区机制相比,预分区策略相比之下有更加优秀的性能,且随着数据量的递增,使用预分区策略没有明显的性能衰减,而HBase 分区机制会随着数据量的递增出现存储效率降低的情况,其与本文提出的模型在性能衰减方面的差距逐渐变大,且在数据到达一定量级时失效。
3.3 负载均衡性评价
本节的目标是评价自动预分区模型的负载均衡性,针对试验的19 台存储节点服务器,判断数据是否能够负载均衡地存储在每个节点上。
表6 给出了某型号飞行器两次飞行试验数据进行的负载均衡性存储试验结果。第一次试验选取的是50 GB 的原始数据文件,由于数据中某些参数采样率高,数据量过大,经过预分区算法模型的计算,选择了按时间戳进行分区存储,结果显示解析之后的数据平均分配到了19 个存储节点上,每个节点Region 的数量为11、12 个,每个节点存储的数据量在40~42 GB。

Table 5 Result of data storage performance test表5 数据存储性能试验结果

Table 6 Load balance test results of model表6 模型的负载均衡试验结果
第二次试验选取的10 GB 的原始数据文件,该文件数据量不大,因此经过预分区算法模型的计算,选择了按参数进行分区,结果显示解析之后的数据平均分配到了19 个存储节点上,每个节点的Region 数量为16、17 个,每个节点的参数数量为533 个左右,每个Region 的参数数量为31 个。
可以看出,预分区策略可以对装备数据进行良好的负载均衡存储,数据平均分配在每一个节点的每一个Region 里,这也有助于提高对海量装备数据的检索效率,提高对多维度数据的检索分析性能。
3.4 适用性评估
本节的目标是讨论预分区策略在装备领域的适用性并进行试验。多点参数、时序性、采样率、采样点数值,凡是满足这些特征的装备数据都可以使用本文讨论的预分区策略。
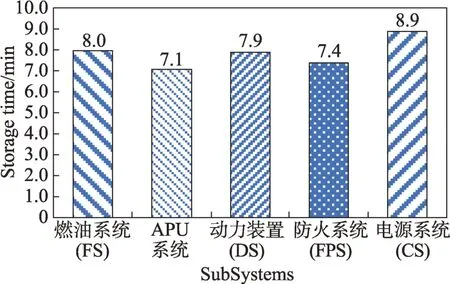
Fig.9 Airplane test data storage图9 飞机试验数据存储
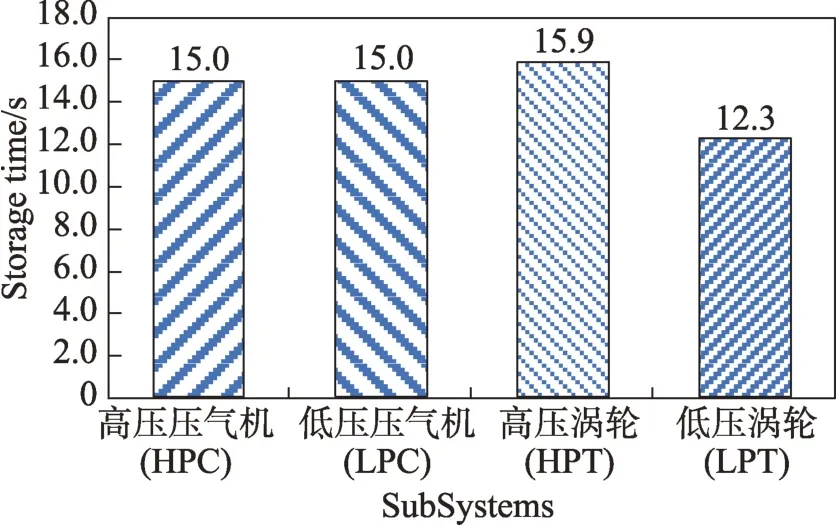
Fig.10 Airplane engine test data storage图10 航空发动机试验数据存储
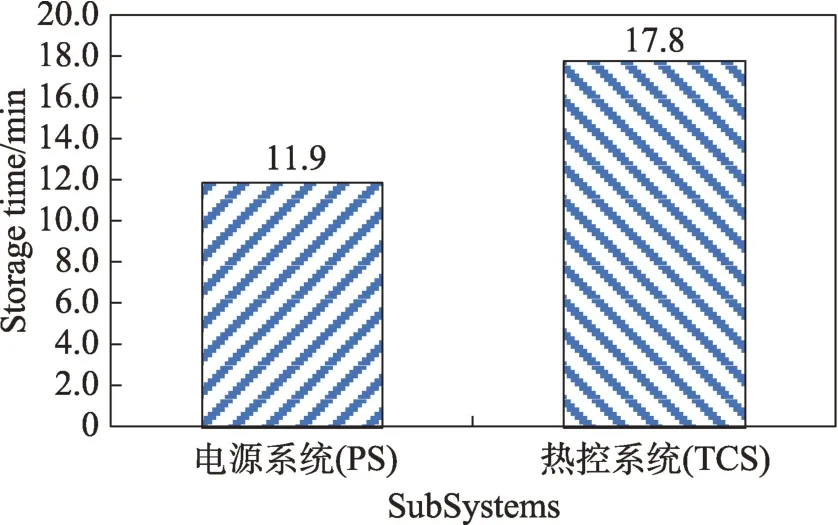
Fig.11 Satellite test data storage图11 卫星试验数据存储
这里选择四类装备进行数据试验,四类装备数据分别为某型号飞机试验数据、某型号发动机气路故障数据、某型号导航卫星数据、某型号特种车辆行驶测试数据,检测模型的适用性。如图9、图10、图11、图12 所示,描述了针对四种不同装备数据进行模型适应性评估的结果,由于数据有限,无法针对不同种类装备数据进行横向比对,但是这里仍然可以根据多次试验生成的结果进行分析。
图9 描述了某型号飞机的数据试验,这里选取了燃油系统(FS)、APU 系统、动力装置(DS)、防火系统(FPS)、电源系统(CS)五个分系统数据,经过格式化之后的数据由Hfile 经过预分区模型进行存储的时间在7~9 min 之间,证明模型对该型号飞机数据进行分布式快速存储是有效的。
图10 描述了航空发动机的数据试验,这里选取的美国NASA 公布出来的发动机进行飞行试验时内部高压压气机(HPC)、低压压气机(LPC)、高压涡轮(HPT)、低压涡轮(LPT)的试验数据。在此基础上进行了故障仿真注入,得到其在一定时间段内的故障数据。由于数据量有限,进行预分区试验在很短的时间内完成,集中在12~17 s之间,证明模型对这类型号发动机故障数据进行分布式快速存储是有效的。
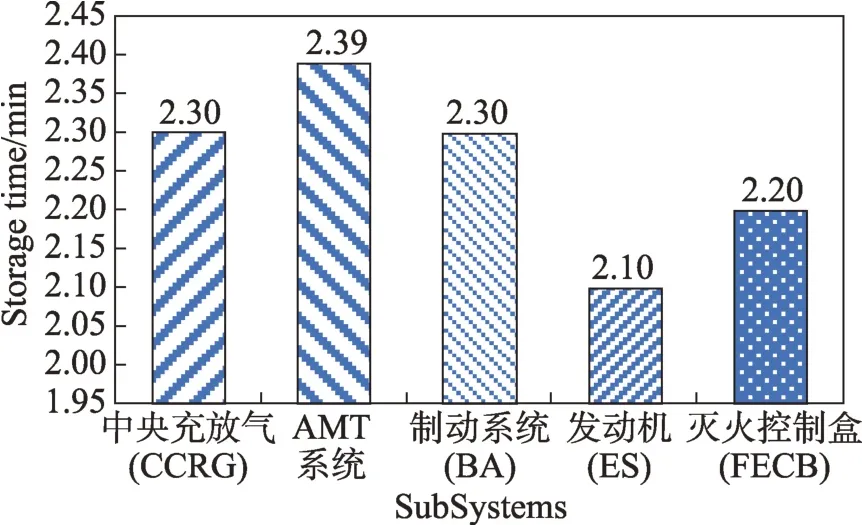
Fig.12 Special vehicle test data storage图12 特种车辆试验数据存储
图11 描述了进行的某型号卫星的数据试验,这里选取了电源系统(PS)和热控系统(TCS)两个分系统的数据及性能试验,由于该类型卫星样本数据积累时间较长,因此样本数据量较多,其中电源系统数据存储时间在12 min 左右,热控系统数据存储时间在18 min 左右,证明模型对这类型号卫星数据进行分布式快速存储是有效的。
图12 描述了进行的某型号特种车辆的数据试验,这里选取车辆5 个分系统的数据,分别为中央充放气系统(CCRG)、AMT 系统、制动系统(BA)、发动机(ES)、灭火控制盒(FECB)。由图可知,几个分系统数据可以进行存储,存储时间集中在2~3 min 内,证明模型对具备该类型特点的装备数据进行分布式快速存储是有效的。
3.5 讨论
上述试验评价了装备数据快速存储优化模型的有效性。试验结果表明,该方法可以有效提高海量装备数据在分布式存储上的性能,并使数据在存储过程中实现负载均衡。然而,本文工作仍存在以下几点不足。
为降低问题的复杂度,本文假设硬件服务器的条件为当前主要使用规格,现有服务器规格对HBase Region 的支持能力最多为10 GB,未来会进一步研究针对更加先进的高聚合高物理核的服务器对模型的影响。
文中研究的数据样本大多是装备飞行器在轨运行数据、飞行试验数据以及地面试验数据,针对飞行器其他途径产生的数据特点未做进一步研究,如指令数据、指挥控制数据、语音图像数据等。
4 相关工作
近年来学者在大数据存储优化方面进行了大量的研究,特别是针对大规模数据的分布式列存储方面,文献[19]提出了一种行列混合的存储方法,该方法在通用的列式存储的基础上,为了提高查询性能,将高频访问的列数据进行组合。但是该方法对HDFS(Hadoop distributed file system)内部进行了重新设计,影响了分布式文件系统的通用性,并不适合所有装备大数据的存储场景。日本NEC 株式社云系统研究试验室的Nishimura和加州大学巴巴拉分校的Das 等人提出了一种基于HBase 的可扩展的数据管理基础架构[20],该方法在键值存储上加入了分层的多维索引结构,而在底层使用键值存储保持系统高吞吐量和大数据量。虽然该方法在多维度查询处理上具有良好的表现,但是在16 个节点的试验环境中只能实现每秒几十万的数据写入,显然不够高效。本文中提出的策略更有助于海量数据的快速和负载均衡存储,对于数据量极其庞大的装备数据而言具有良好的数据存储表现。
还有部分学者以提高数据检索效率为目的进行了数据存储优化研究,文献[21-22]提出了一种构建大数据索引的方式,利用多副本机制满足不同海量数据查询场景,这与本文中满足不同查询场景的目标相同,但是在实际应用中需要更大的系统开销。加拿大阿尔伯塔大学的Vashishtha 等人[23]基于HBase开发了一个框架,可以实现复杂的聚合函数,如行数、最大值、最小值等,但是其解决的根本问题在于数据存储之后的查询性能优化,而本文更关注于数据的存储性能优化。文献[24]同样通过设计一种新的算法,使用户可以最高效地查询到最优的列族,进而提高HBase 的查询性能。事实上,对于装备数据而言,多列族并不适合其数据模型,单一列族可以得到更优化的数据查询性能。
数据压缩技术也是大数据存储优化研究的方向,文献[25]介绍了Snappy、bzip2 等数据压缩技术,通过压缩技术实现大数据处理过程中中间数据的读写速度,从而提高海量数据的存储问题,这与本文研究点有所不同,本文研究的数据处理过程是基于分布式内存技术,不存在中间数据写入磁盘的问题,本文从数据最终写入列式数据库的优化方面进行研究。
5 结束语
本文的主要贡献是提出了一种海量装备数据的快速存储方法,即基于HBase 自动化预分区策略的装备数据存储优化方法,该方法通过对分布式数据库HBase 和装备数据特点进行研究,解决海量装备数据快速的、负载均衡的存储问题。
该方法首先给出了装备数据分布式存储模型,并基于HBase 列式数据库实现数据快速的分布式存储。在装备数据分布式存储模型的基础上,研究了装备数据自动化预分区策略的影响因子,从数据层面和集群配置信息层面进行了关联性分析。在影响因子确认的基础上,给出了针对不同数据场景的自动化预分区算法模型。最后,通过在数据预处理层和数据存储层之间搭建数据快速处理中间件,完成优化模型的实现。该方法选取了某型号飞行器多次试验任务的数据对模型进行了验证,对其基于Hbase系统的实现在存储性能、负载均衡等方面的指标进行了评价。
猜你喜欢
大众科学(2022年5期)2022-05-18
凤凰动漫(军事大王)(2022年1期)2022-04-19
环球时报(2022-03-29)2022-03-29
电脑爱好者(2020年19期)2020-10-20
环球时报(2018-11-30)2018-11-30
软件导刊(2018年3期)2018-03-26
中国新通信(2016年11期)2016-08-09
小朋友·快乐手工(2015年5期)2015-06-06
科技与创新(2014年11期)2014-08-21
电脑爱好者(2009年19期)2009-10-19
